







#数据可视化
#python
分布类可视化图像,如直方图、箱线图和密度图,在数据分析中具有重要意义。它们能够直观展示数据的分布特征、揭示异常值、对比不同数据集的差异,并辅助假设检验。通过这些图像,我们可以快速识别数据问题,进行数据清理和预处理,为后续分析提供有力支持。总之,分布类可视化不仅帮助我们更好地理解数据,还为决策提供了重要依据。
本篇文章将介绍直方图、箱线图、密度图、小提琴图、累计频率图、散点图以及茎叶图。
一、直方图
1、概念
直方图是一种用于展示数据分布的图表,它通过将数据范围划分为多个连续的区间(或称为“桶”),并显示每个区间内数据的频数或频率。直方图的横轴表示数据的数值范围,纵轴表示每个区间内的数据数量或比例。通过直方图,能够直观地看到数据的集中趋势、离散程度、分布形态以及是否存在偏态或异常值,是理解数据分布特征的重要工具。
2、特点
-
数据分组: 直方图将数据划分为多个连续的区间(或“桶”),每个区间代表数据的一部分。这些区间的宽度通常相等,但在某些情况下也可以根据数据特性进行调整。
-
显示频率: 直方图的纵轴通常表示每个区间内的数据频数或频率,即落在该区间内的数据点数量或该区间数据占总数据的比例。
-
连续性: 直方图适用于连续型数据,因为它能够展示数据在数值范围内的分布情况,且区间是相互连接的,形成一个连续的条形图。
-
形态分析: 直方图能够帮助分析数据的分布形态,例如是否呈现正态分布、是否存在偏态(右偏或左偏)或多峰分布等。
-
适用性广: 直方图适用于各种类型的统计分析,尤其是在需要了解数据分布、趋势或分散情况时,广泛应用于各类数据分析领域。
-
可调整的区间宽度: 直方图的区间宽度(即桶的大小)对图形的效果有很大影响。较小的区间宽度会显示出数据的细节,而较大的区间宽度则更能展示整体趋势。选择适当的区间宽度对于直方图的解释至关重要。
-
易于比较不同数据集: 通过并排显示多个数据集的直方图,可以方便地比较它们的分布差异、集中趋势、离散程度等特征。
3、应用场景
-
数据分布分析: 直方图最常见的应用是用于分析数据的分布情况。它可以帮助我们了解数据是集中在某个范围内,还是分散在较广泛的区间中。通过观察直方图的形态,我们可以判断数据是否呈正态分布,是否存在偏态或多峰分布等。
-
识别异常值: 通过直方图,我们可以直观地识别数据中的异常值或极端值。例如,若某个区间的频数异常高或低,可能说明数据中存在异常值,这些值需要进一步检查或处理。
-
数据清洗与预处理: 在数据清洗和预处理阶段,直方图可以帮助识别数据的异常、缺失或不一致问题。例如,如果某个变量的值异常集中或分布不均匀,可能需要对数据进行转换、归一化或修复。
-
质量控制: 直方图广泛应用于质量控制领域,特别是在生产过程中,用于分析产品尺寸、重量或其他关键指标的分布。通过观察产品的分布特征,企业可以判断生产是否稳定,是否需要调整生产流程。
-
检验假设: 在统计学中,直方图用于检验数据是否符合某种特定的假设,例如是否符合正态分布。在进行假设检验时,了解数据的分布情况对于选择适当的统计方法至关重要。
-
对比不同组数据的分布: 通过并排显示多个组的数据直方图,可以直观地比较不同组之间的数据分布差异。例如,比较男性和女性的身高分布、不同地区的收入分布等。
-
金融数据分析: 在金融领域,直方图常用于分析股市收益、风险、资产回报等指标的分布。投资者和分析师通过直方图评估资产的风险分布,帮助决策投资策略。
-
探索性数据分析 (EDA): 在数据科学的探索性数据分析阶段,直方图被广泛用于数据的初步了解。它帮助数据科学家快速把握数据的基本情况,如数据的集中趋势、离散程度及是否存在明显的偏差。
-
环境数据分析: 直方图可以用于环境数据的分析,如温度、湿度、污染物浓度等指标的分布。这有助于环境学者理解不同时间段或区域的环境变化趋势。
-
市场营销与客户分析: 在市场营销领域,直方图用于分析客户行为数据,如购买频率、支出金额、用户活动等。通过了解客户群体的分布,营销团队可以制定更有针对性的营销策略。
4、案例实现
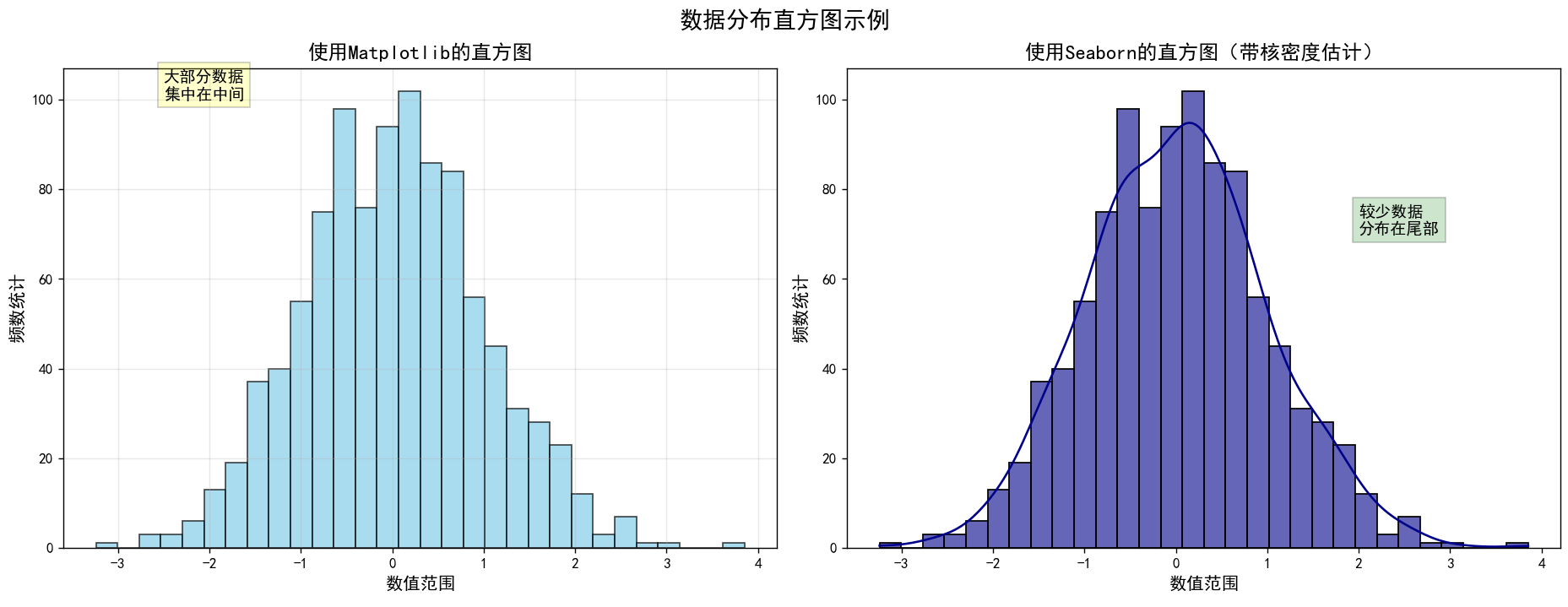
在实现的直方图中,数据描述统计信息如下表所示:
| 数据量 | 1000个数据点 |
| 平均值 | 0.0193 |
| 标准差 | 0.9787 |
| 最小值 | -3.2413 |
| 第一四分位数 | -0.6476 |
| 中位数 | 0.0235 |
| 第三四分位数 | 0.6479 |
| 最大值 | 3.8527 |
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import font_manager as fm
# 设置中文字体支持
# 方法1: 使用系统中已有的中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 设置随机种子以便结果可重现
np.random.seed(42)
# 生成正态分布的随机数据
data = np.random.normal(loc=0, scale=1, size=1000)
# 创建一个图形,包含两个子图
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
# 1. 使用matplotlib创建简单直方图
ax1.hist(data, bins=30, color='skyblue', edgecolor='black', alpha=0.7)
ax1.set_title('使用Matplotlib的直方图', fontsize=14)
ax1.set_xlabel('数值范围', fontsize=12)
ax1.set_ylabel('频数统计', fontsize=12)
ax1.grid(alpha=0.3)
# 2. 使用seaborn创建更美观的直方图
sns.histplot(data=data, bins=30, kde=True, color='darkblue', alpha=0.6, ax=ax2)
ax2.set_title('使用Seaborn的直方图(带核密度估计)', fontsize=14)
ax2.set_xlabel('数值范围', fontsize=12)
ax2.set_ylabel('频数统计', fontsize=12)
# 添加更多的中文标注
ax1.text(-2.5, 100, '大部分数据\n集中在中间',
fontsize=11, bbox=dict(facecolor='yellow', alpha=0.2))
ax2.text(2, 70, '较少数据\n分布在尾部',
fontsize=11, bbox=dict(facecolor='green', alpha=0.2))
# 布局调整
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
plt.suptitle('数据分布直方图示例', fontsize=16)
# 显示图形
plt.show()
# 添加分布描述统计信息
print(f"数据描述统计信息:")
print(f"数据量:{len(data)}个数据点")
print(f"平均值:{np.mean(data):.4f}")
print(f"标准差:{np.std(data):.4f}")
print(f"最小值:{np.min(data):.4f}")
print(f"第一四分位数:{np.percentile(data, 25):.4f}")
print(f"中位数:{np.median(data):.4f}")
print(f"第三四分位数:{np.percentile(data, 75):.4f}")
print(f"最大值:{np.max(data):.4f}")通过使用Python的matplotlib和seaborn库,创建了两种类型的直方图来可视化正态分布数据。生成1000个正态分布的随机数据点,在左侧子图使用matplotlib的hist函数创建基本直方图,展示数据频数分布;右侧子图则使用seaborn的histplot函数创建带有核密度估计曲线的增强版直方图,更直观地展示数据分布趋势。
二、箱线图
1、概念
箱线图(Box Plot)是一种用于展示数据分布的统计图表,通过显示数据的最小值、第一四分位数、中位数、第三四分位数和最大值,直观地反映数据的集中趋势和离散程度。箱线图的“箱子”部分表示数据的四分位范围,中间的线表示数据的中位数,而“须”则表示数据的范围。箱线图特别适合用于识别数据中的异常值(位于箱体外的点)以及比较不同组数据的分布差异。
2、特点
-
五数概括: 箱线图通过展示五个主要统计值来总结数据的分布情况:最小值、第一四分位数(Q1)、中位数(Q2)、第三四分位数(Q3)和最大值。它提供了一个简洁的视图,帮助分析数据的集中趋势和分布情况。
-
异常值检测: 箱线图能够有效识别数据中的异常值(离群点)。这些异常值通常位于箱体外部,超过了“须”所表示的范围(1.5倍四分位距之外的值),它们可以是数据的极端值或错误值。
-
分布形态: 箱线图能够显示数据的分布形态。如果箱体左右不对称,表示数据可能存在偏态分布(左偏或右偏)。箱体的宽度(四分位距)反映了数据的离散程度,宽箱表示较高的离散度,窄箱则表示数据较为集中。
-
中位数和四分位数: 箱线图的中位数线将数据分为上下两部分,能够有效显示数据的中间值。此外,通过显示第一四分位数(Q1)和第三四分位数(Q3),箱线图还展示了数据的上下四分位范围,帮助进一步了解数据的分布。
-
适用于比较多个数据集: 箱线图可以非常方便地用于比较多个数据集的分布情况。通过将多个箱线图并排展示,可以直观地对比不同组数据的分布差异、集中趋势和离散程度。
-
简洁直观: 箱线图通过简单的矩形框和线条,将数据的复杂性压缩为几条线段和一个箱子,能够快速总结出数据的关键统计特征,尤其适用于大规模数据的分析和可视化。
-
对极端值的敏感性: 箱线图对极端值或异常值十分敏感,能准确显示这些特殊数据点。这使得箱线图成为检测和处理异常值的重要工具。
3、应用场景
-
数据分布分析: 箱线图常用于分析数据的分布情况。它可以帮助分析人员直观地看到数据的集中趋势(中位数)、离散程度(四分位距)、是否存在偏态以及数据的最大值和最小值。尤其适用于需要快速了解数据分布特征的情况。
-
异常值检测: 在数据清洗阶段,箱线图是识别异常值(离群点)的有效工具。通过观察箱体外的点,能够轻松发现哪些数据点可能是异常值。这对于数据质量控制和数据预处理非常重要。
-
比较多个数据集: 箱线图非常适合用于比较多个数据集的分布差异。例如,比较不同地区、不同时间段或不同实验组的成绩、收入等指标。多个箱线图可以并排展示,使得各组数据的差异一目了然。
-
质量控制: 在制造业或服务业中,箱线图被广泛用于质量控制。例如,通过箱线图展示生产过程中各项指标(如产品尺寸、重量等)的分布,可以帮助企业了解生产过程中的稳定性以及是否需要进行调整。
-
金融数据分析: 在金融领域,箱线图常用于展示股市收益、资产回报率等指标的分布。投资者可以通过箱线图判断市场的波动性、收益的稳定性以及是否存在极端的市场事件。
-
