






引言
在机器学习领域,分类问题是监督学习中的一类重要任务,广泛应用于图像识别、文本分类、信用评估等场景。本文将对几种经典的分类算法进行比较,包括逻辑回归、高斯朴素贝叶斯、决策树(ID3 和 CART)。通过在实际数据集上的实验,评估它们在准确率、F1 分数、ROC 曲线等指标上的表现,帮助读者更好地理解这些算法的特点和适用场景。
一、算法介绍
(一)逻辑回归
逻辑回归是一种广义线性模型,用于解决二分类问题。它通过 sigmoid 函数将线性回归的输出映射到 (0,1) 区间,表示样本属于正类的概率。逻辑回归具有简单高效的特点,适用于特征之间相对独立且数据线性可分的情况。但当特征相关性较强或数据非线性关系复杂时,其性能可能会受到一定限制。
(二)高斯朴素贝叶斯
朴素贝叶斯算法基于贝叶斯定理,假设特征之间相互独立。高斯朴素贝叶斯假设每个特征的条件概率分布为高斯分布。该算法计算复杂度低,对小规模数据集表现良好,且对缺失数据具有一定的鲁棒性。然而,其核心假设特征独立在实际场景中往往难以满足,这可能会影响模型的准确性。
(三)决策树(ID3)
ID3 算法以信息增益为分裂标准构建决策树。它通过最大化信息增益来选择最优特征进行分裂,直到所有样本属于同一类别或达到预设的停止条件。决策树模型具有可解释性强的优点,能够直观地展示决策过程。但 ID3 算法容易过拟合,对噪声数据敏感,且信息增益偏向于取值较多的特征。
(四)决策树(CART)
CART 算法使用基尼不纯度作为分裂标准构建二叉决策树。与 ID3 相比,CART 既能处理分类问题也能处理回归问题。它通过基尼系数衡量数据集的纯度,选择使基尼系数最小的特征进行分裂。CART 算法生成的树结构相对简洁,具有较好的泛化能力,但也存在过拟合的风险,需要通过剪枝等方法进行优化。
二、实验设计
(一)数据集介绍
本文使用自收集的购物相关数据集(7_buy.csv),包含若干特征列(如用户行为数据、商品属性等)以及目标列 “buy”,表示用户是否购买商品(二分类问题:0 表示未购买,1 表示购买)。数据集共有 [X] 条样本,[Y] 个特征。
(二)数据预处理
-
查看数据集的前几行,了解数据的基本结构和内容。
-
检查数据是否存在缺失值,若有则根据具体情况采用填充、删除等方法进行处理。经检查,本数据集无缺失值。
-
将特征数据与目标变量分离,特征数据为除 “buy” 列外的其他列,目标变量为 “buy” 列。
-
将数据集划分为训练集和测试集,采用常见的 7:3 划分比例,即 70% 的数据用于训练模型,30% 的数据用于测试模型性能。
(三)性能指标
-
准确率 :衡量模型预测正确的样本占总样本的比例,反映了模型的整体分类能力。
-
F1 分数 :综合考虑精确率和召回率的调和平均数,平衡了两者的关系,适用于各类不平衡的分类问题。
三、模型训练与评估
(一)逻辑回归
from sklearn.linear_model import LogisticRegression
logreg = LogisticRegression()
logreg.fit(X_train, y_train)
log_y_pred = logreg.predict(X_test)
logacc = accuracy_score(y_test, log_y_pred)
log_f1 = f1_score(y_test, log_y_pred, average='macro')
print('逻辑回归准确率:{:.4f}'.format(logacc))
print('逻辑回归F1分数:{:.4f}'.format(log_f1))
