






目录
DataFrame概述
DataFrame的创建
创建DataFrame的两种基本方式:
•已存在的RDD调用toDF()方法转换得到DataFrame。
•通过Spark读取数据源直接创建DataFrame。
若使用SparkSession方式创建DataFrame,可以使用spark.read从不同类型的文件中加载数据创建DataFrame。spark.read的具体操作,在创建Dataframe之前,为了支持RDD转换成Dataframe及后续的SQL操作,需要导入import.spark.implicits._包启用隐式转换。若使用SparkSession方式创建Dataframe,可以使用spark.read操作,从不同类型的文件中加载数据创建DataFrame,具体操作API如表4-1所示。

1.数据准备
在HDFS文件系统中的/spark目录中有一个person.txt文件,内容如下:

2.通过文件直接创建DataFrame
我们通过Spark读取数据源的方式进行创建DataFrame
scala > val personDF = spark.read.text("/spark/person.txt")
personDF: org.apache.spark.sql.DataFrame = [value: String]
scala > personDF.printSchema()
root
|-- value: String (Nullable = true)

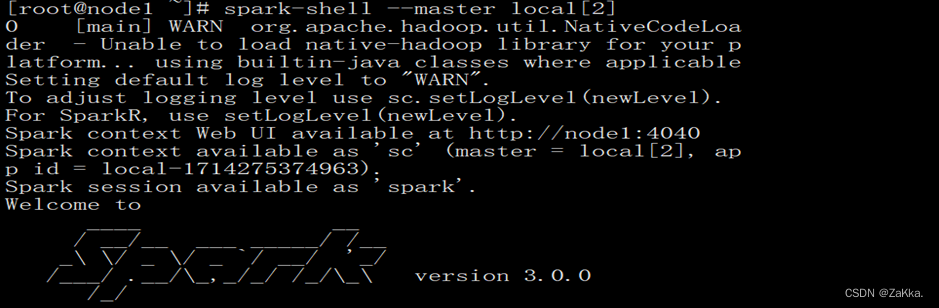

scala > val lineRDD = sc.textFile("/spark/person.txt").map(_.split(" "))
lineRDD: org.apache.spark.rdd.RDD[Array[String]] = MapPartitionsRDD[6] at map at <console>:24
scala > case class Person(id:Int,name:String,age:Int) defined class Person
scala > val personRDD = lineRDD.map(x => Person(x(0).toInt, x(1), x(2).toInt))
personRDD: org.apache.spark.rdd.RDD[Person] = MapPartitionsRDD[7] at map at <console>:27
scala > val personDF = personRDD.toDF()
personDF: org.apache.spark.sql.DataFrame = [id: int, name: string ... 1 more field]

DataFrame的常用操作
1. 操作DataFrame
操作DataFrame的常用方法,具体如下表如示。

Dataframe提供了两种谮法风格,即DSL风格语法和SQL风格语法,二者在功能上并无区别,仅仅是根据用户习惯自定义选择操作方式。接下来,我们通过两种语法风格,分讲解Dstaframe操作的具体方法。
一.DSL风格操作
DataFrame提供了一个领域特定语言(DSL)以方便操作结构化数据,下面将针对DSL操作风格,讲解DataFrame
常用操作示例,
1.show():查看DataFrame中的具体内容信息
2.pritSchema0:查看0staFrame的Schema信息
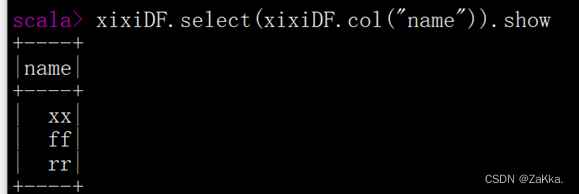
3.select():查看DataFmame中造取部分列的数据,
下面演示查看xixiDF对象的name字段数据,具体代码如下所示
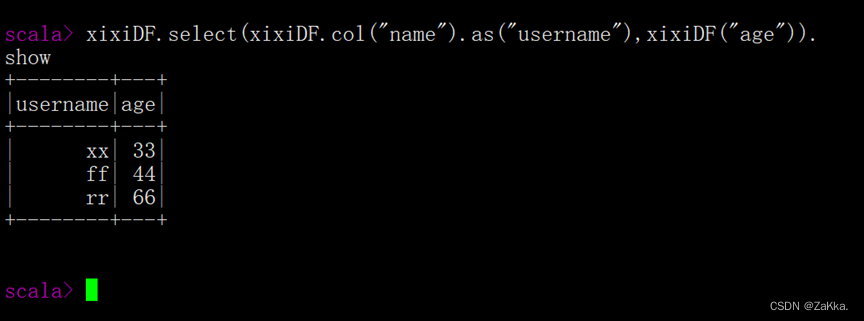
select实现对列名进行重命名
filter()/where条件查询
•要求过滤age 大于44等于44的数据
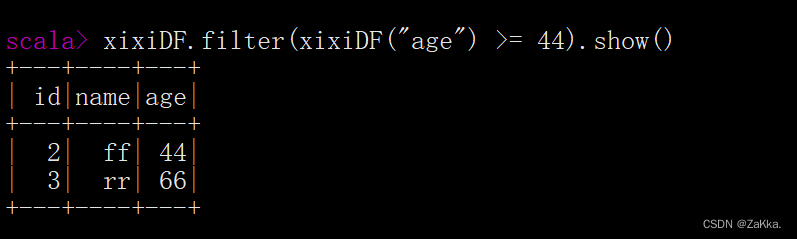
groupBy()对数据进行分组

