







一直在想为什么sqlmap能成为一款优秀的工具?而我写的却不行?sqlmap究竟有什么特殊之处?今天探索发现带大家寻找sqlmap的一些神秘细节。
bigarray 大数组
当你使用dump命令导出数据的时候,有没有想过即使百万行数据sqlmap也可以导出来?从软件开发的思路来说,为了方便管理数据,会将数据存储在内存中,如果百万条数据存在内存中势必会导致内存爆炸,sqlmap如何处理?
sqlmap内部实现了bigarray模块lib/core/bigarray.py,具体原理是将内存数据存储为一个临时文件,要读取时在读取这个文件就行了。具体多大的数据会被缓存下来,sqlmap中有具体的定义BIGARRAY_CHUNK_SIZE

看着挺大,但单位是字节,一个简单的测试可以看到python中一个int占多大的内存(64位)
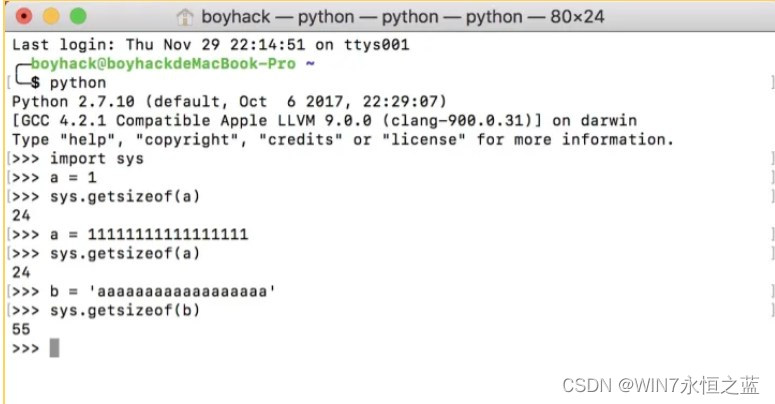
具体实现原理是,当bigarray存储的数据达到这个长度时,会将数据的内容pickle反序列化成文件,此时bigarray不再存储这些数据,存储这个临时文件名,当需要的时候通过文件名读取在映射到内存中。
HashDB
Hashdb实现在lib/utils/hashdb.py,用于存储注入时候的各种信息,主要是封装了sqlite3数据库,因为会在多线程中使用它,所以HashDB内部读写的时候封装了一层线程锁。
经常会有这样一个现象,第一次扫描完后,后面的扫描好像就很快的样子?主要就是它的作用了,它每次初始化的时候都会检查数据库是否保存有相关的信息,如果有,则直接调用,这样就直接获取了前面扫描时的信息,数据库信息,注入点位置等等。
主要读取哪些信息?可以搜索下_resumeHashDBValues这个函数,作用就是从数据库中恢复数据。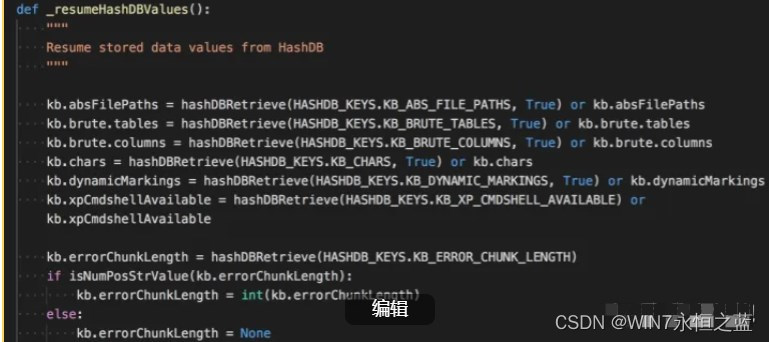
可以看到恢复的数据都赋值给了kb,kb是什么?这引起了我们下面的要说的。
属性字典
上文说道,Kb是什么意思?跳到lib/core/data.py 找到了kb原始的定义
# object to share within function and classes results
kb  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 399
399











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