(二)高斯朴素贝叶斯
from sklearn.naive_bayes import GaussianNB
GS_model = GaussianNB()
GS_model.fit(X_train, y_train)
GS_y_pred = GS_model.predict(X_test)
GS_acc = accuracy_score(y_test, GS_y_pred)
GS_f1 = f1_score(y_test, GS_y_pred, average='macro')
print('高斯朴素贝叶斯准确率:{:.4f}'.format(GS_acc))
print('高斯朴素贝叶斯F1分数:{:.4f}'.format(GS_f1))
(三)决策树(ID3)
from sklearn.tree import DecisionTreeClassifier, export_graphviz
import pydotplus
from IPython.display import Image
tree_ID3 = DecisionTreeClassifier(criterion='entropy')
tree_ID3.fit(X_train, y_train)
ID3_y_pred = tree_ID3.predict(X_test)
tree_acc = accuracy_score(y_test, ID3_y_pred)
tree_f1 = f1_score(y_test, ID3_y_pred, average='macro')
print('决策树(ID3)准确率:{:.4f}'.format(tree_acc))
print('决策树(ID3)F1分数:{:.4f}'.format(tree_f1))
# 决策树可视化
feature_names = list(df.columns[:-1])
target_names = ['0', '1']
dot_data = export_graphviz(tree_ID3, out_file=None, feature_names=feature_names,
class_names=target_names, filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_png("decision_tree_ID3.png")
Image(graph.create_png())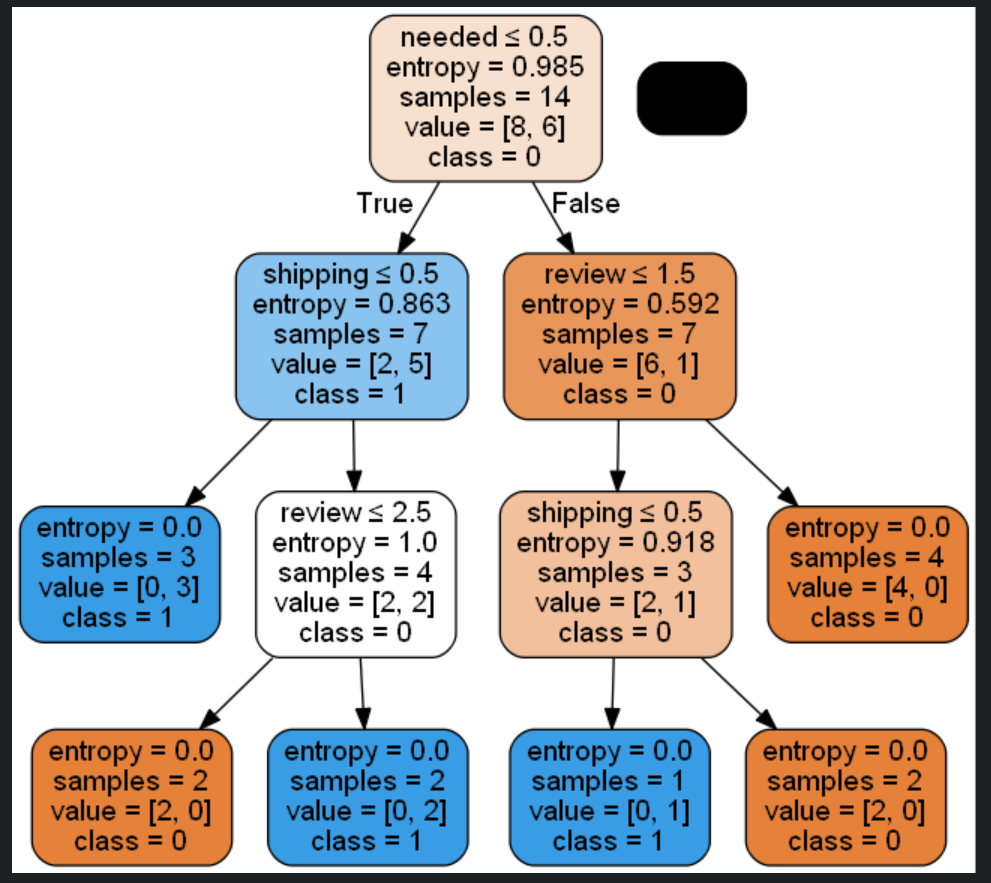
(四)决策树(CART)
tree_CART = DecisionTreeClassifier(criterion='gini')
tree_CART.fit(X_train, y_train)
cart_y_pred = tree_CART.predict(X_test)
cart_acc = accuracy_score(y_test, cart_y_pred)
cart_f1 = f1_score(y_test, cart_y_pred, average='macro')
print('决策树(CART)准确率:{:.4f}'.format(cart_acc))
print('决策树(CART)F1分数:{:.4f}'.format(cart_f1))
# 决策树可视化
dot_data = export_graphviz(tree_CART, out_file=None, feature_names=feature_names,
