






一、环境配置
三台CentOS7虚拟机,默认配置,内存2GB、处理器2核心。
先更新下系统
1 sudo yum update 2 sudo yum upgrade
二、安装并启动 docker
1 yum -y install wget
2 wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O/etc/yum.repos.d/docker-ce.repo
3 yum -y install docker-ce
4 systemctl enable docker
5 systemctl start docker三、安装 kubeadm
1、配置阿里源
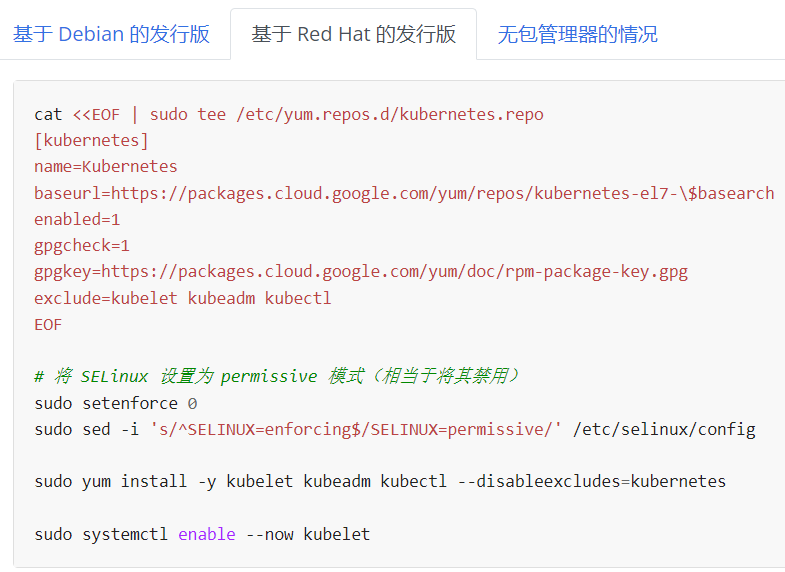
官网这种带 google 的一看就会被墙,我们直接使用阿里的源:
![]()
cat <<EOF > /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF
![]()
设置完源后再更新一下:
sudo yum update
2、禁用 SELinux
将 SELinux 设置为 permissive 模式,相当于将其禁用

1 sudo setenforce 0 2 sudo sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config
3、关闭防火墙
1 systemctl stop firewalld 2 systemctl disable firewalld
4、关闭 swap

swapoff -a
5、安装并启用 kubelet
1 sudo yum install -y kubelet kubeadm kubectl --disableexcludes=kubernetes 2 sudo systemctl enable --now kubelet
四、部署主节点
1、查看 kubeadm 版本信息
kubeadm config print init-defaults
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.k8s.io
kind: ClusterConfiguration
kubernetesVersion: 1.27.0其中 apiVersion 和 kubernetesVersion 需要和下面编写的 kubeadm.yml 保持一致。
2、编写 kubeadm.yaml
![]()
apiVersion: kubeadm.k8s.io/v1beta3
kind: ClusterConfiguration
kubernetesVersion: 1.27.0
imageRepository: registry.aliyuncs.com/google_containers
apiServer:
extraArgs:
runtime-config: "api/all=true"
etcd:
local:
dataDir: /data/k8s/etcd
![]()
3、运行 kubelet.service
systemctl enable kubelet.service
4、启动容器运行时
1 rm -rf /etc/containerd/config.toml 2 systemctl restart containerd
5、使网桥支持 ip6
![]()
1 cd /etc/sysctl.d/ 2 vi k8s-sysctl.conf 3 #添加如下文本 4 net.bridge.bridge-nf-call-ip6tables = 1 5 net.bridge.bridge-nf-call-iptables = 1 6 #使其生效 7 sysctl -p k8s-sysctl.con
![]()
6、部署 master
kubeadm init --config kubeadm.yaml
五、ERROR
虽然上面 4~5 等步骤解决了一些警告,以及报错,但最终步骤8还是跑不起来,将版本换到 1.23.xx 再试试

