






一,Hadoop介绍

Hadoop是一个由Apache基金会所开发的分布式系统基础架构,主要用于海量数据的存储和海量数据的分析计算。以下是关于Hadoop的详细介绍:
一、基本概念
Hadoop是一个能够让用户在不了解分布式底层细节的情况下,开发分布式程序的框架。它充分利用集群的威力进行高速运算和存储,其核心设计包括分布式文件系统(HDFS)和MapReduce编程模型。
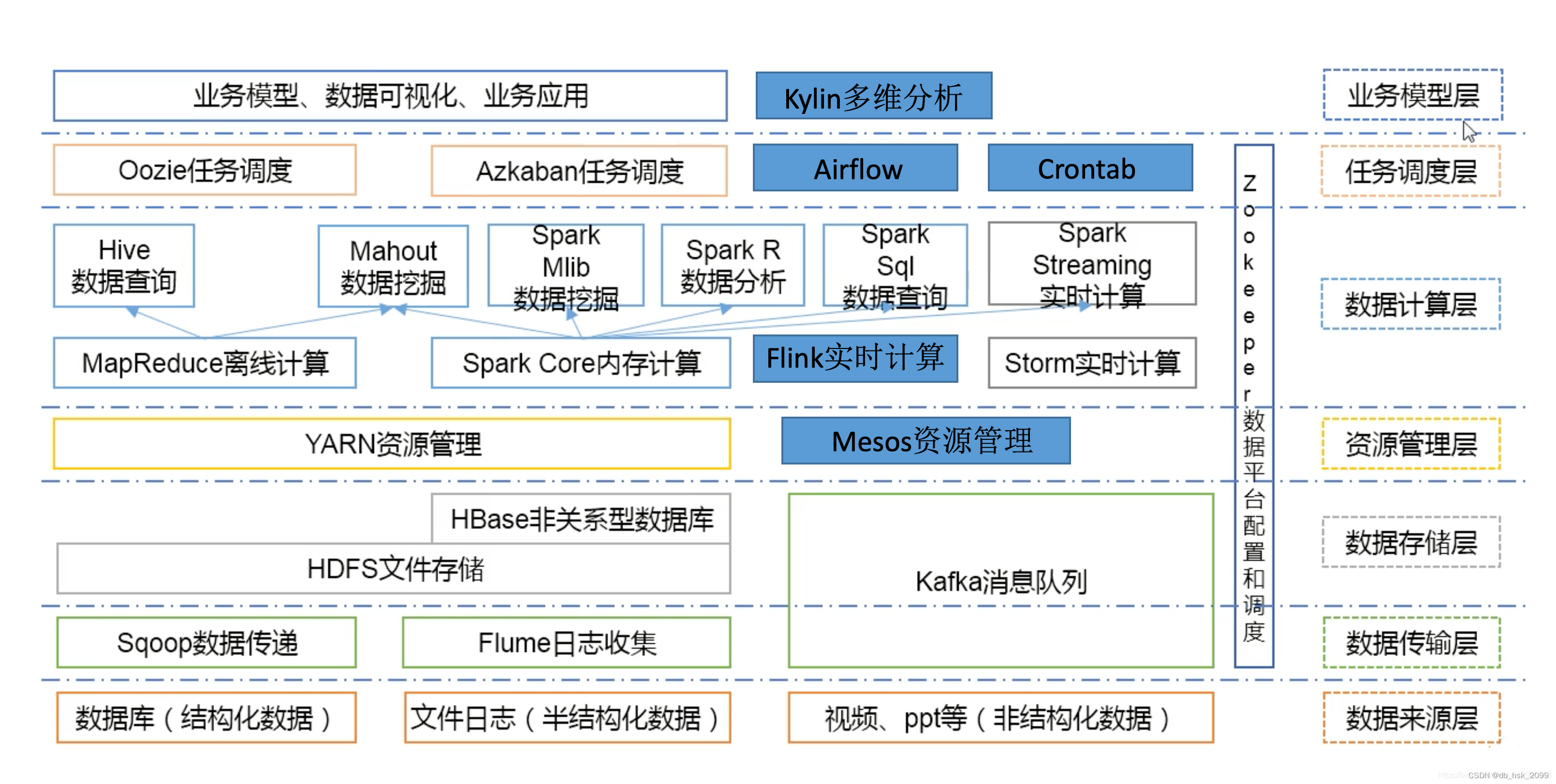
二、核心组件
- HDFS(Hadoop Distributed File System):
- 这是一个高容错性的分布式文件系统,适合部署在低廉的硬件上。
- 它通过自动保存数据的多个副本来确保数据的可靠性。
- HDFS放宽了POSIX的要求,可以以流的形式访问文件系统中的数据。
- MapReduce:
- 这是一个分布式运算编程框架,用于在集群服务器上分布式并行运算。
- 它允许用户编写两个主要的函数:Map函数和Reduce函数,以实现数据的并行处理和聚合。
- YARN(Yet Another Resource Negotiator):
- 这是一个分布式资源调度系统,用于帮助用户调度大量的MapReduce程序,并合理分配运算资源(如CPU和内存)。
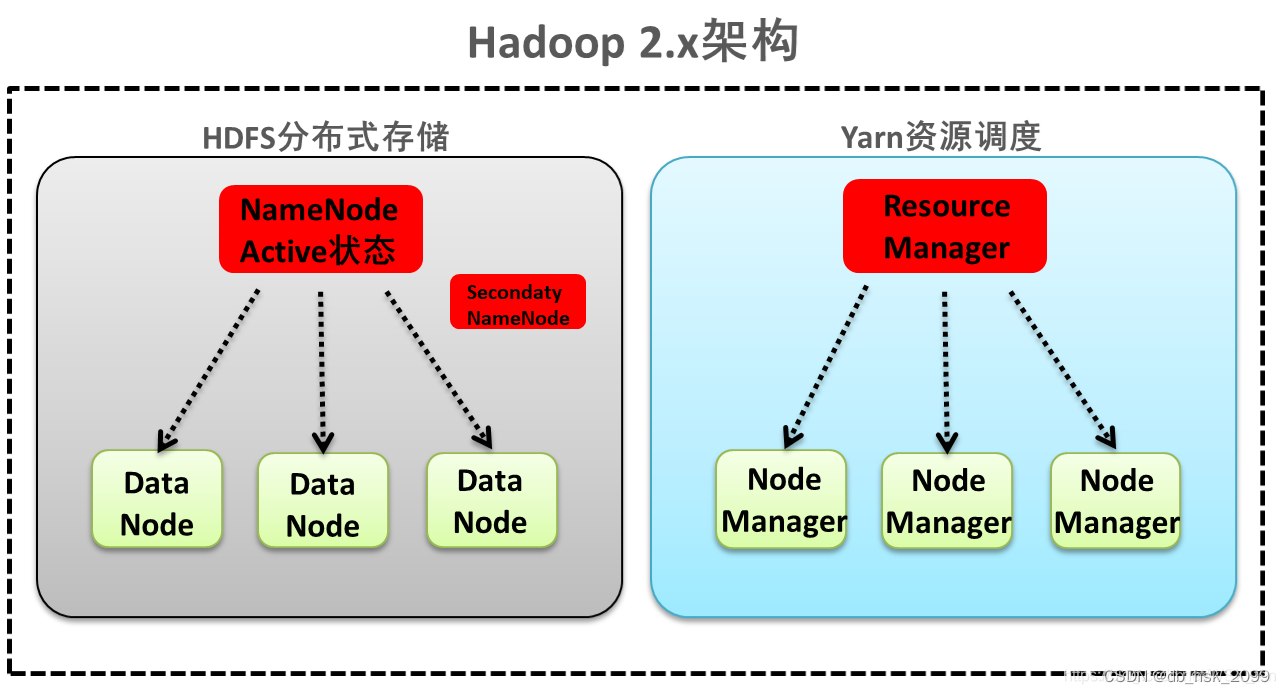
- 这是一个分布式资源调度系统,用于帮助用户调度大量的MapReduce程序,并合理分配运算资源(如CPU和内存)。
三、特点与优势
- 高可靠性:Hadoop通过维护多个数据副本,即使在计算元素或存储出现故障时,也能保证数据的可靠性。
- 高扩展性:Hadoop能够方便地在集群间分配任务数据,并可以轻松地扩展到数以千计的节点。
- 高效性:Hadoop以并行的方式工作,通过并行处理可以加快处理速度。
- 高容错性:Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
- 低成本:Hadoop可以运行在廉价的机器上,并且其成本较低,任何人都可以使用。
四、适用场景
Hadoop适用于以下场景:
- 大数据处理:Hadoop能够处理海量数据,适合用于分布式存储和处理大规模数据集。
- 数据分析:Hadoop提供了MapReduce框架,可以用于数据处理和分析,支持复杂的数据处理任务。
- 日志分析:Hadoop能够处理大量的日志数据,帮助企业分析用户行为和系统运行情况。
- 数据挖掘:Hadoop提供了强大的数据处理和计算能力,可以用于数据挖掘和机器学习任务。
综上所述,Hadoop是一个功能强大的分布式系统基础架构,以其高可靠性、高扩展性、高效性、高容错性和低成本的特点,广泛应用于大数据处理、数据分析、日志分析和数据挖掘等场景。
二,安装过程(以Linux为例)
一、环境准备
- 操作系统:选择CentOS 7作为安装Hadoop的操作系统。
- Java环境:Hadoop需要Java环境,确保安装JDK 1.8或以上版本。
- SSH:Hadoop集群中的节点之间需要使用SSH进行通信,确保SSH服务已经安装并启动。
二、安装步骤
1.下载Hadoop
1访问Apache Hadoop官网(https://hadoop.apache.org/),下载所需的Hadoop版本
2.解压Hadoop
1.将下载的Hadoop压缩包上传至Linux服务器。
2.解压Hadoop压缩包到指定目录,例如/usr/local/hadoop。
保存并退出编辑器,然后运行source ~/.bashrc使配置生效。
sudo tar -xzf hadoop-*.tar.gz -C /usr/local/
sudo ln -s /usr/local/hadoop-* /usr/local/hadoop3.配置环境变量
- 编辑
~/.bashrc文件,添加Hadoop的环境变量。export HADOOP_HOME=/usr/local/hadoop export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
2. 修改core-site.xml文件,core-site.xml:配置Hadoop的核心参数。将以下代码添加进文件中。
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/tmp/hadoop-${user.name}</value>
</property>
</configuration> 3.修改hdfs-site.xml,hdfs-site.xml:配置HDFS的参数。将以下代码添加进文件中。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration> 4.修改yarn-site.xml文件,yarn-site.xml(如果使用YARN):配置YARN的参数。将以下代码添加进文件中。
<configuration>
<!-- Site specific YARN configuration properties -->
</configuration> 5.mapred-site.xml(如果使用MapReduce 1.x):从mapred-site.xml.template复制并重命名,然后配置MapReduce的参数。并在mapred-site.xml中添加配置。
cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml 6.workers(或slaves,取决于Hadoop版本):列出Hadoop集群中的所有DataNode节点。
6.1更改文件权限(如果需要的话)。
sudo chown -R your_username:your_username /usr/local/hadoop7.格式化HDFS
- 在NameNode节点上,运行以下命令格式化HDFS。
hdfs namenode -format
8. 启动Hadoop
8.1启动HDFS。
start-dfs.sh8.2如果使用YARN,则还需要启动YARN。
start-yarn.sh9.检查服务状态
- 使用
jps命令检查NameNode、DataNode、ResourceManager、NodeManager等进程是否正在运行。 - 访问Hadoop的Web界面(默认端口为50070和8088)来查看集群的状态。















 422
422

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









