






什么是Kafka?
Kafka的增长很快。财富500强企业中超过三分之一使用卡夫卡。这些公司包括十大旅游公司,十大银行中的七家,十大保险公司中的八家,十大电信公司中的九家,等等。LinkedIn,微软(Microsoft)和Netflix每天用Kafka处理一兆(1,000,000,000,000)的信息。Kafka用于实时数据流,收集大数据,或做实时分析(或两者兼而有之)。Kafka与内存中的微服务一起使用以提供耐用性,并且可以用于向CEP(复杂事件流式传输系统)和IoT / IFTTT式自动化系统提供事件。
##为什么选择Kafka?
Kafka通常用于实时流式数据体系结构以提供实时分析。由于Kafka是一个快速,可扩展,耐用和容错的发布、订阅消息传递系统,Kafka被用于JMS,RabbitMQ和AMQP可能因为数量和响应速度而不被考虑的情况。Kafka具有更高的吞吐量,可靠性和复制特性,使其适用于跟踪服务呼叫(跟踪每个呼叫)或跟踪传统MOM可能不被考虑的物联网传感器数据。
Kafka可以与Flume / Flafka,Spark Streaming,Storm,HBase,Flink和Spark一起工作,以实时接收,分析和处理流数据。Kafka是用于提供Hadoop的数据流。 Kafka代理支持在Hadoop或Spark中进行低延迟后续分析的大量消息流。此外,kalfka(一个子项目)可用于实时分析。
Kafka用例
简而言之,卡夫卡用于流处理,网站活动跟踪,度量收集和监控,日志聚合,实时分析,CEP,将数据导入到Spark中,将数据导入到Hadoop,CQRS,重播消息,错误恢复,并保证内存计算(微服务)的分布式提交日志。
谁使用Kafka?
许多处理大量数据的大公司使用Kafka。 LinkedIn起源于它,用它来跟踪活动数据和运营指标。Twitter使用它作为Storm的一部分来提供流处理基础设施。Square使用Kafka作为公共汽车,将所有系统事件转移到各种Square数据中心(日志,自定义事件,度量标准等),输出到Splunk,Graphite(仪表板)以及Esper-like / CEP警报系统。Spotify,Uber,Tumbler,Goldman Sachs,PayPal,Box,Cisco,CloudFlare和Netflix等公司也使用这种方法。
为什么Kafka如此受欢迎?
Kafka的操作简单。建立和使用Kafka后,很容易明白Kafka是如何工作的。 然而,Kafka很受欢迎的主要原因是它的出色表现。它是稳定的,提供可靠的持久性,具有灵活的发布 - 订阅/队列,可与N个消费者群体进行良好扩展,具有强大的复制功能,为制作者提供可调整的一致性保证,并在碎片级别提供保留排序(即Kafka 主题分区)。此外,Kafka可以很好地处理有数据流处理的系统,并使这些系统能够聚合,转换并加载到其他商店。 但是,如果Kafka速度缓慢,那么这些特点都不重要。 Kafka最受欢迎的原因是Kafka的出色表现。
为什么Kafka如此快?