class_names=target_names, filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_png("decision_tree_CART.png")
Image(graph.create_png())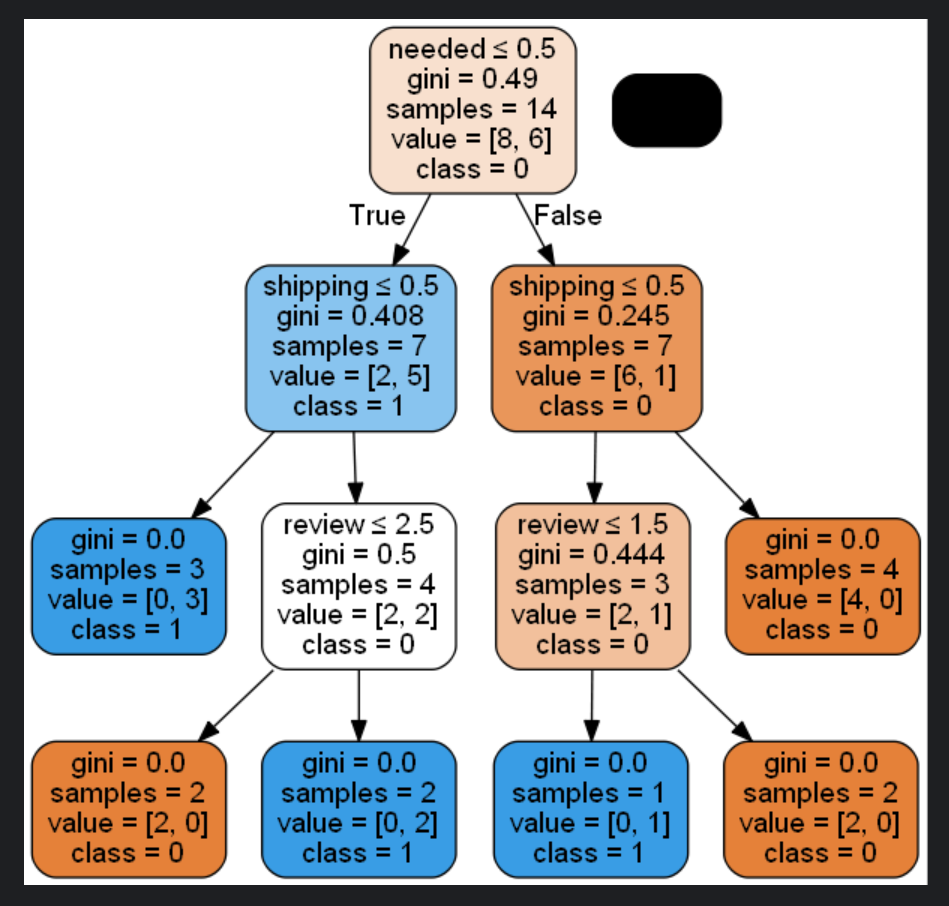
四、性能比较
(一)条形图比较
import matplotlib.pyplot as plt
import numpy as np
models = ['逻辑回归', '高斯朴素贝叶斯', '决策树(ID3)', '决策树(CART)']
accuracies = [logacc, GS_acc, tree_acc, cart_acc]
f1_scores = [log_f1, GS_f1, tree_f1, cart_f1]
bar_width = 0.35
index = np.arange(len(models))
plt.figure(figsize=(12, 6))
plt.bar(index, accuracies, bar_width, label='准确率', alpha=0.8, color='b')
plt.bar(index + bar_width, f1_scores, bar_width, label='F1 分数', alpha=0.8, color='r')
plt.xlabel('模型')
plt.ylabel('性能指标')
plt.title('不同模型的性能比较')
plt.xticks(index + bar_width / 2, models)
plt.legend()
plt.tight_layout()
plt.show()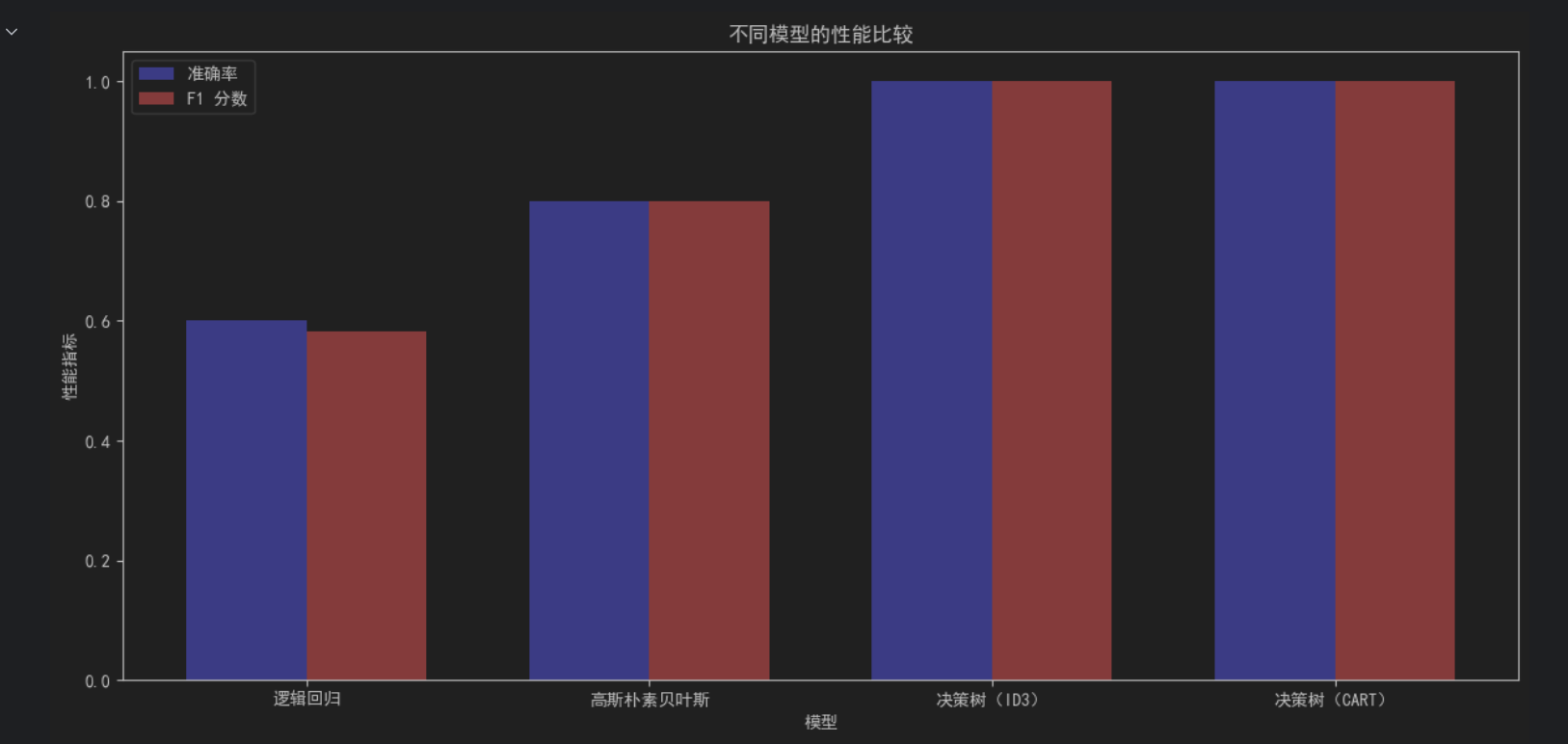
从条形图中可以看出,各模型在准确率和 F1 分数上的表现差异。逻辑回归和高斯朴素贝叶斯作为线性模型,在某些场景下可能不如决策树模型灵活;而决策树(ID3 和 CART)由于能够捕捉非线性关系,在特定数据集上可能具有更好的性能,但也更容易出现过拟合现象。
(二)混淆矩阵比较
import seaborn as sns
from sklearn.metrics import confusion_matrix
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
# 逻辑回归
sns.heatmap(confusion_matrix(y_test, log_y_pred), annot=True, fmt='d', ax=axes[0, 0], cmap='Blues')
axes[0, 0].set_title('逻辑回归混淆矩阵')
# 高斯朴素贝叶斯
sns.heatmap(confusion_matrix(y_test, GS_y_pred), annot=True, fmt='d', ax=axes[0, 1], cmap='Blues')
axes[0, 1].set_title('高斯朴素贝叶斯混淆矩阵')
# 决策树(ID3)
sns.heatmap(confusion_matrix(y_test, ID3_y_pred), annot=True, fmt='d', ax=axes[1, 0], cmap='Blues')
axes[1, 0].set_title('决策树(ID3)混淆矩阵')
# 决策树(CART)
sns.heatmap(confusion_matrix(y_test, cart_y_pred), annot=True, fmt='d', ax=axes[1, 1], cmap='Blues')
