







Block(数据块)
每个磁盘都有默认的数据块大小,这是磁盘进行数据读/写的最小单位,HDFS同样也有块的概念,它是抽象的块,而非整个文件作为存储单元,在Hadoop3.x版本下,默认大小是128M,且备份3份,每个块尽可能地存储于不同的DataNode中。按块存储的好处主要是屏蔽了文件的大小,提供数据的容错性和可用性。Rack(机架)
Rack是用来存放部署Hadoop集群服务器的机架,不同机架之间的节点通过交换机通信,HDFS通过机架感知策略,使NameNode能够确定每个DataNode所属的机架ID,使用副本存放策略,来改进数据的可靠性、可用性和网络带宽的利用率。Metadata(元数据)
在 NameNode 内部是以元数据的形式,维护着两个文件,分别是FsImage镜像文件和EditLog日志文件。其中,FsImage镜像文件用于存储整个文件系统命名空间的信息,EditLog日志文件用于持久化记录文件系统元数据发生的变化。
当 NameNode启动的时候,FsImage 镜像文件就会被加载到内存中,然后对内存里的数据执行记录的操作,以确保内存所保留的数据处于最新的状态,这样就加快了元数据的读取和更新操作,但是这些操作非常消耗NameNode资源。于是HDFS文件系统引入了 EditLog 日志文件,该文件以追加方式记录内存中元数据的每一次变化,如果NameNode宕机,可以通过合并FsImage文件和Edits文件的方式恢复内存中存储的元数据。
注:EditLog和Edits是同一个东西。Edits是EditLog的文件名,它存储了EditLog的内容。
🕘 2.2 HDFS文件读写原理
🕤 2.2.1 HDFS写文件流程
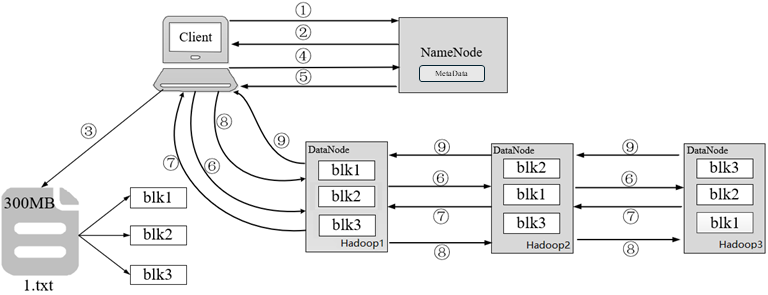
以300MB大小的1.txt文件为例,介绍HDFS写文件流程
- 客户端发起上传1.txt文件到指定目录的请求,通过RPC(远程过程调用)与NameNode建立通讯。
- NameNode检查元数据文件的系统目录树,即检查客户端是否有上传文件的权限,以及文件是否存在等。若系统目录树的父目录不存在该文件相关信息,返回客户端可以上传文件。
- 客户端根据分块策略对文件1.txt进行切分,形成3个Block,分别是blk1、blk2和blk3。
- 客户端向NameNode请求上传第一个Block,即blk1,以及数据块副本的数量。
- NameNode根据副本机制和机架感知向客户端返回可上传blk1的DataNode列表。
- 客户端从NameNode接收到blk1上传的DataNode列表,并与虚拟机建立管道(Pipeline)。
- Hadoop3向Hadoop2汇报管道建立成功,Hadoop2与Hadoop1汇报管道建立成功;Hadoop1与客户端汇报管道建立成功,客户端与所有DataNode列表中的所有DataNode都建立了管道。
