






目录
目录
分桶表
分区表:分区字段不是表中的字段
分桶表:分桶字段必须是表中字段
建表语句:
select * from stu_buck tablesample(bucket 1 out of 4 on id);
从第几份开始抽 将全部数据(桶)分成几份 函数
函数分为:UDF:一进一出 UDAF:多进多出 UDTF:一进多出(体现的是数据的行数)
1)查看系统自带的函数
show functions;
2)显示自带的函数的用法
desc function upper;
3)详细显示自带的函数的用法
desc function extended upper;空字符段赋值函数
如果comm 为 NULL,则用-1 代替
select comm,nvl(comm, -1) from emp;
CASE WHEN THEN ELSE END
求出不同部门男女各多少人
select dept_id,
sum(case sex when '男' then 1 else 0 end) maleCount,
sum(case sex when '女' then 1 else 0 end) femaleCount
from emp_sex group by dept_id;
与if else函数功能类似
select dept_id,
sum(if (sex='男',1,0)) maleCount,
sum(if (sex='女',0,1)) femaleCount
from emp_sex group by dept_id;多列变一列
将学生id生成数组
select collect_list(id) from student1;
select concat('a','-','b','-','c');
输出a-b-c
select concat_ws('-','a','b','c'); 与上条输出一致一行变多行
select
movie,category_name
from movie_info lateral view explode(split(category,',')) movie_info_tmp -- 侧写表表名
as category_name; -- 炸出字段的别名
--侧写表与原来数据做一个关联,否则炸出的行数与原表行数不一致无法匹配输出
split(str,regex)str:字符串,regex:分隔符 功能:转换成数组窗口函数(开窗函数)

-- 查询在 2017 年 4 月份购买过的顾客及总人数
select
distinct (name)
from business
where substring(orderdate,0,7)='2017-04' ;
-- 聚合函数+over()案例
--查询2017四月每位顾客消费总量
select
name,count(*) over()--开窗口 ,count的是窗口里的内容,若是窗口里没有则用该组所有行
from business
where substring(orderdate,0,7)='2017-04'
group by name;--group by --相同字段分成一个组
-- 查询顾客的购买明细及月购买总额
select name,orderdate,cost,sum(cost) over (partition by name,month(orderdate))--限定开窗范围
from business;
-- 将每个顾客的 cost 按照日期进行累加
select name,
orderdate,
cost,
sum(cost) over (partition by name order by orderdate)
from business;
--
select
name,
orderdate,
lag(orderdate,1) over(partition by name order by orderdate)
from business;
--查看顾客上次的购买时间
select name,
orderdate,
cost,
sum(cost) over (partition by name order by orderdate
rows between UNBOUNDED PRECEDING and current row )
from business;
--与上一条结果一样
--只有order by 默认是从开始到当前行,若是有相同则相同字段开窗范围一致
substring(str, pos[, len]) 功能:截取数据
partition by 和order by连用,功能一致
distribute by 和 sort by
Rank(与窗口函数结合使用)
--按成绩排序号
select *,rank()over(order by score) from score;
grouping set多维分析
grouping sets是group by子句更进一步的扩展,它能够定义多个数据分组。这样做使聚合更容易,并且因此使得多维数据分析更容易。