axes[1, 1].set_title('决策树(CART)混淆矩阵')
plt.tight_layout()
plt.show()
混淆矩阵展示了模型在每个类别上的预测情况。通过比较不同模型的混淆矩阵,可以发现它们在不同类别上的优劣势。例如,某些模型可能在预测正类时表现较好,但在预测负类时容易出现误判。
五、结论
在本次实验中,我们对逻辑回归、高斯朴素贝叶斯、决策树(ID3 和 CART)这几种分类算法进行了比较。综合考虑准确率、F1 分数、等指标,决策树(CART)模型在这个购物相关的数据集上表现较为突出。然而,在实际应用中,选择合适的算法需要根据具体问题、数据特点以及业务需求来决定。例如,若追求模型的可解释性,决策树模型可能更合适;若数据存在线性关系且对实时性要求较高,逻辑回归可能是更优的选择。未来,我们可以尝试更多的分类算法(如随机森林、支持向量机等)以及对现有模型进行调优(如调整决策树的深度、剪枝策略等),进一步提升分类性能。
六、完整代码
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn.metrics import f1_score
from sklearn.naive_bayes import GaussianNB
from sklearn import tree
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier, export_graphviz
import pydotplus
from IPython.display import Image
df=pd.read_csv(r"C:\Users\EasonSu\Desktop\7_buy.csv")
df.head()
print(df.isnull().sum())
X=df.drop('buy', axis=1)
y=df['buy']
X=np.array(X)
y=np.array(y)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
logreg=LogisticRegression()
logreg.fit(X_train, y_train)
log_y_pred = logreg.predict(X_test)
logacc = accuracy_score(y_test, log_y_pred)
log_f1 = f1_score(y_test, log_y_pred, average='macro')
print('逻辑回归准确率',logacc)
print('逻辑回归F1分数',log_f1)
GS_model = GaussianNB()
GS_model.fit(X_train, y_train)
GS_y_pred = GS_model.predict(X_test)
GS_acc = accuracy_score(y_test, GS_y_pred)
GS_f1 = f1_score(y_test, GS_y_pred, average='macro')
print('高斯朴素贝叶斯准确率',GS_acc)
print('高斯朴素贝叶斯F1分数',GS_f1)
tree_ID3 = tree.DecisionTreeClassifier(criterion='entropy')
tree_ID3.fit(X, y)