Kafka非常依赖OS内核来快速移动数据。它依靠零拷贝的原则。Kafka使您能够将数据记录批量分块。这些批次的数据可以从生产者到文件系统(Kafka主题日志)到消费者端到端地看到。批处理允许更高效的数据压缩并减少I / O延迟。Kafka写入不可变的提交日志到磁盘顺序,从而避免随机磁盘访问和慢磁盘寻找。Kafka通过分片提供了横向扩展。它将一个主题日志分成数百个(可能是数千个)分区到数千个服务器。这个分解允许Kafka处理巨大的负载。
Kafka流媒体体系结构
Kafka最常用于将数据实时传输到其他系统。 Kafka是一个中间层,可以将您的实时数据管道解耦。Kafka
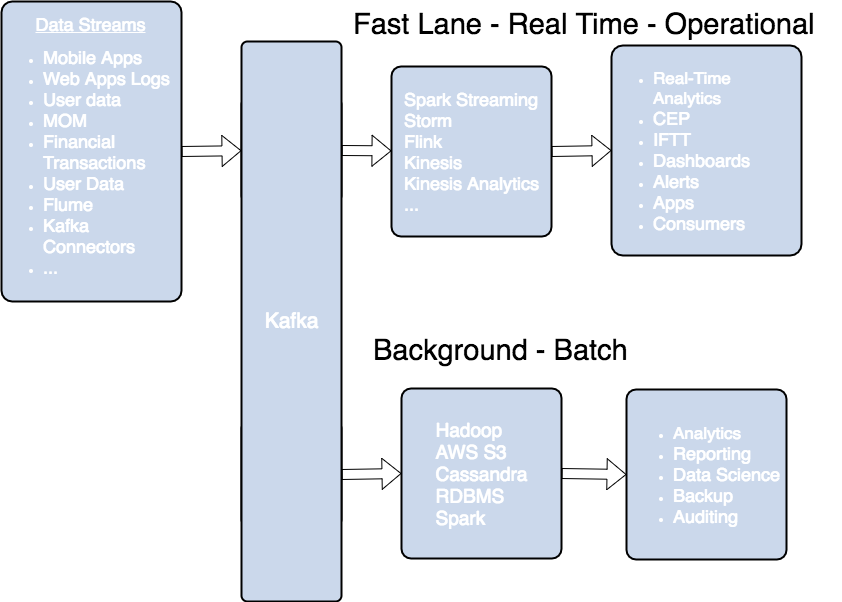
*卡夫卡流式体系结构图*复制
现在让我们真正回答这个大问题。
什么是Kafka?
Kafka是一个分布式流媒体平台,用于发布和订阅记录流。Kafka用于容错存储。 Kafka将主题日志分区复制到多个服务器。Kafka旨在让您的应用程序处理记录。Kafka速度很快,通过批处理和压缩记录来高效地使用IO。Kafka用于解耦数据流。Kafka用于将数据流式传输到数据湖,应用程序和实时流分析系统。
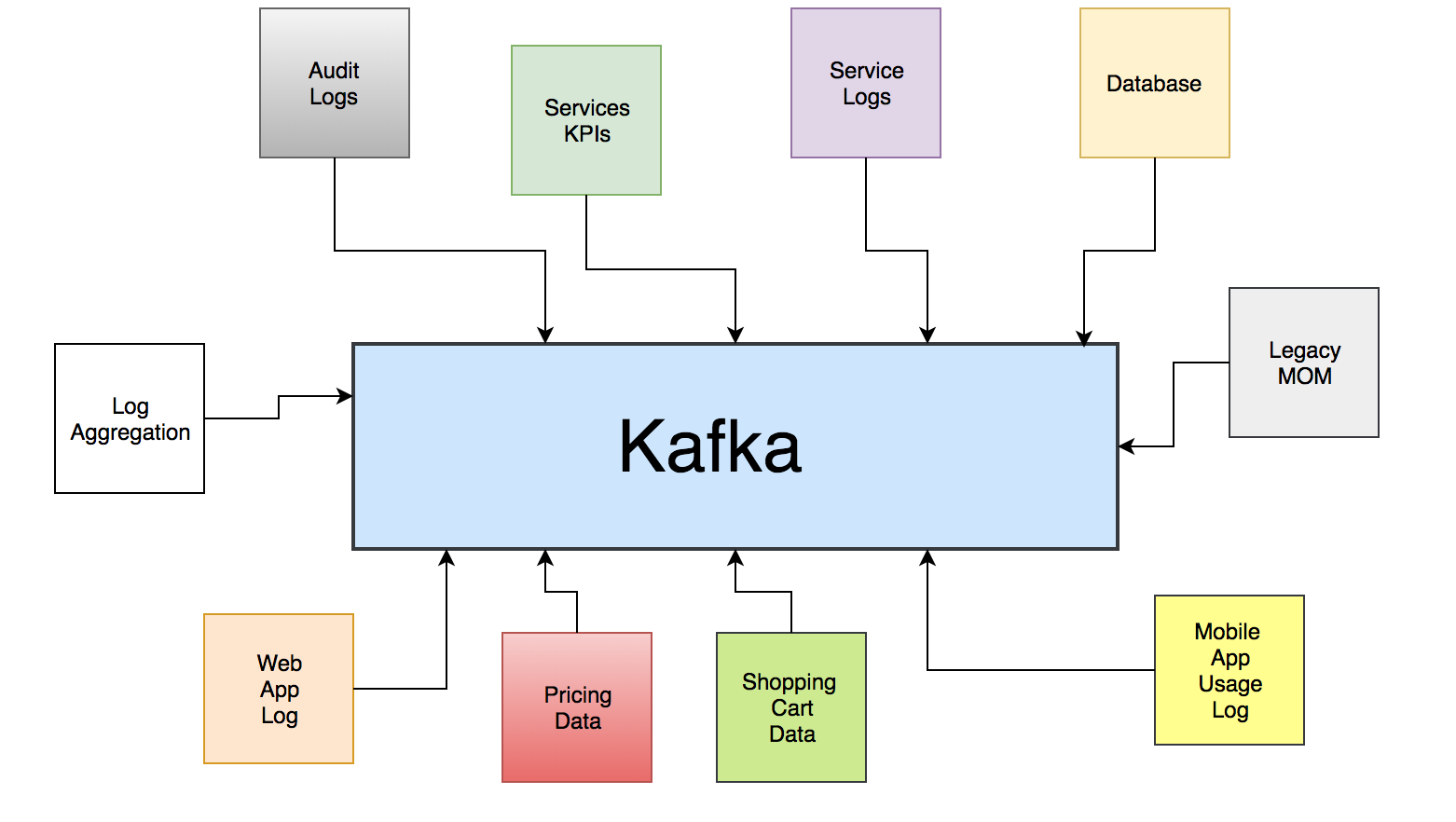
*Kafka解耦数据流*复制
Kafka是多面手
来自客户端和服务器的Kafka通信使用基于TCP的有线协议进行版本化和记录。Kafka承诺保持与老客户的向后兼容性,支持多种语言。有C#,Java,C,Python,Ruby等多种语言的客户端。Kafka生态系统还提供了REST代理,可以通过HTTP和JSON轻松集成,从而使集成变得更加简单。Avro和架构注册表允许客户以多种编程语言制作和读取复杂的记录,并允许记录的演变。Kafka是真正的多面手。
Kafka很有用
Kafka允许您构建实时流数据管道。
