







Python爬出六部曲
第一步:安装requests库和BeautifulSoup库
在程序中两个库的书写是这样的:
import` `requests``from` `bs4 ``import` `BeautifulSoup
由于我使用的是pycharm进行的python编程。所以我就讲讲在pycharm上安装这两个库的方法。在主页面文件选项下,找到设置。进一步找到项目解释器。之后在所选框中,点击软件包上的+号就可以进行查询插件安装了。有过编译器插件安装的hxd估计会比较好入手。具体情况就如下图所示。
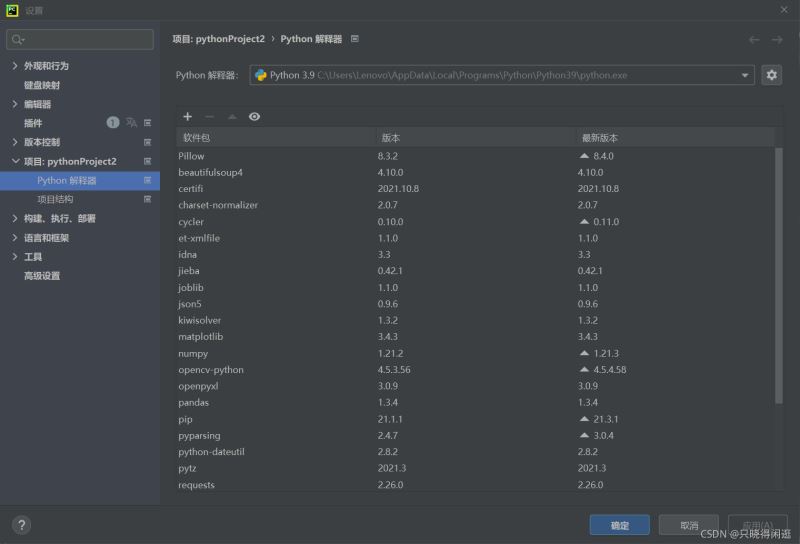
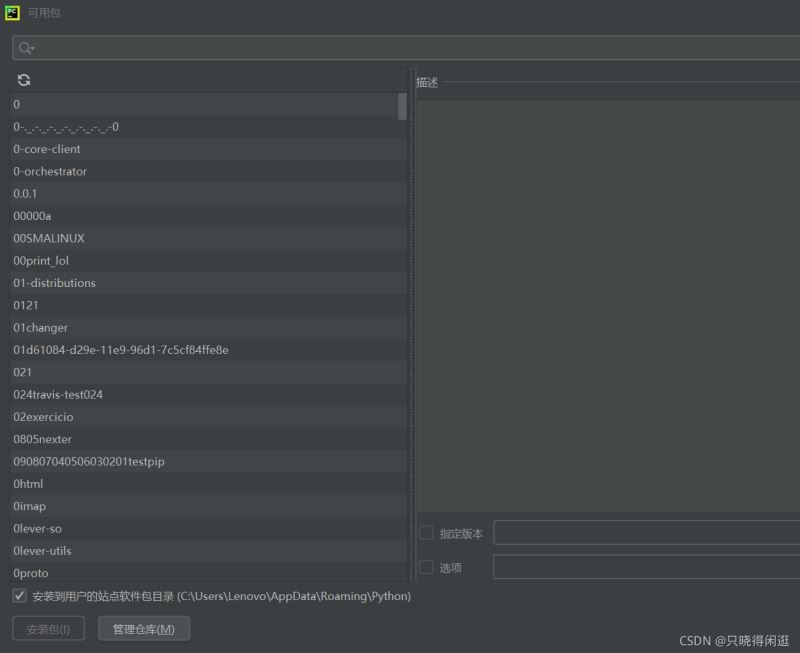
第二步:获取爬虫所需的header和cookie
我写了一个爬取微博热搜的爬虫程序,这里就直接以它为例吧。获取header和cookie是一个爬虫程序必须的,它直接决定了爬虫程序能不能准确的找到网页位置进行爬取。
首先进入微博热搜的页面,按下F12,就会出现网页的js语言设计部分。如下图所示。找到网页上的Network部分。然后按下ctrl+R刷新页面。如果,进行就有文件信息,就不用刷新了,当然刷新了也没啥问题。然后,我们浏览Name这部分,找到我们想要爬取的文件,鼠标右键,选择copy,复制下网页的URL。就如下图所示。
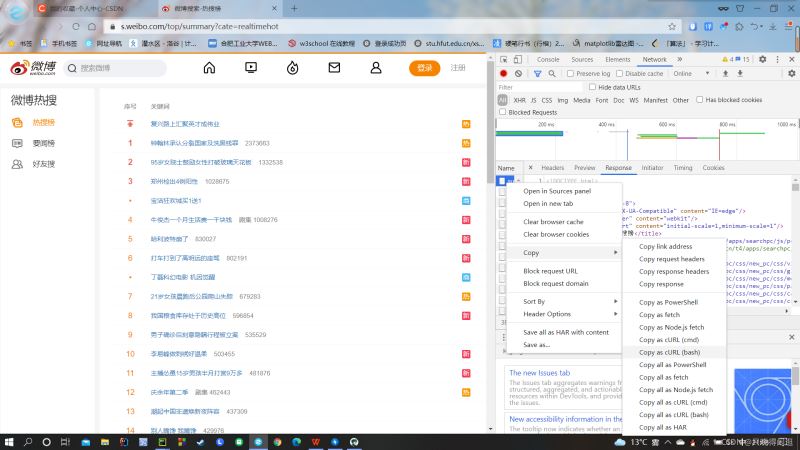
复制好URL后,我们就进入一个网页Convert curl commands to code。这个网页可以根据你复制的URL,自动生成header和cookie,如下图。生成的header和cookie,直接复制走就行,粘贴到程序中。
(1)Python所有方向的学习路线(新版)
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!














 276
276











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









