






目录
前言:
随着数据量的不断增加,数据量过大会造成性能瓶颈,尤其是 线上服务 中,大量数据的实时处理和查询会直接影响到 响应时间 和 系统稳定性。当数据量达到一定规模时,数据库,网络带宽,以及线上资源都可能成为系统的瓶颈,从而导致响应延迟,处理效率低下。因此,如何高效地管理和优化大数据量,确保接口响应时间和高可用性,可以有效的提升系统性能和用户体验的关键。
1.索引
1.1 MySQL索引
索引是在存储引擎层实现的,而不是在服务层实现的,所以不同的存储引擎有不同的索引类型和实现(InnoDB/myisam,mysql 5.5之后/之前)
Innodb 默认使用聚簇索引(主键索引):数据表中的行数据会按照主键的顺序进行物理存储
1.2 B+Tree(具有唯一列的普通索引)
大多数情况下采用B+ Tree 来进行,因为不需要进行全表扫描,只需要对树进行搜索即可,所以查找速度快很多。
B+Tree有序,所以除了用于查找,还可以用于排序和分组。
可以指定多个列作为索引列,多个索引列共同组成键(联合索引)。如果不是按照索引列的顺序进行查找,则无法使用索引。
InnoDB的B+Tree分为主索引和辅助索引。主索引的叶子节点data域记录着完整的数据记录,这种索引方式被称为聚簇索引。因为无法把数据行存放在两个不同的地方,所以一张表只能有一个聚簇索引。