教育评估: 在教育领域,箱线图可以用于展示学生成绩的分布情况。例如,老师可以使用箱线图来比较不同班级、不同学科的学生成绩,帮助发现成绩分布中的不均衡情况,或者识别学习困难的学生。
-
医学研究: 箱线图在医学研究中也有重要应用。它可以用来展示不同药物治疗效果的数据分布,帮助研究人员比较不同药物组的治疗效果差异,以及是否存在药物的副作用等。
-
营销数据分析: 在市场营销中,箱线图可以帮助分析客户的购买行为或消费金额的分布。通过分析客户支出数据的箱线图,营销人员能够识别出不同消费群体,制定针对性的营销策略。
-
时间序列分析: 箱线图可以在时间序列数据分析中帮助展示数据随时间变化的趋势。例如,分析某一指标(如日销售额)的每月分布情况,判断该指标在不同时间段的波动性。
-
科研数据分析: 在科研领域,尤其是实验数据的分析中,箱线图被用来展示不同实验组之间的差异。例如,比较实验组和对照组在某些物理或化学实验中的数据分布。
4、案例实现
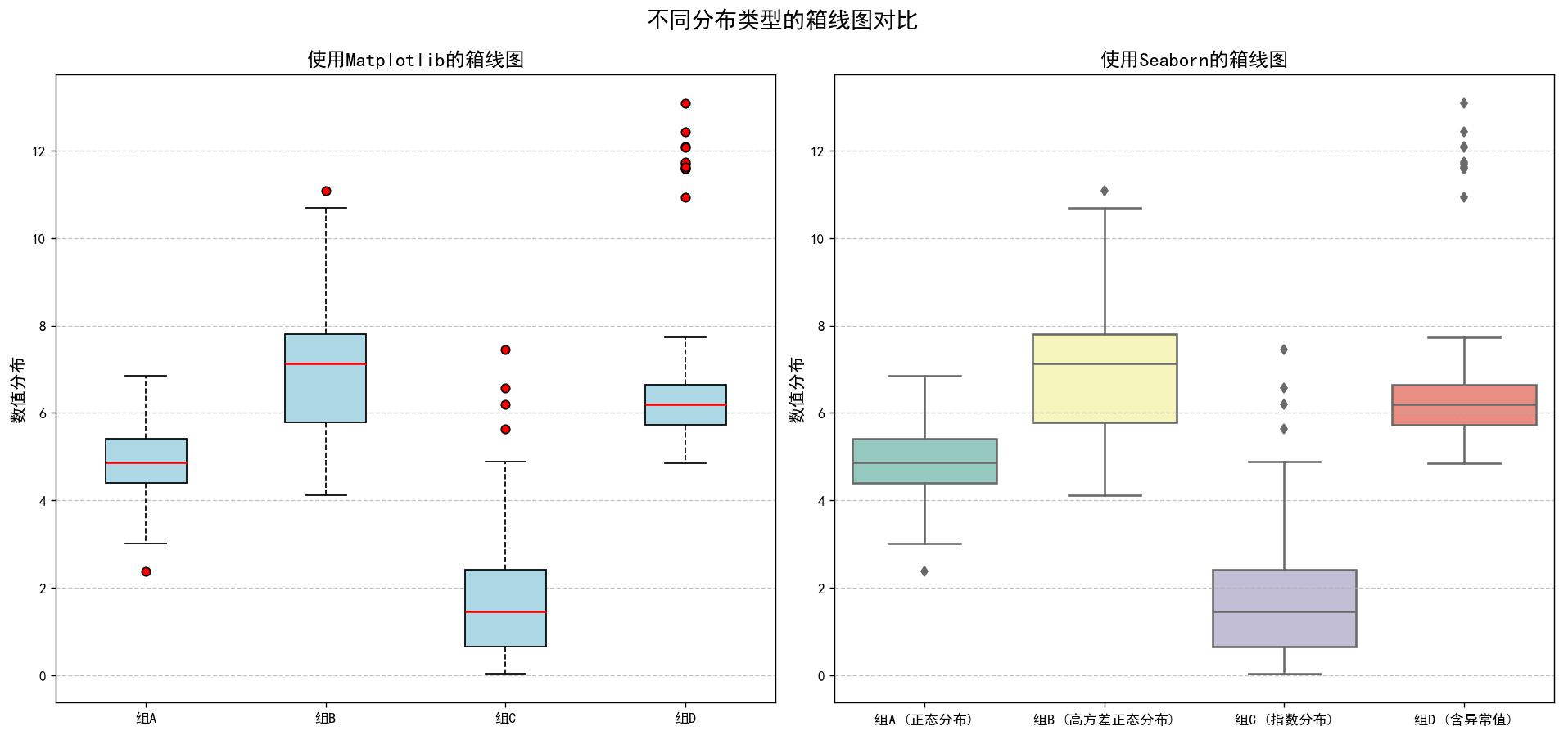
各数据的统计信息:
| 统计指标 | 组 A (正态分布) | 组 B (高方差正态分布) | 组 C (指数分布) | 组 D (含异常值) |
|---|---|---|---|---|
| count | 100.00 | 100.00 | 100.00 | 100.00 |
| mean | 4.90 | 7.03 | 1.75 | 6.67 |
| std | 0.91 | 1.43 | 1.51 | 1.85 |
| min | 2.38 | 4.12 | 0.03 | 4.84 |
| 25% | 4.40 | 5.79 | 0.65 | 5.73 |
| 50% | 4.87 | 7.13 | 1.46 | 6.19 |
| 75% | 5.41 | 7.81 | 2.42 | 6.65 |
| max | 6.85 | 11.08 | 7.45 | 13.09 |
组 A (正态分布) 箱线图解读:
| 解读指标 | 数值 |
|---|---|
| 中位数 | 4.87 |
| 四分位距 (IQR) | 1.01 |
| 四分位数范围 | Q1=4.40, Q3=5.41 |
| 异常值判定范围 | [2.89, 6.92] |
| 异常值数量 | 1 |
| 异常值 | [2.38] |
组 B (高方差正态分布) 箱线图解读:
| 解读指标 | 数值 |
|---|---|
| 中位数 | 7.13 |
| 四分位距 (IQR) | 2.02 |
| 四分位数范围 | Q1=5.79, Q3=7.81 |
| 异常值判定范围 | [2.77, 10.83] |
| 异常值数量 | 1 |
| 异常值 | [11.08] |
组 C (指数分布) 箱线图解读:
| 解读指标 | 数值 |
|---|---|
| 中位数 | 1.46 |
| 四分位距 (IQR) | 1.77 |
| 四分位数范围 | Q1=0.65, Q3=2.42 |
| 异常值判定范围 | [-2.01, 5.08] |
| 异常值数量 | 4 |
| 异常值 | [7.45 6.57 6.2 5.63] |
组 D (含异常值) 箱线图解读:
| 解读指标 | 数值 |
|---|---|
| 中位数 | 6.19 |
| 四分位距 (IQR) | 0.93 |
| 四分位数范围 | Q1=5.73, Q3=6.65 |
| 异常值判定范围 | [4.34, 8.04] |
| 异常值数量 | 10 |
| 异常值 | [12.44 12.09 13.09 11.6 11.58 11.7 10.94 11.74 11.62 12.08] |
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
# 设置中文字体支持
plt.rcParams['font.sans-serif'] = ['SimHei'] # 黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 设置随机种子以便结果可重现
np.random.seed(42)
# 生成多组数据以便比较
group1 = np.random.normal(loc=5, scale=1, size=100) # 均值5,标准差1的正态分布
group2 = np.random.normal(loc=7, scale=1.5, size=100) # 均值7,标准差1.5的正态分布
group3 = np.random.exponential(scale=2, size=100) # 指数分布
group4 = np.concatenate([np.random.normal(loc=6, scale=0.8, size=90), # 正态分布加一些异常值
np.random.normal(loc=12, scale=0.5, size=10)]) # 添加离群点
# 创建DataFrame以便于使用seaborn
data = pd.DataFrame({
'组A (正态分布)': group1,
'组B (高方差正态分布)': group2,
'组C (指数分布)': group3,
'组D (含异常值)': group4
})
# 创建一个图形,包含两个子图
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16, 7))
# 1. 使用matplotlib创建基本箱线图
ax1.boxplot([group1, group2, group3, group4],
labels=['组A', '组B', '组C', '组D'],
patch_artist=True,
boxprops=dict(facecolor='lightblue'),
medianprops=dict(color='red', linewidth=1.5),
whiskerprops=dict(linestyle='--'),
showfliers=True, # 显示离群点
flierprops=dict(marker='o', markerfacecolor='red', markersize=6))
ax1.set_title('使用Matplotlib的箱线图', fontsize=14)
ax1.set_ylabel('数值分布', fontsize=12)
ax1.grid(True, axis='y', linestyle='--', alpha=0.7)
# 2. 使用seaborn创建增强版箱线图
sns.boxplot(data=data, palette='Set3', ax=ax2)
ax2.set_title('使用Seaborn的箱线图', fontsize=14)
ax2.set_ylabel('数值分布', fontsize=12)
ax2.grid(True, axis='y', linestyle='--', alpha=0.7)
# 布局调整
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
plt.suptitle('不同分布类型的箱线图对比', fontsize=16)
# 显示图形
plt.show()
# 打印各组数据的描述统计信息
print("各组数据的统计信息:")
print(data.describe().round(2))
# 增加额外的箱线图解读信息
for column in data.columns:
q1 = data[column].quantile(0.25)
q3 = data[column].quantile(0.75)
iqr = q3 - q1
lower_bound = q1 - 1.5 * iqr
upper_bound = q3 + 1.5 * iqr
outliers = data[column][(data[column] < lower_bound) | (data[column] > upper_bound)]
print(f"\n{column}的箱线图解读:")
print(f"中位数: {data[column].median():.2f}")
print(f"四分位距(IQR): {iqr:.2f}")
print(f"四分位数范围: Q1={q1:.2f}, Q3={q3:.2f}")
print(f"异常值判定范围: [{lower_bound:.2f}, {upper_bound:.2f}]")
print(f"异常值数量: {len(outliers)}")
if len(outliers) > 0:
print(f"异常值: {outliers.values.round(2)}")使用Matplotlib和Seaborn库分别绘制它们的箱线图,同时输出每组数据的描述统计信息。生成四组数据(正态分布、高方差正态分布、指数分布和含异常值的正态分布),创建DataFrame,使用Matplotlib和Seaborn绘制箱线图,调整布局,显示图形。
三、密度图
1、概念
密度图(Density Plot)是一种用于可视化连续型数据分布的统计图表,它通过估计数据的概率密度函数来展示数据的分布特征。与直方图不同,密度图生成平滑的曲线而非离散的柱状图,能够更加连续地展示数据在整个范围内的分布情况。密度图的曲线高度表示数据在某个特定值附近出现的相对概率,曲线下的总面积等于1,这使得密度图特别适合于观察数据的峰值位置、多峰特性、偏态程度,以及比较不同数据集的分布差异。
2、特点
-
平滑连续性: 密度图展示的是平滑的连续曲线,而不是离散的柱状图。这种平滑表示能够更好地反映数据的整体分布趋势,避免了直方图因区间选择可能带来的信息丢失。
-
概率密度表示: 密度图的纵轴表示概率密度,而不是直接的频数或频率。曲线的高度反映了数据在该点附近出现的相对可能性,曲线下的总面积等于1。
-
核密度估计: 密度图通常基于核密度估计(Kernel Density Estimation, KDE)方法生成,这是一种非参数统计技术,能够根据样本数据估计未知的概率密度函数,无需假设数据服从特定的分布。
-
带宽敏感性: 密度图的平滑程度受到带宽参数的影响。较大的带宽会产生更平滑的曲线,但可能会掩盖数据的细节特征;较小的带宽则会显示更多的局部变化,但可能出现过拟合。
-
多峰分布显示: 密度图能够有效地展示数据的多峰分布特征,这是它相比直方图的一个重要优势。通过观察密度曲线的峰值,可以直观地看到数据的集中区域。
-
易于比较多组数据: 密度图特别适合于在同一图表中比较多个数据集的分布特征。通过重叠显示多条密度曲线,可以直观地对比不同组的分布形态、位置和离散程度。
-
形态分析: 密度图能够清晰地展示数据的分布形态,包括是否对称、是否存在偏态(左偏或右偏)、尾部特征等,有助于判断数据是否符合某种理论分布。
-
与其他图表的集成: 密度图可以与其他统计图表(如散点图、小提琴图等)结合使用,增强数据可视化的信息量。例如,在散点图的轴上添加密度图,可以同时展示数据点的分布和密度。
-
美观性: 相比直方图的阶梯状外观,密度图的平滑曲线通常具有更好的视觉效果,能够更加优雅地展示数据分布。
