







selenium环境搭建
- 下载selenium:pip install selenium
- 下载浏览器驱动:浏览器驱动下载视频教程
- 浏览器驱动下载地址: 浏览器驱动下载地址
selenium的基本使用
用selenium打开一个百度网页
from selenium.webdriver import Chrome
# 生成浏览器对象
web = Chrome()
# 需要在浏览器打开的网值
web.get('http://www.baidu.com')
print(web.title) # 网页的标题selenium的基本操作
获取一个元素并点击它
# 用的是Chrome,所以导入的是Chrome,如果用其他的,比如IE、火狐可以导入对应的
from selenium.webdriver import Chrome
# 创建浏览器对象
web = Chrome()
# 打开拉勾网
web.get('https://www.lagou.com/')
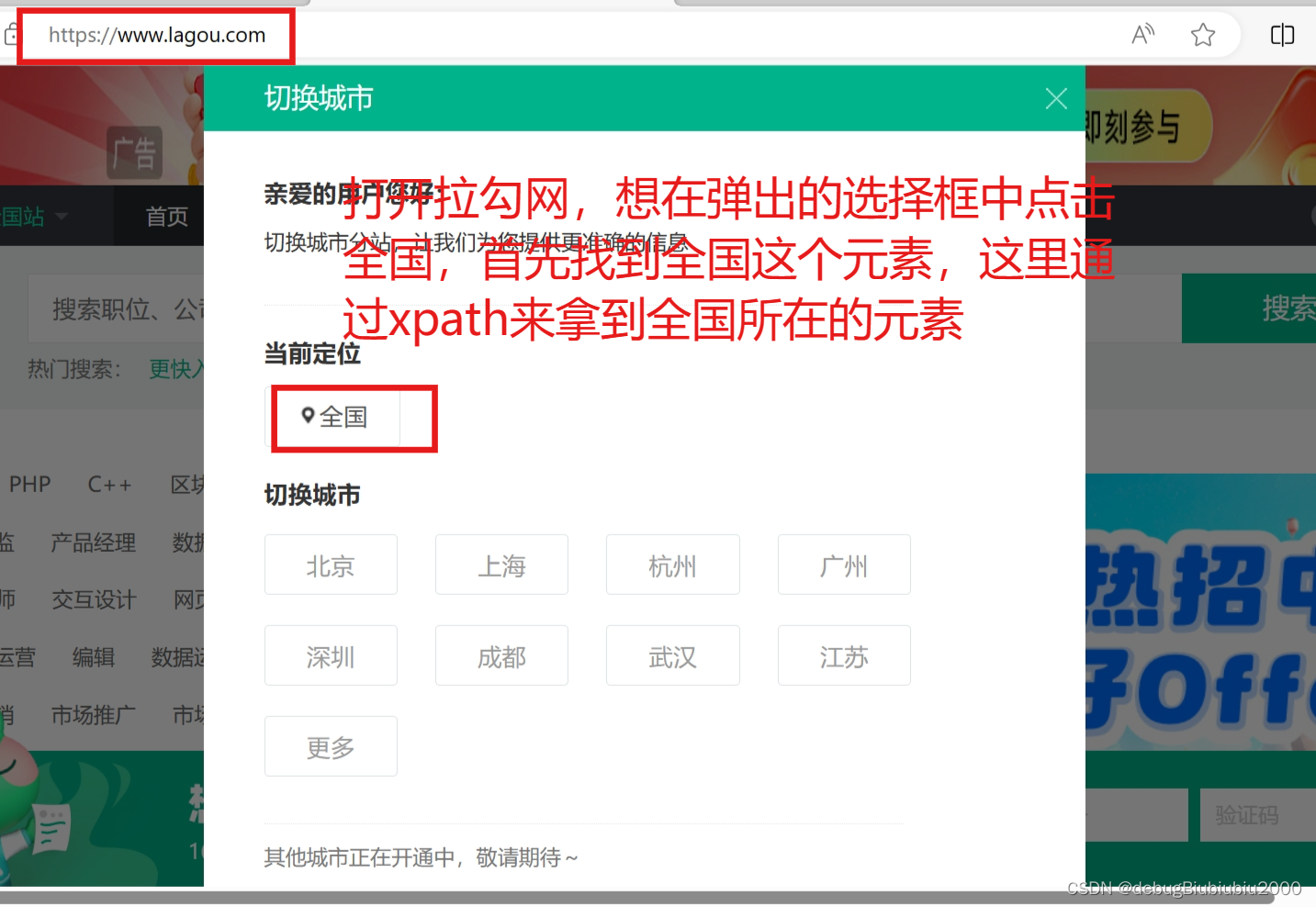
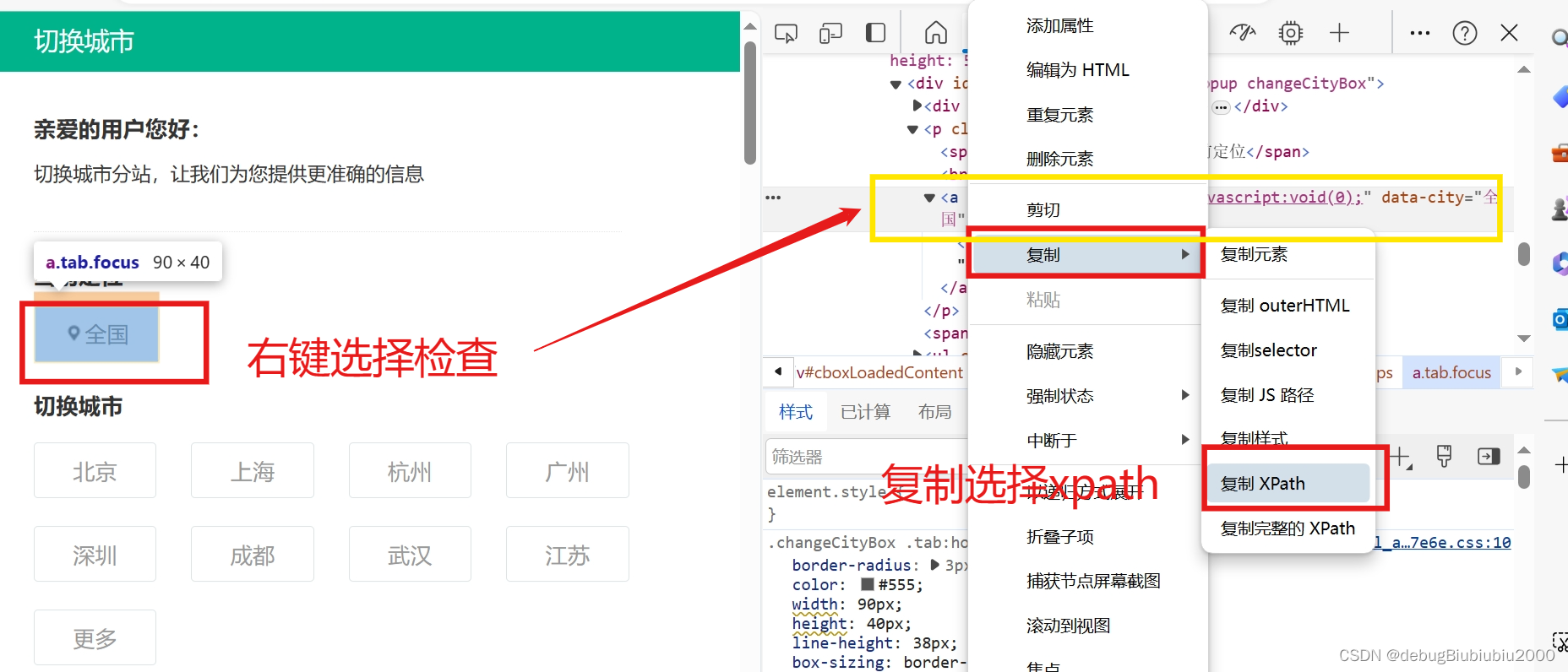
# 通过xpath找到包含全国字样的元素,然后点击它
ele = web.find_element(by=By.XPATH, value='//*[@id="changeCityBox"]/p[1]/a')
ele.click() # 点击元素往输入框里输入文字并搜索输入内容

import time
# 用的是Chrome,所以导入的是Chrome,如果用其他的,比如IE、火狐可以导入对应的
from selenium.webdriver import Chrome
# 导入包,可以模拟输入键盘上的按键
from selenium.webdriver.common.keys import Keys
# 导入包,可以引用里面的各种方式查找元素
from selenium.webdriver.common.by import By
# 创建浏览器对象
web = Chrome()
# 打开拉勾网
web.get('https://www.lagou.com/')
# 通过xpath找到包含全国字样的元素,然后点击它
ele = web.find_element(by=By.XPATH, value='//*[@id="changeCityBox"]/p[1]/a')
