






1、资源分配优化
Spark的分配资源主要就是 executor、cpu per executor、memory per executor、driver memory 等的调节,我们在生产环境中,提交spark作业时,用的spark-submit shell脚本,里面调整对应的参数:
/usr/local/spark/bin/spark-submit
–conf spark.default.parallelism=12
–num-executors 3
–executor-cores 2
–executor-memory 2G
–master yarn
–class com.heroking.spark.WordCount spark-word-count.jar
(1)–num-executors
应用运行时executor的数量,num-executors = spark.cores.max / spark.executor.cores,推荐50-100左右比较合适。
(2)–executor-memory
应用运行时每个executor的内存,对Spark作业运行的性能影响很大,适当增加每个executor的内存量,可以提升性能,原因:
- 如果需要对RDD进行cache,那么更多的内存,就可以缓存更多的数据,将更少的数据写入磁盘,甚至不写入磁盘。减少了磁盘IO。
- 对于shuffle操作,reduce端,会需要内存来存放拉取的数据并进行聚合。如果内存不够,也会写入磁盘。如果给executor分配更多内存以后,就有更少的数据,需要写入磁盘,甚至不需要写入磁盘。减少了磁盘IO,提升了性能。
- 对于task的执行,可能会创建很多对象。如果内存比较小,可能会频繁导致JVM堆内存满了,然后频繁GC,垃圾回收,minor GC和full GC。(速度很慢)。内存加大以后,带来更少的GC,垃圾回收,避免了速度变慢,速度变快了。
注意:num-executor*executor-memory的大小绝不能超过队列的内存总大小,保险起见不能超过队列总大小的2/3,因为还有一些调度任务或其它spark任务。
(3)–executor-cores
应用运行时每个executor的CPU核数,决定了每个executor并行执行task的能力,推荐2-4个比较合适。
注意:num-executor*executor-cores也不能超过分配队列中cpu核数的大小,保险起见不能超过队列总大小的2/3,因为还有一些调度任务或其它spark任务。
(4)–driver-memory
应用运行时driver的内存量,通常不必设置,设置的话1G就足够了,主要考虑如果使用map side join或者一些类似于collect的操作,那么要相应调大内存量。
(5)–total-executor-cores
所有executor总共使用的cpu核数 standalone default all cores,一般大公司的集群会有限制不会允许一个任务把资源都用完。
(6)–conf spark.default.parallelism
每个stage经TaskScheduler进行调度时生成的task数量。此参数未设置时将会根据读到的RDD的分区生成task,即根据源数据在hdfs中的分区数确定,若此分区数较小,则处理时只有少量task在处理,前述分配的executor中的core大部分无任务可干。
- 影响
分区数如果远小于集群可用的 CPU 数,不利于发挥 Spark 的性能,还容易导致数据倾斜等问题。
分区数如果远大于集群可用的 CPU 数,会导致资源分配的时间过长,从而影响性能。 - 设置
①task数量,至少设置成与Spark application的总cpu core数量相同(最理想情况,比如总共150个cpu core,分配了150个task,一起运行,差不多同一时间运行完毕)。
②官方是推荐task数量设置成spark application总cpu core数量的2~3倍,比如150个cpu core,基本要设置task数量为300~500。
因为实际情况,与理想情况不同的,有些task会运行的快一点,比如50s就完了,有些task,可能会慢一点,要1分半才运行完,所以如果你的task数量,刚好设置的跟cpu core数量相同,可能还是会导致资源的浪费,因为,比如150个task,10个先运行完了,剩余140个还在运行,但是这个时候,有10个cpu core就空闲出来了,就导致了浪费。那如果task数量设置成cpu core总数的2~3倍,那么一个task运行完了以后,另一个task马上可以补上来,就尽量让cpu core不要空闲,同时也是尽量提升spark作业运行的效率和速度,提升性能。
③程序中如何设置一个Spark Application的并行度?
