






试题说明:
员工统计信息,包括员工的满意度,5年内升职记录,最后的评估记录,月工作时长等信息,要求对水平分类。展示你的模型的薪资调准确率(accuracy),并且说明你处理流程的思路。
试题说明:
- 独立完成,可查阅教材及参考书籍。
- 此题是分类问题,分类模型可以自己选择,不限于教材所讲授的分类模型。
- 数据集中有Train.csv和Test.csv两个数据文件。其中Train.csv是训练集,用来对模型进行训练;Test.csv是测试集,用来对模型进行测试和评分,目标列为salary,评分指标为准确率accuracy,要求把预测的结果截图。
- 请将源代码中所有的变量名加上学生姓名的拼音首字母缩写_xxxxxx,例如:
源代码中有dataset这个变量,那么‘张三’同学的源代码中的变量应该命名为dataset_zs。
- 报告中详细贴出代码截图,程序运行结果截图贴在报告中。
- 考试报告文档提交的格式为Word,不能提交图片。
- 需要提交源代码,嵌入到word中
提交的文件名字必须为 姓名_学号_班级.docx
import pandas as pd
from demo2 import categorical_features
data_cx=pd.read_csv("train.csv")
test_cx=pd.read_csv("test.csv")
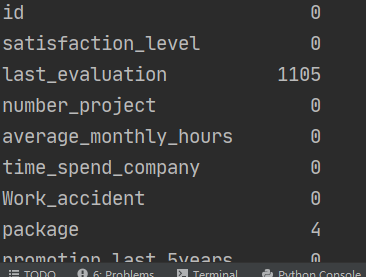
print(data_cx.isnull().sum(axis=0))
data_cx[:,'last_evaluation']=data_cx['last_evaluation'].fillna(data_cx.loc[:,'last_evaluation'].mean())
data_cx=data_cx.drop("division",axis=1)
data_cx=data_cx.drop("package",axis=1)
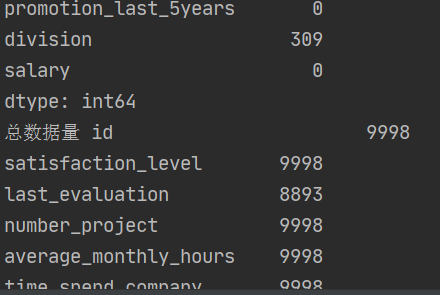
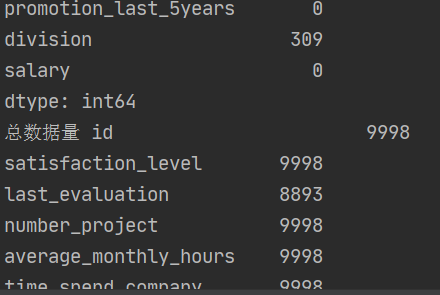
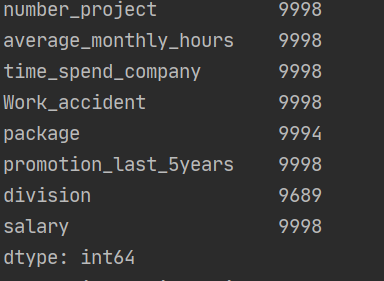
print("处理后的数据量",data_cx.count())
data = data_cx.loc['satisfaction_level', 'last_evaluation','number_project', 'average_monthly_hours','time_spend_company', 'promotion_last_5years', 'salary']
work_onehot=pd.get_dummies(data.loc[:,"last_evaluation"])
data = pd.concat([data,work_onehot],axis=1)
data = data.drop("last_evaluation",axis=1)
#特征编码
# label_encoders = {}
# categorical_features = ['satisfaction_level', 'last_evaluation','number_project', 'average_monthly_hours','time_spend_company', 'promotion_last_5years', 'salary']
# for feature in categorical_features:
# label_encoders[feature] = LabelEncoder()
# data_cx[feature] = label_encoders[feature].fit_transform(data_cx[feature])
from sklearn.preprocessing import LabelEncoder
le=LabelEncoder()
for column in data_cx.columns:
if(data_cx[column]).dtype==type(object):
data_cx[column]=le.fit_transform(data_cx[column])
# data_cx.head()
from sklearn.preprocessing import MinMaxScaler
scaler=MinMaxScaler()
data=pd.DataFrame(scaler.fit_transform(data_cx),columns=data_cx.columns)
print("归一化后的数据",data)
