






目录
1. 一维数组的创建和初始化
1.1 数组的创建
数组是一组相同类型元素的集合。
数组的创建方式:
type_t arr_name [const_n];
//type_t 是指数组的元素类型
//const_n 是一个常量表达式,用来指定数组的大小

注:数组创建,在C99标准之前, [ ] 中要给一个常量才可以,不能使用变量。在C99标准支持了变长数组的概念。
1.2 数组的初始化
数组的初始化是指,在创建数组的同时给数组的内容一些合理初始值(初始化)。

数组在创建的时候如果想不指定数组的确定的大小就得初始化。数组的元素个数根据初始化的内容来确定。
1.3 一维数组的使用
对于数组的使用我们之前介绍了一个操作符: [ ] ,下标引用操作符。专门用来数组访问的操作符。




可以看出:
1,数组是使用下标来访问的,下标从0开始。
2,数组的大小可以通过计算得到。
1.4 一维数组在内存中的存储

上图每个地址都相差4,因为这个数组是int类型,一个int类型占4个字节。
可以得出结论,随着数组下标的增长,元素的地址,也在有规律的递增,数组在内存中是连续存放的。
2. 二维数组的创建和初始化
2.1 二维数组的创建
type_t arr_name [const_n][const_n];
//type_t 是指数组的元素类型
//const_n 是一个常量表达式,用来指定数组的大小

2.2 二维数组的初始化

二维数组即使初始化了,行是可以省略的,但是列是不能省略的。
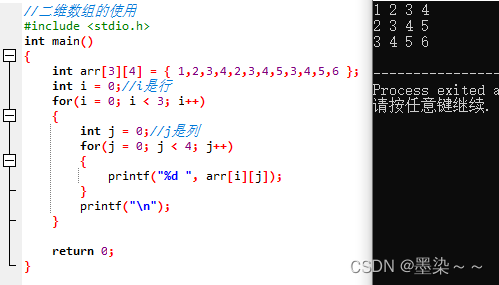
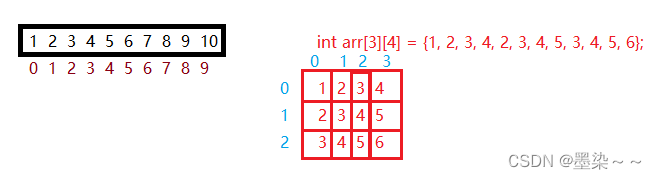
2.3 二维数组的使用
二维数组的使用也是通过下标的方式。不管是行还是列,下标都是从0开始。