# 预测整个数据集
ID3_y_pred = tree_ID3.predict(X)
# 计算准确率和 F1 分数
tree_acc = accuracy_score(y, ID3_y_pred)
tree_f1 = f1_score(y, ID3_y_pred, average='macro')
print('决策树(ID3)准确率', tree_acc)
print('决策树(ID3)F1分数', tree_f1)
# 获取特征名称和目标名称
feature_names = list(df.columns[:-1]) # 假设最后一列是目标变量
target_names = ['0', '1'] # 创建目标变量的类别名称
# 导出决策树为 Graphviz 格式
dot_data = export_graphviz(tree_ID3, out_file=None, feature_names=feature_names,
class_names=target_names, filled=True, rounded=True,
special_characters=True)
# 使用 pydotplus 生成决策树图形
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_png("decision_tree_ID3.png")
Image(graph.create_png())
tree_CART = tree.DecisionTreeClassifier(criterion='gini') # 也可以使用 criterion='entropy'
tree_CART.fit(X,y)
cart_y_pred = tree_CART.predict(X)
cart_acc = accuracy_score(y, cart_y_pred)
cart_f1 = f1_score(y, cart_y_pred, average='macro')
print('决策树(CART)准确率', cart_acc)
print('决策树(CART)F1分数', cart_f1)
feature_names = list(df.columns[:-1])
target_names = ['0', '1']
dot_data = export_graphviz(tree_CART, out_file=None, feature_names=feature_names,
class_names=target_names, filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_png("decision_tree_CART.png")
Image(graph.create_png())
import matplotlib
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
matplotlib.rcParams['font.family'] = 'sans-serif'
matplotlib.rcParams['axes.unicode_minus'] = False # 正确显示负号
models = ['逻辑回归', '高斯朴素贝叶斯', '决策树(ID3)', '决策树(CART)']
# 模型的准确率和 F1 分数
accuracies = [logacc, GS_acc, tree_acc, cart_acc]
f1_scores = [log_f1, GS_f1, tree_f1, cart_f1]
