






| — | — |
| 命令 > 文件 | 将命令执行的标准输出结果重定向输出到指定的文件中,如果该文件已包含数据,会清空原有数据,再写入新数据。 |
| 命令 2> 文件 | 将命令执行的错误输出结果重定向到指定的文件中,如果该文件中已包含数据,会清空原有数据,再写入新数据。 |
| 命令 >> 文件 | 将命令执行的标准输出结果重定向输出到指定的文件中,如果该文件已包含数据,新数据将写入到原有内容的后面。 |
| 命令 2>> 文件 | 将命令执行的错误输出结果重定向到指定的文件中,如果该文件中已包含数据,新数据将写入到原有内容的后面。 |
| 命令 >> 文件 2>&1 或者 命令 &>> 文件 | 将标准输出或者错误输出写入到指定文件,如果该文件中已包含数据,新数据将写入到原有内容的后面。注意,第一种格式中,最后的 2>&1 是一体的,可以认为是固定写法。 |
【例 4】新建一个包含有 “Linux” 字符串的文本文件 Linux.txt,以及空文本文件 demo.txt,然后执行如下命令:
[root@localhost ~]# cat Linux.txt > demo.txt
[root@localhost ~]# cat demo.txt
Linux
[root@localhost ~]# cat Linux.txt > demo.txt
[root@localhost ~]# cat demo.txt
Linux <--这里的 Linux 是清空原有的 Linux 之后,写入的新的 Linux
[root@localhost ~]# cat Linux.txt >> demo.txt
[root@localhost ~]# cat demo.txt
Linux
Linux <--以追加的方式,新数据写入到原有数据之后
[root@localhost ~]# cat b.txt > demo.txt
cat: b.txt: No such file or directory <-- 错误输出信息依然输出到了显示器中
[root@localhost ~]# cat b.txt 2> demo.txt
[root@localhost ~]# cat demo.txt
cat: b.txt: No such file or directory <--清空文件,再将错误输出信息写入到该文件中
[root@localhost ~]# cat b.txt 2>> demo.txt
[root@localhost ~]# cat demo.txt
cat: b.txt: No such file or directory
cat: b.txt: No such file or directory <--追加写入错误输出信息
Linux grep命令详解:查找文件内容
很多时候,我们并不需要列出文件的全部内容,而是从文件中找到包含指定信息的那些行,要实现这个目的,可以使用 grep 命令。
grep 命令作为 Linux 文本处理三剑客的一员,另外两个是 sed 和 awk,它们会在后续章节中作详细介绍。
grep 命令的由来可以追溯到 UNIX 诞生的早期,在 UNIX 系统中,搜索的模式(patterns)被称为正则表达式(regular expressions),为了要彻底搜索一个文件,有的用户在要搜索的字符串前加上前缀 global(全面的),一旦找到相匹配的内容,用户就像将其输出(print)到屏幕上,而将这一系列的操作整合到一起就是 global regular expressions print,而这也就是 grep 命令的全称。
grep命令能够在一个或多个文件中,搜索某一特定的字符模式(也就是正则表达式),此模式可以是单一的字符、字符串、单词或句子。