- 客户端开始传输blk1,传输过程是以流式写入的方式实现。
1)将blk1写入到内存中进行缓存。
2)将blk1按照packet(默认为64K)为单位进行划分。
3)将第一个packet通过管道发送给Hadoop1。
4)Hadoop1接收完第一个packet之后,客户端会将第二个packet发送给Hadoop1,同时Hadoop1通过Pipeline将第一个packet发送给Hadoop2。
5)Hadoop2接收完第一个packet之后,Hadoop1会将第二个packet发送给Hadoop2,同时Hadoop2通过Pipeline将第一个packet发送给Hadoop3。
6)依次类推直至blk1上传完成。 - Hadoop3向Hadoop2发送blk1写入完成的信息,Hadoop2向Hadoop1发送blk1写入完成的信息,最后,Hadoop1向客户端发送blk1写入完成的信息。
注意:客户端成功上传blk1后,重复第4~9步的流程,依次上传blk2和blk3,最终完成1.txt文件的上传。
练习题:客户端上传文件的时候哪项是正确的?(多选)
A、数据经过 NameNode 传递给 DataNode
B、客户端端将文件切分为多个Block,依次上传
C、客户端只上传数据到一台 DataNode,然后由 NameNode 负责 Block 复制工作
D、客户端发起文件上传请求,通过RPC与NameNode建立通讯。
答案:BD
🕤 2.2.2 HDFS读文件流程
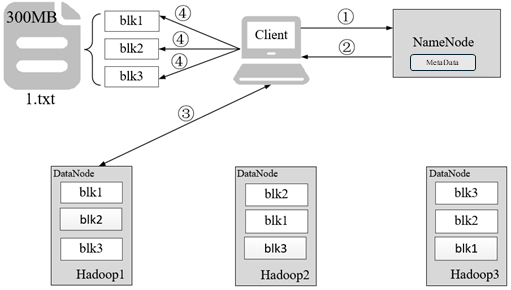
以300MB大小的1.txt文件为例,介绍HDFS读文件流程
- 客户端发起读取1.txt文件的请求,通过RPC与NameNode建立通讯。
- NameNode检查元数据文件的系统目录树,即检查客户端是否有读取文件的权限,以及文件是否存在等。
- 客户端按照就近原则从NameNode返回的Block列表读取Block。
- 客户端将读取所有的Block按照顺序进行合并,最终形成1.txt文件,需要注意的是,如果文件过大导致NameNode无法一次性文件的所有Block列表返回客户端时,会分批次将Block列表返回客户端。
🕒 3. HDFS的Shell操作
HDFS Shell类似于Linux操作系统中的Shell,都是一种命令语言,可以完成对HDFS上文件和目录的一系列操作。
在HDFS集群日常使用的过程时,主要是通过Client Commands类型的HDFS Shell子命令操作HDFS,Hadoop提供了多种Client Commands类型的HDFS Shell子命令,包括dfs、envvars、classpath等,dfs主要用于操作HDFS的文件和目录,也是最常用的HDFS Shell子命令。