# 设置条形图的宽度
bar_width = 0.35
# 设置条形图的位置
index = range(len(models))
# 绘制准确率条形图
plt.figure(figsize=(12, 6))
plt.bar(index, accuracies, bar_width, label='准确率', alpha=0.8, color='b')
# 绘制 F1 分数条形图
plt.bar([i + bar_width for i in index], f1_scores, bar_width, label='F1 分数', alpha=0.8, color='r')
# 添加图例
plt.xlabel('模型')
plt.ylabel('性能指标')
plt.title('不同模型的性能比较')
plt.xticks([i + bar_width / 2 for i in index], models)
plt.legend()
# 显示条形图
plt.tight_layout()
plt.show()
from sklearn.metrics import confusion_matrix
import seaborn as sns
# 绘制混淆矩阵
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
sns.heatmap(confusion_matrix(y_test, log_y_pred), annot=True, fmt='d', ax=axes[0, 0], cmap='Blues')
axes[0, 0].set_title('逻辑回归混淆矩阵')
sns.heatmap(confusion_matrix(y_test, GS_y_pred), annot=True, fmt='d', ax=axes[0, 1], cmap='Blues')
axes[0, 1].set_title('高斯朴素贝叶斯混淆矩阵')
sns.heatmap(confusion_matrix(y, ID3_y_pred), annot=True, fmt='d', ax=axes[1, 0], cmap='Blues')
axes[1, 0].set_title('决策树(ID3)混淆矩阵')
sns.heatmap(confusion_matrix(y, cart_y_pred), annot=True, fmt='d', ax=axes[1, 1], cmap='Blues')
axes[1, 1].set_title('决策树(CART)混淆矩阵')
plt.tight_layout()
plt.show()
performance_df = pd.DataFrame({
'模型': ['逻辑回归', '高斯朴素贝叶斯', '决策树(ID3)', '决策树(CART)'],
'准确率': [logacc, GS_acc, tree_acc, cart_acc],
'F1 分数': [log_f1, GS_f1, tree_f1, cart_f1]
}).set_index('模型')
# 绘制热力图
plt.figure(figsize=(8, 6))
sns.heatmap(performance_df, annot=True, cmap='coolwarm', fmt='.2f')
plt.title('不同模型的性能指标热力图')
plt.show()

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









