







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

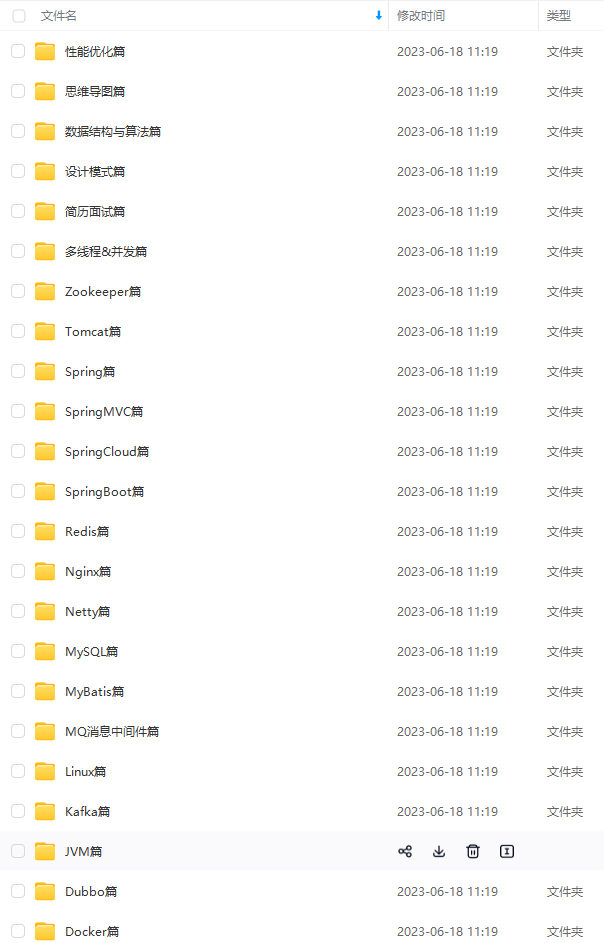
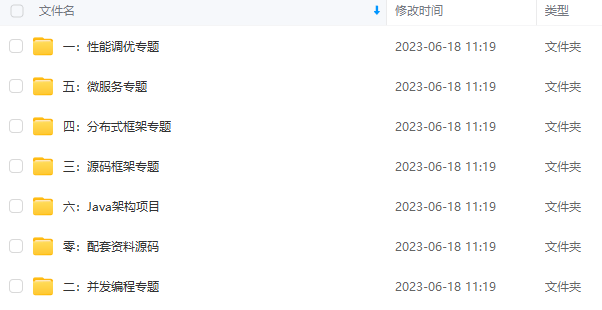
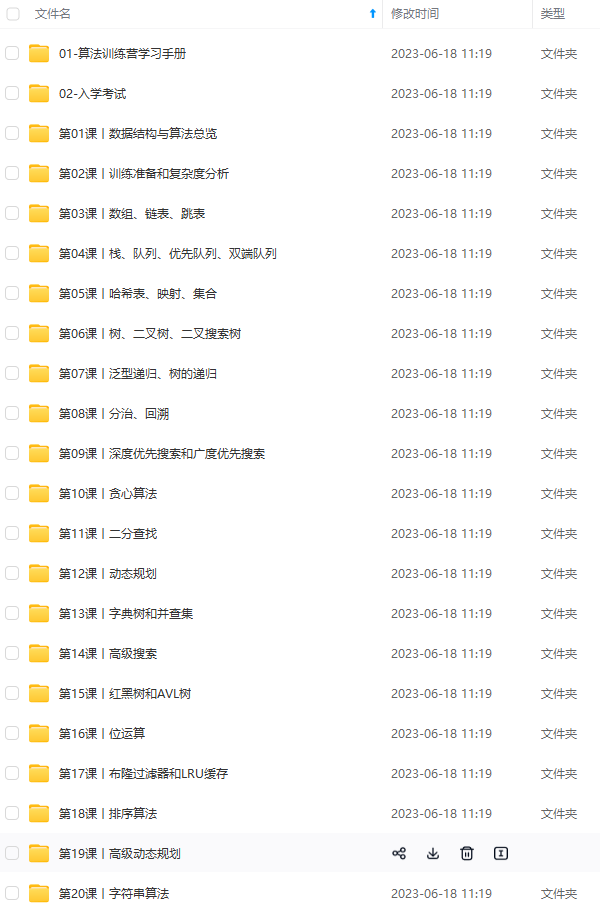
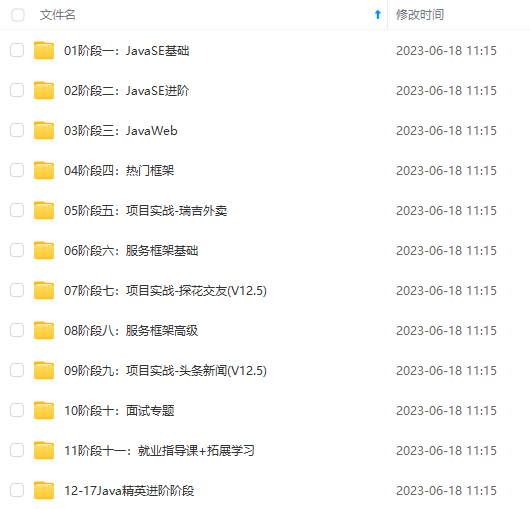
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注Java)

