







最近大家热议的ChatGPT和AI绘画工具的底层技术原理是什么?是如何发展到现在的?有哪些应用场景、热门工具?AIGC产业上下游有哪些公司?作为普通用户,我们还能接触哪些应用AI技术打造的商业解决方案?……
我们查阅了AIGC相关相关的调研报告和各类资料,按照优化后的目录框架对内容进行了摘录和编排,希望能够帮助大家也能更快了解和入门。

MidjourneyAI绘画工具社区作品
内容主要来自:《腾讯研究院-AIGC发展趋势报告2023》和《量子位智库-AI生成内容产业展望报告》这两篇行业报告,以及各类平台的相关文章、视频,文末也对参考内容的来源进行标注,想要深度了解的话可以留意下。
文章比较长,大概需要1-2个小时才能完整阅读,可以找个安静的地方一口气读完。里面的专业词汇如果不懂,可以先忽略,对于普通人来说,我们只需要了解大概的历程和应用场景以及代表工具即可。
本文逻辑:
1、技术定义
2、发展历程和经典事件
3、行业现状(基础层、中间层、应用层)
4、应用场景
5、国内外AIGC工具
可点击查看大图 ▼
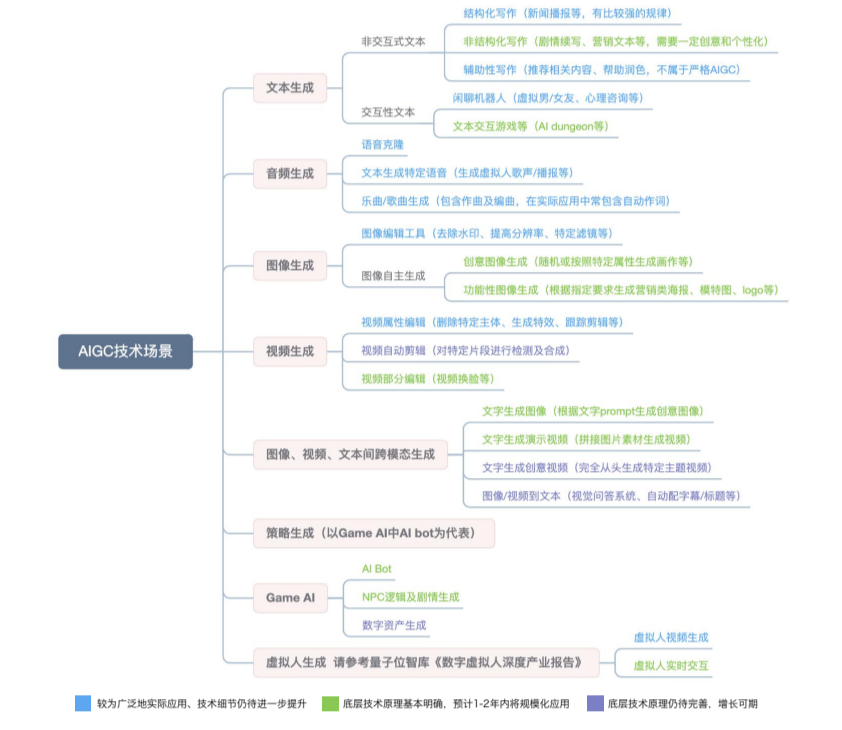
一、技术定义
AIGC全称为AI-Generated Content,指基于生成对抗网络GAN、大型预训练模型等人工智能技术,通过已有数 据寻找规律,并通过适当的泛化能力生成相关内容的技术。与之相类似的概念还包括Synthetic media,合成式媒体,主要指基于AI生成的文字、图像、音频等。
从字面意思上看,AIGC是相对于过去的 PCG、UCG 而提出的。因此,AIGC的狭义概念是利用Al自动生成内容的生产方式。但是 AIGC已经代表了AI技术发展的新趋势。
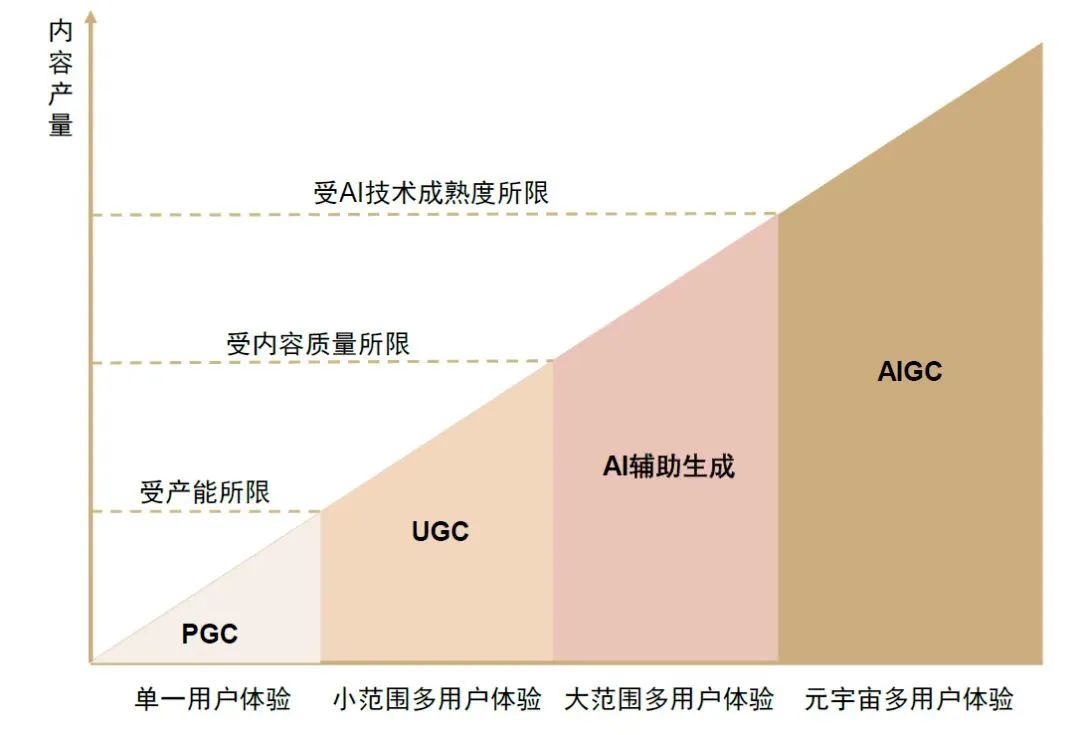
过去传统的人工智能偏向于分析能力,即通过分析一组数据,发现其中的规律和模式并用于其他多种用途,比如应用最为广泛的个性化推荐算法。而现在人工智能正在生成新的东西,而不是仅仅局限于分析已经存在的东西,实现了人工智能从感知理解世界到生成创造世界的跃迁。
