







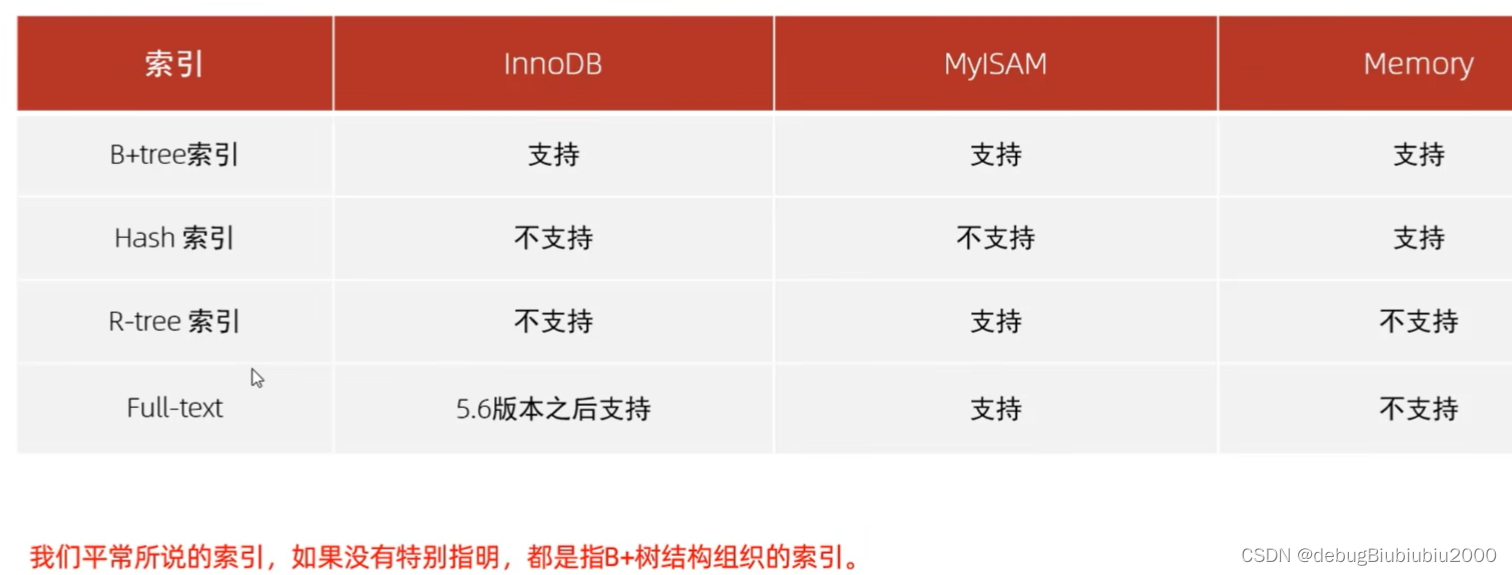
概述


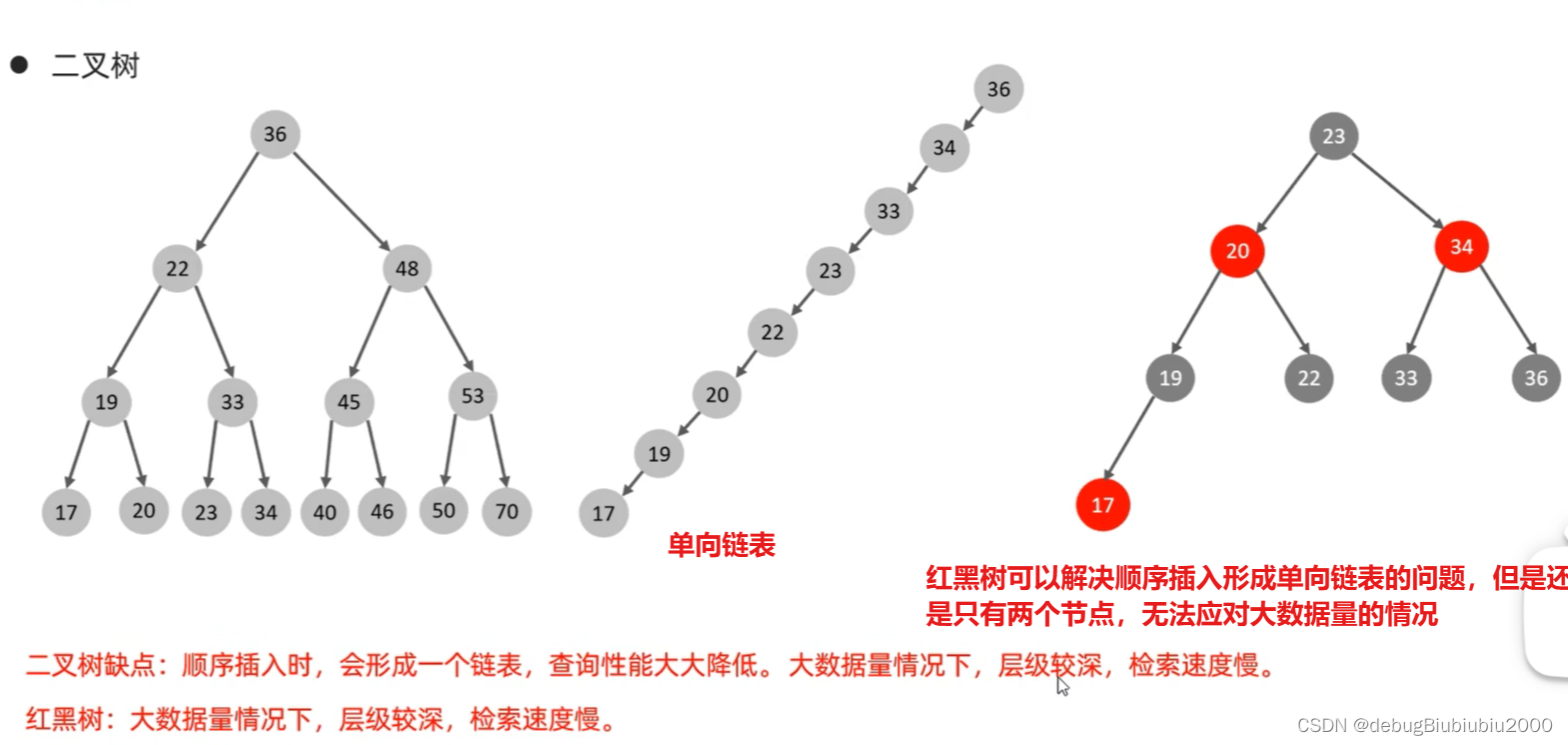
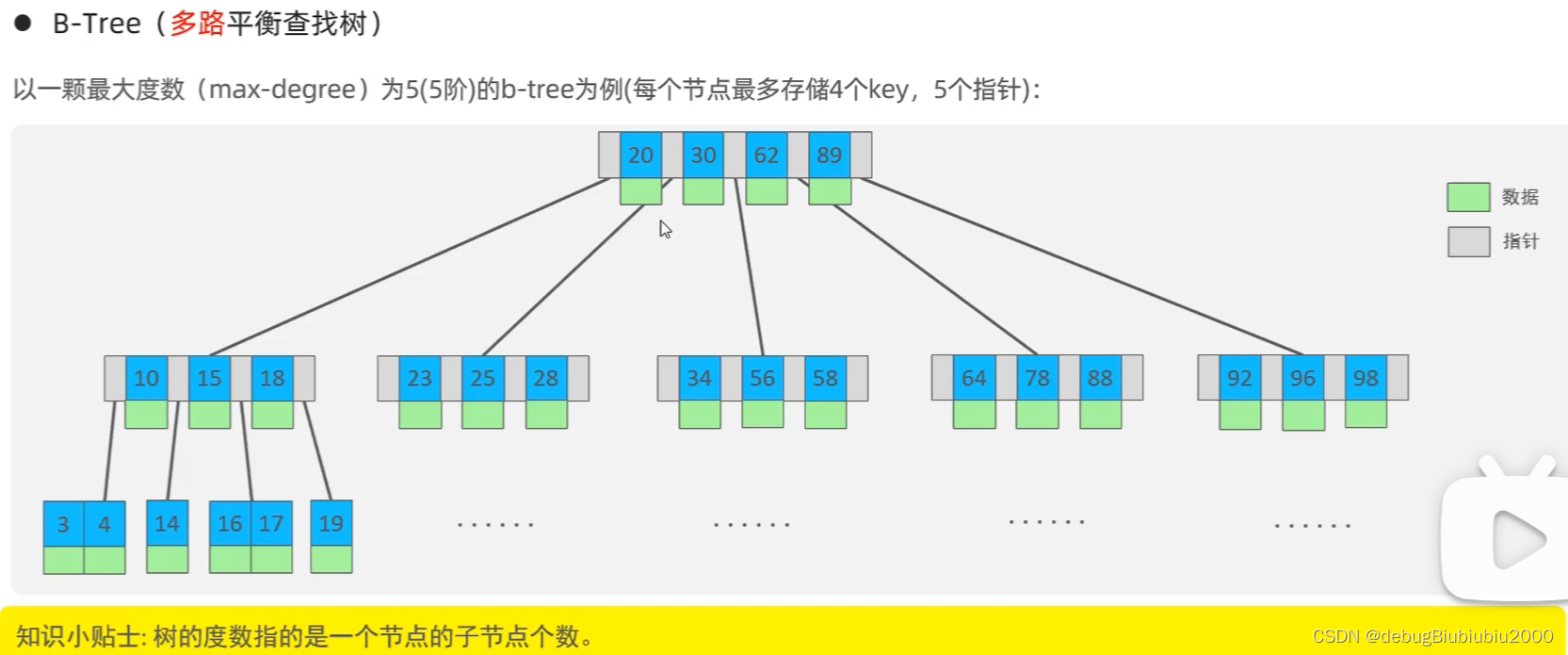
结构

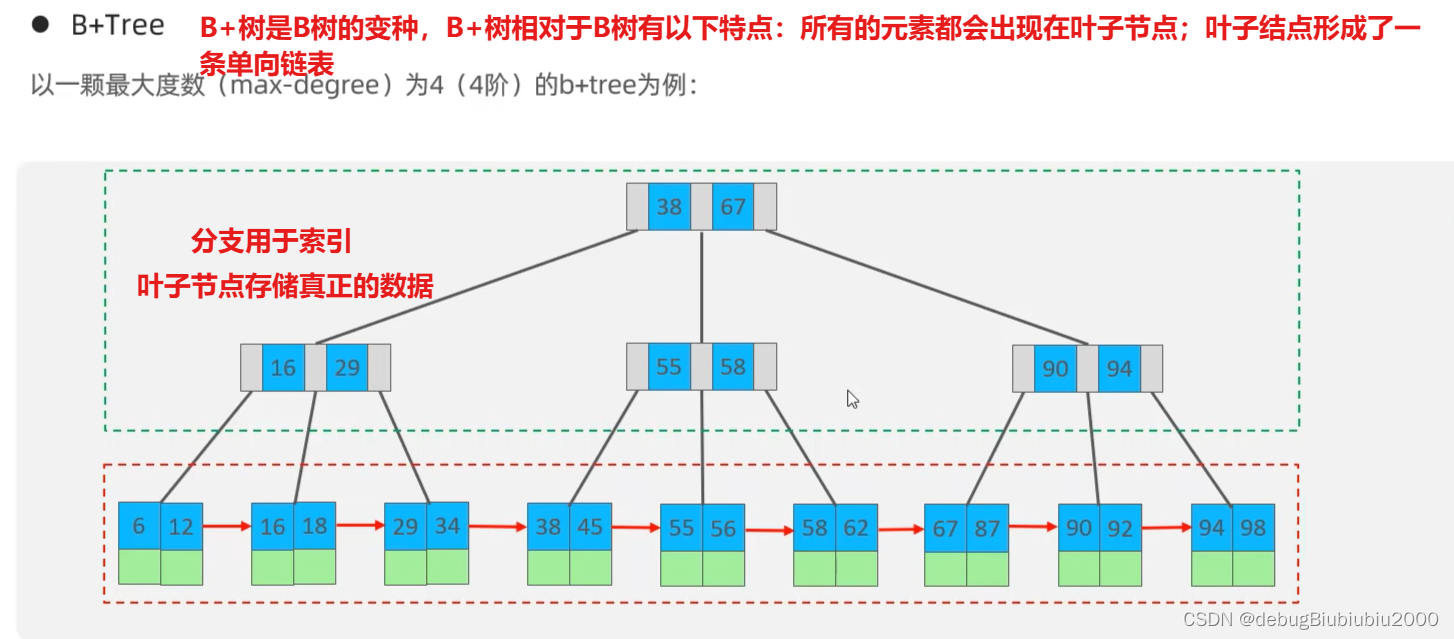
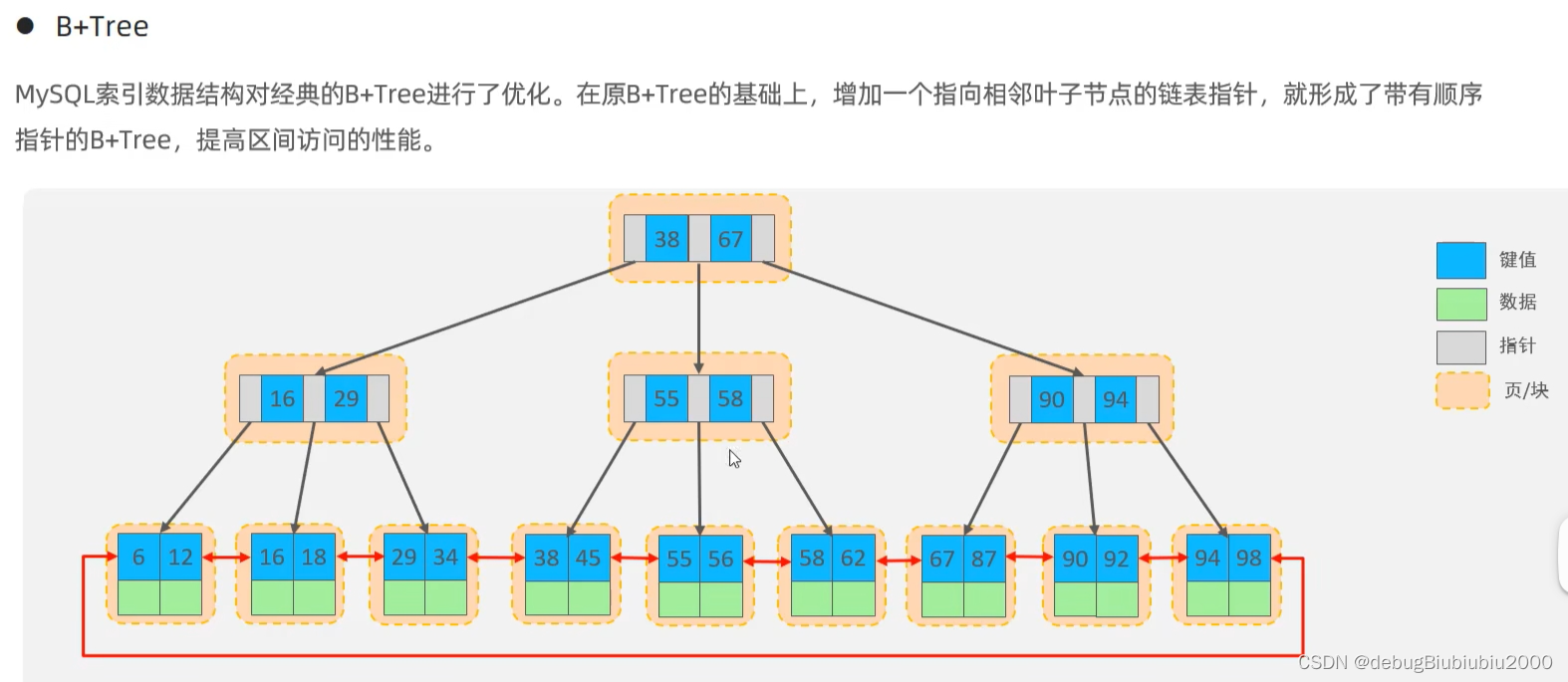
B+树索引
在这里推荐一个可以将个各种数据结构可视化的网站:数据结构可视化
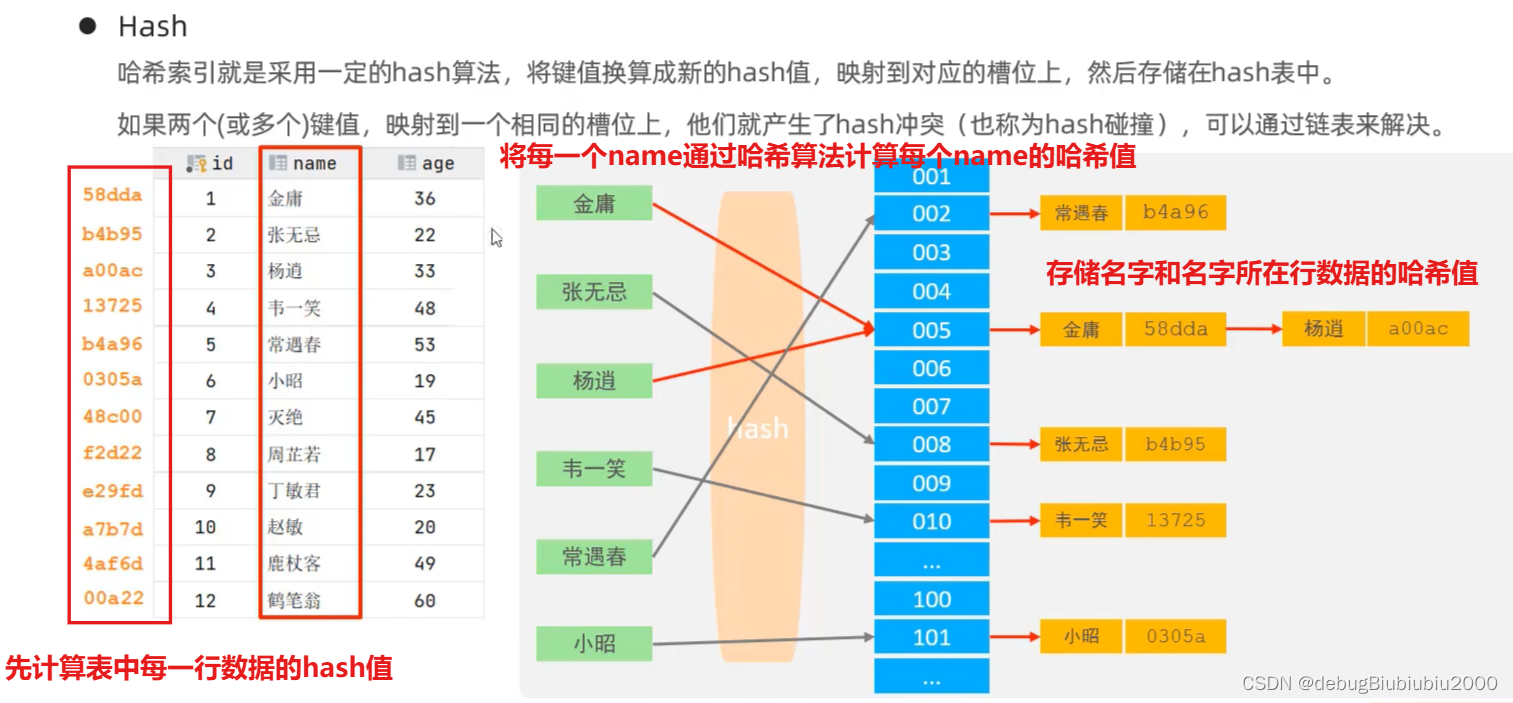
哈希索引

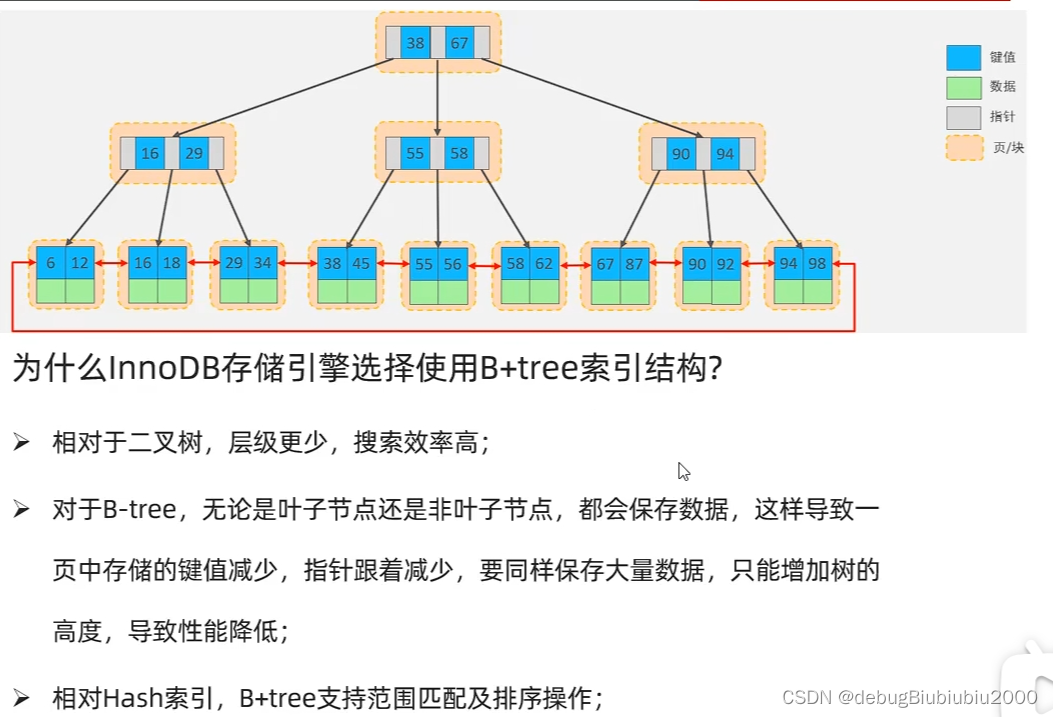
相关的一个面试题
分类

聚集索引和二级索引(非聚集索引)

