






#个人记录#
注:若涉及到版权或隐私问题,请及时联系我删除即可。微信:qq2040772932
一、需要导入的库
导入库:
urllib -->pip install urllib3 urllib主要用于封装url和头部信息
re -->pip install re re主要用于正则表达式的分析
request -->pip install request request主要用于发送请求,主要用get和post方法
bs4 -->pip install bs4 bs4美名为(beautifulsoup漂亮的汤)主要用于
将标签分类,例如:
soup = BeautifulSoup(html, "html.parser")
soup.soup.find_all('div', class_="item")
说明:html中<div class="item">全部找出(我一般用re)
二、思维导图
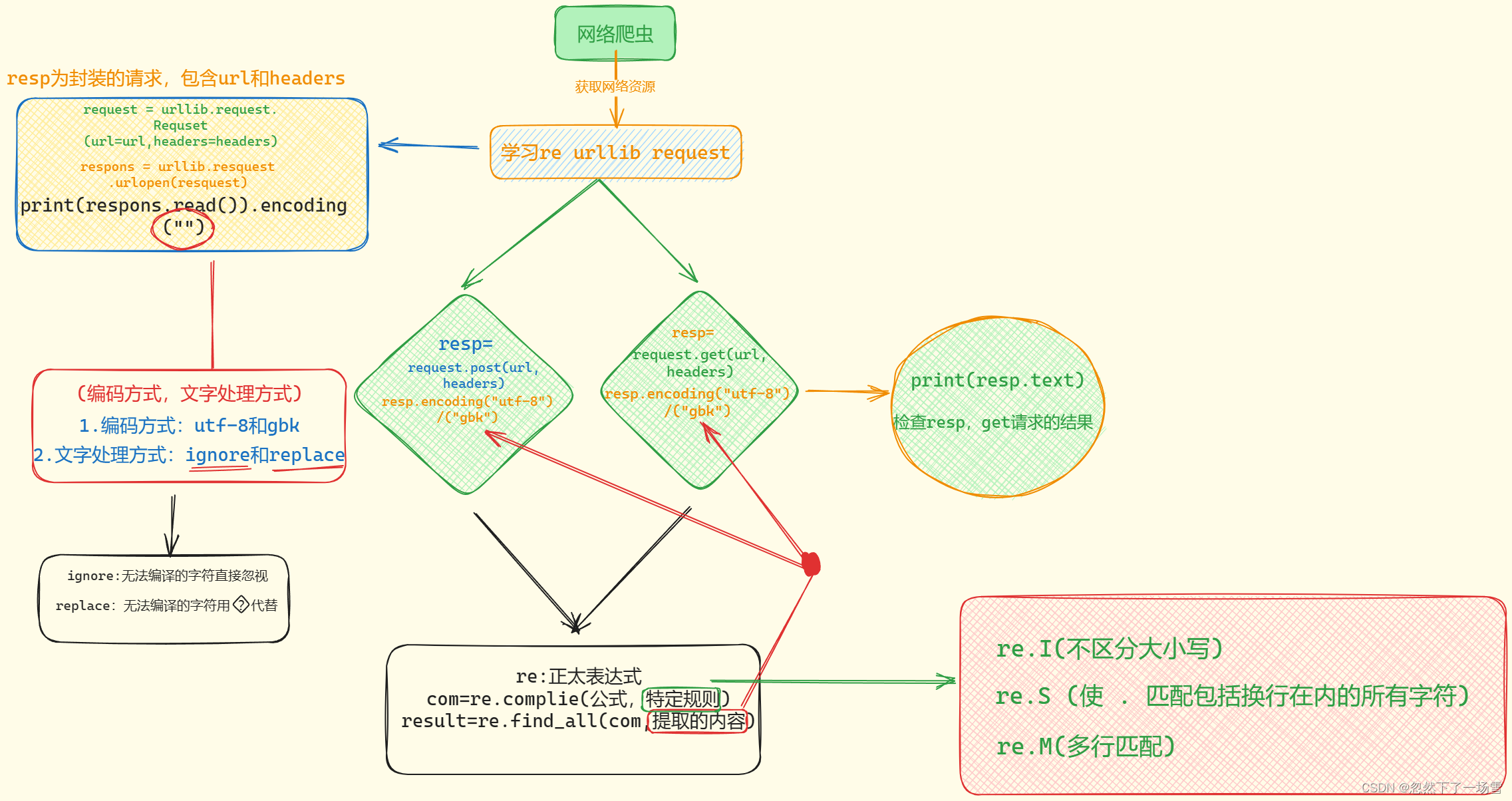
三、代码的演示(注释:此代码需要另行导入xlwt,用于爬取内容保存至xls文件)
1.豆瓣的爬取
跟着网上教程爬取豆瓣的爬行之路(由于本人过菜,虽然爬虫相对简单,但是对于知识把控并不灵活):
b站up主:IT私塾(普通话很标准,讲的很细,课程有点老,但是够用)

import urllib.request,urllib.error #urllib3中包括urllib,
#注释:不要创建urllib.py的包(别问问就是,心酸)
import re
import xlwt #这个是将爬取内容写入xls文件的,需要另行导入
from bs4 import BeautifulSoup
def main():
baseurl = "https://movie.douban.com/top250?start="
# 1.爬取网页
datalist = getData(baseurl)
savepath = "豆瓣电影Top.250.xls"
# 3.保存数据
saveData(savepath, datalist)
# askUrl("https://movie.douban.com/top250?start=0")
findLink = re.compile(r'<a href="(.*?)">') # 链接
findImage = re.compile(r'<img alt=".*src="(.*?)".*/>') # 图片
findTitle = re.compile(r'<span class="title">(.*)</span>') # 标题
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>') # #评分
findNum = re.compile(r'<span>(\d*?)人评价</span>') # 评价人数
findInfo = re.compile(r'<span class="inq">(.*)</span>') # 评价
findDd = re.compile(r'<p class="">(.*?)</p>', re.S) # 忽视换行服务 #相关信息
# 爬取网页
def getData(baseurl):
datalist = [] * 250
for i in range(0, 11):
url = baseurl + str(i * 25)
html = askUrl(url)
# 2.逐一解析数据
soup = BeautifulSoup(html, "html.parser")
for item in soup.find_all('div', class_="item"):
# print(item)
data = [] # 保存一部电影的所有信息
item = str(item)
link = re.findall(findLink, item)[0]
data.append(link) # 链接
image = re.findall(findImage, item)[0]
data.append(image) # 图片
title = re.findall(findTitle, item)[0]
if len(title) == 2: # 名称(中)
ctitle = title[0]
data.append(ctitle)
ctitle1 = title[1].replace("/", "")
data.append(ctitle1)
else:
data.append(title[0]) # 名称(外)
data.append(" ")
score = re.findall(findRating, item)[0]
data.append(score) # 评分
number = re.findall(findNum, item)[0]
data.append(number) # 评价人数
info = re.findall(findInfo, item)
if len(info) != 0: # 最佳评价
info[0].replace("。", "")
data.append(info)
else:
info = " "
data.append(info)
dd = re.findall(findDd, item)[0]
dd = re.sub('<br(\s+)>', " ", dd) # 相关内容
data.append(dd.strip()) # 去掉空格