-ls:查看指定路径的目录结构-du:统计目录下所有文件大小-mv:移动文件-cp:复制文件-rm:删除文件/空白文件夹-cat:查看文件内容-text:源文件输出为文本格式-mkdir:创建空白文件夹-put:上传文件-help:删除文件/空白文件夹

🕒 4. 使用Eclipse开发调试HDFS Java程序
Hadoop采用Java语言开发的,提供了Java API与HDFS进行交互。上面介绍的Shell命令,在执行时实际上会被系统转换成Java API调用。
为了提高程序编写和调试效率,我们采用Eclipse工具编写Java程序。
现在要执行的任务是:假设在目录“hdfs://localhost:9000/user/hadoop”下面有几个文件,分别是file1.txt、file2.txt、file3.txt、file4.abc和file5.abc,这里需要从该目录中过滤出所有后缀名不为“.abc”的文件,对过滤之后的文件进行读取,并将这些文件的内容合并到文件“hdfs://localhost:9000/user/hadoop/merge.txt”中。
🕘 4.1 安装Eclipse
在Ubuntu中打开Firefox直接下载
点击 “Download Packages”
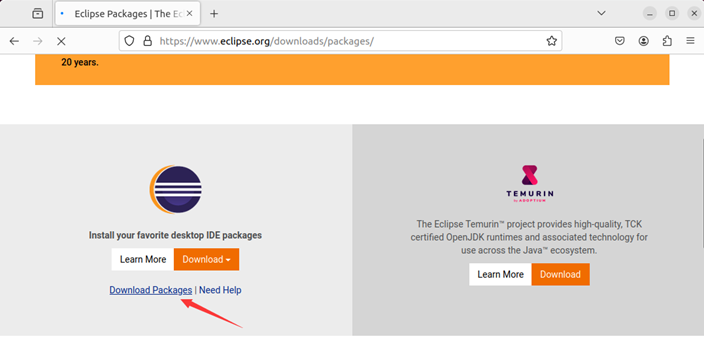
选择对应的操作系统下载
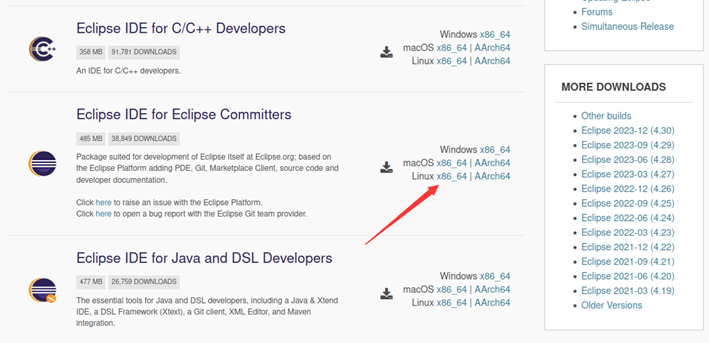
注意选择国内镜像,下载速度才快
下载完成
在“Downloads”文件夹中空白处右键,选择“在终端打开”,输入命令,解压eclipse到/opt目录下:
sudo tar -zxvf eclipse-committers-2023-12-R-linux-gtk-x86_64.tar.gz -C /opt
在Linux系统中设置Eclipse快捷方式
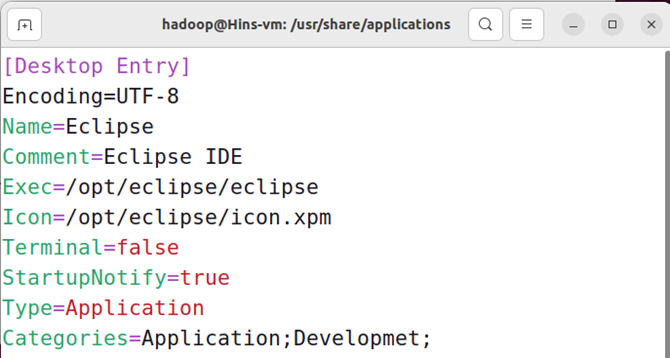
sudo vim /usr/share/applications/eclipse.desktop
向eclipse.desktop中添加以下内容:
[Desktop Entry]
Encoding=UTF-8
Name=Eclipse
Comment=Eclipse IDE
Exec=/opt/eclipse/eclipse
Icon=/opt/eclipse/icon.xpm
Terminal=false
StartupNotify=true
Type=Application
Categories=Application;Developmet;
给eclipse.desktop赋权