1、卸载安装的 kubeadm
sudo yum remove kubelet kubeadm kubectl
2、重新安装指定版本 kubeadm
yum install kubelet-1.23.17 kubeadm-1.23.17 kubectl-1.23.17 kubernetes-cni

3、启用 kubelet
sudo systemctl enable --now kubelet
4、查看 kubeadm 版本信息
5、修改 kubeadm.yaml 版本为 1.23.0
6、部署 master
六、ERROR
降低版本后又出现如下报错:
![]()
[init] Using Kubernetes version: v1.23.0
[preflight] Running pre-flight checks
[WARNING SystemVerification]: this Docker version is not on the list of validated versions: 24.0.2. Latest validated version: 20.10
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR FileAvailable--etc-kubernetes-manifests-kube-apiserver.yaml]: /etc/kubernetes/manifests/kube-apiserver.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-controller-manager.yaml]: /etc/kubernetes/manifests/kube-controller-manager.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-scheduler.yaml]: /etc/kubernetes/manifests/kube-scheduler.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-etcd.yaml]: /etc/kubernetes/manifests/etcd.yaml already exists
[ERROR Port-10250]: Port 10250 is in use
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
![]()
1、首先需要将 24.0.2 版本的 Docker 降级为 20.10 的版本
访问 Docker 版本 可查看 docker-ce 版本:
![]()
yum downgrade --setopt=obsoletes=0 -y docker-ce-20.10.24 docker-ce-selinux-20.10.24 containerd.io
2、重置 kubeadm
kubeadm reset
3、部署 master
7、ERROR
呕、变着花样报错:
![]()
Unfortunately, an error has occurred:
timed out waiting for the condition
This error is likely caused by:
- The kubelet is not running
- The kubelet is unhealthy due to a misconfiguration of the node in some way (required cgroups disabled)
If you are on a systemd-powered system, you can try to troubleshoot the error with the following commands:
- 'systemctl status kubelet'
- 'journalctl -xeu kubelet'
Additionally, a control plane component may have crashed or exited when started by the container runtime.
To troubleshoot, list all containers using your preferred container runtimes CLI.
Here is one example how you may list all Kubernetes containers running in docker:
- 'docker ps -a | grep kube | grep -v pause'
Once you have found the failing container, you can inspect its logs with:
- 'docker logs CONTAINERID'
![]()
1、先看一下 kubelet 是否在运行
systemctl status kubelet
2、输入如下命令查看报错日志
journalctl -xefu kubelet
![]()
May 28 23:23:50 localhost.localdomain kubelet[19052]: E0528 23:23:50.235324 19052 server.go:302] "Failed to run kubelet" err="failed to run Kubelet: misconfiguration: kubelet cgroup driver: \"systemd\" is different from docker cgroup driver: \"cgroupfs\"" May 28 23:23:50 localhost.localdomain systemd[1]: kubelet.service: main process exited, code=exited, status=1/FAILURE May 28 23:23:50 localhost.localdomain systemd[1]: Unit kubelet.service entered failed state. May 28 23:23:50 localhost.localdomain systemd[1]: kubelet.service failed.
![]()
3、Google或百度下报错原因
kubelet cgroup driver: \“systemd\“ is different from docker cgroup driver: \“cgroupfs\“
上面说是 Docker 和 kubelet 的 cgroup driver 不一样,kubelet 的是 systemd,docker 的是 cgroupfs。


3.1 将 docker 的改成 systemd:
![]()
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://gmkz82n7.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"]
}
EOF
![]()
registry-mirrors 是为了配置镜像加速器,exec-opts 才是将 docker 的 cgroup driver 改成 systemd。
镜像加速器地址可以在阿里云官网搜容器镜像服务,然后找到镜像加速器。
3.2 重启 docker:
1 sudo systemctl daemon-reload 2 sudo systemctl restart docker
3.3 查看 docker 的 cgroup
docker info
3.4 重置 kubeadm
kubeadm reset
3.5 部署 master
八、主节点部署成功标志

