







+ **内存计算:** Spark 采用内存计算方式,将数据存储在内存中,大大提高了数据处理速度,适合需要低延迟的实时数据处理需求。
+ **多种数据处理模式:** Spark 支持批处理、流处理、交互式查询、机器学习和图计算等多种数据处理模式,更加灵活。
+ **易用性:** Spark 提供了丰富的 API 支持,编程模型简单易懂,开发效率高。
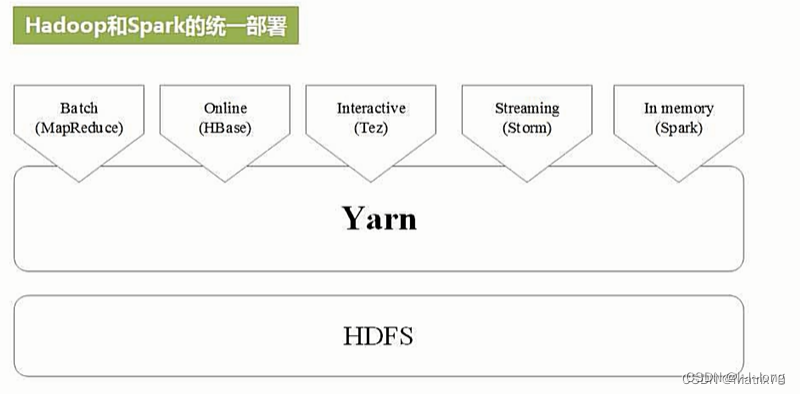
Spark 与 Hadoop 的统一部署: Spark 相对于 MapReduce 具有更高的性能、更灵活的数据处理模式、更简单易用的编程模型和更高效的资源管理。在实时数据处理、交互式查询和复杂数据处理任务中,Spark 更具优势。然而,MapReduce 在某些场景下仍然有其优势,如对于简单的批处理任务和对稳定性要求较高的任务。因此,根据具体需求和场景选择合适的框架是很重要的。因此许多企业在实际应用中通常采用统一部署的形式。Spark 与 Hadoop 可以统一部署在同一个集群中,实现共享资源和数据的优势。通过 YARN(Hadoop 的资源管理器)或者 Spark 自带的 Standalone 模式,可以在同一个集群上同时运行 Hadoop 和 Spark 作业。这种统一部署方式可以充分利用集群资源,减少资源的浪费,简化集群管理,并提高数据处理的整体性能。同时,Spark 可以直接读取 HDFS(Hadoop 分布式文件系统)中的数据,实现数据共享和互操作性。
1.3 Spark的编程语言——Scala
1.31为什么选择 Scala 作为 Spark 的编程语言?
-
Scala 是 JVM 语言:
- Scala 是一种运行在 Java 虚拟机(JVM)上的编程语言,与 Java 无缝集成。由于 Spark 本身就是用 Scala 编写的,因此选择 Scala 作为编程语言可以更好地与 Spark 内部代码集成,提高开发效率。
-
函数式编程支持:
- Scala 是一种支持函数式编程的语言,具有强大的函数式编程特性,如高阶函数、不可变性和模式匹配等。这些特性使得在 Spark 中进行数据处理更加简洁、高效和易于理解。
-
静态类型系统:
- Scala 是一种静态类型语言,可以在编译时捕获更多的错误,提高代码的可靠性和稳定性。在大规模的数据处理任务中,静态类型系统可以帮助开发人员更好地管理复杂性。
-
并发性能:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2427
2427











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