ele.click() # 点击元素
# 有可能搜索框这里会奥错,原因是如果点击全国按钮之后网页刷新,那么输入框可能没有加载出来,就获取不到元素
# 所以如果报错可以先延迟一两秒,等页面加载完成在输入内容搜索
time.sleep(1)
# 通过xpath找到包含搜索框的元素:find_element(by=By.XPATH, value='//*[@id="search_input"]')
# 向搜索框输入Python然后按下键盘上的回车键:send_keys('python', Keys.ENTER)
web.find_element(by=By.XPATH, value='//*[@id="search_input"]').send_keys('python', Keys.ENTER)提取页面中的数据
import time
# 用的是Chrome,所以导入的是Chrome,如果用其他的,比如IE、火狐可以导入对应的
from selenium.webdriver import Chrome
# 导入包,可以模拟输入键盘上的按键
from selenium.webdriver.common.keys import Keys
# 导入包,可以引用里面的各种方式查找元素
from selenium.webdriver.common.by import By
# 创建浏览器对象
web = Chrome()
# 打开拉勾网
web.get('https://www.lagou.com/')
# 通过xpath找到包含全国字样的元素,然后点击它
ele = web.find_element(by=By.XPATH, value='//*[@id="changeCityBox"]/p[1]/a')
ele.click() # 点击元素
# 有可能搜索框这里会奥错,原因是如果点击全国按钮之后网页刷新,那么输入框可能没有加载出来,就获取不到元素
# 所以如果报错可以先延迟一两秒,等页面加载完成在输入内容搜索
time.sleep(2)