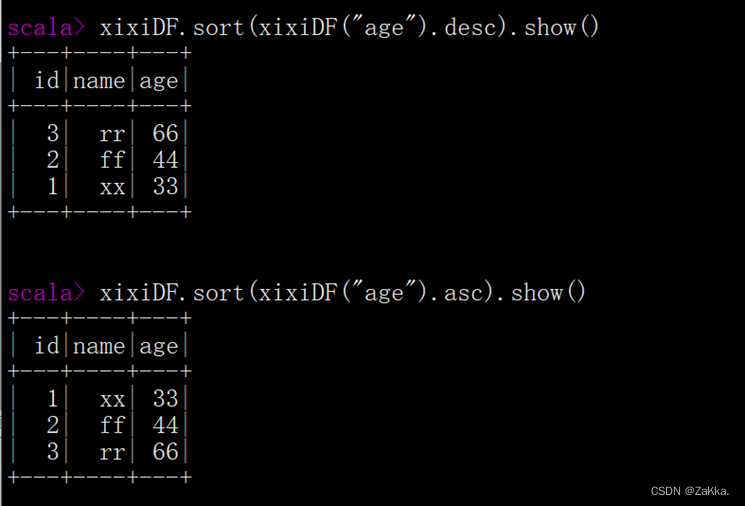
sort()/orderBy():对特定字段进行排序
desc:降序;asc:升序
2. SQL风格操作DataFrame
1. 将DataFrame注册成一个临时表

2. 查询年龄最大的前两名人的信息
scala > spark.sql("select * from t_xixi order by age desc limit 2").show()
+---+------+---+
| id| name|age|
+---+------+---+
| 6| jerry| 40|
| 5|tianqi| 35|
+---+------+---+
3. 查询年龄大于25的人的信息
scala > spark.sql("select * from t_xixi where age > 25").show()
+---+-------+---+
| id | name |age|
+---+-------+---+
| 2 | lisi | 29 |
| 4 | zhaoliu| 30 |
| 5 | tianqi | 35 |
| 6 | jerry | 40 |
+---+-------+---+
Dataset概述
RDD、DataFrame及Dataset的区别
•RDD数据的表现形式,即序号(1),此时RDD数据没有数据类型和元数据信息。
•DataFrame数据的表现形式,即序号(2),此时DataFrame数据中添加Schema元数据信息(列名和数据类型,如ID:String),DataFrame每行类型固定为Row类型,每列的值无法直接访问,只有通过解析才能获取各个字段的值。
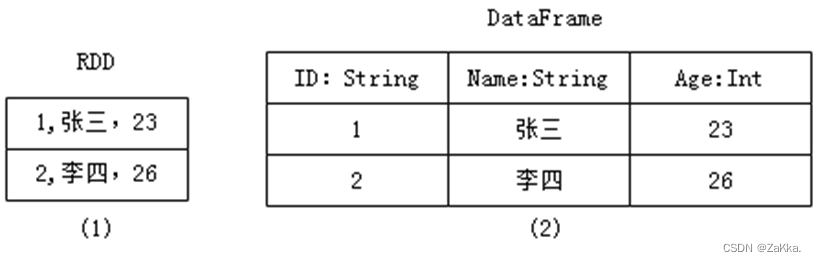
Dataset数据的表现形式,序号(3)和(4),其中序号(3)是在RDD每行数据的基础之上,添加一个数据类型(value:String)作为Schema元数据信息。而序号(4)每行数据添加People强数据类型,在Dataset[Person]中里存放了3个字段和属性,Dataset每行数据类型可自定义,一旦定义后,就具有错误检查机制。