spark.default.parallelism
SparkConf conf = new SparkConf()
conf.set("spark.default.parallelism", "500")
(7)–conf spark.storage.memoryFraction
每一个executor中用于RDD缓存的内存比例,如果程序中有大量的数据缓存,可以考虑调大整个的比例,默认为60%。但是如果Spark作业中的shuffle类操作比较多,而持久化操作比较少,那么这个参数的值适当降低一些比较合适。此外,如果发现作业由于频繁的gc导致运行缓慢(通过spark web ui可以观察到作业的gc耗时),意味着task执行用户代码的内存(executition memory)不够用,那么同样建议调低这个参数的值。个人不太建议调该参数。
(8)–conf spark.shuffle.memoryFraction
每一个executor中用于Shuffle操作的内存比例,默认是20%,如果Spark作业中的RDD持久化操作较少,shuffle操作较多时,建议降低持久化操作的内存占比,提高shuffle操作的内存占比比例,避免shuffle过程中数据过多时内存不够用,必须溢写到磁盘上,降低了性能。
(9)–conf spark.sql.codegen
默认值为false,当它设置为true时,Spark SQL会把每条查询的语句在运行时编译为java的二进制代码。这有什么作用呢?
由于生成了专门运行指定查询的代码,codegen可以让大型查询或者频繁重复的查询明显变快,然而在运行特别快(1-2秒)的即时查询语句时,codegen就可能增加额外的开销(将查询语句编译为java二进制文件)。codegen还是一个实验性的功能,但是在大型的或者重复运行的查询中使用codegen。
(10)–conf spark.sql.inMemoryColumnStorage.compressed
默认值为false 它的作用是自动对内存中的列式存储进行压缩。
(11)–conf spark.sql.inMemoryColumnStorage.batchSize
默认值为1000 这个参数代表的是列式缓存时的每个批处理的大小。如果将这个值调大可能会导致内存不够的异常,所以在设置这个的参数的时候得注意你的内存大小。
在缓存SchemaRDD(Row RDD)时,Spark SQL会安照这个选项设定的大小(默认为1000)把记录分组,然后分批次压缩。
太小的批处理会导致压缩比过低,而太大的话,比如当每个批处理的数据超过内存所能容纳的大小时,也有可能引发问题。
如果你表中的记录比较大(包含数百个字段或者包含像网页这样非常大的字符串字段),就可能需要调低批处理的大小来避免内存不够(OOM)的错误。如果不是在这样的场景下,默认的批处理 的大小是比较合适的,因为压缩超过1000条压缩记录时也基本无法获得更高的压缩比了。
(12)–conf spark.sql.parquet.compressed.codec
默认值为snappy。这个参数代表使用哪种压缩编码器。可选的选项包括uncompressed/snappy/gzip/lzo uncompressed这个顾名思义就是不用压缩的意思。
(13)–conf spark.speculation
推测执行优化机制采用了典型的以空间换时间的优化策略,它同时启动多个相同task(备份任务)处理相同的数据块,哪个完成的早,则采用哪个task的结果,这样可防止拖后腿Task任务出现,进而提高作业计算速度,但是,这样却会占用更多的资源,在集群资源紧缺的情况下,设计合理的推测执行机制可在多用少量资源情况下,减少大作业的计算时间。
检查逻辑代码中注释很明白,当成功的Task数超过总Task数的75%(可通过参数spark.speculation.quantile设置)时,再统计所有成功的Tasks的运行时间,得到一个中位数,用这个中位数乘以1.5(可通过参数spark.speculation.multiplier控制)得到运行时间门限,如果在运行的Tasks的运行时间超过这个门限,则对它启用推测。简单来说就是对那些拖慢整体进度的Tasks启用推测,以加速整个Stage的运行。
- spark.speculation.interval 100毫秒 Spark经常检查要推测的任务。
- spark.speculation.multiplier 1.5 任务的速度比投机的中位数慢多少倍。
- spark.speculation.quantile 0.75 在为特定阶段启用推测之前必须完成的任务的分数。
(14)–conf spark.shuffle.consolidateFiles
默认值:false
参数说明:如果使用HashShuffleManager,该参数有效。如果设置为true,那么就会开启consolidate机制,会大幅度合并shuffle write的输出文件,对于shuffle read task数量特别多的情况下,这种方法可以极大地减少磁盘IO开销,提升性能。
