







前言
本篇文章旨在介绍作者在学习Tensorflow图像识别时,自己搜寻数据并根据课本代码改编的图像识别模型。本模型基于VGG16模型进行迁移训练,是一次较为简单的学习项目,某种意义上来说可以看作是猫狗大战的升级版(笑)。
在构建本次项目前,应先确保电脑中有Anaconda和任意pythonIDE,且安装我们所必须的库。关于Anaconda及PythonIDE程序的安装,请参阅其他文章。
在构建按本次项目前,建议构建虚拟环境并启用GPU计算,否则计算时间可能会非常久。关于虚拟环境的搭建和Windows环境下的GPU计算,请参阅作者之前的文章:总结:成功在Windows11系统上启用Tensorflow的gpu计算,或其他相关文章。
作者当前的操作系统为Windows11,Python版本为3.9.21,Tensorflow版本为2.9.0。
本篇文章会提供数据文件、训练完成的Keras模型文件和带有注释的ipynb程序源代码文件。
一、数据简介
本次项目数据共有10049张交通载具图片,十种不同的交通载具分别为:自行车bke、公交车bus、小轿车car、电动摩托车ebk、摩托车mbk、大型卡车mtk、小型卡车stk、越野车suv、三轮车tbk和面包车van,每种数据都放在一个单独的文件夹中,数据文件夹目录结构大致如下:
data/
|--train/
| |--bke/
| |--bus/
| |--car/
| ...
|--test/
| |--no_labels/
| |--with_labels/
| |--bke/
| ...
|--valid/
|--bke/
...在全部数据集中,7200个数据用于训练集,1800个数据用于验证集,1049个数据用于测试集。
二、代码构建
在VScode或Jupyter Noterbook中创建一个新的ipynb文件,该文件最好和数据文件夹在同一个文件夹下。然后引入下列我们所需要的Python代码库:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import os
import random
import cv2 as cv
import time如果没有对应库可以使用pip进行安装:
pip install __库名__验证一下我们的tf版本和是否启用gpu计算:(cpu也可以计算,但可能会很慢。)
# 验证tf版本和是否启用gpu计算
print(tf.__version__)
print(tf.config.list_physical_devices("GPU"))如果gpu计算正常,输出结果应该如下:
2.9.0
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')](可选)训练前数据查看
定义一个查看数据的check_image()函数,用于直观化查看部分数据:
# 查看数据
def check_image(file_dir):
# 类型列表,存放每个种类的文件夹名
type_list = os.listdir(file_dir)
# 存放图像文件名的列表
image_filename = []
for type in type_list:
# 获取每个类型对应的文件夹路径
type_dir = os.path.join(file_dir, type)
# 将该路径下的每个数据添加到图像文件名的列表中
image_filename += os.listdir(type_dir)
# 查看训练集内的数据数量
print(f"训练集数据数量:{len(image_filename)}")
# 存放图像数据的列表
image_list = []
# 随机输出十张图像,因此循环十次
for num in range(10):
# 随机选取一个类型
type = random.choice(type_list)
# 获取该类型文件夹的路径
type_path = os.path.join(file_dir, type)
# 在该类型文件夹下随机获取一张图片
image_path = os.path.join(type_path, random.choice(os.listdir(type_path)))
# 使用cv读取图像,并转换为RGB格式
image = cv.imread(image_path, cv.COLOR_BGR2RGB)
# 将该图像和其对应类型添加到存放图像数据的列表中
image_list.append([image, type])
# 使用plt输出图像
p = 1
for img in image_list:
# 输出格式为2X5矩阵
fig = plt.subplot(2, 5, p)
# 将该图像的类型设置为其标题
fig.set_title(img[1])
# 输出图像
fig.imshow(img[0])
# 删除坐标轴
fig.axis("off")
p += 1
# 输出最终图像
plt.show()运行函数check_image():
check_image("./data/train/")得到结果如下:

1.获取训练数据并增强
使用tf自带的图像数据处理器tf.keras.preprocessing.image.ImageDataGenerator()生成训练所需的训练集数据和验证集数据,并对训练集数据进行数据增强。
# 对训练集中的数据进行数据增强
TRAIN_DIR = "./data/train/"