因此,从这个意义上来看,广义的 AIGC 可以看作是像人类一样具备生成创造能力的 AI技术,即生成式 AL它可以基于训练数据和生成算法模型,自主生成创造新的文本,图像、音乐、视频、3D交互内容(如虚拟化身、虚拟物品、虚拟环境)等各种形式的内容和数据,以及包括开启科学新发现,创造新的价值和意义等。"因此,AIGC已经加速成为了Al 领域的新疆域,推动人工智能迎来下一个时代。
MIT 科技评论也将A1 合成数据列为 2022 年十大突破性技术之一,甚至将生成性 Al(Generative AI)称为是AI领域过去十年最具前景的进展。Gartner 将生成性 A1 列为 2022 年5大影响力技术之一。
Gartner 也提出了相似概念Generative AI,也即生成式AI。生成式AI是指该技术从现有数据中生成相似的原始数据。相较于量子位智库认为的AIGC,这一概念的范围较狭窄。
一方面,这一概念忽略了跨模态生成(如基于文本生成图像或基于文本生成视频)这一愈加重要的AIGC部分。我们会在下一部分对跨模态生成进行重点讲解。另一方面,在结合现有技术能力和落地场景进行分析后,我们认为“生 成”和“内容”都应该采取更为广泛的概念。
例如,生成中可以包含基于线索的部分生成、完全自主生成和基于底稿的优化生成。内容方面,不仅包括常见的图像、文本、音频等外显性内容,同样也包括策略、剧情、训练数据等 内在逻辑内容。
从特定角度来看,AI内容生成意味着AI开始在现实内容中承担新的角色,从“观察、预测”拓展到“直接生成、决策”。
从商业模式来看,我们认为,AIGC本质上是一种AI赋能技术,能够通过其高通量、低门槛、高自由度的生成能力广泛服务于各类内容的相关场景及生产者。因此,我们不会将其定义为PGC\UGC之后 的新内容创作模式,而是认为其在商业模式上会有大量其他交叉。
未来,兼具大模型和多模态模型的 AIGC模型有望成为新的技术平台。如果说 Al 推荐算法是内容分发的强大引整,AIGC则是数据与内容生产的强大引整。