调优建议:如果的确不需要SortShuffleManager的排序机制,那么除了使用bypass机制,还可以尝试将spark.shffle.manager参数手动指定为hash,使用HashShuffleManager,同时开启consolidate机制。在实践中尝试过,发现其性能比开启了bypass机制的SortShuffleManager要高出10%~30%。
(15)–conf spark.shuffle.file.buffer
默认值:32k
参数说明:该参数用于设置shuffle write task的BufferedOutputStream的buffer缓冲大小。将数据写到磁盘文件之前,会先写入buffer缓冲中,待缓冲写满之后,才会溢写到磁盘。
调优建议:如果作业可用的内存资源较为充足的话,可以适当增加这个参数的大小(比如64k,一定是成倍的增加),从而减少shuffle write过程中溢写磁盘文件的次数,也就可以减少磁盘IO次数,进而提升性能。在实践中发现,合理调节该参数,性能会有1%~5%的提升。
(16)–conf spark.reducer.maxSizeInFlight
默认值:48m
参数说明:该参数用于设置shuffle read task的buffer缓冲大小,而这个buffer缓冲决定了每次能够拉取多少数据。
调优建议:如果作业可用的内存资源较为充足的话,可以适当增加这个参数的大小(比如96m),从而减少拉取数据的次数,也就可以减少网络传输的次数,进而提升性能。在实践中发现,合理调节该参数,性能会有1%~5%的提升。
(17)–conf spark.shuffle.io.maxRetries
默认值:3
参数说明:shuffle read task从shuffle write task所在节点拉取属于自己的数据时,如果因为网络异常导致拉取失败,是会自动进行重试的。该参数就代表了可以重试的最大次数。如果在指定次数之内拉取还是没有成功,就可能会导致作业执行失败。
调优建议:对于那些包含了特别耗时的shuffle操作的作业,建议增加重试最大次数(比如60次),以避免由于JVM的full gc或者网络不稳定等因素导致的数据拉取失败。在实践中发现,对于针对超大数据量(数十亿~上百亿)的shuffle过程,调节该参数可以大幅度提升稳定性。shuffle file not find taskScheduler不负责重试task,由DAGScheduler负责重试stage。
(18)–conf spark.shuffle.io.retryWait
默认值:5s
参数说明:具体解释同上,该参数代表了每次重试拉取数据的等待间隔,默认是5s。
调优建议:建议加大间隔时长(比如60s),以增加shuffle操作的稳定性。
(19)–conf spark.shuffle.memoryFraction
默认值:0.2
参数说明:该参数代表了Executor内存中,分配给shuffle read task进行聚合操作的内存比例,默认是20%。
调优建议:如果内存充足,而且很少使用持久化操作,建议调高这个比例,给shuffle read的聚合操作更多内存,以避免由于内存不足导致聚合过程中频繁读写磁盘。在实践中发现,合理调节该参数可以将性能提升10%左右。
(20)–conf spark.shuffle.manager
默认值:sort | hash
参数说明:该参数用于设置ShuffleManager的类型。Spark 1.5以后,有三个可选项:hash、sort和tungsten-sort。HashShuffleManager是Spark 1.2以前的默认选项,但是Spark 1.2以及之后的版本默认都是SortShuffleManager了。tungsten-sort与sort类似,但是使用了tungsten计划中的堆外内存管理机制,内存使用效率更高。
调优建议:由于SortShuffleManager默认会对数据进行排序,因此如果你的业务逻辑中需要该排序机制的话,则使用默认的SortShuffleManager就可以;而如果你的业务逻辑不需要对数据进行排序,那么建议参考后面的几个参数调优,通过bypass机制或优化的HashShuffleManager来避免排序操作,同时提供较好的磁盘读写性能。这里要注意的是,tungsten-sort要慎用,因为之前发现了一些相应的bug。
(21)–conf spark.shuffle.sort.bypassMergeThreshold
默认值:200
参数说明:当ShuffleManager为SortShuffleManager时,如果shuffle read task的数量小于这个阈值(默认是200),则shuffle write过程中不会进行排序操作,而是按照bypass ShuffleManager的方式去写数据,但是最后会将每个task产生的所有临时磁盘文件都合并成一个文件,并会创建单独的索引文件。
