






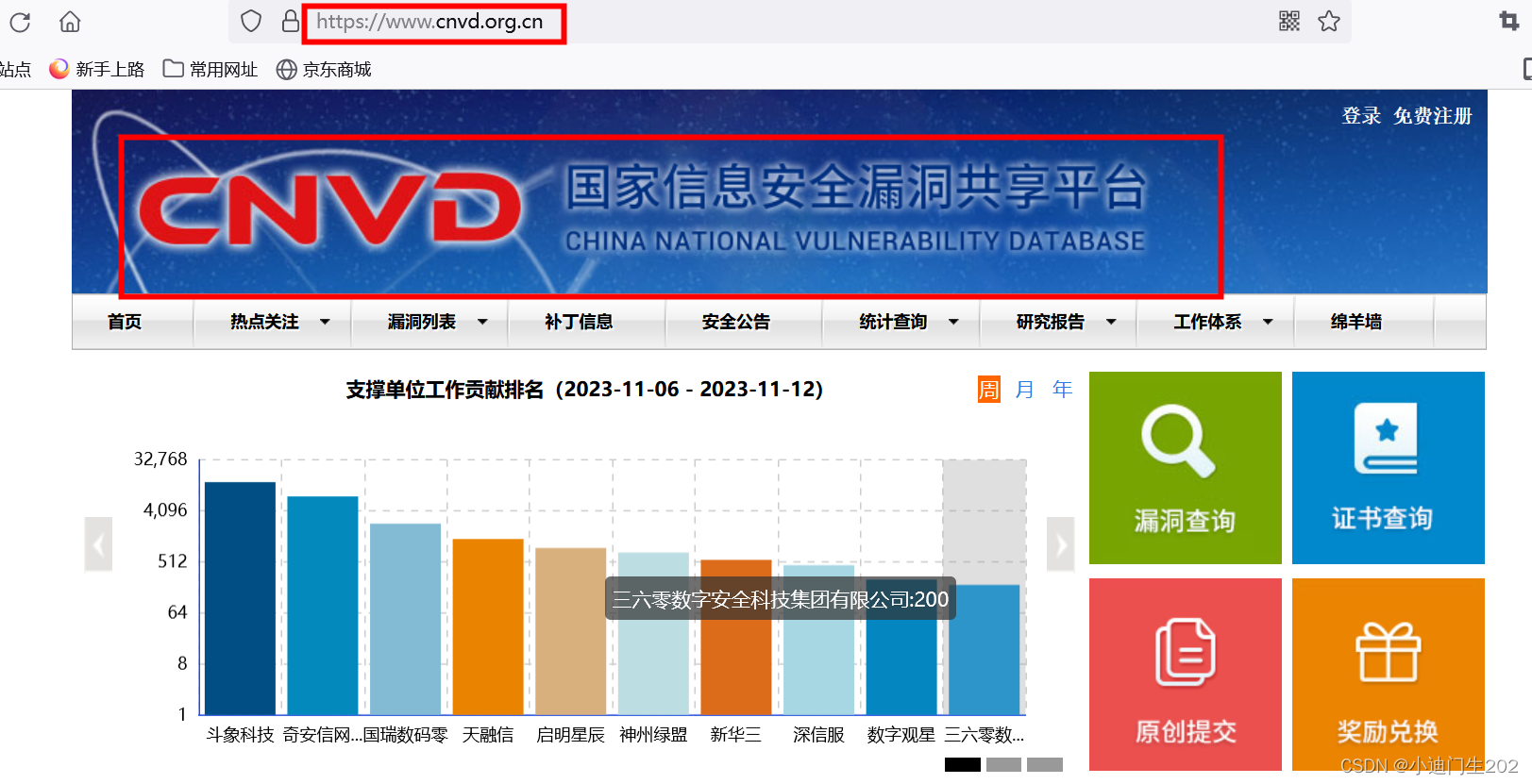
一、CNVD
国家信息安全漏洞共享平台(China National Vulnerability Database):CNVD的主要目标即与国家政府部门、重要信息系统用户、运营商、主要安全厂商、软件厂商、科研机构、公共互联网用户等共同建立软件安全漏洞统一收集验证、预警发布及应急处置体系,切实提升我国在安全漏洞方面的整体研究水平和及时预防能力,进而提高我国信息系统及国产软件的安全性,带动国内相关安全产品的发展。

二、CNNVD
国家信息安全漏洞库(China National Vulnerability Database of Information Security):是中国信息安全测评中心(中文简称:国测,英文简称:CNITSEC,China Information Technology Security Evaluation Center)为切实履行 漏洞分析 和 风险评估 的职能,负责建设运维的国家信息安全漏洞库,面向国家、行业和公众提供灵活多样的信息安全数据服务,为我国信息安全保障提供基础服务。CNNVD在国家专项经费支持下,负责建设运维的国家级信息安全漏洞数据管理平台,旨在为我国信息安全保障提供服务。
官网地址:https://www.cnnvd.org.cn/home/childHome


















 1123
1123

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









