








01 案例背景
近年来,随着我国经济技术的不断提升,自动化机械在人们日常生活中扮演着越来越重要的角色,更多的被应用在不同的领域。而作为新的一种自动化零售业态,自动售货机在日常生活中应用越来越广泛。自动售货机销售产业在走向信息化、合理化同时,也面临着高度同质化、成本上升、毛利下降等诸多困难与问题,这也是大多数企业所会面临到的问题。
为了提高市场占有率和企业的竞争力,某企业在广东省某8个市部署了376台自动售货机,但经过一段时间后,发现其经营状况并不理想。而如何了解销售额、订单数量与自动售货机数量之间的关系,畅销或滞销的商品又有哪些,自动售货机的销售情况等,已成为该企业亟待解决的问题。
02 分析目标
获取了该企业某6个月的自动售货机销售数据,结合销售背景进行分析,并可视化展现销售现状,同时预测未来一段时间内的销售额,从而为企业制定营销策略提供一定的参考依据。
03 分析过程
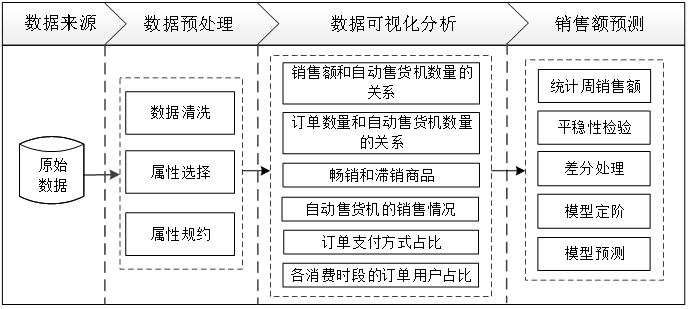
04 数据预处理
1. 清洗数据
1.1 合并订单表并处理缺失值
由于订单表的数据是按月份分开存放的,为了方便后续对数据进行处理和可视化,所以需要对订单数据进行合并处理。同时,在合并订单表的数据后,为了了解订单表的缺失数据的基本情况,需要进行缺失值检测。合并订单表并进行缺失值检测,操作结果如图1所示。
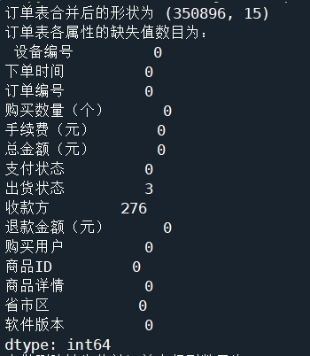
由操作结果可知,合并后的订单数据有350867条记录,且订单表中含有缺失值的记录总共有279条,其数量相对较少,可直接使用删除法对其中的缺失值进行处理。
合并订单表、查看缺失值并处理缺失值,如代码清单1所示。
代码清单1 合并订单表、查看缺失值并处理缺失值
import pandas as pd
# 读取数据
data4 = pd.read_csv('../data/订单表2018-4.csv', encoding='gbk')
data5 = pd.read_csv('../data/订单表2018-5.csv', encoding='gbk')
data6 = pd.read_csv('../data/订单表2018-6.csv', encoding='gbk')
data7 = pd.read_csv('../data/订单表2018-7.csv', encoding='gbk')
data8 = pd.read_csv('../data/订单表2018-8.csv', encoding='gbk')
data9 = pd.read_csv('../data/订单表2018-9.csv', encoding='gbk')
# 合并数据
data = pd.concat([data4, data5, data6, data7, data8, data9], ignore_index=True)
print('订单表合并后的形状为', data.shape)
# 缺失值检测
print('订单表各属性的缺失值数目为:\n', data.isnull().sum())
data = data.dropna(how='any') # 删除缺失值
1.2 增加“市”属性
为了满足后续的数据可视化需求,需要在订单表中增加“市”属性
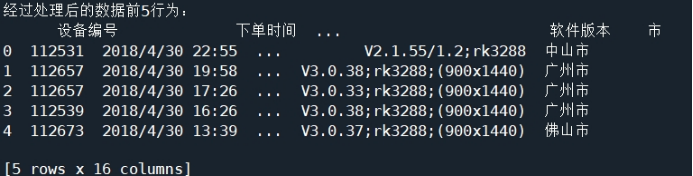
增加“市”属性如代码清单2所示。
代码清单2 增加“市”属性
# 从省市区属性中提取市的信息,并创建新属性
data['市'] = data['省市区'].str[3: 6]
print('经过处理后的数据前5行为:\n', data.head())
1.3 处理订单表中的“商品详情”属性
通过浏览订单表数据发现,在“商品详情”属性中存在有异名同义的情况,即两个名称不同的值所代表的实际意义是一致的,如“脉动青柠X1;”“脉动青柠x1;”等。因为此情况会对后面的分析结果造成一定的影响,所以需要对订单表中的“商品详情”属性进行处理,增加“商品名称”属性,如代码清单3所示。
代码清单3 处理订单表中的“商品详情”属性
# 定义一个需剔除字符的列表error_str
error_str = [' ', '(', ')', '(', ')', '0', '1', '2', '3', '4', '5', '6',
'7', '8', '9', 'g', 'l', 'm', 'M', 'L', '听', '特', '饮', '罐',
'瓶', '只', '装', '欧', '式', '&', '%', 'X', 'x', ';']
# 使用循环剔除指定字符
for i in error_str:
data['商品详情'] = data['商品详情'].str.replace(i, '')
# 新建“商品名称”属性,用于新数据的存放
data['商品名称'] = data['商品详情']
1.4 处理“总金额(元)”属性
此外,当浏览订单表数据时,发现在“总金额(元)”属性中,存在极少订单的金额很小,如0、0.01等。在现实生活中,这种记录存在的情况极少,且这部分数据不具有分析意义。因此,在本案例中,对订单的金额小于0.5的记录进行删除处理
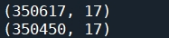
由操作结果可知,删除前的数据行列数目为(350617, 17),删除后的数据行列数目为(350450, 17)。
删除“总金额(元)”属性中订单的金额较少的记录如代码清单4所示。
代码清单4 删除“总金额(元)”属性中订单的金额较少的记录
# 删除金额较少的订单前的数据行列数目
print(data.shape)
# 删除金额较少的订单后的数据行列数目
data = data[data['总金额(元)'] >= 0.5]
print(data.shape)
属性选择
因为订单表中的“手续费(元)”“收款方”“软件版本”“省市区”“商品详情”“退款金额(元)”等属性对本案例的分析没有意义,所以需要对其进行删除处理,选择合适的属性,操作的结果如图4所示。

属性选择如代码清单5所示。
代码清单5 属性选择
# 对于订单表数据选择合适的属性
data = data.drop(['手续费(元)', '收款方', '软件版本', '省市区', '商品详情', '退款金额(元)'], axis=1)
print('选择后,数据属性为:\n', data.columns.values)< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