调优建议:当你使用SortShuffleManager时,如果的确不需要排序操作,那么建议将这个参数调大一些,大于shuffle read task的数量。那么此时就会自动启用bypass机制,map-side就不会进行排序了,减少了排序的性能开销。但是这种方式下,依然会产生大量的磁盘文件,因此shuffle write性能有待提高。
2、RDD持久化或缓存
当第一次对RDD2执行算子,获取RDD3的时候,就会从RDD1开始计算,就是读取HDFS文件,然后对RDD1执行算子,获取到RDD2,然后再计算,得到RDD3。
默认情况下,多次对一个RDD执行算子,去获取不同的RDD;都会对这个RDD以及之前的父RDD,全部重新计算一次;读取HDFS->RDD1->RDD2-RDD3。
这种情况,是一定要避免的,一旦出现一个RDD重复计算的情况,就会导致性能急剧降低。比如,HDFS->RDD1->RDD2的时间是15分钟,那么此时就要走两遍,变成30分钟。
另外一种情况,从一个RDD到几个不同的RDD,算子和计算逻辑其实是完全一样的,结果因为人为的疏忽,计算了多次,获取到了多个RDD。
所以,建议采用以下方法进行优化:
(1)RDD架构重构与优化
尽量去复用RDD,差不多的RDD,可以抽取称为一个共同的RDD,供后面的RDD计算时,反复使用。
(2)公共RDD一定要实现持久化
持久化,也就是说,将RDD的数据缓存到内存中/磁盘中,(BlockManager),以后无论对这个RDD做多少次计算,那么都是直接取这个RDD的持久化的数据,比如从内存中或者磁盘中,直接提取一份数据。
(3)持久化,是可以进行序列化的
如果正常将数据持久化在内存中,那么可能会导致内存的占用过大,这样的话,也许,会导致OOM内存溢出。
当纯内存无法支撑公共RDD数据完全存放的时候,就优先考虑,使用序列化的方式在纯内存中存储。将RDD的每个partition的数据,序列化成一个大的字节数组,就一个对象;序列化后,大大减少内存的空间占用。
序列化的方式,唯一的缺点就是,在获取数据的时候,需要反序列化。
如果序列化纯内存方式,还是导致OOM,内存溢出;就只能考虑
①磁盘的方式,②内存+磁盘的普通方式(无序列化),③内存+磁盘(序列化)。
(4)为了数据的高可靠性,如果内存充足,可以使用双副本机制,进行持久化
持久化的双副本机制,持久化后的一个副本,如果机器宕机了,副本就丢了,那么就得重新计算一次;持久化的每个数据单元,存储一份副本,放在其他节点上面,就可以进行容错:一个副本丢了,不用重新计算,还可以使用另外一份副本。这种方式,仅仅针对内存资源极度充足的情况。
sessionid2actionRDD = sessionid2actionRDD.persist(StorageLevel.MEMORY_ONLY());
/**
* 持久化,很简单,就是对RDD调用persist()方法,并传入一个持久化级别
*
* 如果是persist(StorageLevel.MEMORY_ONLY()),纯内存,无序列化,那么就可以用cache()方法来替代
* StorageLevel.MEMORY_ONLY_SER(),第二选择
* StorageLevel.MEMORY_AND_DISK(),第三选择
* StorageLevel.MEMORY_AND_DISK_SER(),第四选择
* StorageLevel.DISK_ONLY(),第五选择
*
* 如果内存充足,要使用双副本高可靠机制
* 选择后缀带_2的策略
* StorageLevel.MEMORY_ONLY_2()
*
*/
3、使用广播变量
广播变量,其实就是SparkContext的broadcast()方法,传入要广播的变量即可
final Broadcast<Map<String, Map<String, IntList>>> broadcast = sc.broadcast(fastutilDateHourExtractMap);
使用广播变量的时候,直接调用广播变量(Broadcast类型)的value() / getValue() ,可以获取到之前封装的广播变量。
Map<String, Map<String, IntList>> dateHourExtractMap = broadcast .value();
背景:
像随机抽取的map,举例1M,还算小的。如果是从哪个表里面读取了一些维度数据,比方说,所有商品品类的信息,在某个算子函数中要使用到100M,1000个task,100G的数据,进行网络传输。集群因为这个原因瞬间消耗掉100G的内存。
这种默认的,task执行的算子中,使用了外部的变量,每个task都会获取一份变量的副本,有什么缺点呢?在什么情况下,会出现性能上的恶劣的影响呢?