3、应用场景
-
多组数据的分布比较: 密度图特别适合比较多个数据集之间的分布差异。例如,比较不同地区人口的收入分布、不同年龄组的健康指标分布等。通过在同一图表上显示多条密度曲线,可以直观地看出各组之间的差异。
-
金融数据分析: 在金融领域,密度图被广泛用于分析资产回报率、风险分布和市场波动性。投资分析师通过观察不同投资组合的回报率密度分布,可以评估投资风险和不同市场条件下的表现。
-
机器学习与统计建模: 在机器学习过程中,密度图可以用来可视化模型参数的分布、特征分布或预测值分布。这有助于理解模型的学习过程和评估模型的性能。
-
生物医学研究: 在生物医学研究中,密度图常用于展示生物标志物的分布、基因表达水平、医疗测量数据等。例如,比较健康人群与患病人群在某些生物指标上的分布差异。
-
社会科学研究: 在社会科学研究中,密度图可以用来展示人口统计数据、社会态度调查、心理测量结果等的分布情况。例如,分析不同社会群体对某一政策的支持程度分布。
-
多峰分布分析: 当数据呈现多峰分布特征时,密度图比直方图更能清晰地展示这一特性。多峰分布通常表明数据可能来自多个子群体或受到多个因素的影响,这在市场细分、生态研究等领域很常见。
-
异常值检测与数据质量分析: 通过观察密度曲线的形状,特别是尾部的延伸情况,可以帮助分析人员识别可能的异常值或数据质量问题。例如,数据分布尾部异常延伸可能表示存在极端值。
-
时间序列数据分析: 在时间序列分析中,密度图可以用来展示某个变量在不同时间段的分布变化。例如,分析股票价格在不同市场周期的分布特征。
-
环境数据监测: 在环境科学中,密度图用于分析污染物浓度、气象数据等环境指标的分布。例如,比较不同季节或不同地区的空气质量指标分布。
-
质量控制: 在制造业和质量控制领域,密度图被用来监测产品质量指标的分布,帮助识别生产过程中的问题。例如,分析产品尺寸的分布是否符合预期的公差范围。
-
教育评估: 在教育领域,密度图可以用来分析学生成绩、标准化测试分数等的分布情况。例如,比较不同教学方法下学生成绩的分布差异。
-
客户行为分析: 在市场营销中,密度图可以帮助分析客户的消费金额、购买频率等行为特征的分布,为市场细分和个性化营销提供依据。
4、案例实现
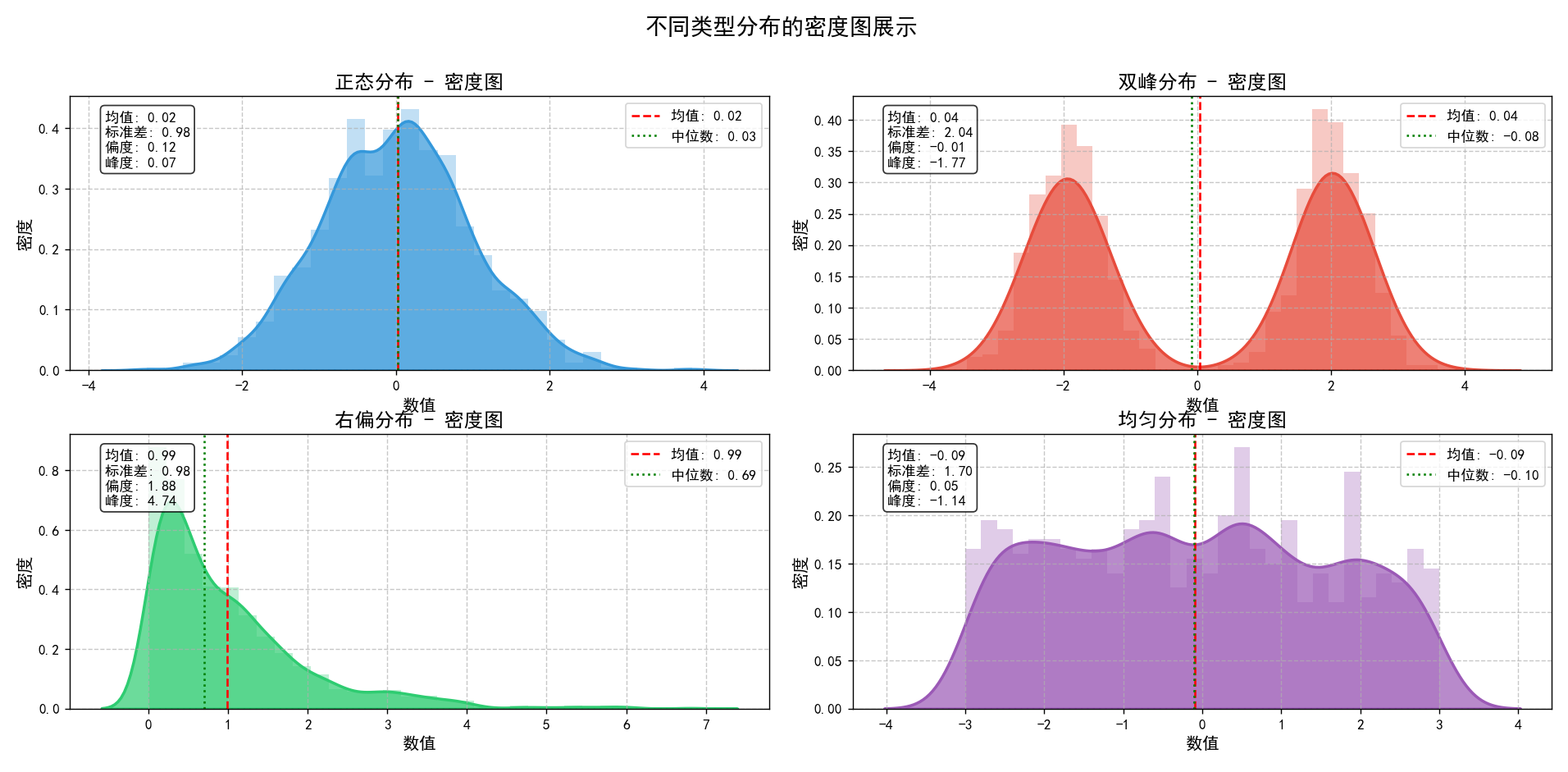
不同分布类型的统计信息:
| 分布类型 | 均值 | 中位数 | 标准差 | 偏度 | 峰度 | 最小值 | 最大值 |
|---|---|---|---|---|---|---|---|
| 正态分布 | 0.019 | 0.025 | 0.979 | 0.117 | 0.066 | -3.241 | 3.853 |
| 双峰分布 | 0.035 | -0.085 | 2.044 | -0.005 | -1.770 | -3.448 | 3.597 |
| 右偏分布 | 0.988 | 0.694 | 0.981 | 1.876 | 4.738 | 0.000 | 6.806 |
| 均匀分布 | -0.091 | -0.104 | 1.701 | 0.055 | -1.139 | -3.000 | 2.997 |
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
from scipy import stats
# 设置中文字体支持
plt.rcParams['font.sans-serif'] = ['SimHei'] # 黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 设置随机种子以便结果可重现
np.random.seed(42)
# 生成多组不同类型的分布数据
n_samples = 1000
# 正态分布数据
normal_data = np.random.normal(loc=0, scale=1, size=n_samples)
# 双峰分布数据(两个正态分布的混合)
bimodal_data = np.concatenate([
np.random.normal(loc=-2, scale=0.5, size=n_samples // 2),
np.random.normal(loc=2, scale=0.5, size=n_samples // 2)
])
# 右偏分布数据
skewed_data = np.random.exponential(scale=1, size=n_samples)
# 均匀分布数据
uniform_data = np.random.uniform(low=-3, high=3, size=n_samples)
# 创建DataFrame以便于使用seaborn
data = pd.DataFrame({
'正态分布': normal_data,
'双峰分布': bimodal_data,
'右偏分布': skewed_data,
'均匀分布': uniform_data
})
# 创建一个图形,包含多个子图
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
axes = axes.flatten() # 扁平化处理多维数组
# 颜色方案
colors = ['#3498db', '#e74c3c', '#2ecc71', '#9b59b6']
# 遍历每种分布类型,创建密度图
for i, (col_name, color) in enumerate(zip(data.columns, colors)):
# 使用seaborn的kdeplot创建密度图
sns.kdeplot(
data=data[col_name],
ax=axes[i],
fill=True,
color=color,
alpha=0.7,
linewidth=2,
bw_adjust=0.8 # 调整带宽,影响平滑程度
)
# 在密度图上添加直方图,以透明方式显示
axes[i].hist(
data[col_name],
bins=30,
density=True,
alpha=0.3,
color=color
)
# 添加均值线
mean_val = data[col_name].mean()
axes[i].axvline(
x=mean_val,
color='red',
linestyle='--',
linewidth=1.5,
label=f'均值: {mean_val:.2f}'
)
# 添加中位数线
median_val = data[col_name].median()
axes[i].axvline(
x=median_val,
color='green',
linestyle=':',
linewidth=1.5,
label=f'中位数: {median_val:.2f}'
)
# 设置标题和标签
axes[i].set_title(f'{col_name} - 密度图', fontsize=14)
axes[i].set_xlabel('数值', fontsize=12)
axes[i].set_ylabel('密度', fontsize=12)
axes[i].grid(True, linestyle='--', alpha=0.7)
axes[i].legend()
# 添加一些统计信息
stat_text = (
f"均值: {data[col_name].mean():.2f}\n"
f"标准差: {data[col_name].std():.2f}\n"
f"偏度: {stats.skew(data[col_name]):.2f}\n"
f"峰度: {stats.kurtosis(data[col_name]):.2f}"
)
axes[i].text(
0.05, 0.95, stat_text,
transform=axes[i].transAxes,
fontsize=10,
verticalalignment='top',
bbox=dict(boxstyle='round', facecolor='white', alpha=0.8)
)
# 添加总标题
plt.suptitle('不同类型分布的密度图展示', fontsize=16)
# 调整布局
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
# 显示图形
plt.show()
# 打印各种分布的基本统计信息
print("不同分布类型的统计信息:")
stats_df = pd.DataFrame({
'均值': data.mean(),
'中位数': data.median(),
'标准差': data.std(),
'偏度': data.apply(stats.skew),
'峰度': data.apply(stats.kurtosis),
'最小值': data.min(),
'最大值': data.max()
})
print(stats_df.round(3))
# 添加KDE带宽选择的影响说明
print("\n密度图中带宽选择的影响:")
print("较小的带宽会产生更多局部细节,但可能导致过拟合")
print("较大的带宽会产生更平滑的曲线,但可能丢失重要的分布特征")
print("最佳带宽的选择通常取决于数据的性质和分析目的")主要实现了生成四种不同类型分布的随机数据(正态分布、双峰分布、右偏分布和均匀分布),并使用Seaborn和Matplotlib库绘制了它们的密度图和直方图,同时在图上标注了均值和中位数线。此外,还计算并显示了每种分布的统计信息,包括均值、中位数、标准差、偏度、峰度、最小值和最大值。
四、小提琴图
1、概念
小提琴图(Violin Plot)是一种结合了箱线图和密度图特点的数据可视化图表。它通过在每个类别的轴上绘制对称的“小提琴形状”,展示数据的分布情况。小提琴图的宽度表示数据在不同数值区间的密度,即数据在某一数值处出现的频率,同时还显示了数据的分位数(如中位数和四分位数)。相比箱线图,小提琴图不仅能够展示数据的集中趋势、散布程度,还能够直观展示数据的分布形态,尤其适合用来比较不同类别或组别的数据分布差异。
2、特点
-
结合箱线图和密度图: 小提琴图在箱线图的基础上,增加了数据的密度估计(通常使用核密度估计)。因此,它不仅能显示数据的集中趋势(如中位数、四分位数),还可以展示数据的分布形态,如是否呈现偏态或多峰。
-
展示数据的分布形态: 小提琴图的宽度代表数据在某一数值区间的密度。曲线越宽,表示该数值区间的出现频率越高。这使得小提琴图非常适合展示数据是否呈现对称、偏态、单峰或多峰的分布特点。
-
显示数据的分位数: 小提琴图通常在中间绘制一条线,表示数据的中位数,并通过箱体展示数据的四分位数。这些元素与传统的箱线图类似,用于显示数据的集中趋势和离散程度。
-
对称性: 小提琴图通常是左右对称的,左边和右边的曲线分别代表数据分布的不同部分。对于多组数据,小提琴图可以并排显示,便于比较各组数据的分布差异。
-
适用于多类别比较: 小提琴图特别适用于比较不同类别或组别之间的分布差异。通过并排显示不同类别的数据分布,能够直观地比较它们的集中趋势、离散程度和分布形态。