datalist.append(data)
# for item in datalist:
# print(item)
return datalist
# 得到一个指定UEl的网页内容
def askUrl(url):
# 伪装头部
# 用户代理,告诉浏览器我们可以接受什么水平的文件
head1 = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0"}
request = urllib.request.Request(url, headers=head1)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
# print(html)
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
def saveData(savepath, datelist):
workbook = xlwt.Workbook(encoding="utf-8")
worksheet = workbook.add_sheet("豆瓣电影TOP250", cell_overwrite_ok=True) # cell_overwrite_ok=True覆盖之前的单元格
col = ("电影链接", "图片链接", "影片中文名", "影片外文名", "评分", "评价人数", "评价", "相关信息")
for i in range(0, 8):
worksheet.write(0, i, col[i]) # 列名
for i in range(0, 250):
print("第%d条" % i)
data = datelist[i]
for item in range(0, 8):
worksheet.write(i + 1, item, data[item])
workbook.save(savepath)
#中外名称获取有点瑕疵,懒得改了封了好多ip,403 forbidden
if __name__ == "__main__":
main()
ip被封解决方法:
1.刷新dns缓存
在控制台输入以下命令:ipconfig /flushdns并回车
ipconfig /flushdns2.换网
简单粗暴:User-Agent 需要重新获取一下
2.图片的爬取(需要导入os,用于写图片的文件夹,作用不是太大)
import requests
import re
import os
url = "https://pic.netbian.com/"
headers = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0"}
parr = re.compile('src="(/u.*?)".alt="(.*?)"') # 匹配图片链接和图片名字
path = "彼岸图网图片获取"
if not os.path.isdir(path): # 判断是否存在该文件夹,若不存在则创建
os.mkdir(path) # 创建
# 对列表进行遍历
p=1
for j in range(1,11):
if j == 1:
packbao = "https://pic.netbian.com/index.html"
response = requests.get(url=packbao, headers=headers)
response.encoding = response.apparent_encoding
image = re.findall(parr, response.text)
else:
packbao = "https://pic.netbian.com/index_%d.html"%j
response = requests.get(url=packbao,headers=headers)
response.encoding = response.apparent_encoding
image = re.findall(parr, response.text)
for i in image:
p=p+1
link = i[0] # 获取链接
name = i[1] # 获取名字
print(f"{p}:{name}{link}")
print(f"------------------------------第{j}页-------------------------------")
#
url1 = "https://pic.netbian.com"+link
img_data = requests.get(url=url1,headers=headers)
with open("./彼岸图网图片获取/%d"%p +".jpg","wb") as jpg:
jpg.write(img_data.content)
print("=========================图片爬取成功!!!!===============================")3.小说爬取
import requests
import re
baseurl = "https://www.qb5.ch"
url = "https://www.qb5.ch/book_90402/52236799.html"
num = 52236799
for num in range(num,num+2):
Url = baseurl + "/book_90402/%d.html"%num
