






瀑布图一般反映了数据的增长或下降趋势,它会形成随着顺序逐步叠加或逐步递减的效果。我们普通的柱状图绘制,虽然也能看得出逐渐递增或递减,但是他描绘不出累加或者累减的形式。
举个例子,如果第一个数据大于0,第二个数据小于0,则第二个柱子就从第一个柱子的顶部高度开始向下延伸;第二个柱子如果大于0,则从第二个柱子从第一个柱子的顶部高度开始向上拓展;特别的,如果第二个数据小于0(即柱子向下延伸),第三个数据大于0,则第三个柱子从第二个柱子的底部向上延伸。例如
普通柱状图
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
plt.rcParams["font.sans-serif"] = ["SimHei"] # windows系统
plt.rcParams['axes.unicode_minus']=False #正常显示符号
data=pd.DataFrame({'项目':['吃饭','逛街','看电影'],'支出':[100,200,400]})
plt.bar(data['项目'],data['支出'])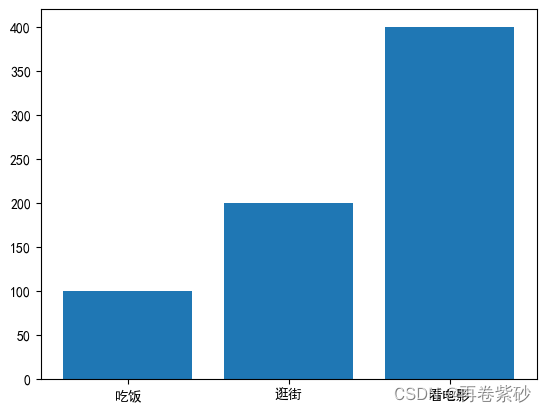
累加瀑布图
首先我们得知道,瀑布图呈现一个累加的状态,所以我们需要把原数据增添累加列。
np.cumsum()能够实现列表数据的累加
data['test1']=pd.Series(np.cumsum(data['支出']))
new_row = pd.DataFrame({'项目':'汇总','支出':0,'test1':data['test1'].iloc[-1]},index=[3])
data = pd.concat([data,new_row],ignore_index=True)| 项目 | 支出 | test1 | |
|---|---|---|---|
| 0 | 吃饭 | 100 | 100 |
| 1 | 逛街 | 200 | 300 |
| 2 | 看电影 | 400 | 700 |
| 3 | 汇总 | 0 | 700 |
但是如果只根据累加的数据绘制柱状图,并不能达到以往的断层上升的状态,也不能显示不同的阶段数值的变化量。形式如下图所见。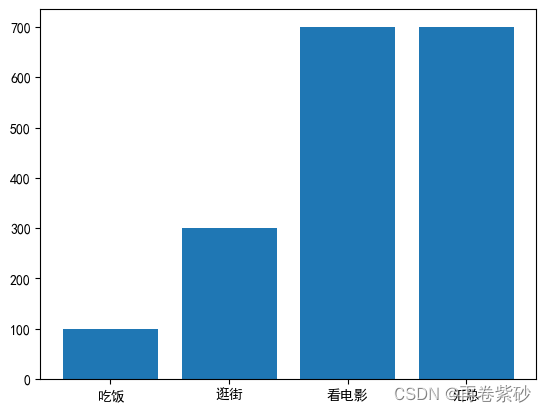
所以我们需要使用覆盖的方式,绘制另一组柱状图
累加的数据为 100 300 700 ,我们命名为主体柱子高度
我们是不是需要背景色柱子高度为 0 100 300 进行覆盖(我们称之为覆盖柱子)
这两个柱子的高度算法我们用代码来描述。
#list为覆盖柱,bars为主体柱子
bars=plt.bar(data['项目'],data['test1'])
list=[0]
for i in data['test1'][:-2]:
list.append(i)
list.append(0)
list=pd.Series(list)
plt.bar(data['项目'],list,color='white')
for i,bar in enumerate(bars): #添加柱子高度,注意是支付列的数据,而不是累加数据
plt.text(bar.get_x()-0.1 + bar.get_width() / 2,bar.get_y() +20+
bar.get_height(),data['支出'][i],
ha='left', va='center', color='black')
plt.bar(data['项目'][3],data['test1'][3],color='red') #汇总加红色