# 创建一个训练数据生成器
train_data_gen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale = 1./255, # 将图像中的像素值归一化到[0,1]范围之间
rotation_range = 20, # 随机旋转的角度
shear_range = 0.2, # 随机剪切的范围
zoom_range = 0.2, # 随机缩放的范围
horizontal_flip=True, # 水平翻转图像
fill_mode = 'nearest' # 边缘填充设置为“最近填充”
)
# 用测试数据生成器生成训练数据
train_generator = train_data_gen.flow_from_directory(
TRAIN_DIR, # 测试集数据路径
target_size=(256,384), # 调整图像的尺寸为(256,384)
class_mode="categorical" # 将图像标签自动转换为one_hot模式
)
# 对验证集中的数据进行归一化处理
VALID_DIR = "./data/valid/"
# 创建一个验证数据生成器
valid_data_gen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale = 1./255
)
# 用验证数据生成器生成验证数据
valid_generator = valid_data_gen.flow_from_directory(
VALID_DIR,
target_size=(256,384),
class_mode="categorical"
)输出结果如下:

由于我们在生成数据时选择了“categorical”,tf自动帮我们把各个数据进行了独热编码。
可以使用plt随意查看一张训练数据中的图像:
# 查看一张训练数据图像
plt.imshow(train_generator[0][0][0])输出结果如下:

关于为什么使用(256,384),长宽比2:1的尺寸图像,作者在构建模型时认为交通载具的三维模型多为长方体,因此认为采用长方形的图像能够更好的保留图像特征。但作者没有使用正方形图像进行训练与之对比。如果想要验证图像长宽比例是否会对图像识别的准确率造成影响,欢迎自行实验,还可以在评论区分享(^__^)。
2.模型构建和获取
使用tf中自带的vgg16模型进行迁移训练。这样既可以减小我们模型构建的复杂度,也可以加快训练速度,减轻电脑压力。编写模型构建函数实现模型的构建:
# 模型构建
def vgg16_model(input_shape=(256,384,3)):
# 读取tf自带的vgg16进行迁移训练
vgg16 = tf.keras.applications.vgg16.VGG16(
include_top = False, # 不要原模型中的顶层
weights='imagenet', # 使用在ImageNet上预训练好的权重,可以加快我们模型的训练速度
input_shape=input_shape # 指定输入数据的形状
)
# 冻结vgg16模型内各层的权重
for layers in vgg16.layers:
layers.trainable = False
# vgg16模型的输出层
last = vgg16.output
# 构建我们自己的全连接层
x = tf.keras.layers.Flatten()(last) # 展平图像
x = tf.keras.layers.Dense(512, activation="relu")(x) # 512个神经元,使用relu激活函数
x = tf.keras.layers.Dropout(0.2)(x) # 随机抛弃0.2个神经元,防止过拟合
x = tf.keras.layers.Dense(128, activation="relu")(x) # 128个神经元,使用relu激活函数
x = tf.keras.layers.Dropout(0.2)(x) # 同上一个Dropout层
x = tf.keras.layers.Dense(32, activation="relu")(x) # 32个神经元,使用relu激活函数
x = tf.keras.layers.Dense(10, activation="softmax")(x) # 输出层,10个输出种类,使用softmax激活函数
# 完整构建模型
model = tf.keras.models.Model(inputs=vgg16.input, outputs=x)
return model再构建一个获取模型的函数,以便于未来读取已经训练的模型权重,实现断点续训功能:
# 获取模型
def get_model(filename=''):
if len(filename) != 0: # 如果输入了模型文件
try:
model = tf.keras.models.load_model(filename) # 读取已存在的模型文件
print("模型加载成功!")
return model
except:
print("输入的模型文件不存在!")
model = vgg16_model()
print("新模型建立成功!")
return model
else:
model = vgg16_model() # 构建新的模型
print("新模型建立成功!")