headers = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0"}
resp = requests.get(Url,headers=headers)
resp.encoding="gbk"
obj = re.compile(r"神印王座II皓月当空</a> >(?P<name>.*?)</span>",re.S)
result = obj.search(resp.text)
html = result.group("name")
print("<h2>"+html+"</h2>")
obj1 = re.compile(r"最新章节!<br><br>(?P<content>.*)”<br /><br />")
result1 = obj1.search(resp.text)
html1 = result1.group("content").replace(" "," ").replace("<br /><br />",r'<br>').strip()
print(html1)
4.爬取需要账号登录的网页
b站up:bili_47436592216(2024年4月13日的新鲜视频,刚好被我看到)

import re
import requests
# data={
# "loginName":"15993036216",
# "password":"12346789z"
# }
# headers ={
# "User-Agent": "Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36"
# }
#
#
# session = requests.session()
#
# url = "https://passport.17k.com/ck/user/login"
#
# resp = session.post(url,data=data,headers=headers)
#
#
# print(resp.cookies)
resp = requests.get("https://user.17k.com/ck/author2/shelf?page=1&appKey=2406394919",headers={
"Cookie": "GUID=50573083-6297-4e19-b738-6878df8898f2; sajssdk_2015_cross_new_user=1; Hm_lvt_9793f42b498361373512340937deb2a0=1712996786; c_channel=0; c_csc=web; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2250573083-6297-4e19-b738-6878df8898f2%22%2C%22%24device_id%22%3A%2218ed6909e45862-0d308aa841ef69-393e5809-1821369-18ed6909e46827%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%2C%22first_id%22%3A%2250573083-6297-4e19-b738-6878df8898f2%22%7D; Hm_lpvt_9793f42b498361373512340937deb2a0=1713000448; acw_sc__v2=661a501b781d4b008028d75af5233eac37bfb37d; ssxmod_itna=eqUxRDcDBDuD0DA2=DzxLp2uPh3v+xPitoWqDl=GixA5D8D6DQeGTW2ztWKtoGeih0xwTeCeCGqD9eCAqWiF4ZDf1+DCPGnDBKqrqFbxiicDCeDIDWeDiDGR7D=xGY9Dm4i7DYqiODzwdyDGfBDYP9QqDg0qDBzrdDKqGg7kt6bmNYxGtKIkGx7qDMmeGXiGW57w2bNch4r2QVlqGuDG=/7qGmB4bDCh5Yi2DYAB3PAGxaQ0GrFbhrWGG+WAoeCIGqtrEbKxhztU+145DAW4w3FFD===; ssxmod_itna2=eqUxRDcDBDuD0DA2=DzxLp2uPh3v+xPitoD6ORQSD0yp403QYqRQ33D9G0RDsxThLsY4R4idKKeMYqGqKGDrtFtGOcicL0Rrikb7qA8PjiRcQqqjHRKG=4O6c2aMTYBRnxqVACyypq=Zfh66Gu3Ll4QLW7D67eoyjbjYquA/GgX3PjEQXjKYUnviXu6CGrryYBbaswUaxeaw7C90GeuriaLCwPf8Z=6xjS00YWdsoIHFCTgohmg8ucdT1=rwAt6+bMn4qpBidn5+Zol8PHdMfmCnL9u4PCR9x6y8vnDK/fIMdeu7MVdapX9ZX9Ade=iBEKtgv0iPQxK3aiqDh5po5aiKQI6nPS=4SpID+EkaqbSiyWR3Ff6ARehmi65mCftEYIB=mmLwWeqn+wGuigA/Bwtr2/lR+AA4AITEDTDG2F+qYDNiFQ70tq+HeF2fhax5xR3oZaHrPCn8WRpxY0brD7qq4iL8oddnStoo=mhqIYYIL/IGkoWOvexfSZRmq3rFlaxYQg4C7m3zVo53dohlqYPxD08DijFQhaQD3vqNVhgFSomqheS20FfjSfje3/8Wy4AQGjlgewwf7Go88ue81MgWsAkvaPYD; accessToken=avatarUrl%3Dhttps%253A%252F%252Fcdn.static.17k.com%252Fuser%252Favatar%252F10%252F30%252F57%252F103395730.jpg-88x88%253Fv%253D1712996886000%26id%3D103395730%26nickname%3DAnger_username%26e%3D1728552800%26s%3D145e93a338e9f65a; tfstk=fQZt9z_Z-6fMJUQ0fR_3uUxNcDBhKleas5yWmjcMlWFL3SKMjmmilxGKHCigh1PYDXNIs54gnWpav7KDj17ahnnmc_flqg2aImoAZ8YJBYAZnY81mfijdnSVIdClqg215Ao0d_X2kD2xRxiXCnGfppGEnEij1qOBRYGIGmibGXwIEAHXfhgsAet54tcBujtYYNJAW65vTUL8vv1qVRLWqAEiBch7CkxXc9MtWbwsT_XIAG0Q3qE23neYCzPqF5O16mwLbu3Qf6-YwWUSvvzFMEh8lR4rdu6DzXqKsSZtRTx-oDZoPcah810mXxNqzofybfwbUuzl4-Eu2-Gq5Jz9W9BpuEusKJkspzFeqNmopbXOoE8q-aMKZ9pJuEusLvhlKyL2u2b5"
})
resp.encoding = "utf-8"
print(resp.text)
print("----------------------------------------")
rr = re.compile(r'"introduction":"(?P<name>.*?)","bookClass"',re.S)
result = rr.search(resp.text)
html = result.group("name")
print(html)5.爬取游戏,也是我的目标,恰好我有账号(朋友的)
根据上面的基础上做的修改爬取的
import re
import requests
for j in range(1,250):
URL_res = "http://103.195.150.221:5678/?page=%d"%j
resp = requests.get(URL_res,headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0",
"Cookie": "====毕竟是朋友的不方便透露,如果需要我可以免费发给你,爬取的游戏===="
})
resp.encoding = "utf-8"
# print(resp.text)
print("-------------------------------------------------")
rr = re.compile(r'<a href="(?P<link>.*?)"><b>.*?</b>')
result = re.findall(rr,resp.text)
# print(result)
# print(result[0])
for i in result:
Link_child = "http://103.195.150.221:5678"+i
resp_child = requests.get(Link_child,headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0",
"Cookie": "think_lang=zh-cn; PHPSESSID=15925cee1792f97dff4f48f36758f8df"
})
resp_child.encoding = "utf-8"
# print(resp_child.text)
rr_child = re.compile(r'<p>(?P<name>.*?)</p><p>(?P<link1>.*?)</p><p>█')
print("------------------------------------------------")
res = rr_child.search(resp_child.text)
try:
result_childname = res.group("name").replace("</p><p>","<br>")
result_childlink = res.group("link1").replace("</p><p>","<br>")
print(result_childname,result_childlink)
except AttributeError as e:
print("第%d页,丢包*******************************"%j)
print("=================================%d=================================="%j)















 203
203











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