plt.ylim(0,900)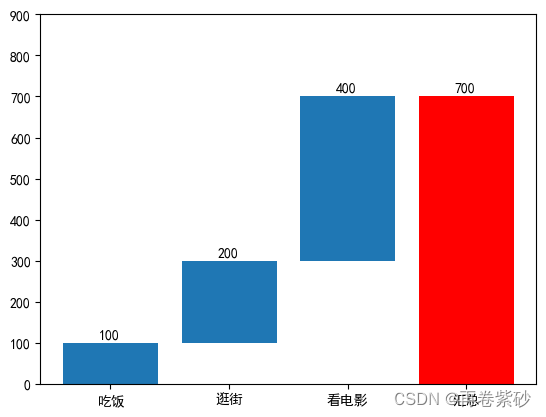
list和data的结果
0 0 1 100 2 300 3 0 dtype: int64
| 项目 | 支出 | test1 | |
|---|---|---|---|
| 0 | 吃饭 | 100 | 100 |
| 1 | 逛街 | 200 | 300 |
| 2 | 看电影 | 400 | 700 |
| 3 | 汇总 | 700 | 700 |
累减瀑布图
累减瀑布图就是随着状态的变化,数据呈现依次递减的形式。思路跟前者差不多,不多赘述。
data1=pd.DataFrame({'项目':['吃饭','逛街','看电影'],'支出':[100,-20,-30]})
data1['test1']=pd.Series(np.cumsum(data1['支出']))
new_row1 = pd.DataFrame({'项目':'汇总','支出':0,'test1':data1['test1'].iloc[-1]},index=[3]) # 这里的3是根据长度不同变换的
data1 = pd.concat([data1,new_row1],ignore_index=True)list1=[data1['test1'][0]]
for i in data1['test1'][:-2]:
list1.append(i)
list1.append(data1['test1'].iloc[-1])
list1=pd.Series(list1)
#list1 作为显示柱
#test2 作为覆盖柱
data1['test2']=data1['test1']
data1['test2'].iloc[0]=0
data1['test2'].iloc[-1]=0bars1=plt.bar(data1['项目'],list1)
plt.bar(data1['项目'],data1['test2'],color='white')
plt.bar(data1['项目'].iloc[-1],data1['test1'].iloc[-1],color='red')
for i,bar in enumerate(bars1):
plt.text(bar.get_x()-0.1 + bar.get_width() / 2,bar.get_y()+3+ bar.get_height(),data1['支出'][i],ha='left', va='center', color='black')
plt.ylim(0,110)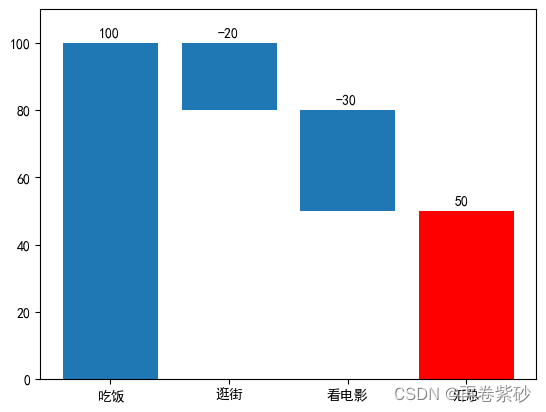
list1和data1结果
0 100 1 100 2 80 3 50 dtype: int64
| 项目 | 支出 | test1 | test2 | |
|---|---|---|---|---|
| 0 | 吃饭 | 100 | 100 | 0 |
| 1 | 逛街 | -20 | 80 | 80 |
| 2 | 看电影 | -30 | 50 | 50 |
| 3 | 汇总 | 50 | 50 | 0 |
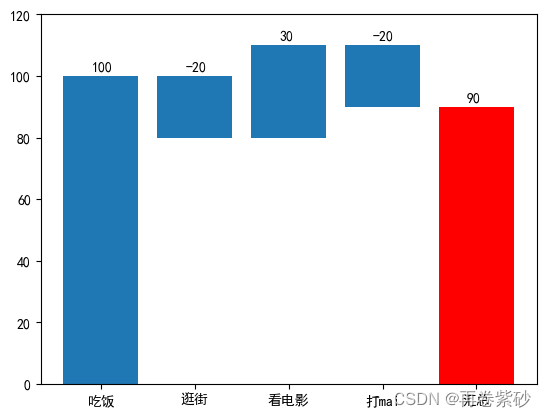
加减瀑布图
一般情况下,根据概念我们知道瀑布图要么递增,要么递减。但是如果你要处理的一组数据,一会增加一会减少,该怎么进行绘制。
data2=pd.DataFrame({'项目':['吃饭','逛街','看电影','打mai'],'支出':[100,-20,30,-20]})