cd /usr/share/applications
sudo chmod u+x eclipse.desktop
找到/usr/share/applications/eclipse.desktop,鼠标右键选择复制,到桌面粘贴即可。
注:高版本Ubuntu会有权限检查,如报错需要右键图标,选择“允许运行”
之后双击快捷方式打开即可。
🕘 4.2 在Eclipse中创建项目
启动Eclipse。当Eclipse启动以后,会弹出如下图所示界面,提示设置工作空间(workspace)。
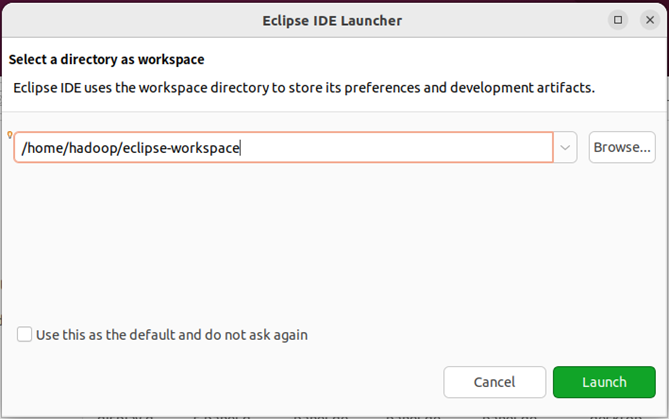
可以直接采用默认的设置“/home/hadoop/workspace”,点击“OK”按钮。可以看出,由于当前是采用hadoop用户登录了Linux系统,因此,默认的工作空间目录位于hadoop用户目录“/home/hadoop”下。
Eclipse启动以后,会呈现如下图所示的界面。

关闭welcome界面后,选择“File–>New–>Java Project”菜单,开始创建一个Java工程,会弹出如下图所示界面。
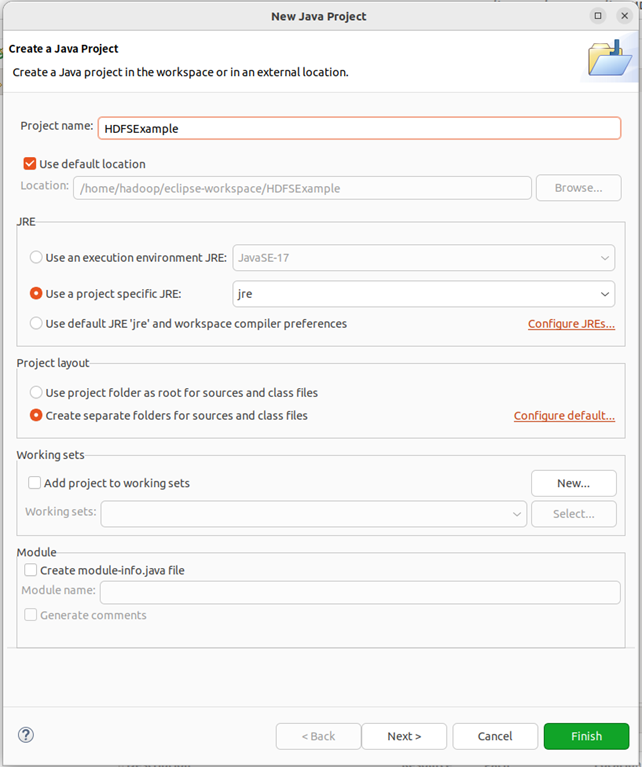
在“Project name”后面输入工程名称“HDFSExample”,选中“Use default location”,让这个Java工程的所有文件都保存到“/home/hadoop/workspace/HDFSExample”目录下。在“JRE”这个选项卡中,可以选择当前的Linux系统中已经安装好的JDK,比如jdk1.8.0_371。然后,点击界面底部的“Next>”按钮,进入下一步的设置。
🕘 4.3 为项目添加需要用到的JAR包
进入下一步的设置以后,会弹出如下图所示界面。
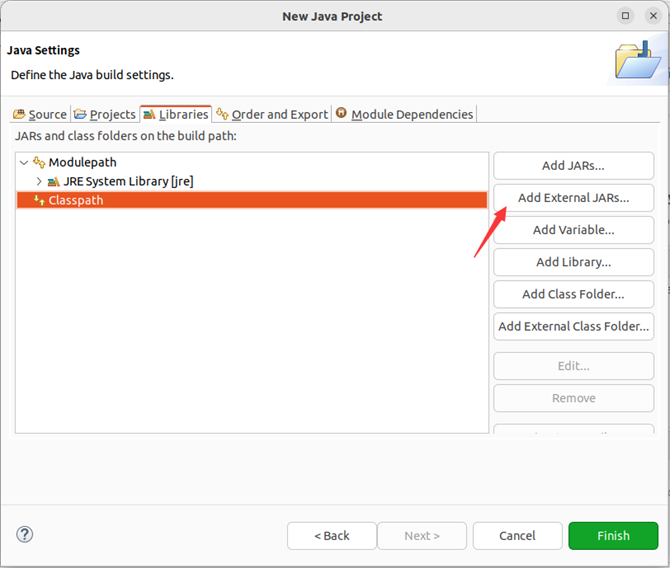
需要在这个界面中加载该Java工程所需要用到的JAR包,这些JAR包中包含了可以访问HDFS的Java API。这些JAR包都位于Linux系统的Hadoop安装目录下,对于本文而言,就是在“/usr/local/hadoop/share/hadoop”目录下。点击界面中的“Libraries”选项卡,然后,点击界面右侧的“Add External JARs…”按钮,会弹出如下图所示界面。
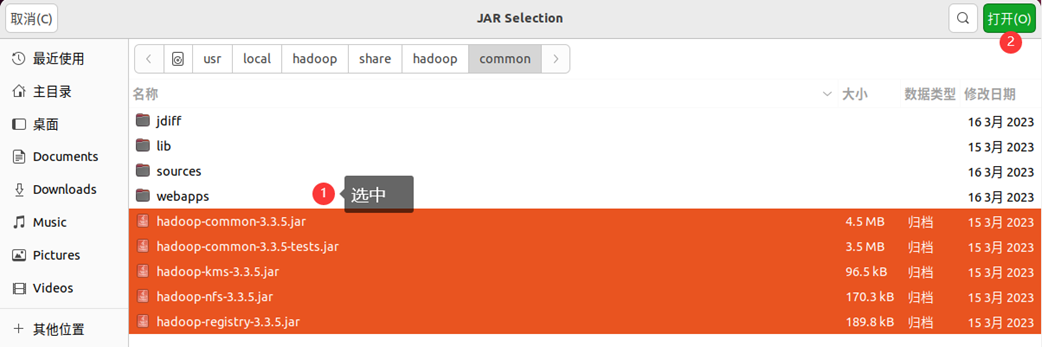
为了编写一个能够与HDFS交互的Java应用程序,一般需要向Java工程中添加以下JAR包:
(1)“/usr/local/hadoop/share/hadoop/common”目录下的所有JAR包,包括hadoop-common-3.3.5.jar、hadoop-common-3.3.5-tests.jar、haoop-nfs-3.3.5.jar、haoop-kms-3.3.5.jar和hadoop-registry-3.3.5.jar,注意,不包括目录jdiff、lib、sources和webapps;
(2)“/usr/local/hadoop/share/hadoop/common/lib”目录下的所有JAR包;
(3)“/usr/local/hadoop/share/hadoop/hdfs”目录下的所有JAR包,注意,不包括目录jdiff、lib、sources和webapps;
(4)“/usr/local/hadoop/share/hadoop/hdfs/lib”目录下的所有JAR包。
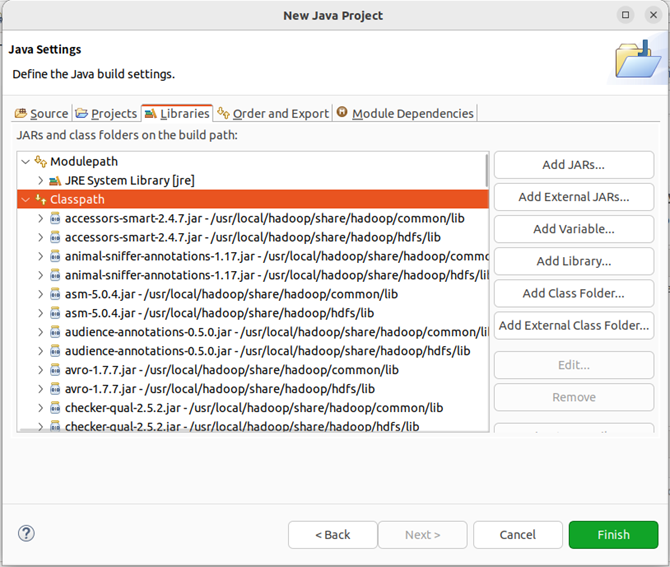
全部添加完毕以后,就可以点击界面右下角的“Finish”按钮,完成Java工程HDFSExample的创建。
🕘 4.4 编写Java应用程序
下面编写一个Java应用程序。
请在Eclipse工作界面左侧的“Package Explorer”面板中(如下图所示),找到刚才创建好的工程名称“HDFSExample”,然后在该工程名称上点击鼠标右键,在弹出的菜单中选择“New–>Class”菜单。
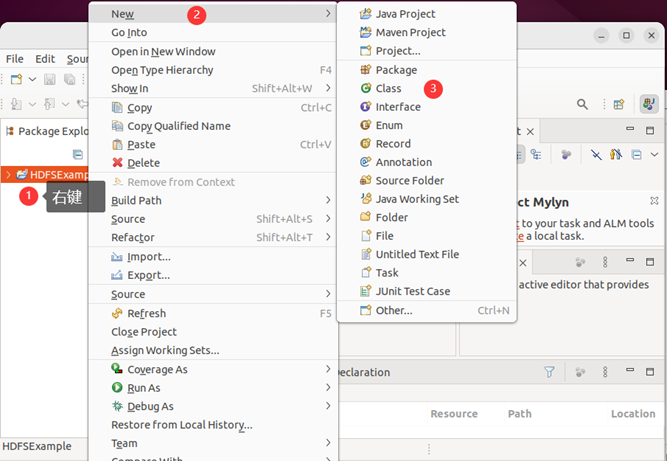
选择“New–>Class”菜单以后会出现如下图所示界面。
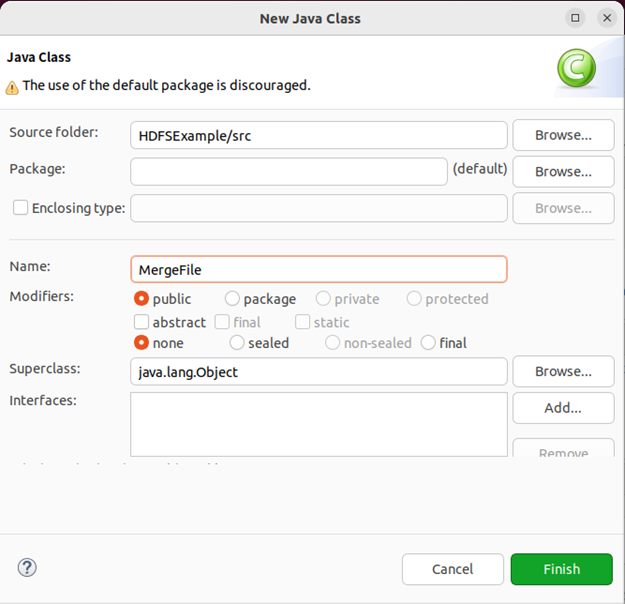
在该界面中,只需要在“Name”后面输入新建的Java类文件的名称,这里采用名称“MergeFile”,其他都可以采用默认设置,然后,点击界面右下角“Finish”按钮,Eclipse就自动创建了一个名为“MergeFile.java”的源代码文件,请在该文件中输入以下代码:
import java.io.IOException;
import java.io.PrintStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.\*;
/\*\*
\* 过滤掉文件名满足特定条件的文件
\*/
class MyPathFilter implements PathFilter {
String reg = null;
MyPathFilter(String reg) {
this.reg = reg;
}
public boolean accept(Path path) {
if (!(path.toString().matches(reg)))
return true;
return false;
}
}
/\*\*\*
\* 利用FSDataOutputStream和FSDataInputStream合并HDFS中的文件