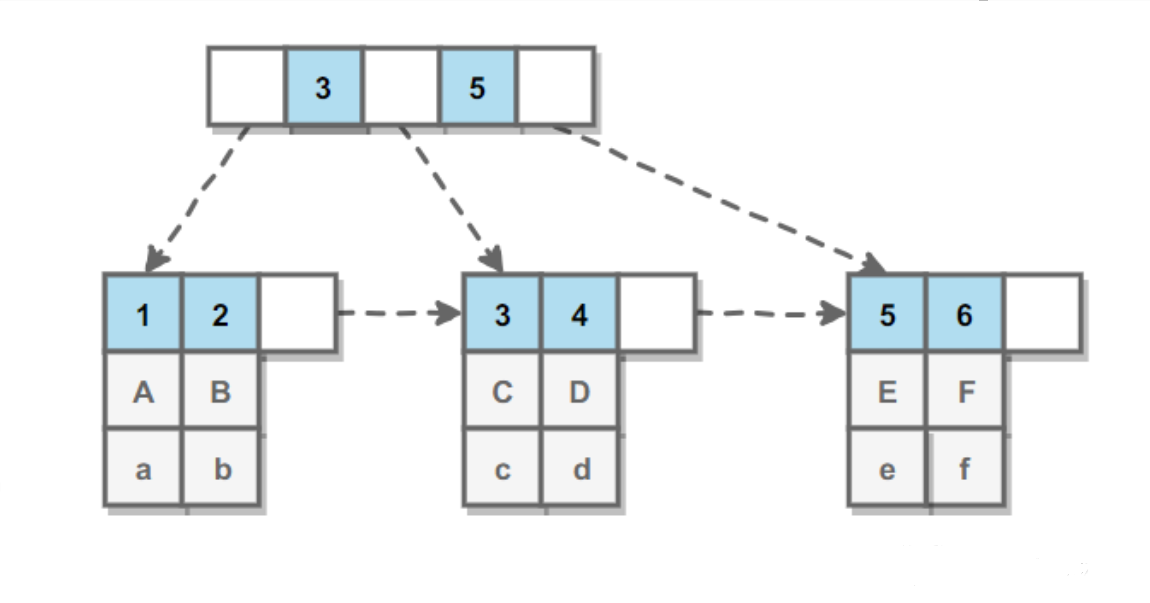
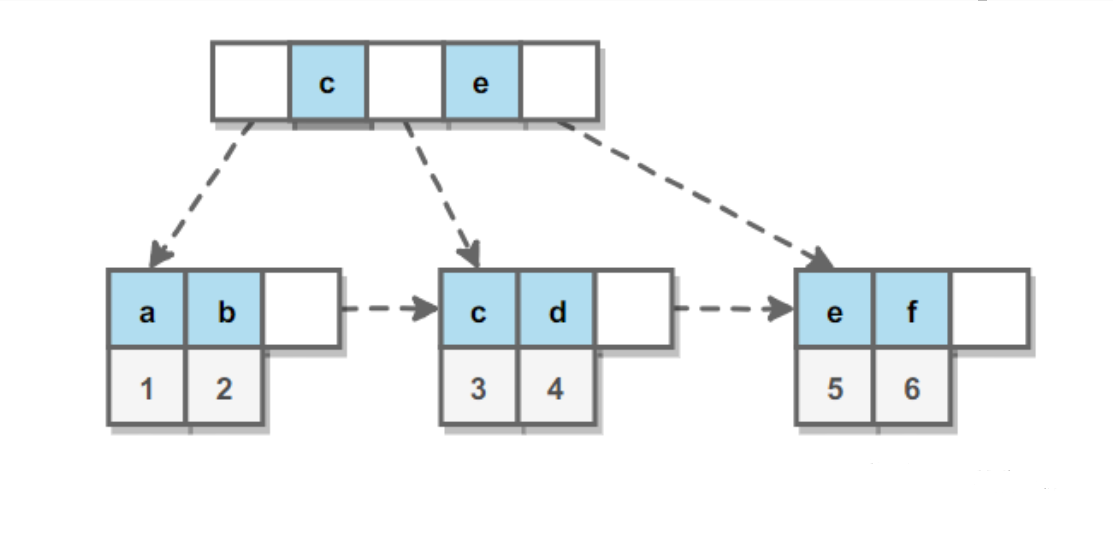
辅助索引的叶子节点的 data 域记录着主键的值,因此在使用辅助索引进行查找时,需要先找到主键值,然后再到主索引中进行查找
1.3 哈希索引
哈希索引能以 O(1) 时间进行查找,但是失去了有序性:
无法用于排序与分组
只支持精确查找,无法用于部分查找和范围查找
InnoDB ‘自适应哈希索引’,当某个索引值被使用的非常频繁时,会在B+Tree索引上在创建一个哈希索引,这样B+Tree索引具有哈希索引的一些优点,比如快速的哈希查找。
1.4 全文索引
MyISAM存储引擎支持全文索引,用于查找文本中的关键字,而不是直接比较是否相等
查找条件使用 MATCH AGAINST,而不是普通的 WHERE
全文索引使用倒排索引实现,它记录着关键词到其所在文档的映射
InnoDB 存储引擎在 5.6.4中也开始支持全文索引
1.5 空间数据索引
MyISAM 存储引擎支持空间数据索引(R-Tree),可以用于地理数据存储。空间数据索引会从所有维度来索引数据,可以有效地使用任意维度来进行组合查询。
必须使用 GIS 相关的函数来维护数据。
2.索引优化