# 通过xpath找到包含搜索框的元素:find_element(by=By.XPATH, value='//*[@id="search_input"]')
# 向搜索框输入Python然后按下键盘上的回车键:send_keys('python', Keys.ENTER)
web.find_element(by=By.XPATH, value='//*[@id="search_input"]').send_keys('python', Keys.ENTER)
time.sleep(3)
# 提取数据
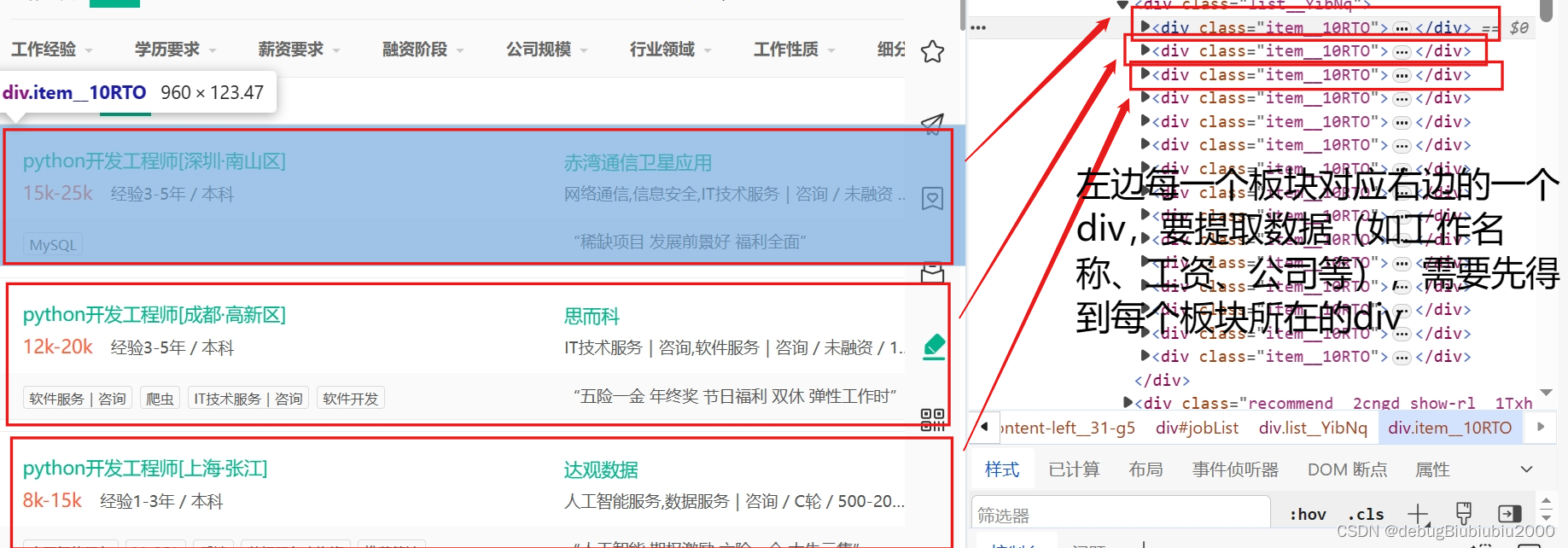
# 1、先根据xpath得到每个板块所在的div元素,这里要提取所有板块,所以用find_elements方法
# 注意,复制的xpath路径为://*[@id="jobList"]/div[1]/div[1]
# 路径最后的[1]是因为我们复制的时候是复制了某一个板块,而这里我们要得到所有的板块,所以要把[1]去掉
divs = web.find_elements(by=By.XPATH, value='//*[@id="jobList"]/div[1]/div')
# 提取每一个板块中的数据,这里提取工作名称、工资、公司名字
for div in divs:
job_name = div.find_element(by=By.ID, value='openWinPostion').text
salary = div.find_element(by=By.CLASS_NAME, value='money__3Lkgq').text
company = (div.find_element(by=By.CLASS_NAME, value='company-name__2-SjF').
find_element(by=By.TAG_NAME, value='a').text)
print(job_name, salary, company)输出结果:

切换不同的窗口进行操作


import time
# 用的是Chrome,所以导入的是Chrome,如果用其他的,比如IE、火狐可以导入对应的
from selenium.webdriver import Chrome
# 导入包,可以模拟输入键盘上的按键
from selenium.webdriver.common.keys import Keys
# 导入包,可以引用里面的各种方式查找元素
from selenium.webdriver.common.by import By
# 创建浏览器对象
web = Chrome()