map,本身是不小,存放数据的一个单位是Entry,还有可能会用链表的格式的来存放Entry链条。所以map是比较消耗内存的数据格式。
比如map总共是1M,你前面调优都调的特好,资源给的到位,配合着资源,并行度调节的绝对到位,1000个task,大量task的确都在并行运行。这些task里面都用到了占用1M内存的map,那么首先,map会拷贝1000份副本,通过网络传输到各个task中去,给task使用。总计有1G的数据会通过网络传输。网络传输的开销,不容乐观啊!!!网络传输,也许就会消耗掉你的spark作业运行的总时间的一小部分。
map副本,传输到了各个task上之后,是要占用内存的。1个map1M的确不大;1000个map分布在你的集群中,一下子就耗费掉1G的内存。对性能会有什么影响呢?不必要的内存的消耗和占用,就导致了你在将RDD持久化到内存中时,也许就没法完全在内存中放下;就只能写入磁盘,最后导致后续的操作在磁盘IO上消耗性能。
你的task在创建对象的时候,也许会发现堆内存中放不下所有对象,也许就会导致频繁的垃圾回收(GC)。GC的时候,一定会导致工作线程停止,也就是导致Spark暂停工作一段时间。频繁GC的话,对Spark作业的运行的速度会有相当大的影响。
如果说,task使用大变量(1m~100m),明知道会导致性能出现恶劣的影响,那么我们怎么来解决呢?
广播(Broadcast),将大变量广播出去,而不是直接使用。
广播变量的好处,不是每个task一份变量副本,而是变成每个节点的executor才一份副本。这样的话,就可以让变量产生的副本大大减少。
广播变量,初始的时候,就在Drvier上有一份副本。task在运行的时候,想要使用广播变量中的数据,此时首先会在自己本地的Executor对应的BlockManager中,尝试获取变量副本;如果本地BlockManager没有,也许会从远程的Driver上面去获取变量副本;也有可能从距离比较近的其他节点的Executor的BlockManager上去获取,并保存在本地的BlockManager中;BlockManager负责管理某个Executor对应的内存和磁盘上的数据,此后这个executor上的task,都会直接使用本地的BlockManager中的副本。
比如,50个executor,1000个task,一个map10M:
默认情况下,1000个task,1000份副本。10G的数据,网络传输,在集群中耗费10G的内存资源。
如果使用了广播变量,50个execurtor,50个副本。500M的数据,网络传输500M的内存消耗,而且不一定都是从Driver传输到每个节点,还可能是就近从最近的节点的executor的bockmanager上拉取变量副本,网络传输速度大大增加。
(1)创建广播变量的两种方式:
-
从普通变量创建广播变量
在广播变量的运行机制下,普通变量存储的数据封装成广播变量,由 Driver 端以 Executors 为粒度进行分发,每一个 Executors 接收到广播变量之后,将其交由 BlockManager管理。 -
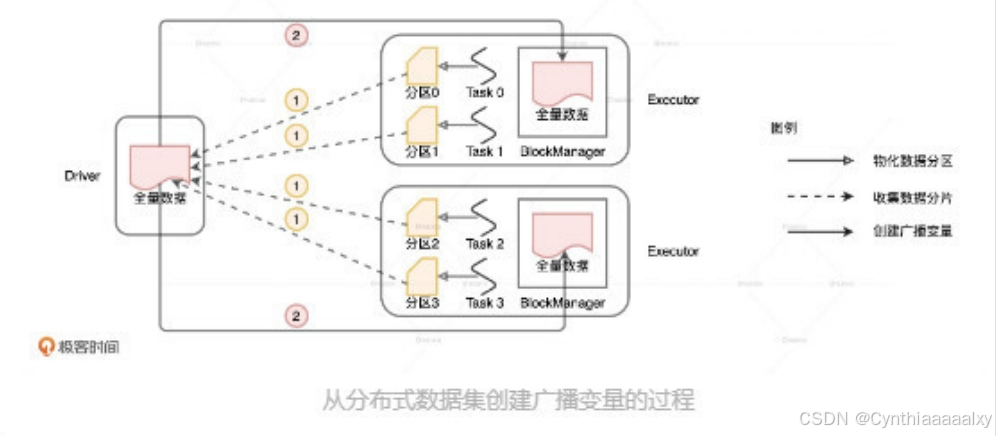
从分布式数据集创建广播变量
这就要比第一种方式复杂一些了。第一步,Driver需要从所有的 Executors 拉取数据分片,然后在本地构建全量数据;第二步,Driver 把汇总好的全量数据分发给各个 Executors,Executors 再将接收到的全量数据缓存到存储系统的 BlockManager 中。
结合这两种方式,我们在做数据关联的时候,把 Shuffle Joins 转换为 Broadcast Joins 就可以用小表广播来代替大表的全网分发,真正做到克制Shuffle。
(2)让spark选择Broadcast Joins的方法:
1、设置 autoBroadcastJoinThreshold 配置项。开发者通过这个配置项指示 Spark SQL 优化器。只要参与 Join 的两张表中,有一张表的尺寸小于这个参数值,就在运行时采用 Broadcast Joins 的实现方式。