-
更加直观的分布展示: 与箱线图相比,小提琴图不仅能展示数据的统计概况,还能够提供更为丰富的分布信息,尤其是数据的形态、尾部特征以及是否存在异常值等。
-
可自定义的显示: 小提琴图允许用户自定义其外观,例如控制带宽(影响平滑程度)、显示或隐藏部分统计元素(如箱线图、点图等),以及调整色彩等。这使得它在数据可视化中有更高的灵活性。
-
适用于大规模数据: 小提琴图适用于处理大规模数据,尤其是在数据量较大时,密度估计能够平滑展现数据的分布,帮助识别数据中的潜在模式。
3、应用场景
-
多组数据分布比较: 小提琴图非常适合用来比较多个类别或组别的数据分布。它能清晰地展示不同类别之间的分布形态、集中趋势、离散程度等。例如,可以用小提琴图比较不同地区或不同性别的收入、成绩等数据的分布差异。
-
类别型数据分析: 小提琴图常用于展示类别型变量与数值型变量之间的关系。例如,分析不同城市的房价分布、不同年龄组的体重分布等,能够帮助揭示不同类别数据在数值上的分布情况。
-
多峰分布分析: 小提琴图能够有效地展示多峰分布。当数据包含多个集中区域(例如混合分布),小提琴图可以帮助识别这些峰值并分析其含义。对于市场细分、客户群体分析等问题,这种特性尤为重要。
-
统计学研究: 小提琴图常用于统计学中的数据分布分析,帮助研究者直观地理解数据集的分布特征。它可以用于展示样本的偏态性、尾部特征(如长尾分布)以及可能存在的异常值。
-
医学和生物学研究: 在医学和生物学研究中,小提琴图被用于展示不同组别(如健康组与患病组)在某些生物标志物、体征数据(如血糖、血压、基因表达水平等)上的分布差异。它有助于识别某些特征在不同组之间的变化规律。
-
教育评估: 小提琴图可以用来分析不同教育背景、性别、年龄组等群体的测试成绩分布。例如,比较不同学校、不同班级或不同学科的学生成绩分布,有助于评估教育干预的效果。
-
金融和经济数据分析: 在金融领域,小提琴图可以用来分析不同投资组合的回报率分布、风险特征等。例如,比较不同股票、基金或行业的收益波动情况,以及识别潜在的风险或机会。
-
质量控制与工业工程: 在制造业和质量控制领域,小提琴图可以帮助分析不同生产批次或不同生产工艺下产品的质量分布。例如,展示产品尺寸、重量、强度等特征的分布情况,帮助识别生产过程中存在的偏差和问题。
-
心理学与社会学研究: 在心理学与社会学研究中,小提琴图可以用于展示不同群体在心理测量、行为特征等方面的数据分布。例如,比较不同年龄段、性别、文化背景等群体的心理测试分数分布情况,帮助研究者识别潜在的群体差异。
-
市场与消费者行为分析: 小提琴图也可以应用于市场营销和消费者行为分析中,用来展示不同消费者群体的购买行为分布。通过比较不同消费者群体的购买金额、购买频率等,可以识别出不同群体的消费特征。
-
物理学和工程学数据分析: 小提琴图在物理学和工程学中也有应用,特别是用于展示实验数据的分布。例如,比较不同实验条件下测量的温度、压力、速度等物理量的分布特征。
-
气候与环境数据分析: 在气候学和环境科学中,小提琴图可以用来展示不同地区、不同季节的气温、降水量等环境变量的分布情况。它可以帮助分析气候变化趋势或环境污染的分布模式。
4、案例实现
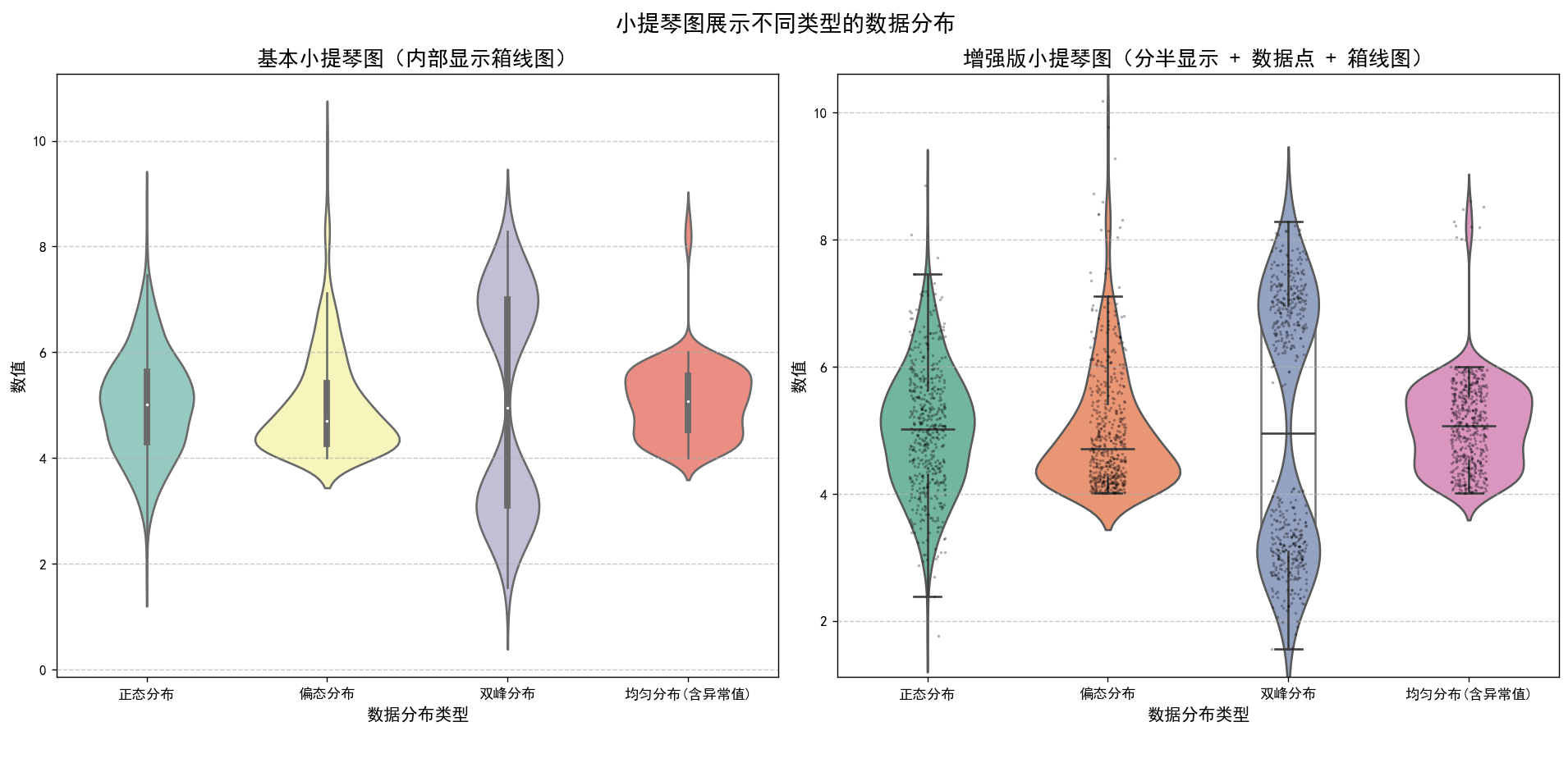
不同分布类型的统计信息:
| 分布类型 | 均值 | 中位数 | 标准差 | 最小值 | 25% 分位数 | 75% 分位数 | 最大值 |
|---|---|---|---|---|---|---|---|
| 正态分布 | 5.01 | 5.01 | 0.98 | 1.76 | 4.30 | 5.64 | 8.85 |
| 偏态分布 | 5.00 | 4.70 | 0.99 | 4.00 | 4.27 | 5.42 | 10.18 |
| 双峰分布 | 5.03 | 4.95 | 2.03 | 1.55 | 3.10 | 7.00 | 8.29 |
| 均匀分布 (含异常值) | 5.08 | 5.07 | 0.73 | 4.01 | 4.52 | 5.55 | 8.61 |
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
# 设置中文字体支持
plt.rcParams['font.sans-serif'] = ['SimHei'] # 黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 设置随机种子以便结果可重现
np.random.seed(42)
# 生成多组不同特征的数据
n_samples = 500
# 正态分布,均值为5,标准差为1
group1 = np.random.normal(loc=5, scale=1, size=n_samples)
# 偏态分布,使用指数分布加上一个常数
group2 = np.random.exponential(scale=1, size=n_samples) + 4
# 双峰分布,混合两个正态分布
group3 = np.concatenate([
np.random.normal(loc=3, scale=0.5, size=n_samples//2),
np.random.normal(loc=7, scale=0.5, size=n_samples//2)
])
# 均匀分布,带有一些异常值
group4 = np.concatenate([
np.random.uniform(low=4, high=6, size=n_samples-10),
np.random.uniform(low=8, high=9, size=10) # 模拟异常值
])
# 创建一个DataFrame来存储数据
df = pd.DataFrame({
'正态分布': group1,
'偏态分布': group2,
'双峰分布': group3,
'均匀分布(含异常值)': group4
})
# 将数据转换为长格式,适用于seaborn绘图
df_long = pd.melt(df, var_name='组别', value_name='数值')
# 创建一个图形
plt.figure(figsize=(14, 10))
# 创建两种不同风格的小提琴图的子图
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16, 8))
# 1. 基本小提琴图
sns.violinplot(
x='组别',
y='数值',
data=df_long,
palette='Set3',
inner='box', # 在小提琴内部显示箱线图
ax=ax1
)
ax1.set_title('基本小提琴图(内部显示箱线图)', fontsize=15)
ax1.set_xlabel('数据分布类型', fontsize=12)
ax1.set_ylabel('数值', fontsize=12)
ax1.grid(axis='y', linestyle='--', alpha=0.7)
# 2. 增强版小提琴图:分半显示,添加数据点
sns.violinplot(
x='组别',
y='数值',
data=df_long,
palette='Set2',
inner=None, # 不在内部显示统计信息
split=True, # 分半显示
ax=ax2
)
# 在小提琴图上叠加散点图,显示实际数据点
sns.stripplot(
x='组别',
y='数值',
data=df_long,
color='black',
size=2,
alpha=0.3,
jitter=True, # 添加随机抖动,防止点重叠
ax=ax2
)
# 在小提琴图上叠加箱线图,使用不同颜色和透明度
sns.boxplot(
x='组别',
y='数值',
data=df_long,
width=0.3, # 箱线图宽度为小提琴图的30%
showfliers=False, # 不显示异常值点
boxprops={'facecolor': 'none', 'alpha': 0.7}, # 透明箱体
ax=ax2
)
ax2.set_title('增强版小提琴图(分半显示 + 数据点 + 箱线图)', fontsize=15)
ax2.set_xlabel('数据分布类型', fontsize=12)
ax2.set_ylabel('数值', fontsize=12)
ax2.grid(axis='y', linestyle='--', alpha=0.7)
# 调整布局
plt.tight_layout(rect=[0, 0.05, 1, 0.95])
plt.suptitle('小提琴图展示不同类型的数据分布', fontsize=16)
# 显示图形
plt.show()
# 打印各种分布的基本统计信息
print("不同分布类型的统计信息:")
stats_df = pd.DataFrame({
'均值': df.mean(),
'中位数': df.median(),
'标准差': df.std(),
'最小值': df.min(),
'25%分位数': df.quantile(0.25),
'75%分位数': df.quantile(0.75),
'最大值': df.max()
})
print(stats_df.round(2))生成了四组不同特征的数据(正态分布、偏态分布、双峰分布和含异常值的均匀分布),将这些数据转换为长格式并存储在DataFrame中。使用Matplotlib和Seaborn库创建了两个子图,分别绘制了基本小提琴图和增强版小提琴图(包括分半显示、数据点和箱线图)。计算并打印了每种分布的基本统计信息,包括均值、中位数、标准差、最小值、25%分位数、75%分位数和最大值。
五、累计频率图
1、概念
累计频率图(Cumulative Frequency Plot)是一种用于展示数据分布的图表,它通过逐步累加数据的频率,展示每个数据点及其之前所有数据点的总频率。与常规的频率分布图不同,累计频率图通过累计每个类别的频率,帮助观察数据的累积趋势和分布形态。它通常用于分析数据的累积情况,如查找分布的中位数、百分位数等,特别适用于查看数据的整体趋势和区间范围内的频率变化。累计频率图通常呈现为阶梯状曲线或直方图的累积版本。
2、特点
-
显示数据的累积分布: 累计频率图通过将每个类别的频率逐步累加,显示数据从小到大的累积趋势。它展示了数据在各个区间内的累积频率,能够帮助理解数据的整体分布情况。
-
阶梯状或曲线状: 累计频率图通常呈现阶梯状的曲线,其中每一个阶梯的高度代表到当前数据点为止的累计频率。这种形式使得我们能够直观地看到数据在不同区间的累积情况。
-
适合查看百分位数和中位数: 通过累计频率图,可以方便地查找数据的中位数(50%累积点)和百分位数。例如,某个特定数据点对应的累积频率为90%,意味着90%的数据点位于该值或更小的范围内。
-
不显示单个数据点的具体频率: 与传统的频率分布图不同,累计频率图关注的是数据的累积情况,而不是单个数据点的频率。因此,它对于整体趋势的把握更加直观,而不适合精确反映单个数据点的频率。
-