您可以使用Kafka来帮助收集指标/关键绩效指标,汇总来自多个来源的统计信息,并实施事件采购。您可以将其与微服务(内存)和参与者系统一起使用,以实现内存中服务(分布式系统的外部提交日志)。
您可以使用Kafka在节点之间复制数据,为节点重新同步以及恢复状态。虽然Kafka主要用于实时数据分析和流处理,但您也可以将其用于日志聚合,消息传递,点击流跟踪,审计跟踪等等。
在这个数据科学和分析是一个大问题的世界里,捕获数据到数据湖和实时分析系统也是一件大事。而且由于Kafka可以承受这种剧烈的使用情况,Kafka是一个大成就。
Kafka有可扩展的消息存储
Kafka是一个很好的记录/信息存储系统。Kafka就像提交日志存储和复制的高速文件系统一样。这些特点使Kafka适用于各种应用场合。写入Kafka主题的记录会持久保存到磁盘并复制到其他服务器以实现容错。由于现代硬盘速度很快,而且相当大,所以这种硬盘非常适合,非常有用。Kafka生产者可以等待确认,直到该消息复制,信息会一直显示为制片人不完整。Kafka磁盘结构可以很好地扩展。现代磁盘驱动器在以大批量流式写入时具有非常高的吞吐量。此外,Kafka客户和消费者可以控制读取位置(偏移量),这允许在重要错误(即修复错误和重放)时重播日志等用例。而且,由于每个消费者群体都会跟踪偏移量,所以我们在这篇Kafka架构文章中提到,消费者可以非常灵活(即重放日志)。
Kafka有记录保留
Kafka集群保留所有公布的记录。如果您没有设置限制,它将保留记录,直到磁盘空间不足。例如,您可以设置三天或两周或一个月的保留策略。主题日志中的记录可供消耗,直到被时间,大小或压缩丢弃为止。消费速度不受Kafka的大小影响,总是写在主题日志的末尾。















 2297
2297











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











