






目录
1.什么是Lambda表达式
Lambda表达式是一个匿名函数,类似于内部类,可以将代码段像数据一样传递,匿名函数顾名思义就是隐藏了函数名。匿名函数格式 (参数)->函数体{ },参数可以有也可以没有。
2.为什么使用Lambda表达式
原先没有Lambda表达式时如要使用线程里的run方法必须实现runnable接口或者继承Thread 类并重写run方法,很麻烦,可能我们只需要run放法里的东西,这时候就可以使用Lambda表达式大大简化代码,所以Lambda表达式又称为“语法糖”。
如不使用Lambda之前
package Demo;
public class Thread1 extends Thread{
@Override
public void run() {
System.out.println("继承了Thread的run方法");
}
}
package Demo;
public class Test {
public static void main(String[] args) {
new Thread1().start();
}
}

使用Lambda表达式后
new Thread(()->{
System.out.println("使用lambda表达式run方法");
}).start();
3.Lambda表达式语法
Lambda表达式在Java语言中引入了一个操作符**“->”**,该操作符被称为Lambda操作符或箭头操作符。它将Lambda分为两个部分:
- 左侧:指定了Lambda表达式需要的所有参数
- 右侧:制定了Lambda体,即Lambda表达式要执行的功能。
-
参数用小括号括起来,用逗号分隔。例如 (a, b) 或 (int a, int b) 或 (String a, int b, float c)。空括号用于表示一组空的参数。例如 () -> 42
-
Lambda表达式的参数列表的数据类型可以省略不写,因为JVM可以通过上下文推断出数据类型,即“类型推断”
-
在执行javac编译程序时,JVM根据程序的上下文推断出了参数的类型。Lambda表达式依赖于上下文环境。
-
注意因为Lambda表达式是靠推断来判断参数的类型的,所以lambda表达式中只允许有一个方法。
4.语法糖
语法糖就是Java中为了简化代码量而设置的语法。如:

5.Stream流
5.1stream流是什么
Stream 是 Java8 的新特性,它允许你以声明式的方式处理数据集合,可以把
5.2为什么要用Stream
import java.util.ArrayList;
import java.util.Arrays;
import java.util.stream.Stream;
public class Stream1 {
public static void main(String[] args) {
ArrayList<Integer> arrayList=new ArrayList();
arrayList.add(1);
arrayList.add(2);
arrayList.add(3);
arrayList.add(4);
Stream<Integer> stream= arrayList.stream();//把集合转化为流
Integer a[]=new Integer[]{1,2,3,4,5};
Stream<Integer> stream1=Arrays.stream(a);//将数组转化为流
Stream stream2= Stream.of(1,2,3,4);
}
}
使用Stream后对于数组,集合一些问题就可以不用for循环解决了,大大简化代码。
int a[]=new int[]{6,1,3,5,7,3};
Arrays.stream(a).sorted().distinct().forEach((e)->{
System.out.print(e);
System.out.print(" ");
});![]()
原先要对数组进行排序去重以及输出,不用api的前提,要for循环遍历,一一比较元素,并定义新数组将排序好的数组装入,并通过for循环输出。
流更偏向于数据处理和计算,比如 filter、map、find、sort 等。
5.3Stream流中的静态方法
(1)中端操作
filter 过滤元素
sorted 排序
distinct 去除重复元素
limit 数量限制
skip 跳过指定元素
forEach() 遍历数组和集合,lambda表达式,隐式函数
map(): 将其映射成一个新的元素
int a[]=new int[]{6,1,3,5,7,3};
Arrays.stream(a).skip(2).limit(2).forEach((e)->{
System.out.print(e);
System.out.print(" ");
});
int sa= Arrays.stream(a).distinct().max().getAsInt();
System.out.println(sa);
int mi=Arrays.stream(a).distinct().min().getAsInt();
System.out.println(mi);
int sum= Arrays.stream(a).distinct().reduce((o1,o2)->{
return o1+o2;
}).getAsInt();
System.out.println(sum);
boolean an=Arrays.stream(a).distinct().anyMatch((o1)->{
return o1>7;
});
System.out.println(an);
long c= Arrays.stream(a).distinct().count();
System.out.println(c);*/结果分别如图所示 (2) 终端操作:把流转化为最终结果 max:返回流中元素最大值 min:返回流中元素最小值 count::返回流中元素最小值 reduce:返回流中所有元素求和 anyMatch:接收一个 Predicate 函数,只要流中有一个元素满足条件则返 回 true,否则返回 false allMatch:接收一个 Predicate 函数,只要流中所有元素满足条件则返 回 true,否则返回 false findFirst:返回第一个元素 toArray:将流中的元素倒入一个数组 collect:将流中的元素倒入一个集合,Collection 或 Map
-
分组操作和分组后再进行排序操作:
-
假设我们有一个包含学生对象的列表,每个学生对象包含姓名和年龄属性。我们想要按照学生的学号进行分组,并且在每个组内按照姓名进行排序。
-
首先,我们定义一个
Student类表示学生对象:
-
public class Student {
int num;
String name;
int age;
public Student(int num, String name, int age) {
this.num = num;
this.name = name;
this.age = age;
}
public int getNum() {
return num;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
@Override
public String toString() {
return "Student{" +
"num=" + num +
", name='" + name + '\'' +
", age=" + age +
'}';
}
}
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
public class Stream3 {
public static void main(String[] args) {
ArrayList<Student> arrayList=new ArrayList<>();
Student s1=new Student(101,"张三",18);
Student s2=new Student(102,"李四",19);
Student s3=new Student(103,"王五",17);
Student s4=new Student(104,"曲艺",20);
arrayList.add(s1);
arrayList.add(s2);
arrayList.add(s3);
arrayList.add(s4);
List<Student> lis= arrayList.stream().sorted((stu1,stu)->{
return stu1.getNum()-stu.getNum();
}).collect(Collectors.toList());
System.out.println(lis);
List<Student> li= arrayList.stream().filter((stu2)->{
return stu2.getAge()>18;
}).collect(Collectors.toList());
System.out.println(li);
Object a[]= arrayList.stream().map(Student::getNum).toArray();
System.out.println(Arrays.toString(a));
}
}
结果如图所示:

6.Maven(项目编译打包软件)
6.1什么是Maven
Maven 是 Apache 软件基金会组织维护的一款专门为 Java 项目提供构建和依赖管理支持的工具。
一个 Maven 工程有约定的目录结构,约定的目录结构对于 Maven 实现自动化构建而言是必不可少的一环,就拿自动编译来说,Maven 必须 能找到 Java 源文件,下一步才能编译,而编译之后也必须有一个准确的位置保持编译得到的字节码文件。 我们在开发中如果需要让第三方工具或框架知道我们自己创建的资源在哪,那么基本上就是两种方式:
通过配置的形式明确告诉它
基于第三方工具或框架的约定 Maven 对工程目录结构的要求。
6.2为什么要使用Maven
原先不使用Maven,java中原来连接数据库必须要自己手动加入相关的包,否则无法连接数据库,有了Maven则不需要手动导入,
如图:

自己手动导入数据库包
使用Maven后则不需要手动导入,只需要提供相关的包地址,Maven就会自动下载,及下载相关的依赖关系。
如图:


6.3Maven 中的相关概念
6.4 Maven 开发环境配置
1.通过官网Apache下载Maven

2. 配置环境变量
Maven 是一个用 Java 语言开发的程序,它必须基于 JDK 来运行,需要通过 JAVA_HOME 来找到 JDK 的安装位置。
首先点击此电脑,选择属性,进入系统信息选择高级系统设计,出现环境变量选项,点击环境变量,找到系统变量里的path选项,点击Path,点击新建,找到安装Maven的地址,复制到bin目录,将该地址粘贴到path新建的地方,








3. 创建模块工程
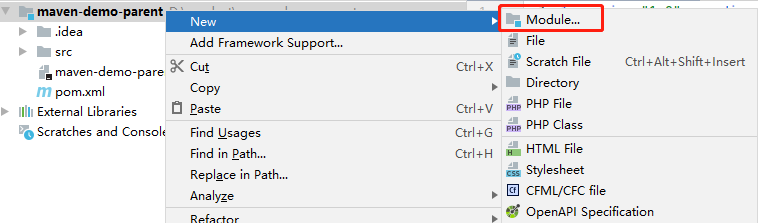
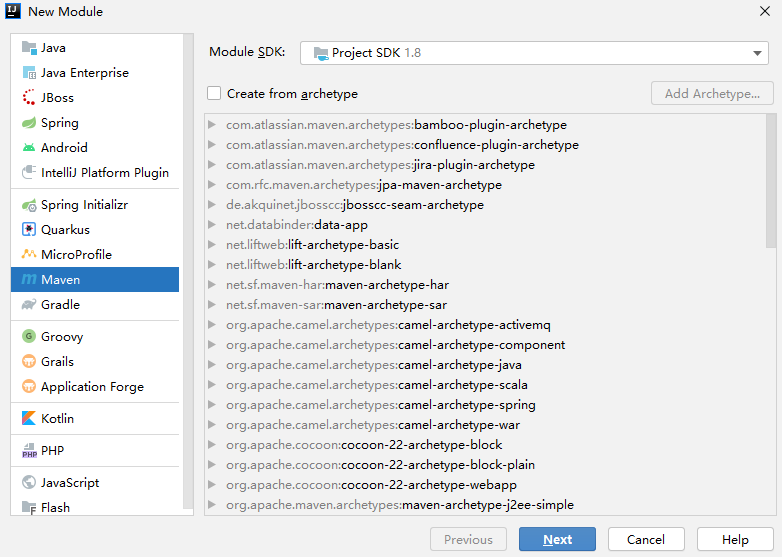
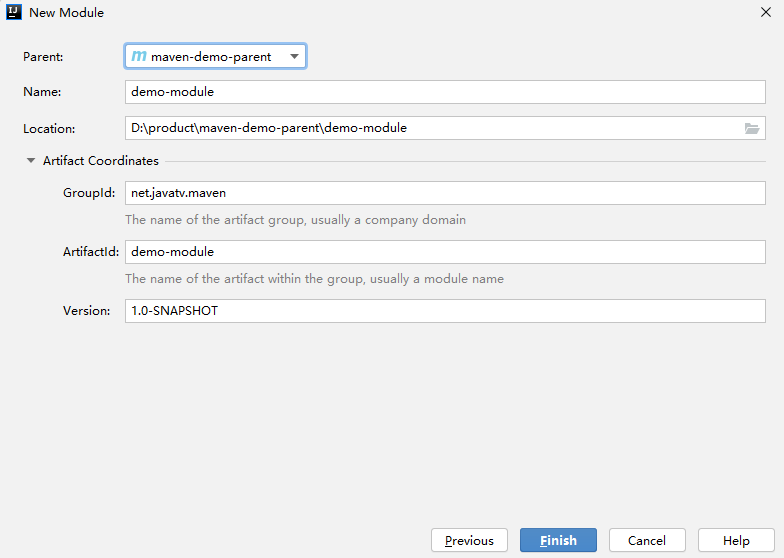
然后可以再工程的 pom 文件中看到:

将需要的地址配置到两个<projiect> 之间

上述位置出现如图所示自己所要配置的包则配置成功。















 235
235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