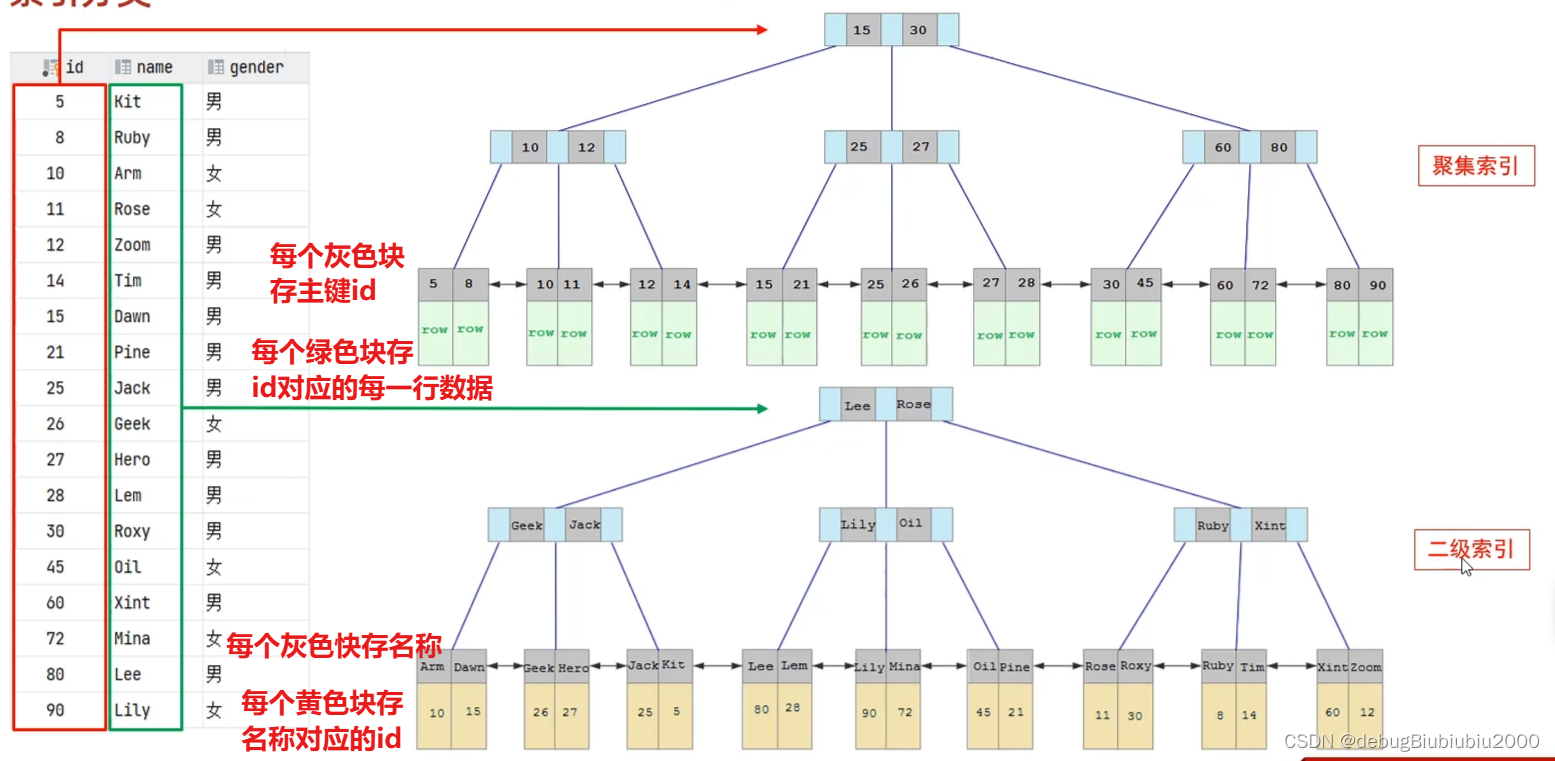
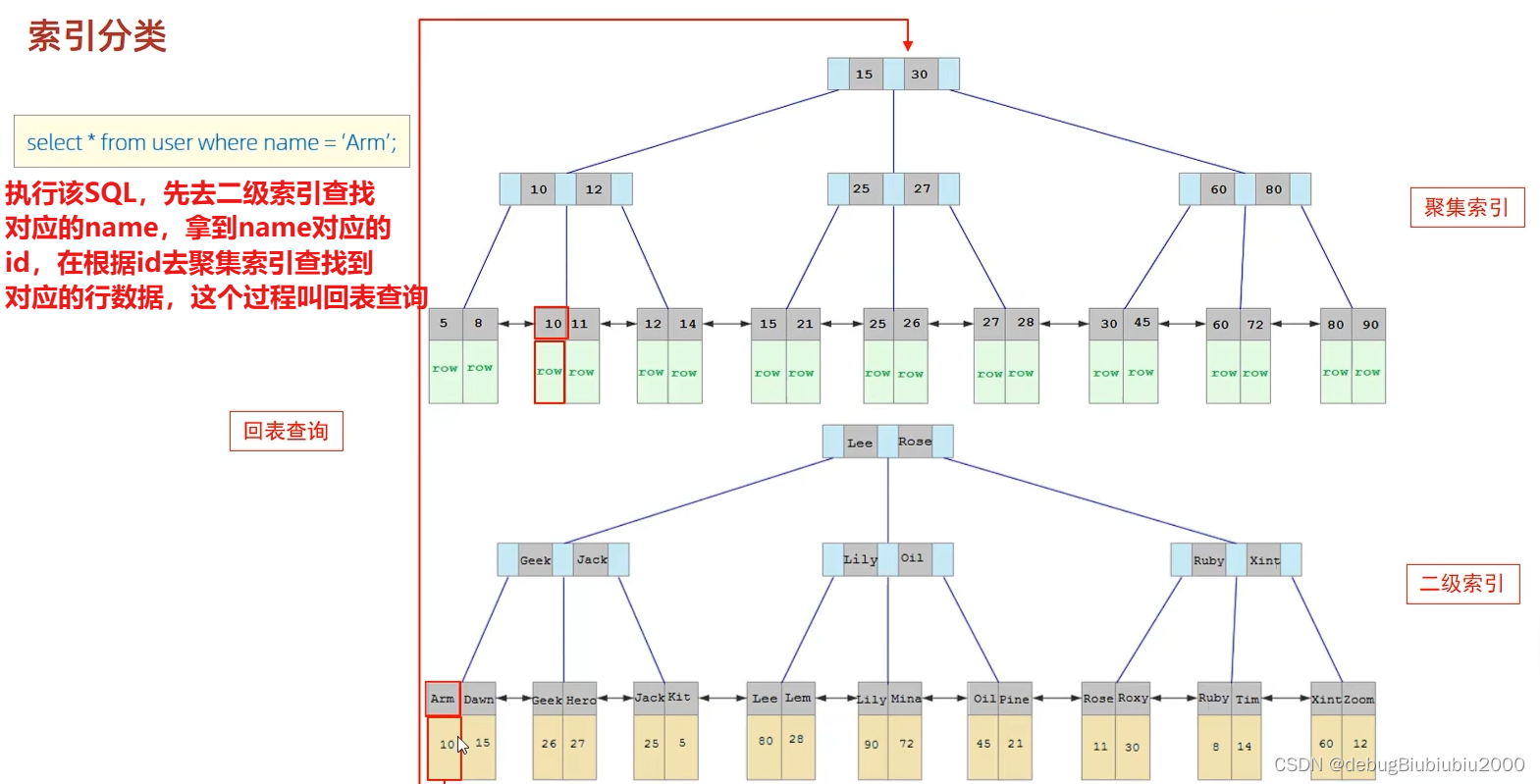
思考题:索引思考题
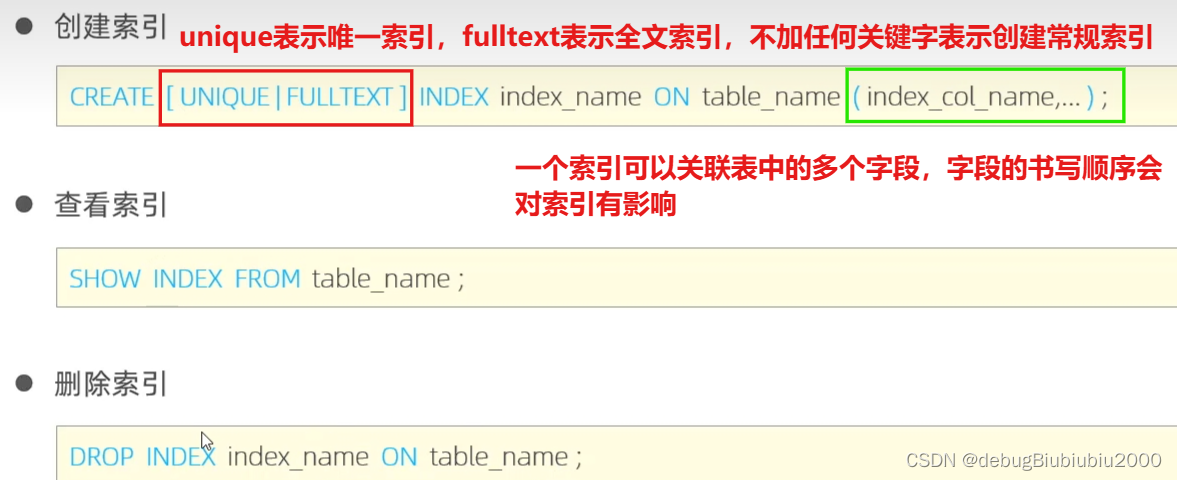
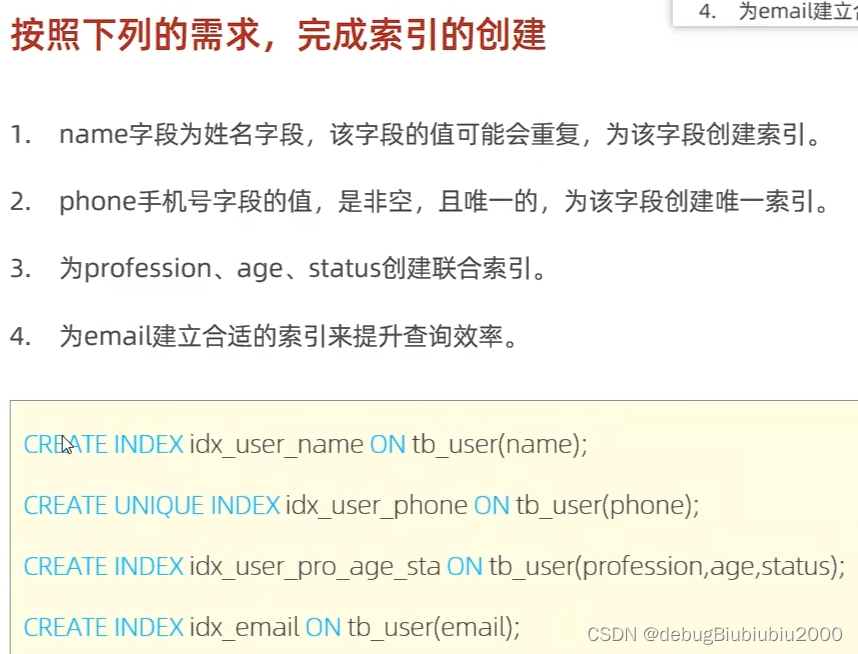
创建索引语法
如果一个索引关联多个字段,那么这个索引叫联合索引或复合查询,字段的书写顺序会影响索引的使用,具体见索引使用规则部分
一般索引名称为index_表名_要建立索引字段名
SQL性能分析
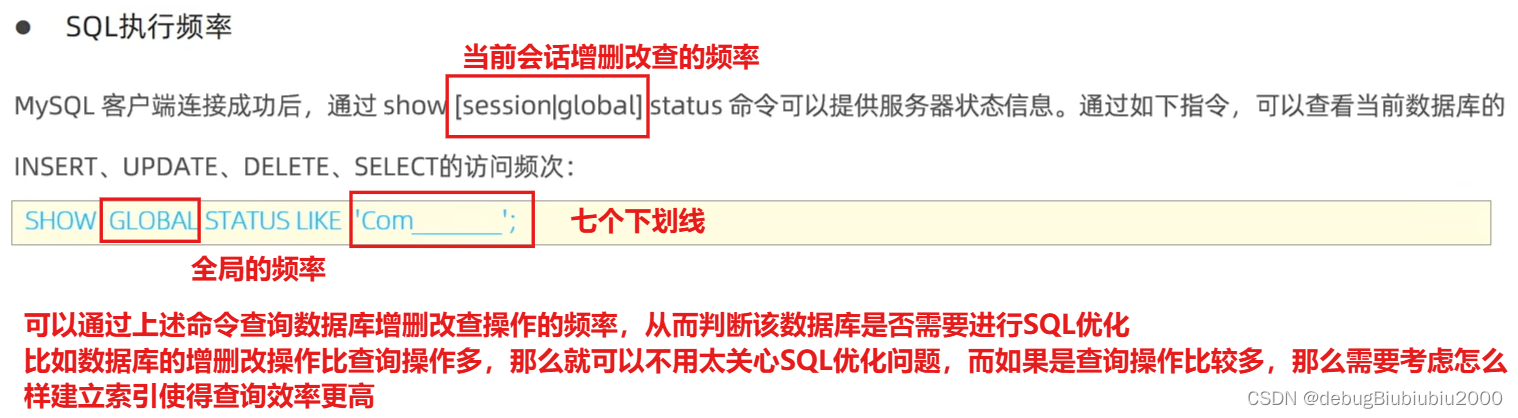
通过命令的方式判断
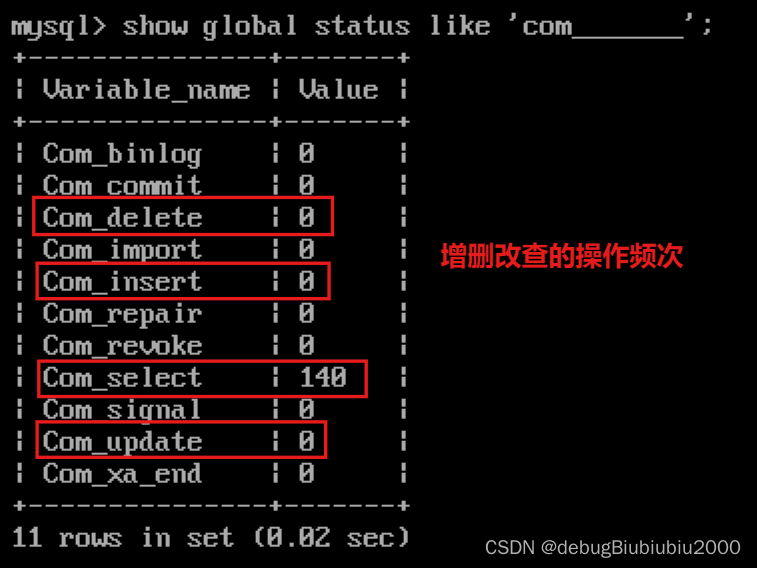
慢查询日志