为了让 Spark SQL 采用 Broadcast Joins,开发者要做的,就是让数据表在内存中的尺寸小于autoBroadcastJoinThreshold 参数的设定值。
此外,在设置广播阈值的时候,因为磁盘数据展开到内存的时候,存储大小会成倍增加,往往导致 Spark SQL无法采用 Broadcast Joins 的策略。因此,我们在做数据关联的时候,还要先预估一张表在内存中的存储大小。一种精确的预估方法是先把 DataFrame 缓存,然后读取执行计划的统计数据。
2、用 API强制广播有两种方法,分别是设置Join Hints 和用 broadcast 函数。
设置Join Hints 的方法就是在 SQL结构化查询语句里面加上一句“/+ broadcast(某表)/”的提示就可以了。

或者

这里的 broadcast 关键字也可以换成 broadcastjoin 或者 mapjoin。另外,你也可以在 DataFrame 的 DSL 语法中使用调用 hint 方法,指定 broadcast 关键字,来达到同样的效果。设置 broadcast 函数的方法非常简单,只要用 broadcast 函数封装需要广播的数据表就可以了。

总的来说,不管是设置配置项还是用 API强制广播都有各自的优缺点,所以,以广播阈值配置为主、强制广播为辅,往往是一个不错的选择。
4、使用Kryo序列化
在SparkConf中设置一个属性,spark.serializer,org.apache.spark.serializer.KryoSerializer类;注册你使用到的一些自定义类,需要通过Kryo序列化。
SparkConf.registerKryoClasses()
SparkConf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.registerKryoClasses(new Class[]{CategorySortKey.class})
Kryo之所以没有被作为默认的序列化类库,主要是因为Kryo的一些要求,如果要达到它的最佳性能的话,那么就一定要注册你自定义的类(比如,你的算子函数中使用到了外部自定义类型的对象变量,这时,就要求必须注册你的类,否则Kryo达不到最佳性能)。
当使用了序列化的持久化级别时,在将每个RDD partition序列化成一个大的字节数组时,就会使用Kryo进一步优化序列化的效率和性能。默认情况下,Spark内部是使用Java的序列化机制,ObjectOutputStream / ObjectInputStream,对象输入输出流机制,来进行序列化。
这种默认序列化机制的好处在于,处理起来比较方便;也不需要我们手动去做什么事情,只是,你在算子里面使用的变量,必须是实现Serializable接口的,可序列化即可。但是缺点在于,默认的序列化机制的效率不高,序列化的速度比较慢;序列化以后的数据,占用的内存空间相对还是比较大。
Spark支持使用Kryo序列化机制。Kryo序列化机制,比默认的Java序列化机制速度要快,序列化后的数据要更小,大概是Java序列化机制的1/10。所以Kryo序列化优化以后,可以让网络传输的数据变少;在集群中耗费的内存资源大大减少。在进行stage间的task的shuffle操作时,节点与节点之间的task会互相大量通过网络拉取和传输文件,此时,这些数据既然通过网络传输,也是可能要序列化的,就会使用Kryo。
Kryo序列化机制,一旦启用以后,会生效的几个地方:
1、算子函数中使用到的外部变量,使用Kryo以后:优化网络传输的性能,可以优化集群中内存的占用和消耗
2、持久化RDD,StorageLevel.MEMORY_ONLY_SER优化内存的占用和消耗;持久化RDD占用的内存越少,task执行的时候,创建的对象,就不至于频繁的占满内存,频繁发生GC。
3、Shuffle:可以优化网络传输的性能。
5、数据本地化级别
数据本地化:数据离计算它的代码有多近。基于数据距离代码的距离,有几种数据本地化级别:
-
PROCESS_LOCAL
数据和计算它的代码在同一个Executor JVM进程中。 -
NODE_LOCAL