逐步累加的性质: 每个数据点的频率都是基于前一个数据点的累计频率,因此累计频率图是一个单调非减的图表。它始终保持上升状态(除非数据中的某个值的频率为零)。
-
有助于判断数据的分布和趋势: 累计频率图能够帮助我们识别数据分布的模式,例如数据的集中度、偏态性、分布的尾部特征等。通过观察曲线的形态,可以快速判断数据的趋势和分布特征。
-
适合比较多个数据集: 累计频率图可以同时绘制多个数据集的累积频率,从而对比不同数据集的分布特征。这样做可以帮助分析各组数据的总体趋势和差异。
3、应用场景
-
数据分布分析: 累计频率图可用于分析数据的分布特点,如数据集中程度、偏态性、分布的尾部等。它帮助研究者理解数据的整体趋势,尤其适合展示数据的累积分布和波动。例如,分析学生考试成绩、销售数据或收入分布时,累计频率图可以帮助揭示大部分数据集中在哪些区间。
-
百分位数和中位数的计算: 累计频率图对于查找数据的百分位数(例如25%、50%、75%等)非常有用。通过图中的曲线,可以快速确定某个特定百分位数对应的数据点。比如,可以通过累计频率图找出收入的中位数,或者计算成绩分布的90百分位。
-
质量控制与过程管理: 在制造业和质量控制中,累计频率图常用于分析产品质量的分布情况,如产品尺寸、重量、强度等参数。通过累计频率图,管理者可以快速查看产品符合质量标准的比例,判断是否需要采取改进措施。例如,生产过程中是否有90%的产品尺寸在规范范围内,可以通过累计频率图直观判断。
-
环境数据分析: 在环境科学中,累计频率图可用于分析气象、污染等环境数据的分布。例如,分析某地的年降水量,累计频率图可以帮助快速查看大部分年份的降水量分布,判断常见的降水量范围。
-
风险评估和金融分析: 在金融领域,累计频率图可用于展示风险分布,如投资回报率、股票价格波动等。通过累计频率图,投资者可以了解某个特定收益水平的累积概率,有助于进行风险评估和决策。比如,投资回报率超过一定值的概率(比如5%收益率的累计频率)。
-
客户行为分析: 在营销和消费者行为研究中,累计频率图可用于分析客户行为,如购买金额、购买频率等。它可以帮助企业了解大部分客户的消费水平和购买模式,从而制定更有效的市场策略。例如,分析大部分客户的年消费金额分布,帮助设定合适的定价策略。
-
人口统计学研究: 在人口统计学中,累计频率图可以用于展示人口的年龄分布、收入分布、教育水平等。通过累计频率图,可以了解某一特征的累积分布,进而分析不同群体的比例,帮助制定社会政策和福利措施。
-
医学研究与生物统计学: 在医学领域,累计频率图可用于展示疾病发生率、药物效果分布等。例如,在临床试验中,累计频率图能够帮助分析不同患者群体对药物的反应,快速了解药物的疗效分布。
-
社会学和心理学研究: 在社会学和心理学研究中,累计频率图有助于分析社会现象或心理测试分数的分布。通过展示不同群体的分布情况,帮助研究者理解群体行为、心理状态等特征。
-
教育评估: 在教育领域,累计频率图可用于分析学生的考试成绩分布,帮助了解考试成绩的整体表现。它可以用来判定成绩达到某个水平(如及格、优秀)的学生比例,从而为教育决策提供依据。
4、案例实现
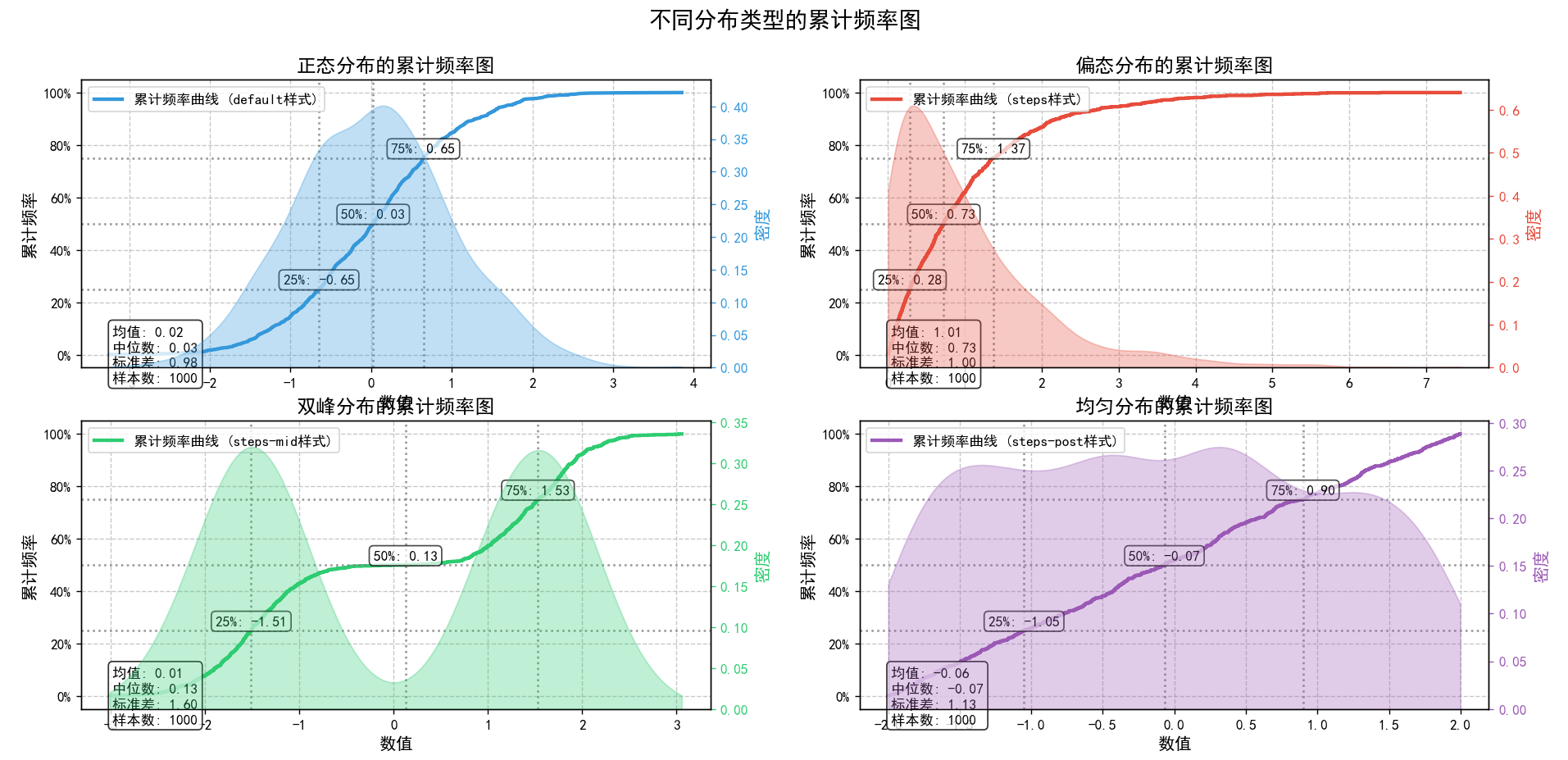
各分布类型的百分位数统计:
| 百分位数 | 正态分布 | 偏态分布 | 双峰分布 | 均匀分布 |
|---|---|---|---|---|
| 0% | -3.24 | 0.00 | -3.01 | -2.00 |
| 10% | -1.24 | 0.10 | -1.91 | -1.63 |
| 25% | -0.65 | 0.28 | -1.51 | -1.05 |
| 50% | 0.03 | 0.73 | 0.13 | -0.07 |
| 75% | 0.65 | 1.37 | 1.53 | 0.90 |
| 90% | 1.31 | 2.23 | 1.92 | 1.54 |
| 100% | 3.85 | 7.44 | 3.05 | 2.00 |
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from scipy import stats
from matplotlib.ticker import PercentFormatter
# 设置中文字体支持
plt.rcParams['font.sans-serif'] = ['SimHei'] # 黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 设置随机种子以便结果可重现
np.random.seed(42)
# 生成不同类型的数据
n_samples = 1000
# 正态分布数据
normal_data = np.random.normal(loc=0, scale=1, size=n_samples)
# 偏态分布数据(指数分布)
skewed_data = np.random.exponential(scale=1, size=n_samples)
# 双峰分布数据
bimodal_data = np.concatenate([
np.random.normal(loc=-1.5, scale=0.5, size=n_samples // 2),
np.random.normal(loc=1.5, scale=0.5, size=n_samples // 2)
])
# 均匀分布数据
uniform_data = np.random.uniform(low=-2, high=2, size=n_samples)
# 创建数据框
data = {
'正态分布': normal_data,
'偏态分布': skewed_data,
'双峰分布': bimodal_data,
'均匀分布': uniform_data
}
df = pd.DataFrame(data)
# 创建一个2x2的子图
fig, axes = plt.subplots(2, 2, figsize=(14, 12))
axes = axes.flatten()
# 颜色方案
colors = ['#3498db', '#e74c3c', '#2ecc71', '#9b59b6']
# 修正drawstyle参数为matplotlib支持的值
methods = ['default', 'steps', 'steps-mid', 'steps-post']
# 处理每种分布数据
for i, (col_name, color, method) in enumerate(zip(df.columns, colors, methods)):
# 当前数据
data = df[col_name].sort_values()
# 计算累计频率
y = np.arange(1, len(data) + 1) / len(data)
# 绘制累计频率图
axes[i].plot(data, y, drawstyle=method, color=color, linewidth=2.5,
label=f'累计频率曲线 ({method}样式)')
# 添加网格线
axes[i].grid(True, linestyle='--', alpha=0.7)
# 设置标题和标签
axes[i].set_title(f'{col_name}的累计频率图', fontsize=14)
axes[i].set_xlabel('数值', fontsize=12)
axes[i].set_ylabel('累计频率', fontsize=12)
# 设置y轴为百分比格式
axes[i].yaxis.set_major_formatter(PercentFormatter(1.0))
# 绘制辅助线,标记25%、50%、75%百分位数
percentiles = [0.25, 0.5, 0.75]
percentile_values = [np.percentile(data, p * 100) for p in percentiles]
for p, pv in zip(percentiles, percentile_values):
# 水平线
axes[i].axhline(y=p, color='gray', linestyle=':', alpha=0.8)
# 垂直线
axes[i].axvline(x=pv, color='gray', linestyle=':', alpha=0.8)
# 标记百分位数值
axes[i].text(
pv, p + 0.02, f'{int(p * 100)}%: {pv:.2f}',
fontsize=10, ha='center',
bbox=dict(facecolor='white', alpha=0.7, boxstyle='round,pad=0.3')
)
# 计算并展示密度分布
kde = stats.gaussian_kde(data)
x_vals = np.linspace(min(data), max(data), 1000)
density = kde(x_vals)
# 创建次坐标轴显示密度分布
ax2 = axes[i].twinx()
ax2.fill_between(x_vals, density, alpha=0.3, color=color)
ax2.set_ylabel('密度', fontsize=12, color=color)
ax2.tick_params(axis='y', colors=color)
ax2.set_ylim(0, max(density) * 1.1) # 调整y轴范围
# 添加统计信息
stats_text = (
f"均值: {np.mean(data):.2f}\n"
f"中位数: {np.median(data):.2f}\n"
f"标准差: {np.std(data):.2f}\n"
f"样本数: {len(data)}"
)
axes[i].text(
0.05, 0.15, stats_text,
transform=axes[i].transAxes,
fontsize=10,
verticalalignment='top',
bbox=dict(boxstyle='round', facecolor='white', alpha=0.8)
)
# 添加图例
axes[i].legend(loc='upper left')
# 添加总标题
plt.suptitle('不同分布类型的累计频率图', fontsize=16)
# 调整布局
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
# 显示图形
plt.show()
# 打印各分布的关键百分位数
print("各分布类型的百分位数统计:")
percentiles = [0, 10, 25, 50, 75, 90, 100]
percentile_df = pd.DataFrame(
{col: np.percentile(df[col], percentiles) for col in df.columns},
index=[f"{p}%" for p in percentiles]
)