AIGC朝着效率和品质更高、成本更低的方向发展,在某些情况下,它比人类创造的东西更好。包括从社交媒休到游戏,从广告到建筑,从编码到平面设计、从产品设计到法律,从营销到销售等各个需要人类知识创造的行业都可能被 AIGC 所影响和变革。数字经济和人工智能发展所需的海量数据也能通过 AIGC技术生成、合成出来,即合成数据(synthetic data)。
未来,人类的某些创造性的工作可能会被生成性 AI 完全取代,也有一些创造性工作会加速进入人机协同时代--人类与 AIGC技术共同创造比过去单纯人的创造之下更高效、更优质。
在本质上AIGC 技术的最大影响在于,AIGC技术将会把创造和知识工作的边际成本降至零,以产生巨大的劳动生产率和经济价值。换句话说,正如互联网实现了信息的零成本传播、复制。未来AIGC 的关键影响在于,将实现低成本甚至零成本的自动化内容生产,这一内容生产的范式转变,将升级甚至重塑内容生产供给,进而给依赖于内容生产供给的行业和领域带来巨大影响。
二、起源历程
AIGC发展历程和典型事件
虽然从严格意义上来说,1957 年莱杰伦·希勒(Lejaren Hiller)和伦纳德·艾萨克森(Leon-ard saacson)完成了人类历史上第一支由计算机创作的音乐作品就可以看作是 AIGC的开端,距今已有 65 年,这期间也不断有各种形式的生成模型、Al 生成作品出现。
但是 2022年才真正算是 AIGC 的爆发之年,人们看到了 AIGC无限的创造潜力和未来应用可能性。目前,AIGC 技术沉淀、产业生态已初步形成,保持强劲发展和创新势头。

主流生成模型诞生历程
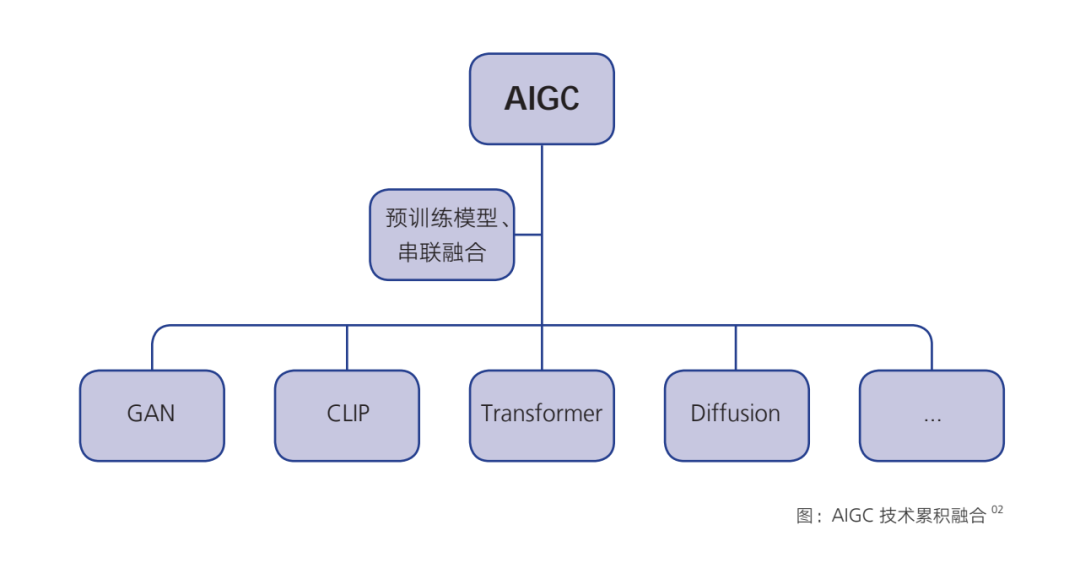
生成算法、预训练模型、多模态等AI技术累积融合,催生了AIGC 的大爆发。
一是,基础的生成算法模型不断突破创新。
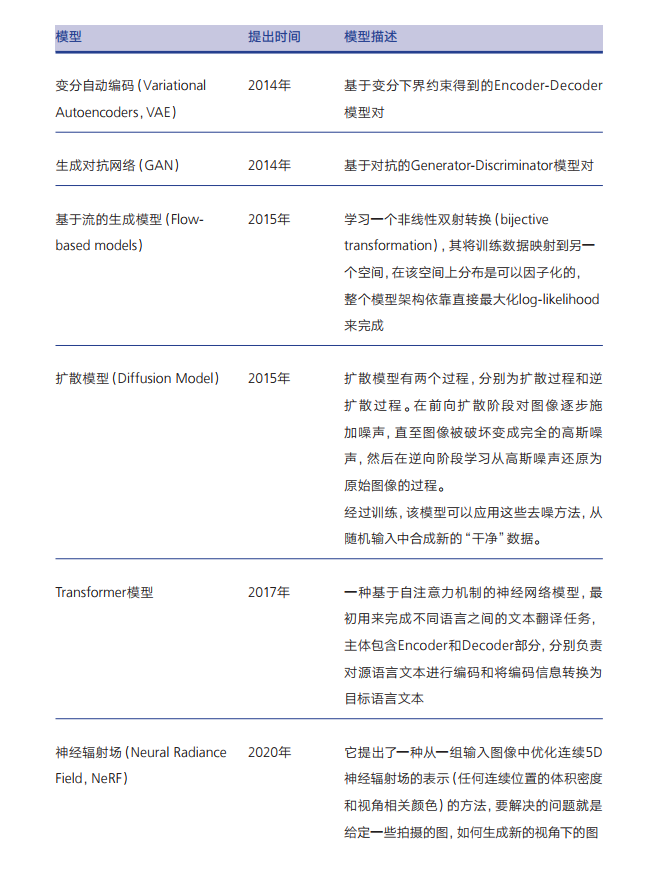
2014年,伊恩·古德费洛(lan Goodfellow)提出的生成对抗网络(Generative Adversarial Network,GAN)成为早期最为著名的生成模型。