正则表达式是描述一组字符串的一个模式,正则表达式的构成模仿了数学表达式,通过使用操作符将较小的表达式组合成一个新的表达式。正则表达式可以是一些纯文本文字,也可以是用来产生模式的一些特殊字符。为了进一步定义一个搜索模式,grep 命令支持如表 1 所示的这几种正则表达式的元字符(也就是通配符)。
| 通配符 | 功能 |
|---|---|
| c* | 将匹配 0 个(即空白)或多个字符 c(c 为任一字符)。 |
| . | 将匹配任何一个字符,且只能是一个字符。 |
| [xyz] | 匹配方括号中的任意一个字符。 |
| [^xyz] | 匹配除方括号中字符外的所有字符。 |
| ^ | 锁定行的开头。 |
| $ | 锁定行的结尾。 |
需要注意的是,在基本正则表达式中,如通配符 *、+、{、|、( 和 )等,已经失去了它们原本的含义,而若要恢复它们原本的含义,则要在之前添加反斜杠 \,如 *、+、{、|、( 和 )。
grep 命令是用来在每一个文件或中(或特定输出上)搜索特定的模式,当使用 grep 时,包含指定字符模式的每一行内容,都会被打印(显示)到屏幕上,但是使用 grep 命令并不改变文件中的内容。
grep 命令的基本格式如下:
[root@localhost ~]# grep [选项] 模式 文件名
这里的模式,要么是字符(串),要么是正则表达式。而此命令常用的选项以及各自的含义如表 2 所示。
| 选项 | 含义 |
|---|---|
| -c | 仅列出文件中包含模式的行数。 |
| -i | 忽略模式中的字母大小写。 |
| -l | 列出带有匹配行的文件名。 |
| -n | 在每一行的最前面列出行号。 |
| -v | 列出没有匹配模式的行。 |
| -w | 把表达式当做一个完整的单字符来搜寻,忽略那些部分匹配的行。 |
注意,如果是搜索多个文件,grep 命令的搜索结果只显示文件中发现匹配模式的文件名;而如果搜索单个文件,grep 命令的结果将显示每一个包含匹配模式的行。
【例 1】假设有一份 emp.data 员工清单,现在要搜索此文件,找出职位为 CLERK 的所有员工,则执行命令如下:
[root@localhost ~]# grep CLERK emp.data
#忽略输出内容
而在此基础上,如果只想知道职位为 CLERK 的员工的人数,可以使用“-c”选项,执行命令如下:
[root@localhost ~]# grep -c CLERK emp.data
#忽略输出内容
【例 2】搜索 emp.data 文件,使用正则表达式找出以 78 开头的数据行,执行命令如下:
[root@localhost ~]# grep ^78 emp.data
#忽略输出内容
grep 命令的功能非常强大,通过利用它的不同选项以及变化万千的正则表达式,可以获取任何我们所需要的信息。本节所介绍的 grep 命令,只介绍了它的一部分基础知识,比如说,grep 命令可用的选项还有很多,且用法也五花八门,不过对于初学者来说,本节所介绍的内容已经足以应付多数 Linux 系统的日常工作了。
正则表达式
2.1 认识正则
(1)介绍
正则表达式应用广泛,在绝大多数的编程语言都可以完美应用,在Linux中,也有着极大的用处。
使用正则表达式,可以有效的筛选出需要的文本,然后结合相应的支持的工具或语言,完成任务需求。
在本篇博客中,我们使用grep/egrep来完成对正则表达式的调用
(2)正则表达式类型
正则表达式可以使用正则表达式引擎实现,正则表达式引擎是解释正则表达式模式并使用这些模式匹配文本的基础软件。
在Linux中,常用的正则表达式有:
- POSIX 基本正则表达式(BRE)引擎
- POSIX 扩展正则表达式(BRE)引擎
2.2 基本正则表达式
2.2.1 匹配字符
(1)格式
- . 匹配任意单个字符,不能匹配空行