1. 范围查询:idx (a, b, c) ,要使用 betweend 或者 > <,该字段需要放在最后(c)。因为当所有中有范围查询,之后的索引就无法使用了。
2. 索引列的顺序:选则性最强的索引列应该放在最前面 选择比 = 索引列的唯一值数目 / 总行数。选则性越高,每个记录的区分度越高,查询效率也越高。
3. 前缀索引:适用于字符串,比如前10个字符,只索引开始的部分字符
4. 聚合索引:索引包含所有需要查询的字段的值。
优点:
适用于读取频繁,但写入较少的
避免回表(回表指当查询条件使用了索引,但查询的字段不完全包含在索引中的情况下,数据库必须先通过索引获取主键,再访问数据表获取其他字段。回表的过程会消耗额外的时间和I/O)
缺点:索引较大,维护成本高,适用于读多写少的场景。
3.分库分表
分库分表分为物理分区和逻辑分区
| 区别 | 物理分区 | 逻辑分区 |
|---|---|---|
| 定义 | 数据在物理层面上的分割和存储 | 数据在应用层或逻辑层面上的划分和组织 |
| 关注点 | 数据的实际存储位置和分布 | 数据的组织和访问方式 |
| 实现方式 | 数据按照某些规则分散存储到不同的数据库、表中 | 数据以业务逻辑为基础进行虚拟化分区 |
| 透明性 | 需要应用程序和数据库管理系统了解分区规则 | 应用程序通常不需要关心分区细节 |
| 扩展性 | 物理分区通过增加硬件来实现扩展 | 逻辑分区通过修改逻辑层来实现扩展 |
