






p120
1.创建DataFrame


步骤顺序:导包 >定义一个样例类 > 读取文件创建RDD > RDD转成DataFrame
2.查看DataFrame数据
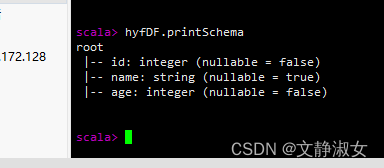
(1)printSchema:输出数据模式
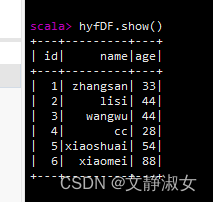
(2)show():查看数据
hyfDF.show()显示前20条记录
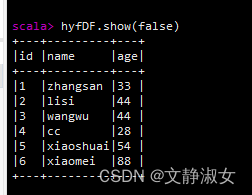
hyfDF.show(false):显示所有字符
(3)first()/head()take()/takeAsList():获取若干条记录
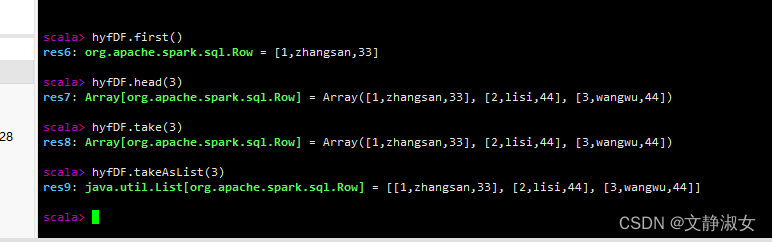
first()获取第一条记录
head(x)获取前x条记录
take(x)获取前x条记录
takeAsList(x)获取前x条记录并以列表的形式展现
(4)collect()/collectAsList()获取所有数据