通过MySQL提供的慢查询日志,可以定位出哪些SQL语句执行的时间超出我们指定的时间,从而可以对这些SQL进行优化。

show profile

expplain执行计划
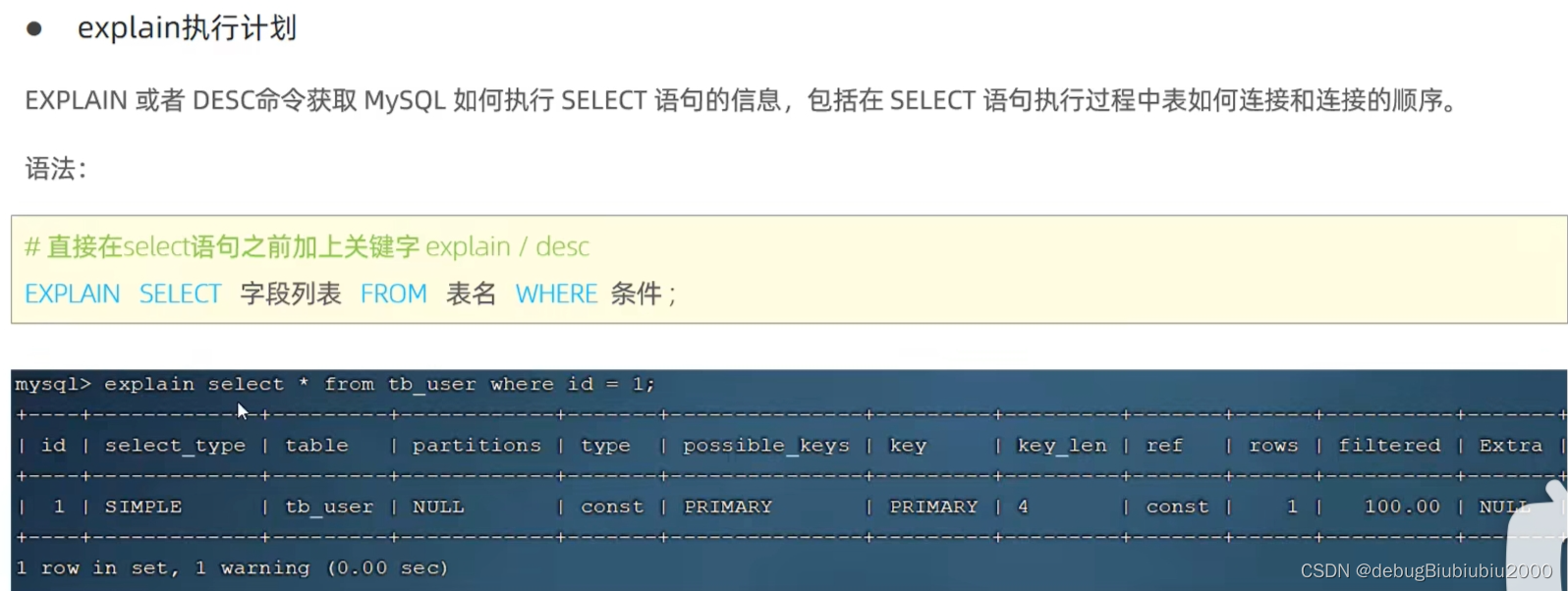
一般SQL优化要关注type、key、key_len、possible_key、extra这几个字段


索引使用规则
造成索引失效的情况
假设现在有一个user表,表中包含name,age,和status三个字段,并为这三个字段创建了联合索引test_index
创建索引:
create index test_index on user(name, age, status);
根据创建索引所书写的字段顺序,索引的最左列字段是name,最右列的字段是status,中间的是age
最左前缀法则