数据和计算它的代码在同一个节点,但不在同一个进程中,比如在不同的executor进程中,或者是数据在HDFS文件的block中。因为数据需要在不同的进程之间传递或从文件中读取。分为两种情况,第一种:task 要计算的数据是在同一个 worker 的不同 Executor 进程中。第二种:task 要计算的数据是在同一个 worker 的磁盘上,或在 HDFS 上恰好有 block 在同一个节点上。如果 Spark 要计算的数据来源于 HDFS 上,那么最好的本地化级别就是 NODE_LOCAL。 -
NO_PREF
从任何地方访问数据速度都是一样,不关心数据的位置。 -
RACK_LOCAL
机架本地化,数据在同一机架的不同节点上。需要通过网络传输数据以及文件 IO,比 NODE_LOCAL 慢。情况一:task 计算的数据在 worker2 的 EXecutor 中。情况二:task 计算的数据在 work2 的磁盘上。 -
ANY
数据可能在任何地方,比如其他网络环境内,或者其他机架上。越往前的级别等待时间应该设置的长一点,因为越是前面性能越好。
根据“数据不动代码动”的原则,Spark Core 优先尊重数据分片的本地位置偏好,尽可能地将计算任务分发到本地计算节点去处理。显而易见,本地计算的优势来源于网络开销的大幅减少,进而从整体上提升执行性能。
Spark在Driver上,对Application的每一个stage的task,进行分配之前,都会计算出每个task要计算的是哪个分片数据,RDD的某个partition;Spark的task分配算法,优先会希望每个task正好分配到它要计算的数据所在的节点,这样的话,就不用在网络间传输数据。
但是可能task没有机会分配到它的数据所在的节点,因为可能那个节点的计算资源和计算能力都满了;这种时候,Spark会等待一段时间,默认情况下是3s(不是绝对的,还有很多种情况,对不同的本地化级别,都会去等待),到最后,实在是等待不了了,就会选择一个比较差的本地化级别,比如说,将task分配到靠它要计算的数据所在节点,比较近的一个节点,然后进行计算。
但是对于第二种情况,通常来说,肯定是要发生数据传输,task会通过其所在节点的BlockManager来获取数据,BlockManager发现自己本地没有数据,会通过一个getRemote()方法,通过TransferService(网络数据传输组件)从数据所在节点的BlockManager中,获取数据,通过网络传输回task所在节点。
对于我们来说,当然不希望是类似于第二种情况的了。最好的,当然是task和数据在一个节点上,直接从本地executor的BlockManager中获取数据,纯内存,或者带一点磁盘IO;如果要通过网络传输数据的话,性能肯定会下降的,大量网络传输,以及磁盘IO,都是性能的杀手。
什么时候要调节这个参数?
观察日志,spark作业的运行日志,推荐大家在测试的时候,先用client模式,在本地就直接可以看到比较全的日志。日志里面会显示,starting task… …,PROCESS LOCAL、NODE LOCAL。观察大部分task的数据本地化级别,如果大多都是PROCESS_LOCAL,那就不用调节了。如果发现很多级别都是NODE_LOCAL、ANY,那么最好就去调节一下数据本地化的等待时长。调节完,应该是还要反复调节,每次调节完以后再来运行,观察日志,看看大部分的task的本地化级别有没有提升;看看整个spark作业的运行时间有没有缩短。
但是注意别本末倒置,本地化级别倒是提升了,但是因为大量的等待时长,spark作业的运行时间反而增加了,那就还是不要调节了。
spark.locality.wait,默认是3s;可以改成6s,10s。默认情况下,下面3个的等待时长,跟上面那个是一样的,都是3s。
spark.locality.wait.process
spark.locality.wait.node
spark.locality.wait.rack
new SparkConf()
.set("spark.locality.wait", "10")

















 2685
2685

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