上图说了要启动集群需要执行的命令:
1 mkdir -p $HOME/.kube 2 sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config 3 sudo chown $(id -u):$(id -g) $HOME/.kube/config
export KUBECONFIG=/etc/kubernetes/admin.conf
最后,你应该部署一个 pod 网络附加组件,可参考 weaveworks网站 进行部署:
kubectl apply -f https://github.com/weaveworks/weave/releases/download/v2.8.1/weave-daemonset-k8s.yaml
检查部署状态:
kubectl get pods -n kube-system

从失败到成功大概可能要个五分钟左右吧。
九、部署工作节点
1、重复步骤 一 ~ 三,安装 kubeadmin。

提醒:
- Docker 不要安装太高版本,或者可按步骤先安装后降级
- Docker 的 cgroup driver 驱动需要改成 systemd
- kubeadm 不要默认安装最新版,要安装指定版本
- 禁用 SELinux,禁用 swap
- 关闭防火墙
2、加入节点
kubeadm join 192.168.33.133:6443 --token rodccq.t8fooat0paxcof56 \
--discovery-token-ca-cert-hash sha256:64e91a185d8929b23c987683ffae359e62b09fb94e035322d511addbd065fb02
十、ERROR

说是 token 过期了,不过我主节点出现这个 token 到部署 WorkNode 不过一小时。
那么重新生成一下 Token 看看:
kubeadm token create --print-join-command
出现如下命令:
kubeadm join 192.168.33.133:6443 --token vz24u8.4h5vuriszbns3cfi --discovery-token-ca-cert-hash sha256:64e91a185d8929b23c987683ffae359e62b09fb94e035322d511addbd065fb02
在 WorkNode 上执行一下上面命令,过了几分钟后,还是出现同样报错。
网上搜到说本地时间错误同样会导致证书过期报错,检查一下两台机器的本地时间
date
发现确实不对,同步时间命令,两台机器都执行一下:
1 sudo yum install ntpdate 2 ntpdate ntp1.aliyun.com
MasterNode 重新生成下 token,WorkNode 执行加入节点命令。
很遗憾的是我的虚拟机上的主节点突然宕机了,并且之后换了一个 IP,然后我又立马给它起起来了。
然后再 MasterNode 重新生成下 token,WorkNode 执行加入节点命令。
继续报错,如果你们的没有像我一样突然发生宕机,可能不会出现这样的问题:
You must delete the existing Node or change the name of this new joining
然后我就给新加入的节点重命名主机名:
hostnamectl set-hostname node01
再重新加入,然后又报了一个错:
[ERROR FileAvailable--etc-kubernetes-pki-ca.crt]: /etc/kubernetes/pki/ca.crt already exists
这需要重置一下 kubeadm:
kubeadm reset
再再重新加入,终于成功了:

接着我们运行一下查看节点的命令:(注意,需要在有 control-plane 组件的节点查看,目前只有主节点有)
kubectl get nodes
那我们在主节点上运行看看:
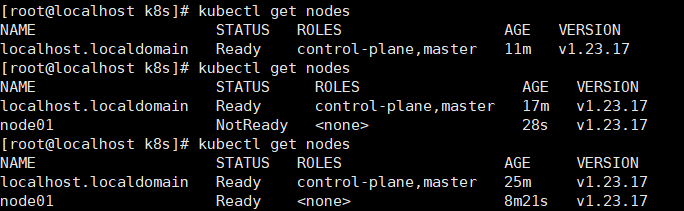
这个命令我在主节点上执行了三次,第一次是工作节点还没加入前,第二次是工作节点加入后,可以看到 node01 状态是 NotReady,过了几分钟后,我又执行了一次,node01 的状态变成了 Ready。
最后我们再按照加入子节点的步骤,再加入一台机器:

一个主节点、两个工作节点 K8S 集群搭建完成。















 344
344











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