| 路由机制 | 物理路由:根据规则定位数据的物理存储位置 | 逻辑路由:根据业务规则定位数据逻辑位置 |
| 举例 | 按ID范围分表,按地区分库 | 订单表、用户表按时间、区域、ID等分区 |
3.1分库不分表
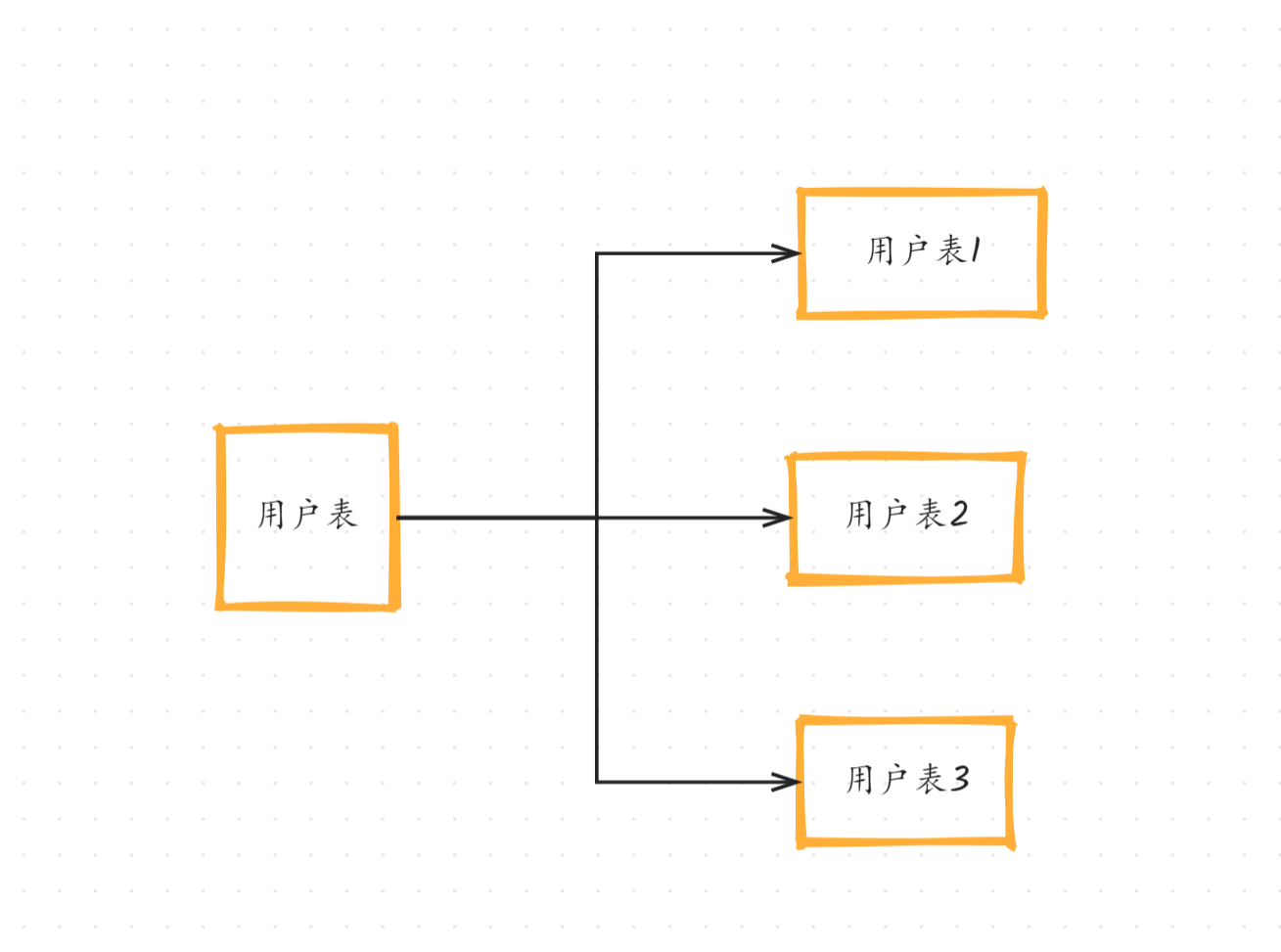
3.2分表不分库
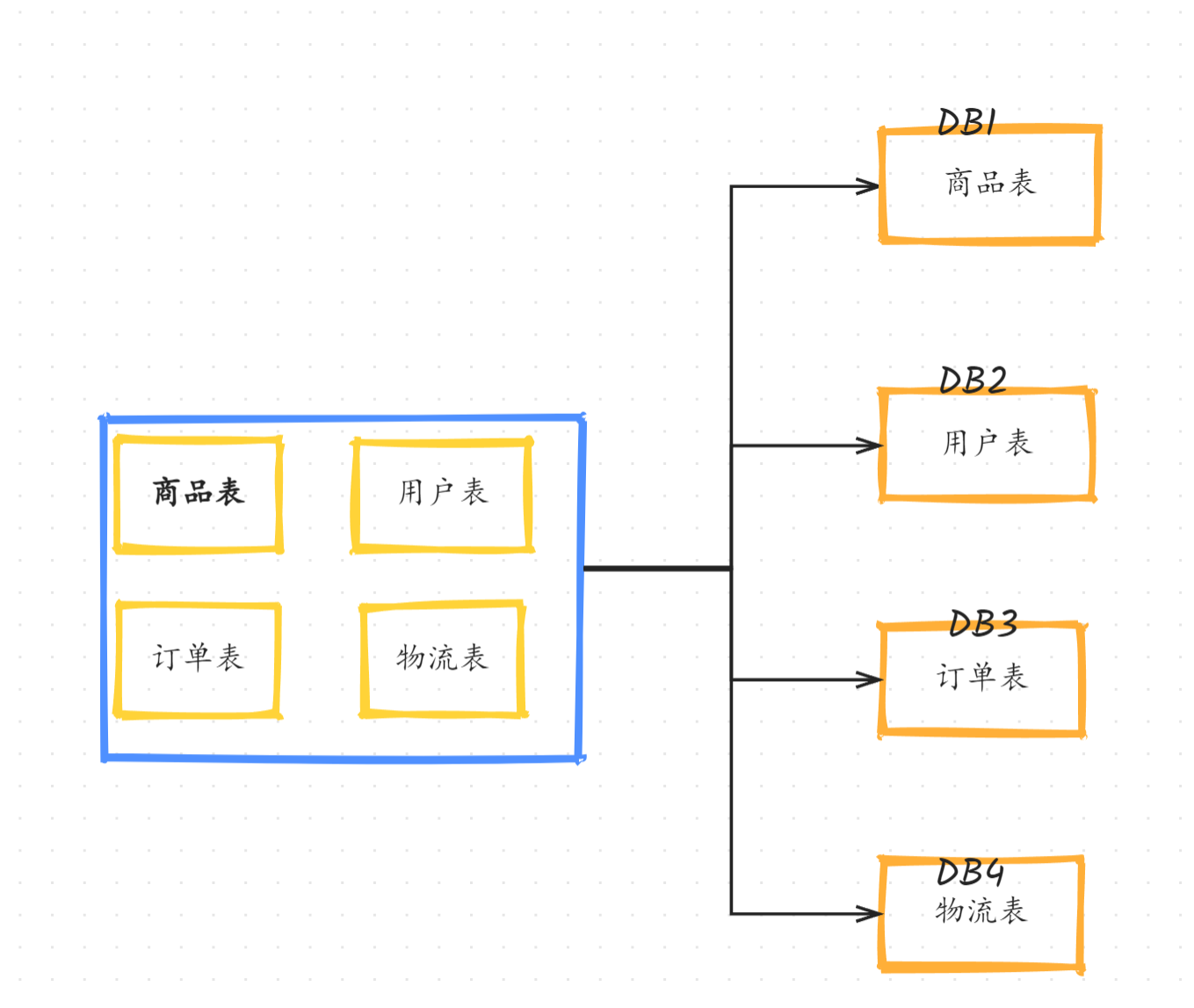
3.3 分库又分表
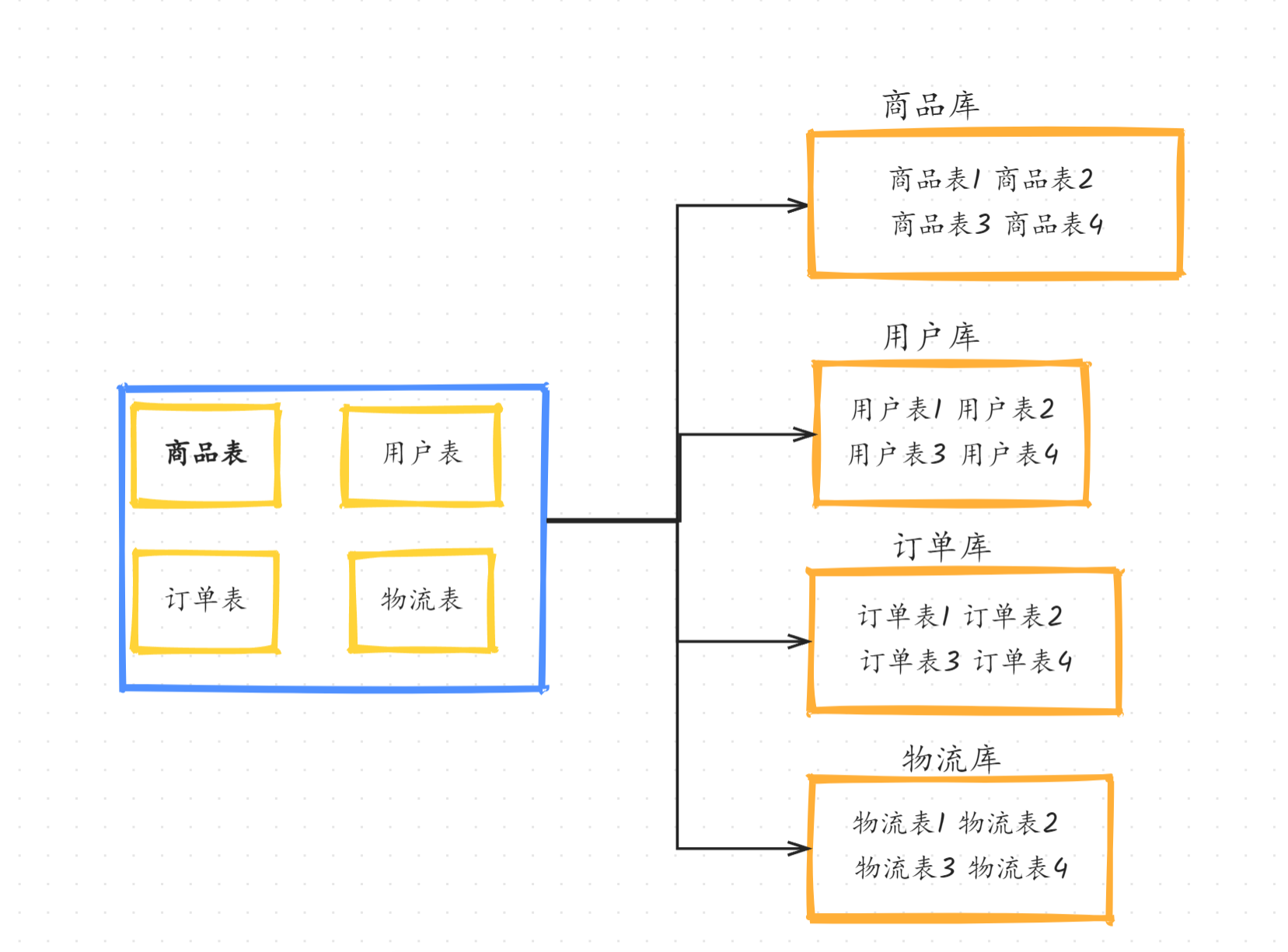
3.4 逻辑分区
样例中fq为column,根据该字段进行分区
样例
ALTER TABLE `test_sales`
PARTITION BY RANGE (`fq`) (
PARTITION p202101 VALUES LESS THAN (202101),
PARTITION p202102 VALUES LESS THAN (202102),
PARTITION p202103 VALUES LESS THAN (202103)
);
动态添加
ALTER TABLE `test_sales`
ADD PARTITION (
PARTITION p202108 VALUES LESS THAN (202108)
);
删除分区