print(percentile_df.round(2))生成四组不同类型的数据(正态分布、偏态分布、双峰分布和均匀分布),创建了一个2x2的子图布局,用于绘制每组数据的累计频率图和密度分布。在每张子图中,绘制了累计频率曲线,并使用不同的绘制样式进行了展示。同时,还计算并标注了25%、50%、75%的百分位数,并在次坐标轴上展示了数据的密度分布。此外,每张图还显示了数据的均值、中位数、标准差和样本数等统计信息。
六、散点图
1、概念
散点图是一种常用的数据可视化工具,通过在平面坐标系中绘制数据点来展示两个变量之间的关系。每个数据点由一个横坐标和一个纵坐标表示,横坐标通常代表一个变量,纵坐标代表另一个变量。散点图能够帮助我们识别变量之间是否存在某种关联关系,比如线性关系、非线性关系,或者是否存在离群点。它是探索性数据分析中非常重要的一种图形工具。
2、特点
-
显示关系:散点图通过将数据点绘制在二维坐标轴上,能够直观地展示两个变量之间的关系,比如正相关、负相关或无关联。
-
易于识别趋势:通过散点图,可以清晰地看到数据点的分布情况,帮助识别出潜在的趋势或模式。例如,点是否沿着一条直线分布,或是否存在某种曲线趋势。
-
识别离群点:散点图能够有效识别数据中的离群点(异常值),这些离群点可能与大多数数据点显著不同,通常显示在坐标图的远离主要聚集区的位置。
-
适用于大数据量:即使在数据量较大的情况下,散点图也能够通过显示每个数据点的位置,帮助理解数据的整体分布情况。
-
灵活性:散点图可以通过调整点的大小、颜色等属性来进一步表示数据的其他维度,例如第三个变量或类别信息。
-
不适用于显示非连续数据:散点图更适用于连续型数据,对于分类数据或离散数据不太合适。
3、应用场景
-
探索性数据分析 (EDA):
在数据分析初期,散点图可以帮助分析师了解数据的基本特征,揭示数据中可能存在的关系、趋势和模式。例如,通过绘制不同变量之间的散点图,可以快速判断它们是否相关,关系是否线性。
-
回归分析:
散点图常用于回归分析中,帮助分析自变量与因变量之间的关系。通过散点图,可以直观地判断是否适合使用线性回归模型,或者是否存在非线性关系。
-
识别离群点:
散点图能够有效识别数据中的离群点或异常值,这些点通常在图中远离其他数据点的位置。识别离群点有助于数据清洗或进一步分析。
-
市场分析与消费者行为研究:
在市场分析中,散点图可用于展示不同产品或服务的销售与某些因素(如广告支出、价格等)之间的关系。通过这种方式,企业可以评估不同因素对销售额的影响。
-
金融分析:
在金融领域,散点图可以用于分析股市中不同股票之间的相关性,或者分析某个股票的价格变动与宏观经济指标、行业数据等因素的关系。
-
健康与医学研究:
散点图常用于医学研究中,帮助分析患者的体征数据,如血糖水平与体重、年龄与血压等之间的关系。它有助于找出可能的健康风险因素。
-
质量控制:
在质量控制中,散点图用于分析生产过程中不同变量之间的关系,如产品的重量与温度、湿度与生产效率等,帮助识别潜在的生产问题。
-
多维数据可视化:
当涉及到多维数据时,可以通过在散点图中使用不同的颜色、大小或形状的点来表示数据的其他维度,帮助进行复杂数据集的可视化分析。
4、案例实现
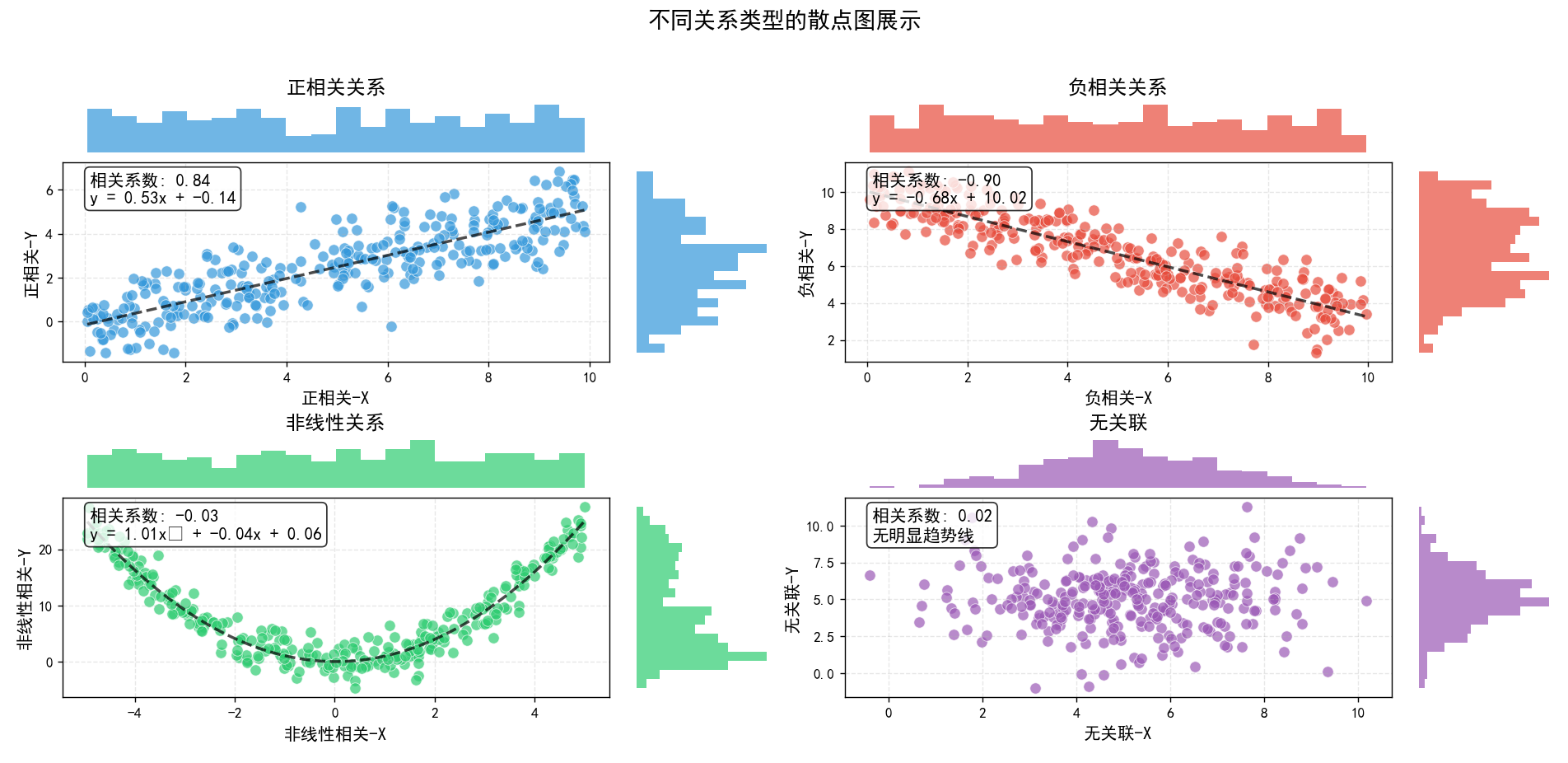
| 关系类型 | 相关系数 | X 变量 - 均值 | X 变量 - 标准差 | Y 变量 - 均值 | Y 变量 - 标准差 | 线性回归 - 斜率 | 线性回归 - 截距 | 线性回归 - R² | 线性回归 - p 值 |
|---|---|---|---|---|---|---|---|---|---|
| 正相关关系 (正相关 - X vs 正相关 - Y) | 0.8433 | 4.95 | 2.94 | 2.46 | 1.84 | 0.5262 | -0.1441 | 0.7111 | 0.0000 |
| 负相关关系 (负相关 - X vs 负相关 - Y) | -0.8979 | 4.82 | 2.85 | 6.75 | 2.15 | -0.6781 | 10.0205 | 0.8063 | 0.0000 |
| 非线性关系 (非线性相关 - X vs 非线性相关 - Y) | -0.0310 | 0.05 | 2.88 | 8.38 | 7.84 | -0.0843 | 8.3861 | 0.0010 | 0.5932 |
| 无关联 (无关联 - X vs 无关联 - Y) | 0.0152 | 5.10 | 1.88 | 5.00 | 1.99 | 0.0161 | 4.9132 | 0.0002 | 0.7928 |
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
from scipy import stats
# 设置中文字体支持
plt.rcParams['font.sans-serif'] = ['SimHei'] # 黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 设置随机种子以便结果可重现
np.random.seed(42)
# 生成具有不同分布特征的数据
n_samples = 300
# 1. 线性相关数据(正相关)
x1 = np.random.uniform(0, 10, n_samples)
y1 = 0.5 * x1 + np.random.normal(0, 1, n_samples)
corr1 = np.corrcoef(x1, y1)[0, 1]
# 2. 线性相关数据(负相关)
x2 = np.random.uniform(0, 10, n_samples)
y2 = 10 - 0.7 * x2 + np.random.normal(0, 1, n_samples)
corr2 = np.corrcoef(x2, y2)[0, 1]
# 3. 非线性相关数据(二次函数关系)
x3 = np.random.uniform(-5, 5, n_samples)
y3 = x3 ** 2 + np.random.normal(0, 2, n_samples)
# 由于是非线性关系,皮尔逊相关系数不是很有意义,但我们仍计算它作为参考
corr3 = np.corrcoef(x3, y3)[0, 1]
# 4. 无关联数据
x4 = np.random.normal(5, 2, n_samples)
y4 = np.random.normal(5, 2, n_samples)
corr4 = np.corrcoef(x4, y4)[0, 1]
# 创建包含所有数据的DataFrame
data = pd.DataFrame({
'正相关-X': x1, '正相关-Y': y1,
'负相关-X': x2, '负相关-Y': y2,
'非线性相关-X': x3, '非线性相关-Y': y3,
'无关联-X': x4, '无关联-Y': y4
})
# 创建2x2子图
fig, axes = plt.subplots(2, 2, figsize=(14, 12))
axes = axes.flatten()
# 设置颜色和标题
colors = ['#3498db', '#e74c3c', '#2ecc71', '#9b59b6']
titles = ['正相关关系', '负相关关系', '非线性关系', '无关联']
x_cols = ['正相关-X', '负相关-X', '非线性相关-X', '无关联-X']
y_cols = ['正相关-Y', '负相关-Y', '非线性相关-Y', '无关联-Y']
corrs = [corr1, corr2, corr3, corr4]
# 绘制四种不同类型的散点图
for i, (ax, color, title, x_col, y_col, corr) in enumerate(zip(axes, colors, titles, x_cols, y_cols, corrs)):
# 基本散点图
ax.scatter(data[x_col], data[y_col], color=color, alpha=0.7, s=60, edgecolor='white', linewidth=0.5)
# 添加趋势线
if i < 2: # 对于线性关系,添加线性回归线
slope, intercept, r_value, p_value, std_err = stats.linregress(data[x_col], data[y_col])
x_line = np.linspace(data[x_col].min(), data[x_col].max(), 100)
y_line = slope * x_line + intercept
ax.plot(x_line, y_line, color='black', linestyle='--', linewidth=2, alpha=0.7)
line_eq = f'y = {slope:.2f}x + {intercept:.2f}'
elif i == 2: # 对于非线性关系,添加多项式回归线
z = np.polyfit(data[x_col], data[y_col], 2)
p = np.poly1d(z)
x_line = np.linspace(data[x_col].min(), data[x_col].max(), 100)
y_line = p(x_line)
ax.plot(x_line, y_line, color='black', linestyle='--', linewidth=2, alpha=0.7)
line_eq = f'y = {z[0]:.2f}x² + {z[1]:.2f}x + {z[2]:.2f}'
else: # 对于无关联数据,不添加趋势线
line_eq = '无明显趋势线'
# 添加边缘密度图
# X轴密度
ax_histx = ax.inset_axes([0, 1.05, 1, 0.25], sharex=ax)
ax_histx.hist(data[x_col], bins=20, color=color, alpha=0.7)
ax_histx.axis('off')
# Y轴密度
ax_histy = ax.inset_axes([1.05, 0, 0.25, 1], sharey=ax)
ax_histy.hist(data[y_col], bins=20, orientation='horizontal', color=color, alpha=0.7)
ax_histy.axis('off')
# 设置标题和标签
ax.set_title(title, fontsize=14)
ax.set_xlabel(x_col, fontsize=12)
ax.set_ylabel(y_col, fontsize=12)
# 添加相关系数和回归方程信息
stats_text = f"相关系数: {corr:.2f}\n{line_eq}"
ax.text(0.05, 0.95, stats_text, transform=ax.transAxes, fontsize=12,