# 打开拉勾网
web.get('https://www.lagou.com/')
# 通过xpath找到包含全国字样的元素,然后点击它
ele = web.find_element(by=By.XPATH, value='//*[@id="changeCityBox"]/p[1]/a')
ele.click() # 点击元素
# 有可能搜索框这里会奥错,原因是如果点击全国按钮之后网页刷新,那么输入框可能没有加载出来,就获取不到元素
# 所以如果报错可以先延迟一两秒,等页面加载完成在输入内容搜索
time.sleep(2)
# 通过xpath找到包含搜索框的元素:find_element(by=By.XPATH, value='//*[@id="search_input"]')
# 向搜索框输入Python然后按下键盘上的回车键:send_keys('python', Keys.ENTER)
web.find_element(by=By.XPATH, value='//*[@id="search_input"]').send_keys('python', Keys.ENTER)
time.sleep(3)
# 提取数据
# 1、先根据xpath得到每个板块所在的div元素,这里要提取所有板块,所以用find_elements方法
# 注意,复制的xpath路径为://*[@id="jobList"]/div[1]/div[1]
# 路径最后的[1]是因为我们复制的时候是复制了某一个板块,而这里我们要得到所有的板块,所以要把[1]去掉
divs = web.find_elements(by=By.XPATH, value='//*[@id="jobList"]/div[1]/div')
# 提取每一个板块中的数据,这里提取工作名称、工资、公司名字
for div in divs:
job_name = div.find_element(by=By.ID, value='openWinPostion').text
salary = div.find_element(by=By.CLASS_NAME, value='money__3Lkgq').text
company = (div.find_element(by=By.CLASS_NAME, value='company-name__2-SjF').