用grouping sets在同一查询中定义多个分组。
grouping sets:对分组集中指定的组表达式的每个子集执行group by,group by A,B grouping sets(A,B)就等价于 group by A union group by B;其中A和B也可以是一个集合,比如group by A,B,C grouping sets((A,B),(A,C))。
自定义函数
添加 jar
add jar linux_jar_path
创建 functionquanliem
create [temporary] function [dbname.]function_name AS class_name;压缩和存储
|
压缩格式
| 文件扩展名 | 是否可切分 |
|
DEFLATE
|
.deflate
|
否
|
|
Gzip
|
.gz
| 否 |
|
bzip2
|
.bz2
| 是 |
|
LZO
|
.lzo
| 是 |
|
Snappy
|
.snappy
| 否 |
开启 Map 输出阶段压缩( MR 引擎)
查看支持的压缩方式
hadoop checknative
(1)开启 hive 中间传输数据压缩功能
hive (default)>set hive.exec.compress.intermediate=true;
(2)开启 mapreduce 中 map 输出压缩功能
hive (default)>set mapreduce.map.output.compress=true;
(3)设置 mapreduce 中 map 输出数据的压缩方式(snappy)
hive (default)>set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
(1)开启 hive 最终输出数据压缩功能
hive (default)>set hive.exec.compress.output=true;
(2)开启 mapreduce 最终输出数据压缩
hive (default)>set mapreduce.output.fileoutputformat.compress=true;
(3)设置 mapreduce 最终数据输出压缩方式
hive (default)> set mapreduce.output.fileoutputformat.compress.codec =
org.apache.hadoop.io.compress.SnappyCodec;
(4)设置 mapreduce 最终数据输出压缩为块压缩
hive (default)> set
mapreduce.output.fileoutputformat.compress.type=BLOCK;
(5)测试一下输出结果是否是压缩文件
hive (default)> insert overwrite local directory
'/opt/module/data/distribute-result' select * from emp distribute by
deptno sort by empno desc;文件存储格式
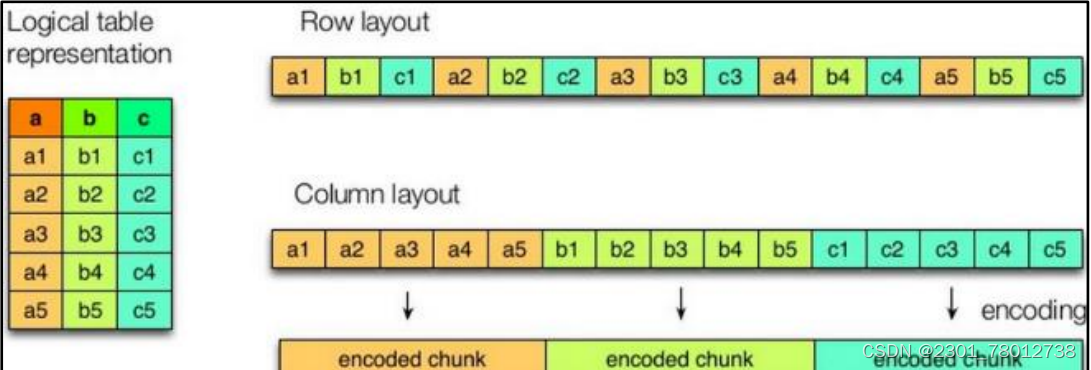
Orc 格式
列式存储的一种,每个 Orc 文件由 1 个或多个 stripe 组成,每个 stripe 一般为 HDFS的块大小,每一个 stripe 包含多条记录,这些记录按照列进行独立存储。
优点:存储大小最小,三种文件格式的查询速度差不多,所以生成中多用Orc格式。
create table log_orc(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as orc
tblproperties("orc.compress"="NONE"); -- 设置 orc 存储不使用压缩
hive (default)> insert overwrite local directory
'/opt/module/data/log_orc' select substring(url,1,4) from log_orc;
-- 插入数据hdfs看文件大小Parquet 格式
Parquet 文件是以二进制方式的行组、列组存储
行组:每一个行组包含一定的行数,在一个 HDFS 文件中至少存储一个行组,类似于 orc 的 stripe 的概念。
列块:在一个行组中每一列保存在一个列块中,行组中的所有列连续的存储在这个行组文件中。一个列块中的值都是相同类型的,不同的列块可能使用不同的算法进行压缩。
页(Page):每一个列块划分为多个页,一个页是最小的编码的单位,在同一个列块的不同页可能使用不同的编码方式。
在 Parquet 中,有三种类型的页:数据页、字典页和索引页。数据页用于存储当前行组中该列的值,字典页存储该列值的编码字典,每一个列块中最多包含一个字典页,索引页用来存储当前行组下该列的索引,
CSV文件:以","分割的文件格式,类似windows的excel文件。