正文
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次握手。
完成三次握手,客户端与服务器开始传送数据
四次挥手
-
客户端先发送FIN,进入FIN_WAIT1状态
-
服务端收到FIN,发送ACK,进入CLOSE_WAIT状态,客户端收到这个ACK,进入FIN_WAIT2状态
-
服务端发送FIN,进入LAST_ACK状态
-
客户端收到FIN,发送ACK,进入TIME_WAIT状态,服务端收到ACK,进入CLOSE状态
TIME_WAIT的状态就是主动断开的一方(这里是客户端),发送完最后一次ACK之后进入的状态。并且持续时间还挺长的。客户端TIME_WAIT持续2倍MSL时长,在linux体系中大概是60s,转换成CLOSE状态
TIME_WAIT
TIME_WAIT 是主动关闭链接时形成的,等待2MSL时间,约4分钟。主要是防止最后一个ACK丢失。 由于TIME_WAIT 的时间会非常长,因此server端应尽量减少主动关闭连接
CLOSE_WAIT
CLOSE_WAIT是被动关闭连接是形成的。根据TCP状态机,服务器端收到客户端发送的FIN,则按照TCP实现发送ACK,因此进入CLOSE_WAIT状态。但如果服务器端不执行close(),就不能由CLOSE_WAIT迁移到LAST_ACK,则系统中会存在很多CLOSE_WAIT状态的连接。此时,可能是系统忙于处理读、写操作,而未将已收到FIN的连接,进行close。此时,recv/read已收到FIN的连接socket,会返回0。
为什么需要 TIME_WAIT 状态?
假设最终的ACK丢失,server将重发FIN,client必须维护TCP状态信息以便可以重发最终的ACK,否则会发送RST,结果server认为发生错误。TCP实现必须可靠地终止连接的两个方向(全双工关闭),client必须进入 TIME_WAIT 状态,因为client可能面 临重发最终ACK的情形。
为什么 TIME_WAIT 状态需要保持 2MSL 这么长的时间?
如果 TIME_WAIT 状态保持时间不足够长(比如小于2MSL),第一个连接就正常终止了。第二个拥有相同相关五元组的连接出现,而第一个连接的重复报文到达,干扰了第二个连接。TCP实现必须防止某个连接的重复报文在连接终止后出现,所以让TIME_WAIT状态保持时间足够长(2MSL),连接相应方向上的TCP报文要么完全响应完毕,要么被 丢弃。建立第二个连接的时候,不会混淆。
TIME_WAIT 和CLOSE_WAIT状态socket过多
如果服务器出了异常,百分之八九十都是下面两种情况:
1.服务器保持了大量TIME_WAIT状态
2.服务器保持了大量CLOSE_WAIT状态,简单来说CLOSE_WAIT数目过大是由于被动关闭连接处理不当导致的。
一次完整的HTTP请求过程
域名解析 --> 发起TCP的3次握手 --> 建立TCP连接后发起http请求 --> 服务器响应http请求,浏览器得到html代码 --> 浏览器解析html代码,并请求html代码中的资源(如js、css、图片等) --> 浏览器对页面进行渲染呈现给用户
讲一下长连接
- 一、基于http协议的长连接
- 在HTTP1.0和HTTP1.1协议中都有对长连接的支持。其中HTTP1.0需要在request中增加”Connection: keep-alive“ header才能够支持,而HTTP1.1默认支持.
- http1.0请求与服务端的交互过程:
-
客户端发出带有包含一个header:”Connection: keep-alive“的请求
-
服务端接收到这个请求后,根据http1.0和”Connection: keep-alive“判断出这是一个长连接,就会在response的header中也增加”Connection: keep-alive“,同是不会关闭已建立的tcp连接.
-
客户端收到服务端的response后,发现其中包含”Connection: keep-alive“,就认为是一个长连接,不关闭这个连接。并用该连接再发送request.转到a)
- 二、发心跳包。每隔几秒就发一个数据包过去
TCP如何保证可靠传输?
-
三次握手。
-
将数据截断为合理的长度。应用数据被分割成 TCP 认为最适合发送的数据块(按字节编号,合理分片)
-
超时重发。当 TCP 发出一个段后,它启动一个定时器,如果不能及时收到一个确认就重发
-
对于收到的请求,给出确认响应
-
校验出包有错,丢弃报文段,不给出响应
-
对失序数据进行重新排序,然后才交给应用层
-
对于重复数据 , 能够丢弃重复数据
-
流量控制。TCP 连接的每一方都有固定大小的缓冲空间。TCP 的接收端只允许另一端发送接收端缓冲区所能接纳的数据。这将防止较快主机致使较慢主机的缓冲区溢出。
-
拥塞控制。当网络拥塞时,减少数据的发送。
详细介绍http
HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。
特点
-
简单快速:客户向服务器请求服务时,只需传送请求方法和路径。请求方法常用的有GET、HEAD、POST。每种方法规定了客户与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快。
-
灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。