find_element(by=By.TAG_NAME, value='a').text)
print(job_name, salary, company)
time.sleep(2)
# 切换窗口操作
# 点击岗位名称查看详情
web.find_element(By.XPATH, '//*[@id="openWinPostion"]').click()
# 切换到新打开的窗口,即第2个窗口
web.switch_to.window(web.window_handles[1])
detail = web.find_element(By.XPATH, '//*[@id="job_detail"]/dd[2]').text
print(detail)
# 如果想回到岗位展示页面(即原先的页面),那么先关闭当前页面,在切回去
web.close() # 关闭当前岗位详情页面
# 尝试了一下,不关闭岗位详情页面也可以直接切换到第一个页面
web.switch_to.window(web.window_handles[0]) # 切换回第一个窗口
all = web.find_element(By.XPATH, '//*[@id="jobsContainer"]/div[2]/div[1]/div[1]/div[1]/div[1]/div/div[2]/div[1]')
print(all.text)运行结果:

切换到iframe页面
# 用的是Chrome,所以导入的是Chrome,如果用其他的,比如IE、火狐可以导入对应的
from selenium.webdriver import Chrome
# 导入包,可以引用里面的各种方式查找元素
from selenium.webdriver.common.by import By
# 创建浏览器对象
web = Chrome()
# 访问网页A
web.get('网页A的网址')
# 假设网页A嵌套着一个iframe页面
# 如果要访问iframe页面,首先要拿到iframe这个页面元素
iframe = web.find_element(By.XPATH, 'iframe元素的xpath')
# 然后切换到iframe页面
web.switch_to.frame(iframe)
# 对iframe页面的操作同之前的做法,操作完iframe页面后,想切回去
web.switch_to.default_content() # 切换回网页A的页面下拉框的操作
import time
from selenium.webdriver import Chrome
# 导入下拉框相关的包
from selenium.webdriver.support.select import Select
from selenium.webdriver.common.by import By
# 导入浏览器相关的配置包
from selenium.webdriver.chrome.options import Options
# 配置无头浏览器
# 无头浏览器就是用selenium时不弹出浏览器页面
opt = Options()
opt.add_argument('--headless')
opt.add_argument('--disbale-gpu')
web = Chrome(options=opt)
url = '包含下拉框的网页地址'
web.get(url) # 发起请求
# 获取下拉框元素
sel_ele = web.find_element(by=By.XPATH, value='xxx')
# 将获取到的下拉框元素包装成下拉框菜单
sel = Select(sel_ele)
# 点击下拉框中的每一个选项得到对应的数据
for i in range(len(sel.options)): # sel.options获取下拉框中的所有选项
"""
# 下拉框元素
<select>
<option value='xxx'>text</option>
</select>
"""
# 下列三种方式表示选择某一个选项,然后会发送对应的网络请求获取数据
# sel.select_by_value('xxx') # 通过选项的值获取
# sel.select_by_visible_text('text') # 通过选项的可视文本获取
sel.select_by_index(i) # 通过选项的索引获取
time.sleep(2) # 休眠2秒,等待网络请求返回数据
# 拿到页面代码,就是 右键->检查 那里的HTML代码
# 和页面源代码的区别就是页面源代码不包含js动态加载后的代码(页面源代码就是右键->查看页面源代码)
print(web.page_source)













 342
342











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