TSV文件:以" "分割的文件格式。
存储和压缩结合
案例
创建一个 ZLIB 压缩的 ORC 存储方式
(1)建表语句
create table log_orc_zlib(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as orc
tblproperties("orc.compress"="ZLIB");
(2)插入数据
insert into log_orc_zlib select * from log_text;
(3)查看插入后数据
hive (default)> dfs -du -h /user/hive/warehouse/log_orc_zlib/ ;离线数仓教育项目
项目的架构
基于cloudera manager大数据统一管理平台,在此平台之上构建大数据相关的软件
(zookeeper ,HDFS,YARN ,HIVE , 00ZIE ,SQ0OP ,HUE...),除此以外,还使用FINEBI实现数据报表展示。
各个软件相关作用:
zookeeper:集群管理工具,主要服务于hadoop高可用以及其他基于zookeeper管理的大数据软件
HDFS:主要负责最终数据的存储
YARN:主要提供资源的分配
HIVE:用于编写SQL,进行数据分析
oozie:主要是用来做自动化定时调度
sqoop:主要是用于数据的导入导出
HUE:提升操作hadoop用户体验,可以基于HUE操作HDFS,HIVE
FINEBI:由帆软公司提供的一款进行数据报表展示工具
项目架构中:数据流转的流程

首先业务是存储在MySQL数据库中,通过sqoop对MySQL 的数据进行数据的导入操作,将数据导入到HIVE的ODS层中,对数据进行清洗转换成处理工作,处理之后对数据进行统计分析,将统计分析的结果基于sqoop在导出到MySQL中,最后使用finebi实现图表展示操作,由于分析工作是需要周期性干活,采用ooize进行自动化的调度工作,整个项目是基于cloudera manager进行统一监控管理。
cloudera manager:是cloder公司推出的专门用来管理监控CDH相关软件的工具,可以轻松部署和集中操作完整的CDH堆栈和其他托管服务(Hadoop、Hive、Spark、Kudu)。其特点:应用程序的安装过程自动化,将部署时间从几周缩短到几分钟; 并提供运行主机和服务的集群范围的实时监控视图; 提供单个中央控制台,以在整个群集中实施配置更改; 并集成了全套的报告和诊断工具,可帮助优化性能和利用率,解决了Apache 版本Hadoop生态圈组件的缺点。
注意事项
浏览器:http://hadoop01:7180或http://hadoop01.itcast.cn:7180
切记:后续关机问题:
教育项目中虚拟机,坚决不允许挂起,以及强制关闭操作,如果做了,非常大的概率导致服务器出现内存以及磁盘问题,需要重新配置。
关机必须在CRT或者fineShell 或者xShell上直接关机命令: shutdown -h now (每一个节 点都要执行)
重启服务器:执行reboot (每一个节点都要执行)
注意: CDH软件开机后,整个所有服务族复正常,大约需要耗时10~20分钟左右,可能有大量的都是红色感叹号,等待20分钟之后
数据仓库的基本概念
什么是数据仓库:
存储数据的仓库,主要是用于存储过去既定发生的历史数据,对这些数据进行数据分析的操作,从而对未来提供决策支持。
数据仓库最大的特点:
既不生产数据,也不消耗数据,数据来源于各个数据源
数据仓库的四大特征:
1)面向于 主题的:面向于分析,分析的内容是什么什么就是我们的主题
2)集成性: 数据是来源于各 个数据源,将各个数据源数据汇总在一一起
3)非易失性(稳定性):存储在数据仓库中数据都是过去既定发生数据,这些数据都是相对比较稳定的数据,不会发生改
变
4)时变性:随着的推移, 原有的分析手段以及原有数据可能都会出现变化(分析手动更换,以及数据新增)
ETL:
ETL:抽取、转换、加载
指数据从数据源将数据灌入到ODS层,以及从ODS层将数据抽取出来,对数据进行转换处理工作,最终将数据加载到DW层,然后DW层对数据进行统计分析,将统计分析后的数据灌入到DA层,整个全过程都是属于ETL范畴。
数据仓库与数据集市
数仓架构

数据仓库和数据集市区别
数据仓库是针对企业整体分析数据的集合。
数据集市是针对部门级别分析的数据集合。
应用系统:这里的应用系统是指使用数据仓库完成数据分析、数据查询、数据报表等功能的系统。及生成报表。
用户:使用数据仓库系统的用户主要有数据分析人员、管理决策人员(公司高层)等。
维度分析
对数据进行分析通常采取维度分析,比如:用户提出分析课程访问量的指标,为了满足不同的分析需求可以从时间维度分析课程访问量,分析每天、每小时的课程访问量;也可以从课程维度来分析课程访问量,分析每个课程、每个课程分类的访问量。
指标与维度