\*/
public class MergeFile {
Path inputPath = null; //待合并的文件所在的目录的路径
Path outputPath = null; //输出文件的路径
public MergeFile(String input, String output) {
this.inputPath = new Path(input);
this.outputPath = new Path(output);
}
public void doMerge() throws IOException {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://localhost:9000");
conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fsSource = FileSystem.get(URI.create(inputPath.toString()), conf);
FileSystem fsDst = FileSystem.get(URI.create(outputPath.toString()), conf);
//下面过滤掉输入目录中后缀为.abc的文件
FileStatus[] sourceStatus = fsSource.listStatus(inputPath,
new MyPathFilter(".\*\\.abc"));
FSDataOutputStream fsdos = fsDst.create(outputPath);
PrintStream ps = new PrintStream(System.out);
//下面分别读取过滤之后的每个文件的内容,并输出到同一个文件中
for (FileStatus sta : sourceStatus) {
//下面打印后缀不为.abc的文件的路径、文件大小
System.out.print("路径:" + sta.getPath() + " 文件大小:" + sta.getLen()
+ " 权限:" + sta.getPermission() + " 内容:");
FSDataInputStream fsdis = fsSource.open(sta.getPath());
byte[] data = new byte[1024];
int read = -1;
while ((read = fsdis.read(data)) > 0) {
ps.write(data, 0, read);
fsdos.write(data, 0, read);
}
fsdis.close();
}
ps.close();