ALTER TABLE `test_sales`
DROP PARTITION p202101;
4.NoSQL
NoSQL 比 SQL 快的原因主要归结于以下几点:
-
简化的数据模型:避免了复杂的表连接和数据规范化。
-
灵活的数据模式:无需预定义模式或表结构。
-
水平扩展:通过分布式架构和分片提高性能和可伸缩性。
-
优化特定场景的查询:如缓存、全文搜索、列式存储等。
-
最终一致性:牺牲一致性以获得更高的吞吐量和可用性。
-
低延迟、高并发:内存存储和优化的查询方式。
5. 数据处理与计算优化
5.1 数据压缩
对于大量存储的数据,可以进行压缩,减少存储空间的消耗,如聚合后创建副本,定时任务根据数据推送时间定期维护副本数据。
5.2 数据预处理与去重
1. 去重:对于重复的数据(例如重复记录、冗余数据),需要提前进行去重操作,减少无效数据的存储和计算。
2. 数据清洗:通过去除噪声数据、填补缺失值、标准化格式等步骤清洗数据,提高后续计算效率。
补充:
1. 当拥有足够权限时,可以考虑根据需求,自行聚合出自建表副本,聚合后的数据可以有效减少数据量,优化响应时间
2. 如果你的数据量非常大,网络也可能会成为你的瓶颈,需要考虑到带宽对执行时间的影响


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