-
无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
-
无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
-
支持B/S及C/S模式。
请求消息Request
-
请求行,用来说明请求类型,要访问的资源以及所使用的HTTP版本.
-
请求头部,紧接着请求行(即第一行)之后的部分,用来说明服务器要使用的附加信息从第二行起为请求头部,HOST将指出请求的目的地.User-Agent,服务器端和客户端脚本都能访问它,它是浏览器类型检测逻辑的重要基础.该信息由你的浏览器来定义,并且在每个请求中自动发送等等
-
空行,请求头部后面的空行是必须的
-
请求数据也叫主体,可以添加任意的其他数据。
响应消息Response
-
状态行,由HTTP协议版本号, 状态码, 状态消息 三部分组成。
-
消息报头,用来说明客户端要使用的一些附加信息
-
空行,消息报头后面的空行是必须的
-
响应正文,服务器返回给客户端的文本信息。
状态码
-
200 OK //客户端请求成功
-
301 Moved Permanently //永久重定向,使用域名跳转
-
302 Found // 临时重定向,未登陆的用户访问用户中心重定向到登录页面
-
400 Bad Request //客户端请求有语法错误,不能被服务器所理解
-
401 Unauthorized //请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
-
403 Forbidden //服务器收到请求,但是拒绝提供服务
-
404 Not Found //请求资源不存在,eg:输入了错误的URL
-
500 Internal Server Error //服务器发生不可预期的错误
-
503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后可能恢复正常
http的方法
-
get:客户端向服务端发起请求,获得资源。请求获得URL处所在的资源。
-
post:向服务端提交新的请求字段。请求URL的资源后添加新的数据。
-
head:请求获取URL资源的响应报告,即获得URL资源的头部
-
patch:请求局部修改URL所在资源的数据项
-
put:请求修改URL所在资源的数据元素。
-
delete:请求删除url资源的数据
URI和URL的区别
URI,是uniform resource identifier,统一资源标识符,用来唯一的标识一个资源。Web上可用的每种资源如HTML文档、图像、视频片段、程序等都是一个来URI来定位的
URI一般由三部组成:
-
访问资源的命名机制
-
存放资源的主机名
-
资源自身的名称,由路径表示,着重强调于资源。
URL是uniform resource locator,统一资源定位器,它是一种具体的URI,即URL可以用来标识一个资源,而且还指明了如何locate这个资源。URL是Internet上用来描述信息资源的字符串,主要用在各种WWW客户程序和服务器程序上,特别是著名的Mosaic。采用URL可以用一种统一的格式来描述各种信息资源,包括文件、服务器的地址和目录等。
URL一般由三部组成:
-
协议(或称为服务方式)
-
存有该资源的主机IP地址(有时也包括端口号)
-
主机资源的具体地址。如目录和文件名等
HTTPS和HTTP的区别
总结:绘上一张Kakfa架构思维大纲脑图(xmind)

其实关于Kafka,能问的问题实在是太多了,扒了几天,最终筛选出44问:基础篇17问、进阶篇15问、高级篇12问,个个直戳痛点,不知道如果你不着急看答案,又能答出几个呢?
若是对Kafka的知识还回忆不起来,不妨先看我手绘的知识总结脑图(xmind不能上传,文章里用的是图片版)进行整体架构的梳理
梳理了知识,刷完了面试,如若你还想进一步的深入学习解读kafka以及源码,那么接下来的这份《手写“kafka”》将会是个不错的选择。
-
Kafka入门
-
为什么选择Kafka
-
Kafka的安装、管理和配置
-
Kafka的集群
-
第一个Kafka程序
-
Kafka的生产者
-
Kafka的消费者
-
深入理解Kafka
-
可靠的数据传递
-
Spring和Kafka的整合
-
SpringBoot和Kafka的整合
-
Kafka实战之削峰填谷
-
数据管道和流式处理(了解即可)


网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
式处理(了解即可)
[外链图片转存中…(img-Qce289Lq-1713064847786)]
[外链图片转存中…(img-wwqAuJt5-1713064847786)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)
[外链图片转存中…(img-rnZuadNs-1713064847787)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 831
831











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