fsdos.close();
}
public static void main(String[] args) throws IOException {
MergeFile merge = new MergeFile(
"hdfs://localhost:9000/user/hadoop/",
"hdfs://localhost:9000/user/hadoop/merge.txt");
merge.doMerge();
}
}
🕘 4.5 编译运行程序
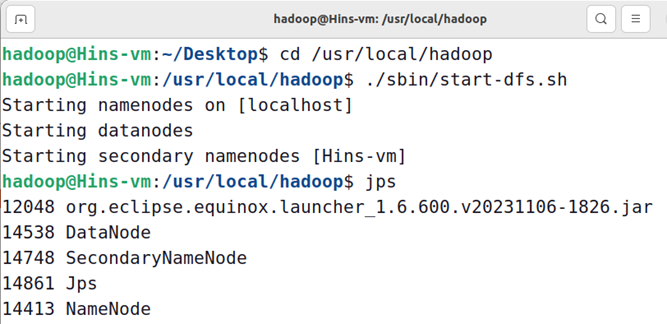
在开始编译运行程序之前,请一定确保Hadoop已经启动运行,如果还没有启动,需要打开一个Linux终端,输入以下命令启动Hadoop,并检查是否都正常启动:
cd /usr/local/hadoop
./sbin/start-dfs.sh
然后,要确保HDFS的“/user/hadoop”目录下已经存在file1.txt、file2.txt、file3.txt、file4.abc和file5.abc,每个文件里面有内容。这里,假设文件内容如下:
file1.txt的内容是:this is file1.txt
file2.txt的内容是:this is file2.txt
file3.txt的内容是:this is file3.txt
file4.abc的内容是:this is file4.abc
file5.abc的内容是:this is file5.abc
我们可以在Windows端创建好文件,之后通过Win端的浏览器上传
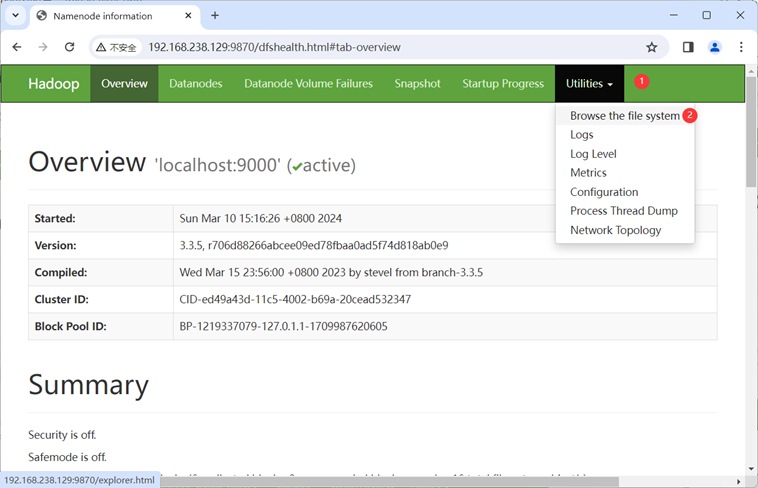
浏览器输入: http://[虚拟机IP]:9870/
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数大数据工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)

一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
转存中…(img-td9loSrF-1712996927839)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)
[外链图片转存中…(img-nPpvKvK1-1712996927839)]
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!














 797
797











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