# from sklearn.linear_model import LinearRegression
# model=LinearRegression()
# model.fit(x_train,y_train)
#
# # 2.4 数值映射 字符串转化为数值
# from sklearn.preprocessing import LabelEncoder
# le=LabelEncoder()
# for column in data_cx.columns:
# if(data_cx[column]).dtype==type(object):
# data_cx[column]=le.fit_transform(data_cx[column])
# data_cx.head()
from sklearn.model_selection import train_test_split
x_train=data.drop('salary',axis=1)
# y=data['salary']
# x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3,random_state=42)
y_train=data['salary']
x_test=test_cx.drop('salary',axis=1)
y_test=test_cx['salary']
from sklearn.linear_model import LinearRegression
model = DecisionTreeClassifier(max_depth=3,criterion='entropy')
model.fit(x_train,y_train.astype(int))
# 5、模型的预测及评估
result = model.score(x_test.astype(int),y_test.astype(int))
print("accuary",result)
import pandas as pd
# 1.获取数据
data_cx = pd.read_csv('员工满意度_test.csv')
# print("测试集数据总量:", data_cx2.count())
# 2.2空值的处理,检查空值情况和处理空值
data_na = data_cx.isnull().sum(axis=0)
print("检查空值情况:",data_na)
# 2.3空值处理
data_cx = data_cx.dropna(axis=1)
print("处理后的数据量:", data_cx.count())
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
for column in data_cx.columns:
if data_cx[column].dtype == type(object):
data_cx[column] = le.fit_transform(data_cx[column])
# 2.5归一化或正则化
from sklearn.preprocessing import MinMaxScaler, StandardScaler
scale = MinMaxScaler()
# 2.6划分训练集与测试集
from sklearn.model_selection import train_test_split
X = data_cx.drop('salary', axis=1)
y = data_cx['salary']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.05, random_state=42)
# 4.模型选择及训练
from sklearn.tree import DecisionTreeClassifier
model_cx = DecisionTreeClassifier(max_depth=3,criterion="entropy")
model_cx.fit(X_train, y_train)
# 5.模型的预测与评估
result = model_cx.score(X_test, y_test)
print("模型最后的精度为:",result)
结果截图:
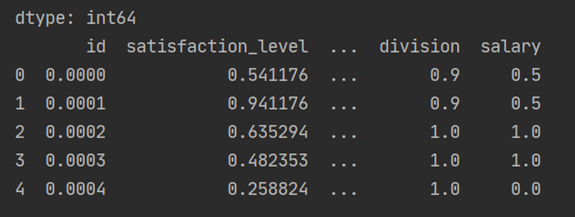
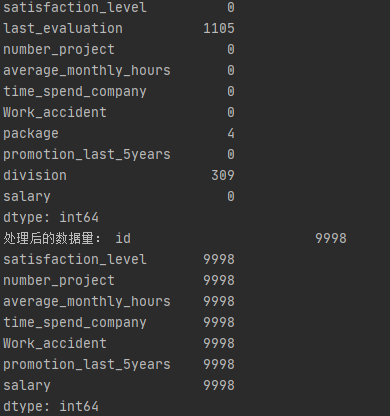
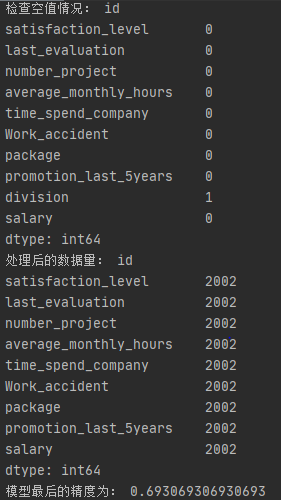
任务二:处理流程的思路
1.先读取数据,进行空值处理,然后把last_evaluation用均值填充,丢掉division和package
2.进行归一化处理。
3.划分训练集与测试集,目标列为entropy
4.模型选择决策树,最后打印出模型的精度。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