collect()获取所有数据返回一个数组
collectAsList()获取所有数据返回一个列表
3.查询DataFrame查询操作
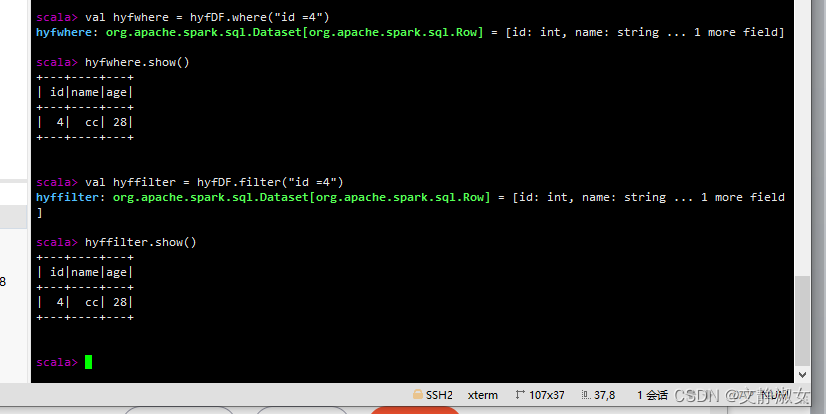
(1) where()/filter()方法
条件查询
(2)select()/selectExpr()/col()/apply()方法
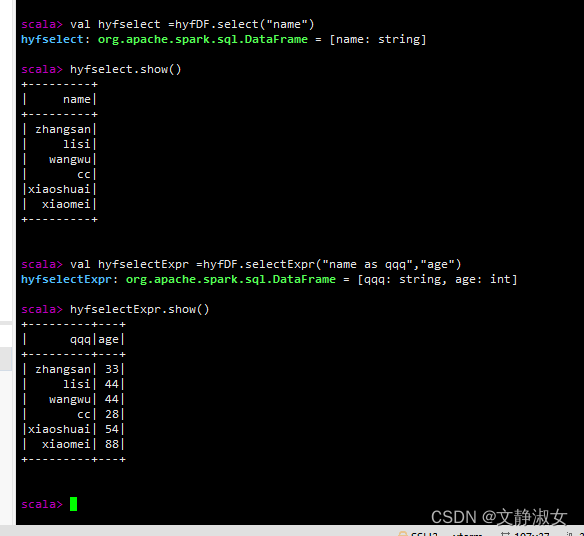
select()获取指定字段值
selectExpr():对指定字段进行特殊处理
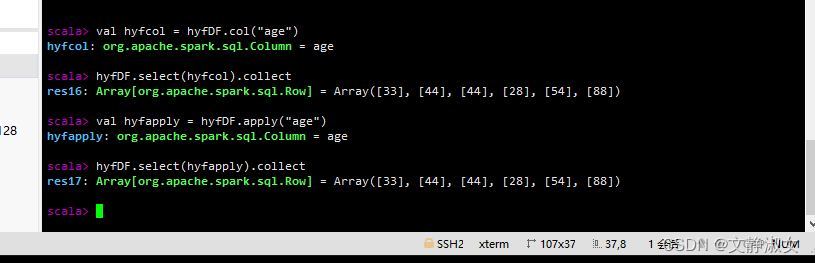
col()获取指定字段值
apply()获取指定字段值
第二章
1.定义与使用常量,变量
(1)常量
程序运行过程中值不会发生变化的量
通过val定义
(2)变量
程序运行过程中值可能发生变化的量
通过var定义
2.使用运算符
3.定义与使用数组
方式1:var hyf: Array[String] = new ArrayString
方式2:var hyf:Array[String] = Array(元素1,元素2,…)
var hyf:Array[String] = Array(“baidu”,“google”,“bing”)
hyf.length
hyf.head
hyf.tail
hyf.isEmpty
hyf.contains(“baidu”)
定义数组hyf
查看长度
查看第一个元素
查看除第一个元素外其他元素
查看是否为空
查看是否包含元素"baidu"
4.定义与使用函数
def hyf(a:Int,b:Int):Int={a+b)
hyf(2,3)
定义两个整数相加的函数
调用函数计算2+3
(1)匿名函数
定义函数时不给出函数名的函数
val hyf=(x:Int,y:Int)=>x+y
hyf(1,2)
定义两个整数相加的匿名函数
调用函数计算1+2
(2)高级函数–函数作为参数
def hyf(f:(Int,Int)=>Int,a:Int,b:Int)=f(a,b)
hyf((a:Int,b:Int)=>a+b,1,2)
(3)高级函数–函数作为返回值
def hyf(length:Double)=(height:Double)=>(length+height)*2
val func=gsj(4)
println(func(5))
(4)函数柯里化
def hyf(a:Int)(b:Int):Int=a+b
hyf(1)(2)
5.if判断
if(布尔表达式){若布尔表达式为true,则执行该语句块}
6.for循环
for(变量<- 集合) {循环语句}
7.定义与使用列表
列表是不可变的
val hyf:List[数据类型]=List(元素1,元素2,…)
hyf.head
hyf.init
hyf.last
hyf.tail
hyf.take(2)
定义集合
获取列表第一个元素
返回所有元素除了最后一个
获取列表的最后一个元素
返回所有元素除了第一个
获取列表前n个元素
val hyf1:List[Int]=List(1,2,3)
val hyf2:List[Int]=List(4,5,6)
hyf1:::hyf2
hyf1.:::(hyf2)
List.concat(hyf1,hyf2)
合并两个列表
val hyf:List[Int]=List(1,2,3)
hyf.contains(3)
判断列表中是否包含某个元素
8.定义与使用集合
集合是没有重复对象的,所有元素都是唯一的
val hyf:Set[Int]=Set(1,2,3,4,5)
hyf.head
hyf.init
hyf.last
hyf.tail
hyf.take(2)
定义集合
获取集合第一个元素
返回所有元素除了最后一个
获取集合的最后一个元素
返回所有元素除了第一个
获取集合前n个元素
9.定义与使用映射
映射是一种可迭代的键值对结构
val hyf:Map[String,Int]=Map(“John”->21,“Betty”->20,“Mike”->22)
hyf.head
hyf.init
hyf.last
hyf.tail
hyf.take(n)
hyf.isEmpty
hyf.keys
hyf.values
定义映射
获取映射第一个元素
返回所有元素除了最后一个
获取映射的最后一个元素
返回所有元素除了第一个
获取映射前n个元素
判断映射的数据是否为空
获取所有的键
获取所有的值
10.定义与使用元组
元组可以包含不同类型的元素
Scala支持的元组最大长度为22
val hyf=(1,3.14,“a”)
val hyf=new Tuple3(1,3.14,“a”)
hyf._1
hyf._3
定义元组的第一种方法
定义元组的第二种方法
访问元组第一个元素
访问元组第三个元素
11.使用函数组合器
(1)map()方法
(2)foreaach()方法
(3)filter()方法
(4)flatten()方法
(5)flatMap()方法
(6)groupBy()方法
第三章
1.从内存中读取数据创建RDD
(1)parallelize()
val hyf = Array(1,2,3,4,5)
val hyfrdd=sc.parallelize(hyf)
hyfrdd.partitions.size
val hyfrdd=sc.parallelize(hyf,4)
hyfrdd.partitions.size
定义一个数组
创建RDD
查看RDD默认分区个数
设置分区个数为4后创建RDD
再次查看RDD分区个数
(2)makeRDD()
val seq = Seq((1,Seq(“iteblog.com”,“sparkhost1.com”)),
((3,Seq(“iteblog.com”,“sparkhost2.com”)),
((2,Seq(“iteblog.com”,“sparkhost3.com”)))
val hyf = sc.makeRDD(seq)
hyf.collect
hyf.partitioner
hyf.partitions.size
hyf.preferredLocations(gsj.partitions(0))
hyf.preferredLocations(gsj.partitions(1))
hyf.preferredLocations(gsj.partitions(2))
定义一个序列seq
创建RDD
查看RDD的值
查看分区个数