data2['test1']=pd.Series(np.cumsum(data2['支出']))
#主体柱子高度
def main_bar(a,b):
main_list=[a[0]]
for i in range(1,len(a)):
if a[i]<0:
main_list.append(b[i-1])
elif a[i]>0:
main_list.append(b[i])
else:
main_list.append(main_list[i-1])
return pd.Series(main_list)
data2['main']=main_bar(data2['支出'],data2['test1'])
#覆盖柱子高度
def test_bar(a,b):
test_bar=[0]
for i in range(1,len(a)):
if a[i]<0:
test_bar.append(b[i])
elif a[i]>0:
test_bar.append(b[i-1])
else:
test_bar.append(test_bar[i-1])
return pd.Series(test_bar)
data2['test_bar']=test_bar(data2['支出'],data2['test1'])
#增添汇总行
new_row2 = pd.DataFrame({'项目':'汇总','支出':data2['test1'].iloc[-1],'test1':data2['test1'].iloc[-1],'main':data2['test1'].iloc[-1],'test_bar':data2['test_bar'].iloc[-1]},index=[4]) # 这里的3是根据长度不同变换的
data2 = pd.concat([data2,new_row2],ignore_index=True)这个代码算是把前二者都综合起来进行判断
data2的结果
| 项目 | 支出 | test1 | main | test_bar | |
|---|---|---|---|---|---|
| 0 | 吃饭 | 100 | 100 | 100 | 0 |
| 1 | 逛街 | -20 | 80 | 100 | 80 |
| 2 | 看电影 | 30 | 110 | 110 | 80 |
| 3 | 打mai | -20 | 90 | 110 | 90 |
| 4 | 汇总 | 90 | 90 | 90 | 90 |
bars2=plt.bar(data2['项目'],data2['main']) #主柱子
plt.bar(data2['项目'],data2['test_bar'],color='white') #覆盖柱子
plt.bar(data2['项目'].iloc[-1],data2['test1'].iloc[-1],color='red')
for i,bar in enumerate(bars2):
plt.text(bar.get_x()-0.1 + bar.get_width() / 2,bar.get_y()+3+ bar.get_height(),data2['支出'][i],
ha='left', va='center', color='black')
plt.ylim(0,120)
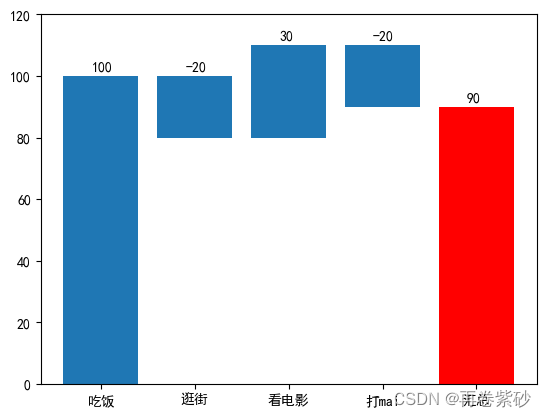
(其实大家只要自己纸上画个图,把原数据,累加数据列出来,就能发现主体柱子和覆盖柱子高度的关系了)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