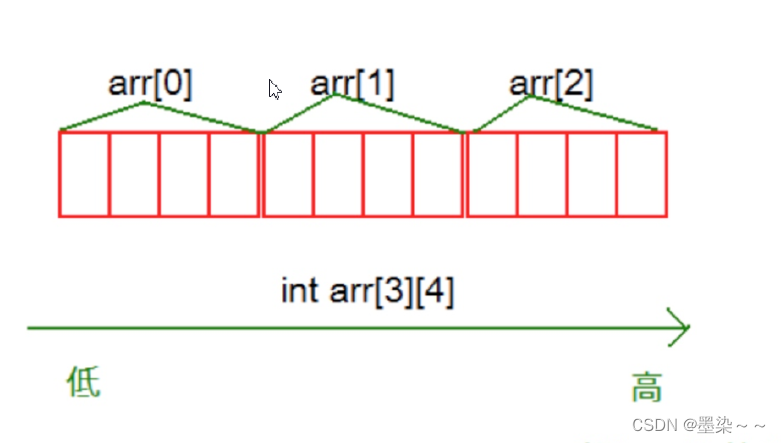
2.4 二维数组在内存中的存储
像一维数组一样,这里我们尝试打印二维数组的每个元素的地址。
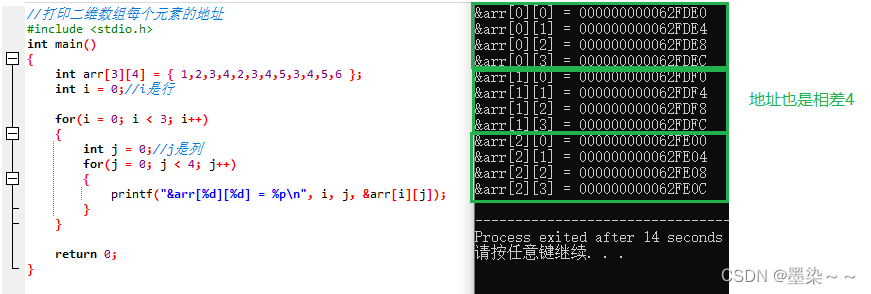
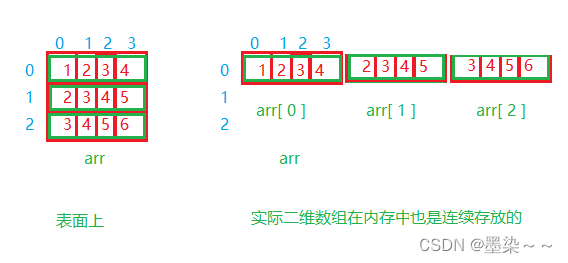
通过结果我们可以分析到,其实二维数组在内存中也是连续存储的。
3. 数组越界
数组的下标是有范围限制的。
数组的下规定是从0开始的,如果数组有n个元素,最后一个元素的下标就是n-1。
所以数组的下标如果小于0,或者大于n-1,就是数组越界访问了,超出了数组合法空间的访问。
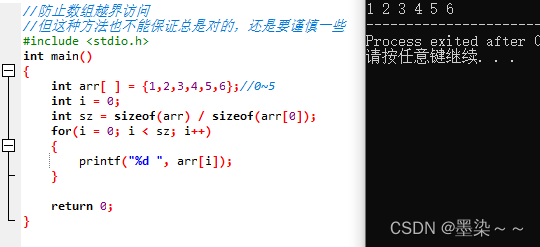
C语言本身是不做数组下标的越界检查,编译器也不一定报错,但是编译器不报错,并不意味着程序就是正确的,所以我们写代码时,最好自己做越界的检查。