 最左前缀法则如下:
最左前缀法则如下:
当查询时,有以下几种情况:
(1)索引中的三个字段都用上(where后三个字段的顺序不重要):select * from user where name="zs" and age=18 and status=1; 这种情况下三个字段的查询都用上了联合索引test_index
(2)用上了最左边的一个或几个字段:select * from user where name="zs" and age=18; 这种情况下也是name和age两个字段的查询都用上了联合索引test_index
(3)而如果跳过左侧的某个列,那么该列之后的列都不会使用联合索引进行查询,比如跳过了age这一列:select * from user where name="zs" and status=1; 那么age之后(在创建索引时age之后的字段是status)的字段status不会使用联合索引test_index进行查询,而是全表查询。即name使用索引test_index进行查询,而status因为跳过了其左侧的age,所以索引失效,采用全表查询。同理,select * from user where age=18 and status=1; 这个查询里的age和status都索引失效,因为跳过了它们的左侧索引name,age和status采用的是全表查询
上面三种情况是否使用索引查询可以通过在select查询语句前加explain关键字的执行计划进行验证,可以看到执行计划中的key_len在不同的情况下值不一样,值越大说明用上索引的的字段越多
最左前缀法则只要求左侧的列都存在,至于这几个列在where的书写顺序并不重要
范围查询