verticalalignment='top', bbox=dict(boxstyle='round', facecolor='white', alpha=0.8))
# 添加网格线
ax.grid(True, linestyle='--', alpha=0.3)
# 添加总标题
plt.suptitle('不同关系类型的散点图展示', fontsize=16)
# 调整布局
plt.tight_layout(rect=[0, 0.05, 1, 0.95])
# 显示图形
plt.show()
# 打印数据的基本统计信息
print("各组数据的基本统计信息:")
for x_col, y_col, title, corr in zip(x_cols, y_cols, titles, corrs):
print(f"\n{title} ({x_col} vs {y_col}):")
print(f"相关系数: {corr:.4f}")
print(f"{x_col} - 均值: {data[x_col].mean():.2f}, 标准差: {data[x_col].std():.2f}")
print(f"{y_col} - 均值: {data[y_col].mean():.2f}, 标准差: {data[y_col].std():.2f}")
# 计算线性回归(即使是非线性关系,也计算线性回归作为参考)
slope, intercept, r_value, p_value, std_err = stats.linregress(data[x_col], data[y_col])
print(f"线性回归 - 斜率: {slope:.4f}, 截距: {intercept:.4f}, R²: {r_value ** 2:.4f}, p值: {p_value:.4f}")主要实现了生成四组不同关系类型的数据(正相关、负相关、非线性相关和无关联),并使用Matplotlib和Seaborn库绘制了它们的散点图。每组数据包括两个变量(X和Y),代码计算了它们之间的皮尔逊相关系数,并添加了相应的趋势线(线性或多项式回归)。此外,还在每个散点图的边缘添加了密度图,显示了数据分布。最后,打印了每组数据的基本统计信息,包括均值、标准差、相关系数和线性回归参数。整个图形包括一个总标题和四个子图,每个子图都有相应的标题、标签和统计信息标注。
七、茎叶图
1、概念
茎叶图(Stem-and-leaf plot)是一种用来展示数据分布的图形工具,它将数据按一定的规则分组,并在图中通过“茎”和“叶”表示数据的结构。通常,数据的高位数字作为“茎”,低位数字作为“叶”。这种图形形式能够保留原始数据的具体数值,同时显示数据的集中趋势、分布情况和波动情况。茎叶图适用于中小规模数据的可视化,能够直观地反映数据的形态和分布特征,尤其在描述数据分布的对比、观察数据的集中趋势和离群点方面有较好的效果。
2、特点
-
直观展示数据分布:
茎叶图能够直观地显示数据的分布情况,包括数据的集中趋势、分散程度和形态特征,使得数据的具体数值和分布都能一目了然。
-
保留原始数据:
与其他图表(如直方图、箱线图)不同,茎叶图保留了原始数据的具体数值。这使得用户能够从图形中快速获取每个数据点的精确值。
-
适用于中小规模数据:
茎叶图适用于中小规模的数据集,特别是数据量较小(如几十个数据点),当数据量过大时,茎叶图会变得难以阅读。
-
能够识别数据的集中趋势和分布:
茎叶图通过将数据分组,能够清晰地显示数据的集中趋势、分布范围以及是否存在离群点,从而帮助分析数据的形态和特征。
-
有助于比较多个数据集:
在同一图上绘制多个数据集的茎叶图,可以直观地比较不同数据集的分布差异,方便进行相对比较。
-
适合用于定量数据:
茎叶图适用于定量数据,尤其是那些连续型数值数据。它不适合用于处理类别型数据或离散型数据。
-
易于手工制作:
茎叶图相对简单,适合手工绘制,尤其是在分析数据时无需使用复杂的工具或软件,适合快速地进行数据可视化。
-
支持对称和非对称数据:
茎叶图不仅可以显示对称分布(如正态分布)的数据,还能很好地展示非对称分布的数据(如偏态分布)。
3、应用场景
-
探索性数据分析 (EDA):
在数据分析的初期阶段,茎叶图能够帮助分析师快速了解数据的基本特征,直观地展示数据的分布、集中趋势和波动情况。它适合用于中小规模数据集的初步分析。
-
数据分布的可视化:
茎叶图能够展示数据的分布情况,尤其是在数据量较小的情况下,能够显示数据是否呈现对称、偏态或其他分布模式。它可以帮助分析数据的离散程度和可能的离群点。
-
检查数据的偏态性:
通过观察茎叶图,分析师可以容易地判断数据是否呈现正偏态或负偏态(即分布是否偏向数据的一侧)。这对进一步选择合适的统计分析方法有重要帮助。
-
比较不同数据集:
在同一图上可以绘制多个数据集的茎叶图,帮助分析人员直观地比较不同数据集的分布特征,例如不同群体、时间段或地区的表现差异。
-
简洁的数据展示:
茎叶图适合用于报告和简洁的数据展示,尤其是当需要展示数据的原始值并且数据量较小的时候,能够使受众快速理解数据的分布和特点。
-
教育和教学:
在统计学和数据科学的教学中,茎叶图是一个很好的工具,帮助学生理解数据分布、数据排序和数据总结的概念。它也有助于学生掌握如何通过简单的方式展示和解释数据。
-
初步的统计分析:
在进行更复杂的统计分析之前,茎叶图可以作为一种工具,帮助分析人员初步识别数据的特征,如集中趋势、离群值、对称性等,便于进一步选择合适的分析方法。
-
质量控制与监控:
在生产和质量控制中,茎叶图可以用来分析测量数据(如产品尺寸、重量等)的分布情况,帮助识别生产过程中的偏差或不稳定性。
-
科研和实验数据分析:
在科学研究中,茎叶图有助于快速查看实验数据的分布特征。例如,在医学实验、社会科学研究等领域,茎叶图可以帮助科研人员快速识别出实验组之间的差异。
4、案例实现
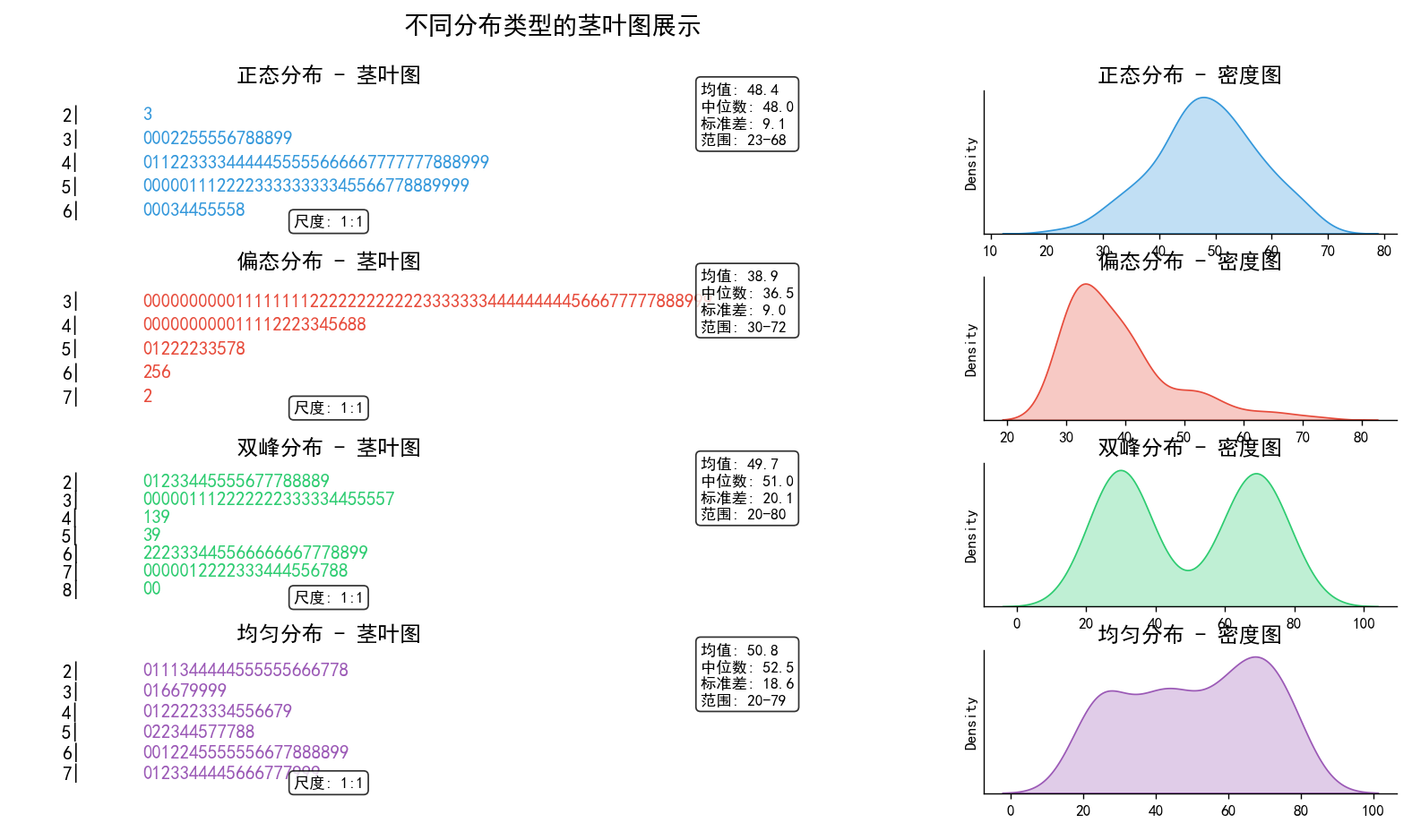
正态分布统计信息表:
| 统计指标 | 数值 |
|---|---|
| 样本数 | 100 |
| 均值 | 48.42 |
| 中位数 | 48.00 |
| 标准差 | 9.08 |
| 最小值 | 23 |
| 最大值 | 68 |
| 四分位数 Q1 | 43.0 |
| 四分位数 Q3 | 53.25 |
偏态分布统计信息表:
| 统计指标 | 数值 |
|---|---|
| 样本数 | 100 |
| 均值 | 38.85 |
| 中位数 | 36.50 |
| 标准差 | 9.00 |
| 最小值 | 30 |
| 最大值 | 72 |
| 四分位数 Q1 | 32.0 |
| 四分位数 Q3 | 41.25 |
双峰分布统计信息表:
| 统计指标 | 数值 |
|---|---|
| 样本数 | 100 |
| 均值 | 49.66 |
| 中位数 | 51.00 |
| 标准差 | 20.12 |
| 最小值 | 20 |
| 最大值 | 80 |
| 四分位数 Q1 | 30.75 |
| 四分位数 Q3 | 69.0 |
均匀分布统计信息表:
| 统计指标 | 数值 |
|---|---|
| 样本数 | 100 |
| 均值 | 50.80 |
| 中位数 | 52.50 |
| 标准差 | 18.62 |
| 最小值 | 20 |
| 最大值 | 79 |
| 四分位数 Q1 | 36.0 |
| 四分位数 Q3 | 67.25 |
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
from collections import defaultdict
# 设置中文字体支持
plt.rcParams['font.sans-serif'] = ['SimHei'] # 黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 设置随机种子以便结果可重现
np.random.seed(42)
# 生成不同类型的分布数据
n_samples = 100
# 正态分布数据 (均值=50, 标准差=10)
# 修正:将n_samples作为关键字参数size
normal_data = np.random.normal(loc=50, scale=10, size=n_samples).astype(int)
# 偏态分布数据 (指数分布,平移到正值区域)
skewed_data = (np.random.exponential(scale=10, size=n_samples) + 30).astype(int)
# 双峰分布数据 (两个正态分布的混合)
bimodal_data = np.concatenate([
np.random.normal(loc=30, scale=5, size=n_samples // 2),
np.random.normal(loc=70, scale=5, size=n_samples // 2)
]).astype(int)
# 均匀分布数据
uniform_data = np.random.uniform(low=20, high=80, size=n_samples).astype(int)
# 创建一个函数用来生成茎叶图数据
def create_stem_leaf(data, scale=1):
"""
创建茎叶图数据结构。
参数:
data: 输入数据数组
scale: 缩放因子,决定每个茎的间隔
返回:
stem_leaf: 包含茎和叶的字典
"""
# 将数据除以scale,整数部分为茎,小数部分(乘以10并取整)为叶
stems = {}
for value in sorted(data):
stem = value // (10 * scale)
leaf = (value // scale) % 10
if stem not in stems:
stems[stem] = []
stems[stem].append(leaf)
return stems
# 创建一个函数用来绘制茎叶图
def plot_stem_leaf(data, ax, title, color, scale=1):
"""
在给定的轴上绘制茎叶图。
参数:
data: 输入数据数组
ax: matplotlib轴对象
title: 图的标题
color: 图的颜色
scale: 缩放因子,决定每个茎的间隔
"""
stems = create_stem_leaf(data, scale)
# 按茎的顺序排序
sorted_stems = sorted(stems.keys())
# 找到最大叶子数,用于调整图形宽度
max_leaves = max(len(leaves) for leaves in stems.values())
# 绘制茎叶图
for i, stem in enumerate(sorted_stems):
# 转换叶子为字符串并排序
leaves = stems[stem]
leaves_str = ''.join(map(str, sorted(leaves)))