Dataset对象的创建
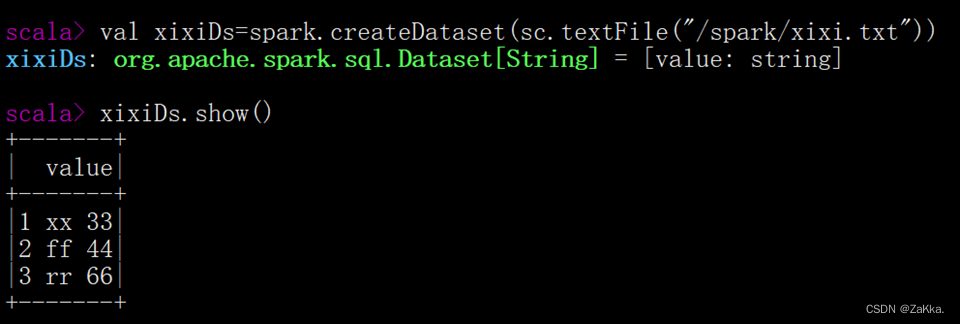
1、通过SparkSession中的createDataset来创建Dataset
2、DataFrame通过“as[ElementType]”方法转换得到Dataset

RDD转换DataFrame
•Spark官方提供了两种方法实现从RDD转换得到DataFrame。
•第一种方法是利用反射机制来推断包含特定类型对象的Schema,这种方式适用于对已知数据结构的RDD转换
•第二种方法通过编程接口构造一个Schema,并将其应用在已知的RDD数据中。
反射机制推断Schema
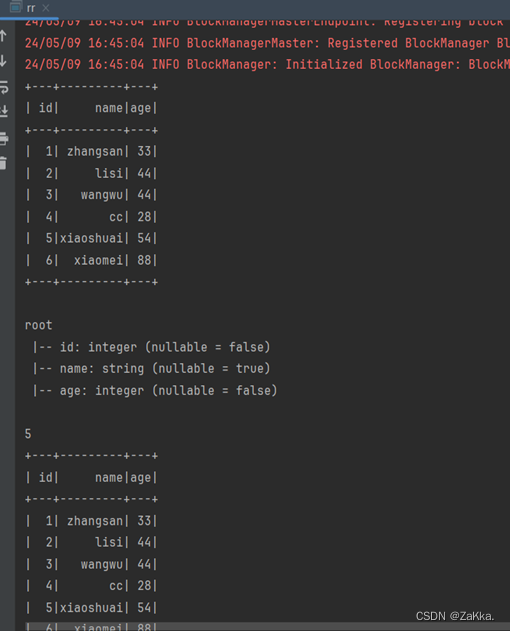
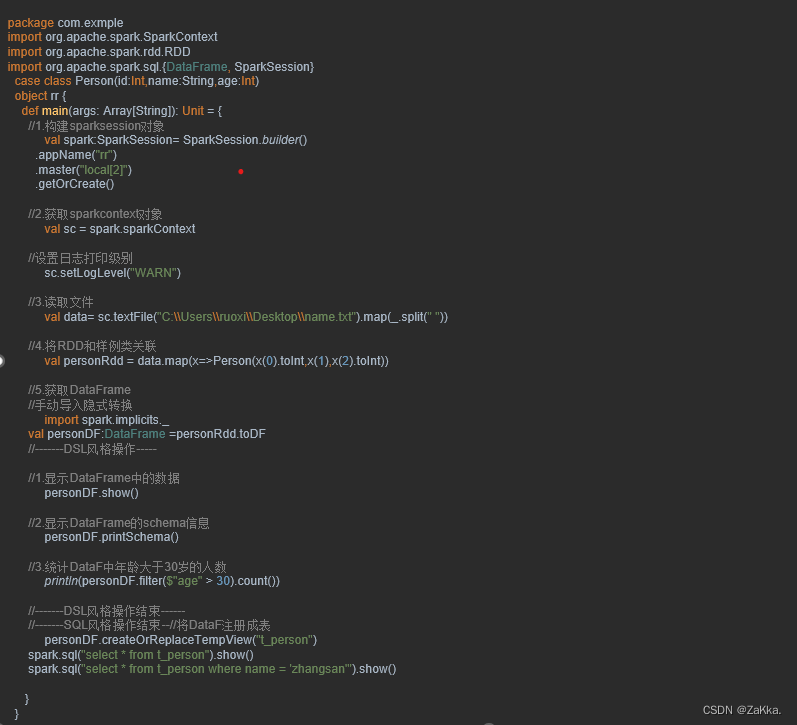
Windows系统开发Scala代码,可使用本地环境测试(需要先准备本地数据文件)。我们可以很容易的分析出当前数据文件中字段的信息,但计算机无法直观感受字段的实际含义,因此需要通过反射机制来推断包含特定类型对象的Schema信息,实现将RDD转换成DataFrame。