根据位置信息查看每一个分区的值
2.从外部存储系统中读取数据创建RDD
(1)通过HDFS文件创建RDD
val hyf = sc.textFile(“/user/root/test.txt”)
(2)通过Linux本地文件创建RDD
val hyf = sc.textFile(“file:///opt/text.txt”)
3.使用map()方法转换数据
val hyf = sc.parallelize(List(1,3,45,3,76))
val sq_gsj=hyf.map(x => x*x)
求平方值
4.使用sortBy()方法进行排序
val hyf =sc.parallelize(List((1,3),(45,3),(7,6))
val sort_hyf = data.sortBy(x => x._2,false,1)
5.使用collect()方法查询数据
sq_hyf.collect
sort_hyf.collect
6.使用flatMap()方法转换数据
val hyf =sc.parallelize(List(“How are you”,“I am fine”,“What about you”))
hyf.collect
hyf.map(x => x.split(" “)).collect
hyf.flatMap(x => s.split(” ")).collect
7.使用take()方法查询某几个值
val hyf = sc.parallelize(1 to 10)
hyf.take(5)
8.使用union()方法合并多个RDD
val hyf1 = sc.parallelize(List((‘a’,1),(‘b’,2),(‘c’,3)))
val hyf2 = sc.parallelize(List((‘a’,1),(‘d’,4),(‘e’,5)))
hyf1.union(gsj2).collect
9.使用filter()方法进行过滤
val hyf1 = sc.parallelize(List((‘a’,1),(‘b’,2),(‘c’,3)))
hyf1.filter(_._2 >1).collect
hyf1.filter(x => x._2 >1).collect
10.使用distinct()方法进行去重
val hyf = sc.makeRDD(List(‘a’,1),(‘a’,1),(‘b’,1),(‘c’,1)))
hyf.distinct().collect
11.使用简单的集合操作
(1)intersection()方法
求出两个RDD的共同元素(求交集)
val hyf1 = sc.parallelize(List((‘a’,1),(‘a’,1),(‘b’,1),(‘c’,1)))
val hyf2 = sc.parallelize(List((‘a’,1),(‘b’,1),(‘d’,1)))
hyf1.intersection(hyf2).collect
(2)subtract()方法
求补集
val hyf1 = sc.parallelize(List((‘a’,1),(‘b’,1),(‘c’,1)))
val hyf2 = sc.parallelize(List((‘d’,1),(‘e’,1),(‘c’,1)))
hyf1.subtract(hyf2).collect
hyf2.subtract(hyf1).collect
(3)cartesian()方法
求笛卡儿积
val hyf1 = sc.makeRDD(List(1,3,5,3))
val hyf2 = sc.makeRDD(List(2,4,5,1))
hyf1.cartesian(hyf2).collect
12.创建键值对RDD
val hyf =sc.parallelize(List(“this is a test”,“how are you”,“I am fine”,“can you tell me”))
val hyfs = gsj.map(x => (x.split(" ")(0),x))
hyfs.collect
13.使用键值对RDD的keys和values方法
val key = hyfs.keys
key.collect
val value = hyfs.values
value.collect
14.使用键值对RDD的reduceByKey()方法
val hyf = sc.parallelize(List((‘a’,1),(‘a’,2),(‘b’,1),(‘c’,1),(‘c’,1)))
val re_hyf = gsj.reduceByKey((a,b) => a+b)
re_hyf.collect
15.使用键值对RDD的groupByKey()方法
val g_hyf = hyf,groupByKey()
g_hyf.collect
g_hyf.map(x => (x._1,x._2.size)).collect
16.使用join()方法连接两个RDD
(1)join()方法
val hyf1 = sc.parallelize(List((‘a’,1),(‘b’,2),(‘c’,3)))
val hyf2 = sc.parallelize(List((‘a’,1),(‘d’,4),(‘e’,5)))
val j_hyf = gsj1.join(gsj2)
j_hyf.collect
(2)rightOuterJoin()方法
右外连接
val right_hyf = gsj1.rightOuterJoin(hyf2)
right_hyf.collect
(3)leftOuterJoin()方法
左外连接
val left_hyf = hyf1.leftOuterJoin(hyf2)
left_hyf.collect
(4)fullOuterJoin()方法
全外连接
val full_hyf = hyf1.fullOuterJoin(hyf2)
full_hyf.collect
17.使用zip()方法组合两个RDD
val hyf1 = sc.makeRDD(1 to 5 ,2)
val hyf2 = sc.makeRDD(seq(“A”,“B”,“C”,“D”,“E”),2)
hyf1.zip(gsj2).collect
hyf2.zip(gsj1).collect















 8660
8660

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