# 绘制茎
ax.text(0.3, len(sorted_stems) - i - 1, f"{stem}|", ha='right', va='center', fontsize=12, color='black')
# 绘制叶
ax.text(0.35, len(sorted_stems) - i - 1, leaves_str, ha='left', va='center', fontsize=12, color=color)
# 设置图的属性
ax.set_title(title, fontsize=14)
ax.set_xlim(0, 1)
ax.set_ylim(-1, len(sorted_stems))
ax.axis('off') # 不显示坐标轴
# 添加图例
scale_text = f"尺度: 1个单位 = {scale * 10}" if scale > 1 else "尺度: 1:1"
ax.text(0.5, -0.5, scale_text, ha='center', va='center', fontsize=10,
bbox=dict(facecolor='white', alpha=0.8, boxstyle='round,pad=0.3'))
# 添加统计信息
stats_text = (
f"均值: {np.mean(data):.1f}\n"
f"中位数: {np.median(data):.1f}\n"
f"标准差: {np.std(data):.1f}\n"
f"范围: {np.min(data)}-{np.max(data)}"
)
ax.text(0.8, len(sorted_stems) * 0.8, stats_text, ha='left', va='center', fontsize=10,
bbox=dict(facecolor='white', alpha=0.8, boxstyle='round,pad=0.3'))
# 创建用于添加密度图的辅助函数
def add_density_plot(data, ax, color):
"""
在给定的轴上添加密度图。
参数:
data: 输入数据数组
ax: matplotlib轴对象
color: 图的颜色
"""
sns.kdeplot(data, ax=ax, color=color, fill=True, alpha=0.3)
ax.set_ylim(0)
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.set_yticks([])
# 创建图形和子图
fig = plt.figure(figsize=(16, 12))
# 定义图形布局 - 每种分布类型一行,左边是茎叶图,右边是密度图
gs = fig.add_gridspec(4, 2, width_ratios=[3, 1], height_ratios=[1, 1, 1, 1])
# 设置颜色和数据
colors = ['#3498db', '#e74c3c', '#2ecc71', '#9b59b6']
all_data = [normal_data, skewed_data, bimodal_data, uniform_data]
titles = ['正态分布', '偏态分布', '双峰分布', '均匀分布']
# 为每种分布创建子图
for i, (data, title, color) in enumerate(zip(all_data, titles, colors)):
# 茎叶图
ax_stem = fig.add_subplot(gs[i, 0])
plot_stem_leaf(data, ax_stem, f"{title} - 茎叶图", color)
# 密度图
ax_density = fig.add_subplot(gs[i, 1])
add_density_plot(data, ax_density, color)
ax_density.set_title(f"{title} - 密度图", fontsize=14)
# 添加总标题
plt.suptitle('不同分布类型的茎叶图展示', fontsize=16)
# 调整布局
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
# 显示图形
plt.show()
# 打印各分布的统计信息
print("不同分布类型的统计信息:")
for data, title in zip(all_data, titles):
print(f"\n{title}:")
print(f"样本数: {len(data)}")
print(f"均值: {np.mean(data):.2f}")
print(f"中位数: {np.median(data):.2f}")
print(f"标准差: {np.std(data):.2f}")
print(f"最小值: {np.min(data)}")
print(f"最大值: {np.max(data)}")
print(f"四分位数: Q1={np.percentile(data, 25)}, Q3={np.percentile(data, 75)}")
# 展示茎叶图的文字表示
print("\n茎叶图文字表示示例(正态分布):")
stems = create_stem_leaf(normal_data)
for stem in sorted(stems.keys()):
leaves = stems[stem]
leaves_str = ''.join(map(str, sorted(leaves)))
print(f"{stem:2d} | {leaves_str}")生成四组不同分布特征的数据(正态分布、偏态分布、双峰分布和均匀分布),定义了两个函数:create_stem_leaf用于生成茎叶图数据结构,plot_stem_leaf用于在给定的Matplotlib轴上绘制茎叶图。然后,创建了一个辅助函数add_density_plot用于在给定的轴上添加密度图。创建了一个图形和子图布局,并为每种分布类型创建了茎叶图和密度图子图。最后打印各分布的统计信息,并展示了正态分布的茎叶图的文字表示。整个图形包括一个总标题和四个子图,每个子图都有相应的标题和统计信息标注。
八、各图形对比总结
1、分布类可视化图像对比表
| 图表类型 | 优点 | 缺点 | 数据保留 | 适用数据量 | 显示特性 | 最适用场景 |
|---|
| 直方图 | • 直观展示频率分布 • 易于理解 • 可调整bin宽度探索不同分辨率 | • 依赖bin宽度选择 • 无法展示精确数值 • 可能掩盖细节 | 不保留原始数据 | 大、中、小 | 频率分布、集中趋势 | 总体分布形态分析、频率分布展示 |
| 密度图 | • 平滑展示分布 • 连续性好 • 多组数据比较方便 | • 依赖带宽参数 • 基于估计而非实际数据 • 可能过平滑 | 不保留原始数据 | 中、大 | 分布形态、多峰检测 | 多组数据比较、分布形态分析、连续数据展示 |
| 箱线图 | • 显示关键统计量 • 识别异常值 • 紧凑 | • 丢失分布细节 • 无法显示多峰 • 过度简化 | 仅保留统计量 | 大、中、小 | 四分位数、离群值、中位数 | 多组数据比较、异常值检测、概括性统计展示 |
| 小提琴图 | • 结合密度图和箱线图优点 • 显示分布形态和统计量 • 多组比较直观 | • 复杂度较高 • 对小样本效果有限 • 有时过于复杂 | 仅保留统计量 | 中、大 | 分布形态、多峰性、分位数 | 复杂分布形态比较、多组数据对比、研究细节与总体 |
| 累计频率图 | • 展示累积分布 • 容易读取分位数 • 直观比较整体分布 | • 细节不如直方图 • 不适合识别多峰 • 解读需要训练 | 不保留原始数据 | 大、中、小 | 累积分布、分位数 | 分位数分析、分布比较、阈值分析 |
| 散点图 | • 显示变量关系 • 保留所有数据点 • 可添加第三维度 | • 不直接显示分布 • 点重叠问题 • 需要两个变量 | 完全保留原始数据 | 小、中 | 相关性、关系模式、离群点 | 变量关系分析、相关性研究、模式识别 |
| 茎叶图 | • 保留原始数据 • 直观展示分布 • 易于手动创建 | • 不适合大数据集 • 只适用于整数或小数 • 显示受限 | 完全保留原始数据 | 小、中(小) | 分布形态、原始数据值 | 小样本探索、教学演示、保留原始数据的分布展示 |
2、不同分布类型的适用性
| 分布类型 | 最适合的图表类型 | 次优选择 |
|---|---|---|
| 正态分布 | 直方图、密度图 | 箱线图、小提琴图 |
| 偏态分布 | 密度图、小提琴图 | 直方图、累计频率图 |
| 多峰分布 | 密度图、小提琴图 | 直方图、核密度估计 |
| 离散分布 | 直方图、茎叶图 | 箱线图 |
| 重尾分布 | 累计频率图、密度图 | 箱线图(含离群点) |
| 混合分布 | 密度图、小提琴图 | 核密度估计 |
| 稀疏数据 | 散点图、茎叶图 | 箱线图 |
| 聚类数据 | 散点图、密度图 | 直方图 |
3、应用场景比较
| 分析需求 | 推荐图表类型 | 理由 |
|---|---|---|
| 总体分布形态 | 直方图、密度图 | 直观展示频率分布和整体形态 |
| 多组数据比较 | 箱线图、小提琴图 | 并排展示多组数据的统计特征和分布差异 |
| 异常值检测 | 箱线图、散点图 | 明确标识离群点和异常值 |
| 精确数值保留 | 散点图、茎叶图 | 保留原始数据值 |
| 分位数分析 | 累计频率图、箱线图 | 直观展示分位数和累积分布 |
| 多峰分布识别 | 密度图、小提琴图 | 能够显示分布中的多个峰值 |
| 教学演示 | 茎叶图、直方图 | 直观易懂,适合教学目的 |
| 大数据集分析 | 密度图、直方图 | 能够高效处理和展示大量数据 |
| 相关性分析 | 散点图 | 直观展示两个变量之间的关系 |
| 复杂分布形态 | 小提琴图、密度图 | 能够展示复杂的分布形态和细节 |
在数据分析与可视化领域,不同类型的分布图表各具特色,服务于不同的分析需求。直方图以其简单直观的特性成为展示频率分布的基础工具;密度图则通过平滑曲线优雅地呈现连续分布,特别适合多组数据比较;箱线图凭借其紧凑的设计高效展示关键统计量和异常值;小提琴图作为箱线图和密度图的结合,全面展示分布形态和统计信息;累计频率图专注于累积分布和分位数分析;散点图直观展示变量关系并保留原始数据点;茎叶图在保留原始数据的同时展示分布形态,尤其适合小样本教学场景。
选择合适的可视化方法需考虑多方面因素:数据量大小、是否需要保留原始数据、分析重点(如总体分布、异常值检测、多峰识别等)以及数据本身的分布特征。在实践中,通常结合使用不同类型的图表以获得数据分布的全面视角,从而支持更准确、深入的数据分析和决策。每种图表都有其独特价值,了解它们的特点和适用场景,能够帮助分析师根据具体需求选择最合适的可视化工具。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