GAN 使用合作的零和博弈框架来学习,被广泛用于生成图像、视频、语音和三维物体模型等。GAN 也产生了许多流行的架构或变种,如DCGAN,StyleGAN,BigGAN,StackGAN.Pix2pix,Age-cGAN,CycleGAN、对抗自编码器(Adversarial Autoencoders,AAE)、对抗推断学习(Adversarially Learned Inference,ALI)等。
随后,Transformer、基于流的生成模型(Flow-based models)、扩散模型(Diffusion Model)等深度学习的生成算法相继涌现。其中,Transformer 模型是一种采用自注意力机制的深度学习模型,这一机制可以按照输入数据各部分重要性的不同而分配不同的权重,可以用在自然语言处理(NLP)、计算机视觉(CV)领域应用。后来出现的 BERT、GPT-3、LaMDA等预训练模型都是基于Transformer 模型建立的。
而扩散模型(Diffusion Mode)是受非平衡热力学的启发,定义一个扩散步骤的马尔可夫链,逐渐向数据添加随机噪声,然后学习逆扩散过程,从噪声中构建所需的数据样本。扩散模型最初设计用于去除图像中的噪声。随着降噪系统的训练时间越来越长并且越来越好,它们最终可以从纯噪声作为唯一输入生成逼直的图片。
然而,从最优化模型性能的角度出发,扩散模型相对 GAN 来说具有更加灵活的模型架构和精确的对数似然计算,已经取代 GAN 成为最先进的图像生成器。2021年6月,OpenAl 发表论文已经明确了这个结论和发展趋势。

二是,预训练模型引发了 AIGC技术能力的质变。
虽然过去各类生成模型层出不穷,但是使用门槛高、训练成本高、内容生成简单和质量偏低,远远不能满足真实内容消费场景中的灵活多变、高精度、高质量等需求。预训练模型的出现引发了 AIGC技术能力的质变,以上的诸多落地问题得到了解决。
随着 2018 年谷歌发布基于 Transformer 机器学习方法的自然语言处理预训练模型 BERT,人工智能领域进入了大炼模型参数的预训练模型时代。AI预训练模型,又称为大模型、基础模型(foundation mode),即基于大量数据(通常使用大规模自我监督学习)训练的、拥有巨量参数的模型,可以适应广泛的下游任务。