维度是事务的特征,如颜色、区域、时间等,可以根据不同的维度来对指标进行分析对比。比如根据区域维度来分析不同区域的产品销量,根据时间来分析每个月产品的销量,同一个产品销量指标从不同的维度分析会得出不同的结果。
维度分为定性维度和定量维度两种,
定性维度:就是字符类型的特征,比如区域维度包括全国各省份;
定量维度:就是数值类型的特征,如价格区间、销量区间等,如价格区间维度分为0--100、100-1000两个区间,
指标是衡量事务发展的标准,也叫度量,如价格,销量等;指标可以求和、求平均值等计算。
指标分为绝对数值和相对数值,
绝对指标:反映具体的大小和多少,如价格、销量、分数等;
相对指标:反映一定的程度,如及格率、购买率、涨幅等。
维度分层与分级
相当于将维度进行细分。细分两层,则维度包含一个层次,多个级别。 细分三层,则维度包含多个层次,多个级别。
比如全年课程购买量,然后会详细去看每个季度、每个月的课程购买量,全年、季度、月这些属于时间维度的一个层次,年、季度、月是这个层次的三个级别;还有按地区分析课程购买量,全国、省、市、县属于地区维度的一个层次,层次中共有四个级别。
数仓建模
数仓建模指的规定如何在hive中构建表,数仓建模中主要提供两种理论来进行数仓建模操作:三范式建模和维度建模理论。
三范式建模:主要是存在关系型数据库建模方案上,主要规定了比如建表的每一个表都应该有一个主键,数据要尽量的避免冗余发生等。
维度建模:主要是存在分析性数据库建模方案上,主要一切以分析为目标, 只要是利于分析的建模,都是允许的,允许出现一定的冗余, 表也可以没有主键
维度建模的两个核心概念:事实表和维度表。
事实表和维度表
简单描述
事实表:一般指的就是分析主题所对应的表,每一条数据用于描述一 个具体的事实信息,事实表记录了特定事件的数字化信息,一般由数值型数字和指向维度表的外键组成。
事实表的设计依赖于业务系统,事实表的数据就是业务系统的指标数据。数据分析的实质就是基于事实表开展的计算操作。
注意:一般需要计算的指标字段所在表,都是事实表
维度表:维度是指观察数据的角度,一般是一个名词,比如对于销售金额这个事实,我们可以从销售时间、销售产品、销售店铺、购买顾客等多个维度来观察分析。在对事实表进行统计分析的时候,基于某一个维度, 而这个维度具体信息可能其他表中,可能需要关联到其他的表(维度表),而这些表就是维度表。
维度表的记录数比事实表少,但是每条记录可能会包含很多字段。
维度表并不一定存在,但是维度是一定存在:
比如:根据用户维度进行统计,如果在事实表只存储了用户id,此时需要关联用户表,这个时候就是维度表。
比如:根据用户维度进行统计,如果在事实表不仅仅存储了用户id,还存储用户名称,所需要的数据在事务表中有,这个时候有用户维度,但是不需要用户表的参与,意味着没有这个维度表。
分类
事实表的分类
1) 事务事实表:
保存的是最原子的数据,也称“原子事实表”或“交易事实表”。沟通中常说的事实表,大多指的是事务事实表。
2)周期快照事实表:
周期快照事实表以具有规律性的、可预见的时间间隔来记录事实,时间间隔如每天、每月、每年等等,简单来说,就是按照一个可以预见的周期进行提前聚合形成的事实表,周期表由事务表加工产生。
作用:通过周期快照事实表,完成提前聚合操作,当需要进行上卷统计的时候,只需要对周期表数据进行累加即可,减少数据扫描量,提升查询的效率。
3) 累计快照事实表:
完全覆盖一个事务或产品的生命周期的时间跨度,它通常具有多个日期字段,用来记录整个生命周期中的关键时间点。例如(订单表中,由下单时间,发货时间,收货时间,售后截止时间组成的事务表)
维度表的分类
高基数维度表:指的表中的数据量是比较庞大的,而且数据也在发生变化,一般是用户资料表、商品资料表类似的资料表。数据量可能是千万级或者上亿级别。
例如:商品表,用户表
低基数维度表:指的表中的数据量不是特别多,一般在几十条到几千条左右,而且数据相对比较稳定,基本不会发生更改,一般是配置表,比如枚举值对应的中文含义,或者日期维表、地理维表等。数据量可能是个位数或者几千条几万条
例如:日期表,配置表,区域表
维度建模的三种模型
第一种:星型模型
特点:只有一个事实表,那么也就意味着只有一个分析的主题,在事实表的周围围绕了多个维度表,维度表与维度表之间没有任何的依赖。
反映数仓发展初期最容易产生模型
第二种:雪花模型
特点:只有一个事实表,那么也就意味着只有一个分析的主题,在事实表的周围围绕了多个维度表,维度表可以接着关联其他的维度表
反映数仓发展出现了畸形产生模型,这种模型一旦大量出现,对后期维护是非常繁琐,同时随着依赖层次越多,SQL分析的难度也会加大
此种模型在实际生产中,建议尽量减少这种模型产生
第三种:星座模型
特点:有多个事实表,那么也就意味着有了多个分析的主题,在事实表的周围围绕了多个维度表,多个事实表在条件符合的情况下,可以共享维度表
反映数仓发展中后期最容易产生模型















 2248
2248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