- [] 匹配指定范围内的任意单个字符
- [^] 取反
- [:alnum:] 或 [0-9a-zA-Z]
- [:alpha:] 或 [a-zA-Z]
- [:upper:] 或 [A-Z]
- [:lower:] 或 [a-z]
- [:blank:] 空白字符(空格和制表符)
- [:space:] 水平和垂直的空白字符(比[:blank:]包含的范围广)
- [:cntrl:] 不可打印的控制字符(退格、删除、警铃…)
- [:digit:] 十进制数字 或[0-9]
- [:xdigit:]十六进制数字
- [:graph:] 可打印的非空白字符
- [:print:] 可打印字符
- [:punct:] 标点符号
(2)演示
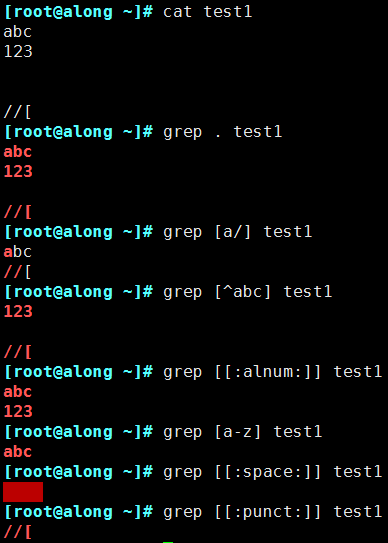
2.2.2 配置次数
(1)格式
- ***** 匹配前面的字符任意次,包括0次,贪婪模式:尽可能长的匹配
- .* 任意长度的任意字符,不包括0次
- ? 匹配其前面的字符0 或 1次
- + 匹配其前面的字符至少1次
- {n} 匹配前面的字符n次
- {m,n} 匹配前面的字符至少m 次,至多n次
- {,n} 匹配前面的字符至多n次
- {n,} 匹配前面的字符至少n次
(2)演示
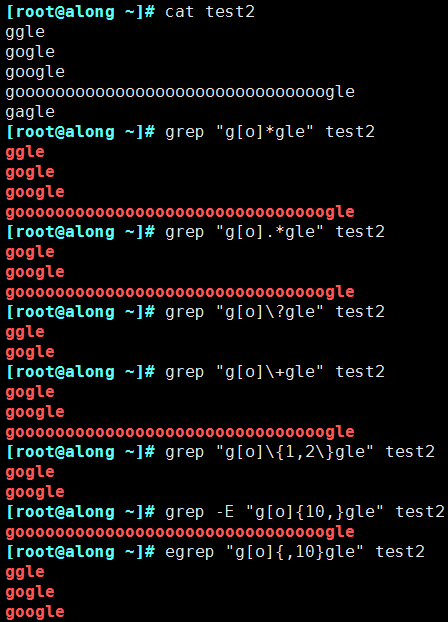
2.2.3 位置锚定:定位出现的位置
(1)格式
- ^ 行首锚定,用于模式的最左侧
- $ 行尾锚定,用于模式的最右侧
- ^PATTERN$,用于模式匹配整行
- ^$ 空行
- 1.*$ 空白行
- < 或 \b 词首锚定,用于单词模式的左侧
-
或 \b 词尾锚定;用于单词模式的右侧
(2)演示

2.2.4 分组和后向引用
(1)格式
① 分组:() 将一个或多个字符捆绑在一起,当作一个整体进行处理
分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这些变量的命名方式为: \1, \2, \3, …
② 后向引用
引用前面的分组括号中的模式所匹配字符,而非模式本身
1 表示从左侧起第一个左括号以及与之匹配右括号之间的模式所匹配到的字符
2 表示从左侧起第2个左括号以及与之匹配右括号之间的模式所匹配到的字符,以此类推
& 表示前面的分组中所有字符
③ 流程分析如下:
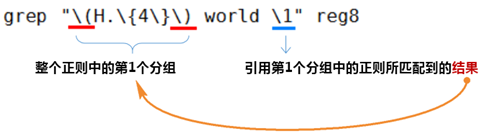
(2)演示
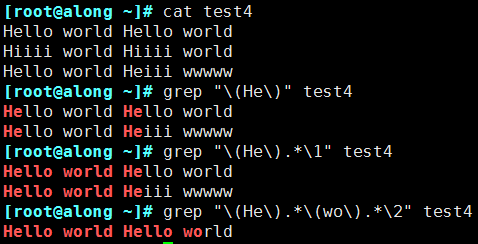
2.3 扩展正则表达式
(1)字符匹配:
- . 任意单个字符
- [] 指定范围的字符
- [^] 不在指定范围的字符
- 次数匹配:
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前在阿里
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上运维知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
中…(img-kA4cZXbb-1714150890162)]
[外链图片转存中…(img-CywYB2WU-1714150890162)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上运维知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新














 3084
3084











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