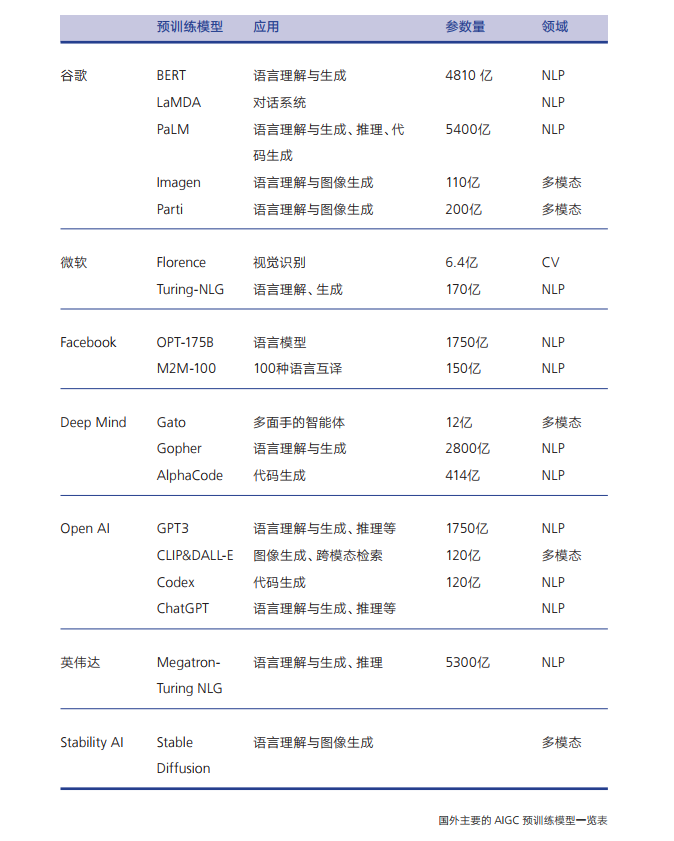
这些模型基于迁移学习的思想和深度学习的最新进展,以及大规模应用的计算机系统,展现了令人惊讶的涌现能力,并显著提高各种下游任务的性能。”鉴于这种潜力,预训练模型成为 AI技术发展的范式变革,许多跨领域的Al系统将直接建立在预训练模型上。具体到 AIGC 领域,AI 预训练模型可以实现多任务、多语言、多方式,在各种内容的生成上将扮演关键角色。按照基本类型分类,预训练模型包括:(1)自然语言处理(NLP)预训练模型,如谷歌的 LaMDA和 PaLM、Open AI的 GPT 系列:(2)计算机视觉(CV)预训练模型,如微软的 Florence:(3)多模态预训练模型,即融合文字、图片、音视频等多种内容形式。
可点击查看大图 ▼
三是,多模态技术推动了AIGC的内容多样性,让 AIGC 具有了更通用的能力。
预训练模型更具通用性,成为多才多艺、多面手的 Al模型,主要得益于多模型技术(multimodal technol-ogy)的使用,即多模态表示图像、声音、语言等融合的机器学习。
2021年,OpenAI团队将跨模态深度学习模型CLIP(Contrastive Lanquaqe-Image Pre-Training,以下简称“CLIP")进行开源。CLIP 模型能够将文字和图像进行关联,比如将文字“狗”和狗的图像进行关联,并且关联的特征非常丰富。因此,CLIP 模型具备两个优势:一方面同时进行自然语言理解和计算机视觉分析,实现图像和文本匹配。另一方面为了有足够多标记好的“文本-图像”进行训练,CLIP 模型广泛利用互联网上的图片,这些图片一般都带有各种文本描述,成为 CLIP 天然的训练样本。
据统计,CLIP 模型搜集了网络上超过 40 亿个“文本-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