return model由于我们是第一次训练,因此直接创建一个新的模型。但我们还是创建一个模型存储路径的变量,在构建回调函数时有用。
# 存储模型的路径
model_file_path = "./model/model.keras"
model = get_model()输出结果如下:
新模型建立成功!如果有已存在的模型文件,输入模型文件路径实现断点续训:
model = get_model(model_file_path)输出结果如下:
模型加载成功!3.模型编译、回调和训练
接下来进行模型编译和回调函数的设置:
# 模型编译
model.compile(
optimizer="adam", # 使用Adam优化器
loss="categorical_crossentropy",# 使用categorical_crossentropy损失函数
metrics=["accuracy"] # 设置准确率为模型评估指标
)
# 设置回调函数
callbacks = [
tf.keras.callbacks.ModelCheckpoint(filepath=model_file_path, # 存储模型的路径
verbose=1, # 设置日志输出的详细程度
save_freq="epoch", # 设置每次训练完成都检查是否需要保存
save_best_only=True), # 只保存损失最小模型
tf.keras.callbacks.EarlyStopping(monitor="val_loss",# 监控验证集损失函数值
patience=5) # 耐心值为5,如果连续五次损失值函数未得到改善则停止训练
]
编写模型训练函数:
# 模型训练函数
def train_model(train_epochs, do_train=False):
if do_train:
# 记录训练耗时
start = time.time()
# 训练记录
train_history = model.fit(train_generator, # 训练数据
epochs=train_epochs, # 训练总轮次
validation_data = valid_generator, # 验证数据
verbose=1, # 输出日志
callbacks=callbacks # 回调函数
)
# 计算总时间
end = time.time()
used_time = int(end - start)
hour = used_time // 3600
minute = (used_time % 3600) // 60
second = used_time - (hour * 3600) - (minute * 60)
print(f"""设定训练轮次:{train_epochs}\n
实际训练轮次:{len(train_history.epoch)}\n
总使用时间:{hour}时{minute}分{second}秒""")
return train_history设置训练次数并训练模型,由于我们有保存机制所以可以不用设立太大的训练次数,这里我选择20:
# 训练模型
train_history = train_model(train_epochs=20, do_train=True)输出结果如下:

4.预测与可视化训练结果
定义一个可视化函数,让我们能够直观化查看损失值和准确值的变化:
# 定义可视化函数查看训练数据
def show_train(train_history, output=False):
train_metric = ["loss", "accuracy"]
valid_metric = ["val_loss", "val_accuracy"]
# 如果输出
if output:
for i in range(1,3):
fig = plt.subplot(2, 1, i)
fig.plot(train_history.history[train_metric[i-1]]) # 训练集的损失/准确值
fig.plot(train_history.history[valid_metric[i-1]]) # 验证集的损失/准确值
fig.set_title(train_metric[i-1]) # 设立标题
fig.set_ylabel(train_metric[i-1]) # 命名y轴
labels = [str(epoch) for epoch in train_history.epoch] # 设置x轴数值
fig.set_xticks(ticks=train_history.epoch, labels=labels) # 设置x轴为正整数
fig.set_xlabel("epochs") # 命名x轴
fig.legend(["train", "validation"], loc="upper left") # 两个函数的命名,放置在左上角
plt.subplots_adjust(hspace=0.5) # 损失图和准确图之间的间隔
plt.show()运行该函数来查看数据:
show_train(train_history, output=True)输出结果如下: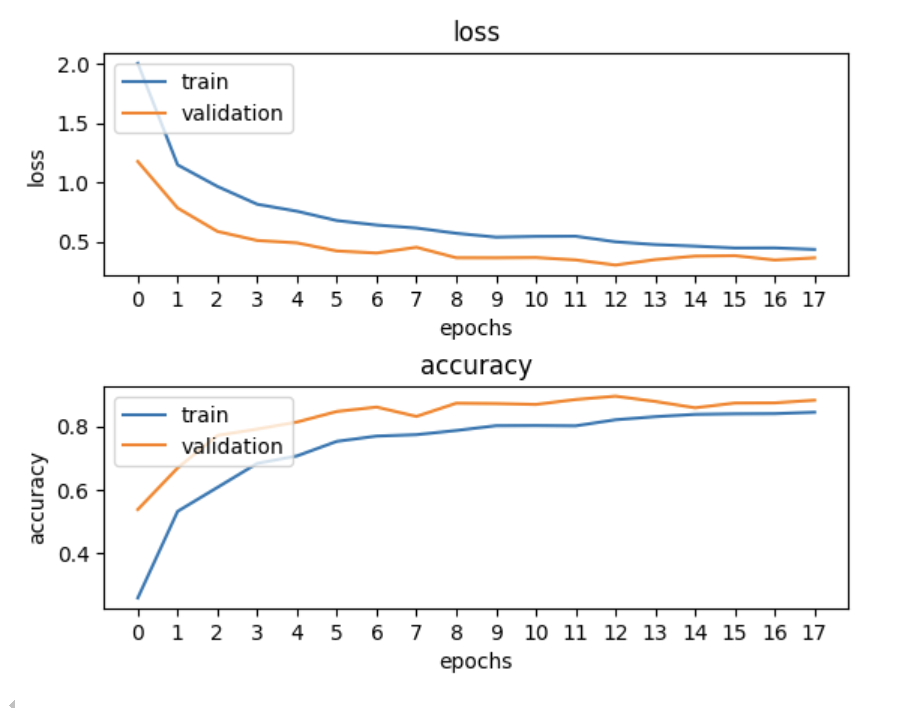
此时模型的训练部分就已经全部完成,接下来是测试和预测。
用带有标签的测试集图像数据生成测试数据:
# 生成测试数据
TEST_DIR = "./data/test/with-labels/"
# 测试数据生成器
test_data_gen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255)
test_generator = test_data_gen.flow_from_directory(TEST_DIR, target_size=(256, 384), class_mode="categorical")再使用evaluate方法执行测试:
test_loss, test_acc = model.evaluate(test_generator, verbose=1)输出结果如下:
![]()
可以看到使用测试数据集进行测试的准确值为0.8599.
为了方便观察,可以编写可视化函数实现直观化预测结果。
首先编写读取测试数据集中的无标签数据函数:
# 读取无标签测试数据
def read_test_image(path, start, finish, image_size):
test_files = os.listdir(path)
test_images = []
# 只读取从start到finish之间的图像
for file_name in test_files[start:finish]:
image_file_name = path + file_name
# 用preprocessing()读取图像并改变形状
img = tf.keras.preprocessing.image.load_img(image_file_name, target_size=image_size)
# 转换为数组形式
img_array = tf.keras.preprocessing.image.img_to_array(img)
test_images.append(img_array)
# 将保存了读取图像的列表转换为数组形式
test_data = np.array(test_images)
# 归一化处理
test_data /= 255.0
print(f"从图像{start}到图像{finish}")
print(f"测试集数据形状为:{test_data.shape}")
return test_data然后再编写输出16张测试结果图的函数:
# 输出16张测试结果图
def test_image_predict(path, start, image_size=(256, 384)):
# 将输出时的独热编码转为名字
name_dict = {0:'Bike', 1:'Bus', 2:'Car', 3:'Elc bike', 4:'Motor bike',
5:'Max truck', 6:'Small truck', 7:'Suv', 8:'Three bike', 9:'Van'}
# 因为只读16张,因此只需输入start数值即可
finish = start + 16
# 调用read_test_image函数
test_data = read_test_image(path, start, finish, image_size)
# 执行预测
preds = model.predict(test_data)
# 可视化输出
p = 1
fig = plt.gcf()
fig.set_size_inches(14, 10)
for i in range(0, 16):
f = plt.subplot(4, 4, p)
name = np.argmax(preds[i])
label = name_dict[name] + "\n" + str(preds[i][name])
f.set_title(label)
f.imshow(test_data[i])
plt.axis("off")
p += 1
plt.show()运行函数test_image_predict():
test_image_predict("./data/test/no-labels/", 100)得到输出结果:

可以直观看到,在自行车、摩托车、三轮车、电动车这些特征较为明确的类型,模型能够很好的预测,而对于特征有些相似的类型,如大卡车和公交车、越野车和面包车、越野车和小轿车等可能会出错。
尾言
本次训练作为一次比较简单的实战训练,在操作上比较简单。虽然模型准确率整体上较好,但仍有提升空间。如果进一步增加训练数据量、增加训练轮次或调整模型结构等方法都可能可以使模型准确率进一步提高。
欢迎下载资源并自己尝试训练。有许多参数都是可以调整的,如输入形状,全连接层的层数和神经元数、激活函数、早停的耐心值等。多多尝试也许会得到不一样的效果。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