出现大于小于(>,<)的范围查询时,范围查询右侧的列索引失效
当出现范围查询时,有以下几种情况:
(1)select * from user where name='zs' and age > 20 and status=1; 这种情况下由于age使用了大于的范围查询,所以status字段的索引失效,status使用的全表查询。可以使用大于等于或小于等于来解决这个问题。所以在实际应用中,如果允许则尽量使用>=和<=符号
其他几种情况





当数据库中的大部分数据都符合查询条件,那么就可能全表查询的效率高于索引查询,则采用的就是效率高的全表查询。
比如一张表中大部分数据的name字段都是非空(name字段建立了索引),而查询该表name为空的数据(表中只有少量数据符合条件), 那么此时索引查询的效率高于全表查询,就会采用索引查询。而如果查询的是name不为空的数据(此时表中大部分数据都符合),那么就会采用全表查询。
反之,如果一张表的大部分数据的name都是空(name字段建立了索引),而查询该表name为空的数据(此时表中大量数据符合条件), 那么此时全表查询的效率高于索引查询,就会采用全表查询。而如果查询的是name不为空的数据(表中只有小部分数据符合),那么就会采用索引查询。
SQL提示
SQL提示就是当一个字段有多个索引时,在实际查询时建议/忽略/强制使用哪个索引。比如一个字段即建立了单列索引,又在联合索引中且联合索引生效,那么可以通过下面三个关键字指定MySQL实际查询时使用单列索引还是联合索引

覆盖索引
这个感觉不好做笔记,看视频吧:覆盖索引
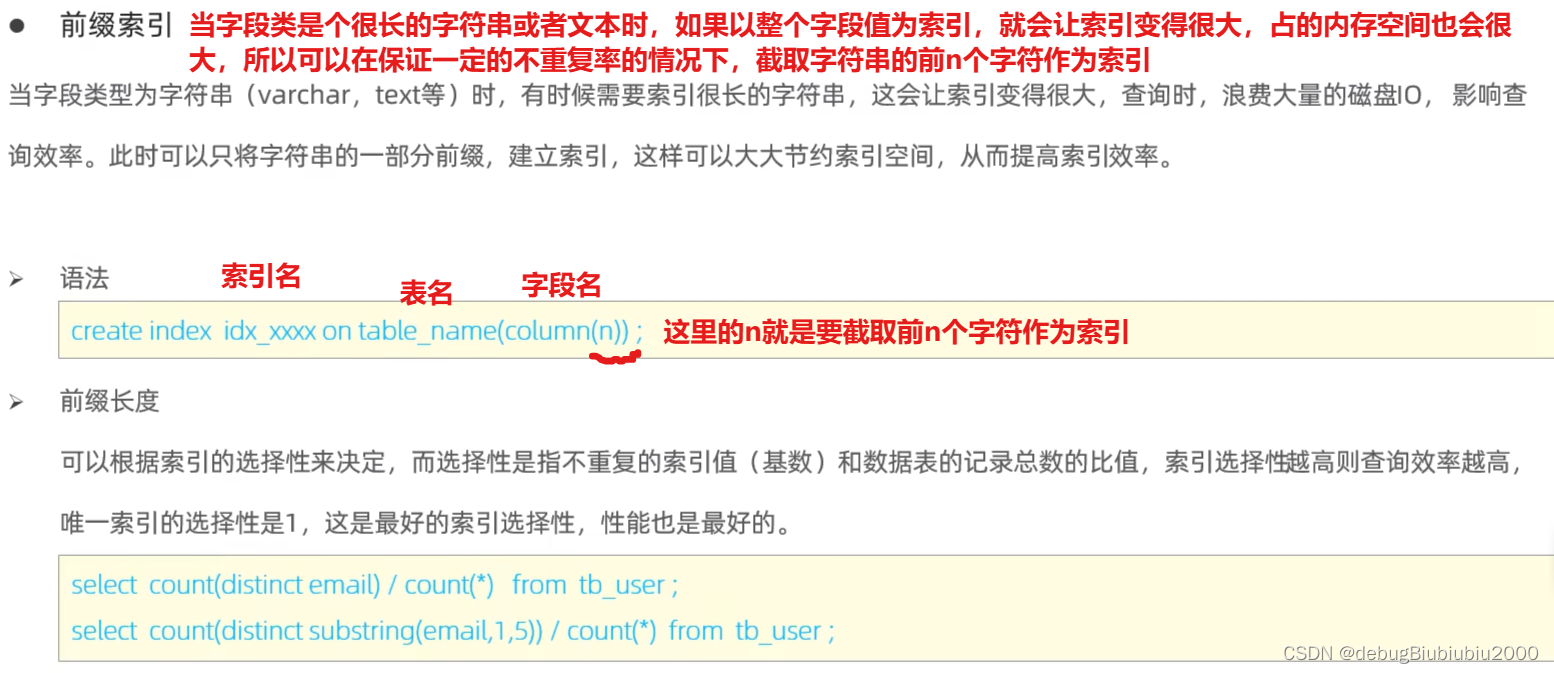
前缀索引
假设下图中的字段email是个长字符串,要对其建立索引。表中所有数据量为total=count(*),表中去重后所有的email总数num=count(distinct email),得到两个数的比值:d1 = num / total;比值d1越大说明email字段的重复率越低,即email的唯一性越高;
如果要判断n的合适取值,就可以看比值d2 = count(distinct substring(email, 1, 5)) / count(*)(SQL中的字符串索引从1开始,这里表示截取前5个字符);综合考量d2的值和n,看实际需求是侧重查找效率还是侧重索引体积,侧重效率则取让d2值大的n,侧重体积则取允许范围内的n
单列索引VS联合索引

索引设计原则
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