下面的方法可以防止数组越界访问,但这种方法也不能保证总是对的,还是要谨慎一些,确保元素下标的范围是正确的。
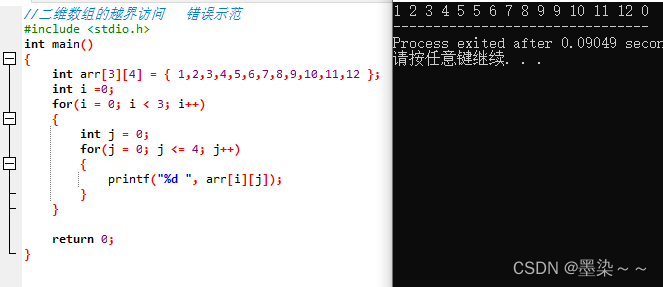
一维数组存在越界,二维数组的行和列也可能存在越界。
4. 数组作为函数参数
往往我们在写代码的时候,会将数组作为参数传给函数,比如:我要实现一个冒泡排序函数,将一个整形数组排序。
4.1 冒泡排序函数的错误设计
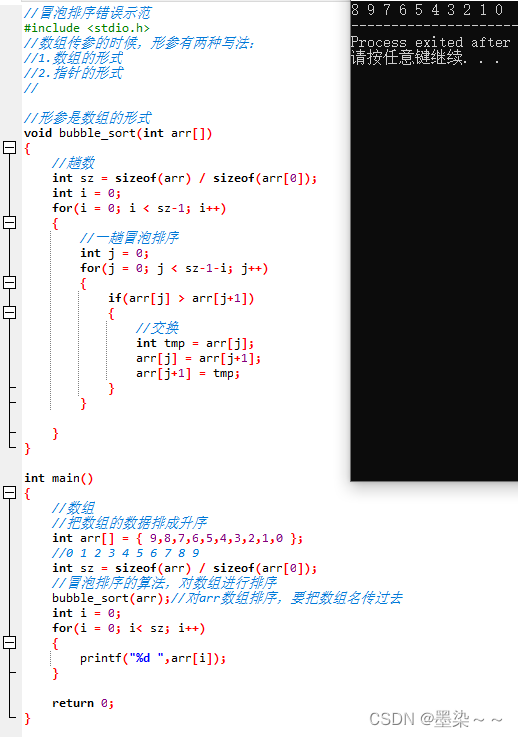
方法1,出问题,那我们找一下问题,调试之后可以看到bubble_sort 函数内部的sz ,是1。
难道数组作为函数参数的时候,不是把整个数组的传递过去?
我们来分析一下:
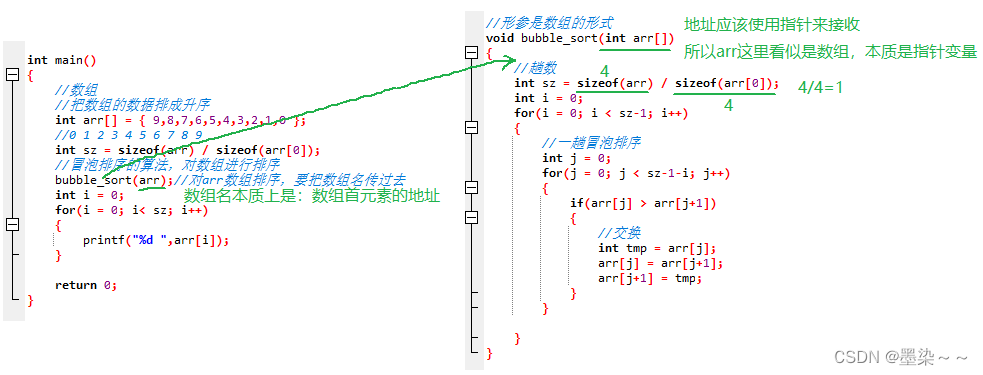
以上是一个错误的用法,很多初学者会犯这样的错,很经典的一个错误。
4.2 数组名是什么?
4.2.1 一维数组的数组名
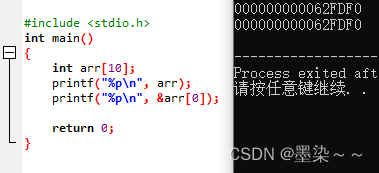
数组名是数组首元素的地址。(有两个例外)
如果数组名是首元素地址,那么:
为什么下面代码输出的结果是:40?

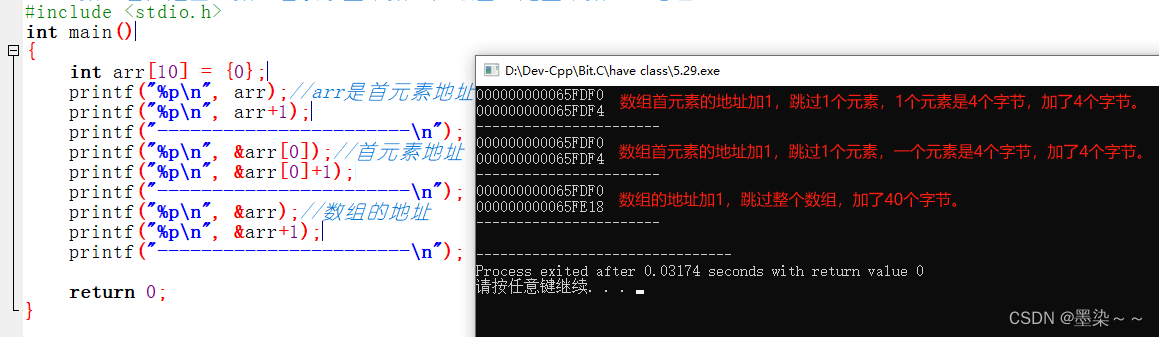
补充:
1. sizeof(数组名),计算整个数组的大小,sizeof内部单独放一个数组名,数组名表示整个数
组。
2. &数组名,取出的是数组的地址。&数组名,数组名表示整个数组。
除此1,2两种情况之外,所有的数组名都表示数组首元素的地址。
4.2.2 二维数组的数组名
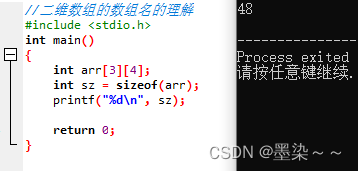
sizeof(arr)计算整个数组的大小,数组的大小为34=12,124=48。