反射机制推断Schema
•1.创建Maven工程。
•拉依赖

•效果
编程方式定义Schema
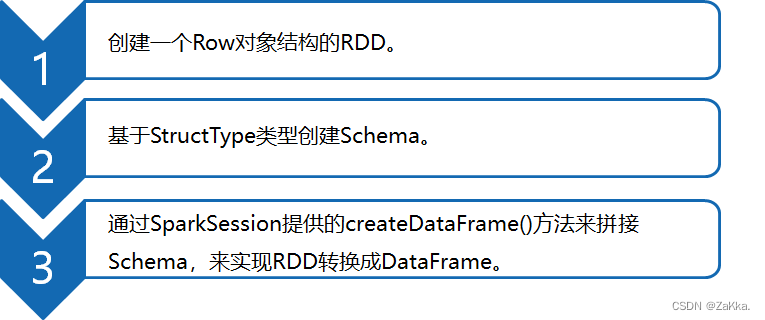
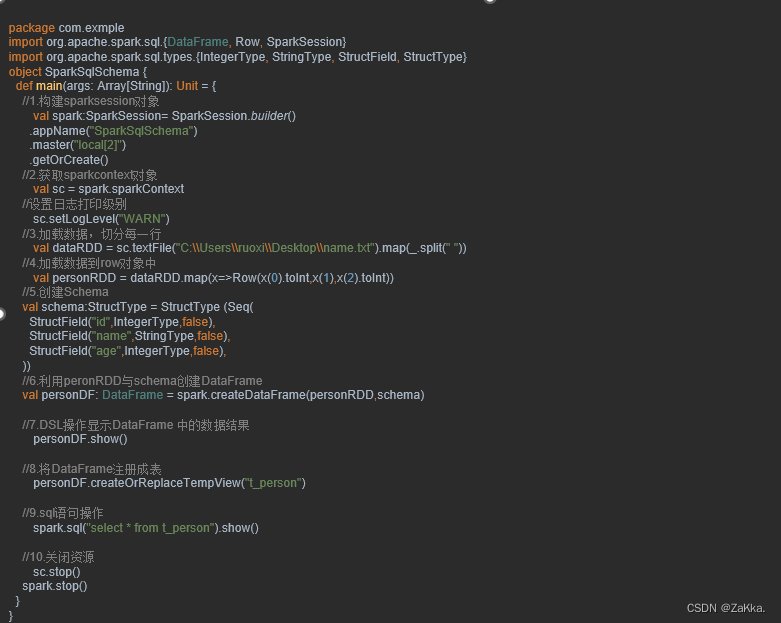
当Case类不能提前定义Schema时,就需要采用编程方式定义Schema信息,实现RDD转换DataFrame的功能。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