一维数组与二维数组一样:
1.sizeof(数组名),计算整个数组的大小,sizeof内部单独放一个数组名,数组名表示整个数
组。
2. &数组名,取出的是数组的地址。&数组名,数组名表示整个数组。
除此1,2两种情况之外,所有的数组名都表示数组首元素的地址。
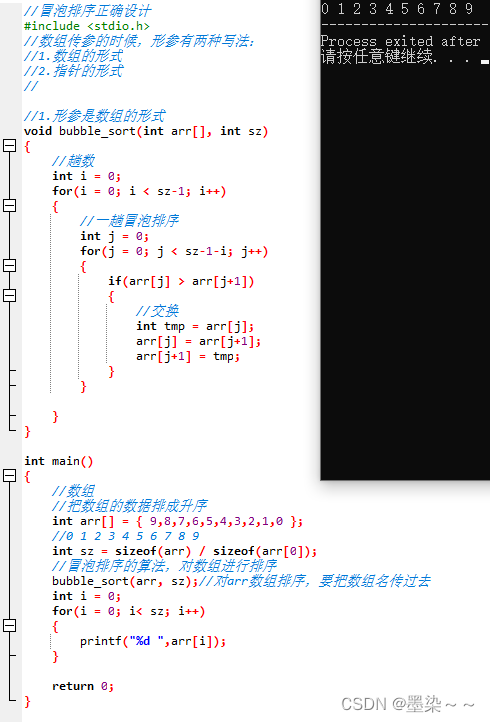
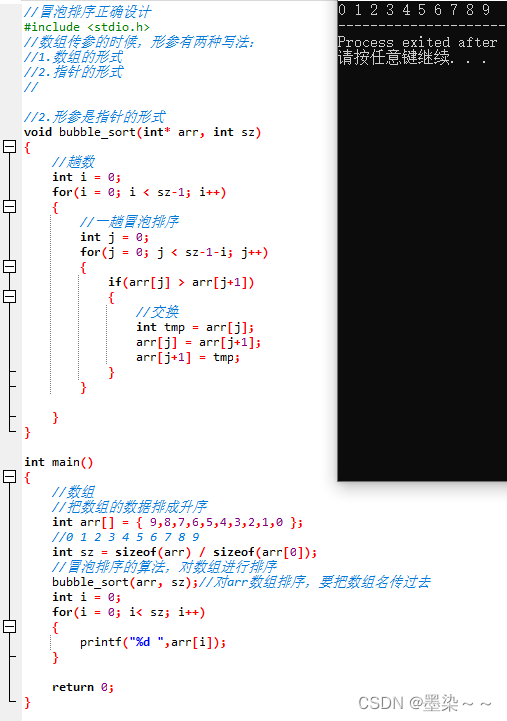
4.3 冒泡排序函数的正确设计
当数组传参的时候,实际上只是把数组的首元素的地址传递过去了。
所以即使在函数参数部分写成数组的形式: int arr[] 表示的依然是一个指针: int *arr 。
那么,函数内部的sizeof(arr) 结果是4。
如果上一个方法错了,该怎么设计?
1.形参是数组的形式
2.形参是指针的形式
总结
感谢观看,欢迎三连,如有错误,欢迎指正。















 1108
1108

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









