






一、背景
-
包含编程资料、学习路线图、源代码、软件安装包等!【[点击这里]】!
微信公众号的内容由于其特殊性,通常不允许被搜索引擎抓取,并且采取了多种反爬虫策略。尽管如此,网上仍有一些方法可以尝试爬取微信公众号的数据。以下是我近期网上搜索总结出的一系列技术方案(部分内容来源于网络):
方案1:直接抓包请求爬取
抓不到内容请求,难度大(可看下面的具体方案分析)
方案2:搜狗微信爬取
大量请求之后会触发验证码,无法精确搜索指定公众号,输入公众号名会搜出多个公众号,且对应的文章链接是临时链接,几个小时之后会失效。 搜狗微信在2019.10.29日已下线,所以获取不到最新注册的公众号内容
方案3:通过Hook来拦截获取微信的消息
必须独立使用一台windows服务器去做,因为微信只有win和mac版本,你想要把他跑在线上就必须搞一台windows服务器,而且还必须挂一个微信上去,成本就很高 微信在不知道什么时候做了额外的反爬机制,根据我的搜索应该就是22、23年左右添加的,触发某种反爬机制之后,惩罚从以前的封禁24小时修改成了永久封禁。这个封禁方式也很有意思,他阻止你访问微信公众号的历史列表
方案4:微信公众号转RSS方案
目前公众号RSS方案基本被平台封杀的差不多了,目前可用都是通过间接的方式来抓取数据,经测试数据刷新较及时的分别为:Feeddd、公众号文章话题 Tag 这几个订阅方式比较及时。
方案5:微信公众号后台引用链接方式爬取
需要使用自己公众号的cookie,并且cookie会失效,也有反爬和返回数量限制
二、各种方案尝试
方案1:直接抓包请求爬取
1.打开Charles,进行基础设置(安装证书,代理设置等)2.打开微信,设置代理(我的Charles代理端口8888)1.注意这里的服务器地址不要用localhost,要写具体IP
设置完成后,开始抓包,微信里打开公众号相关文章发请求,发现Charles里其实也抓到了一些包,主要是图片什么的
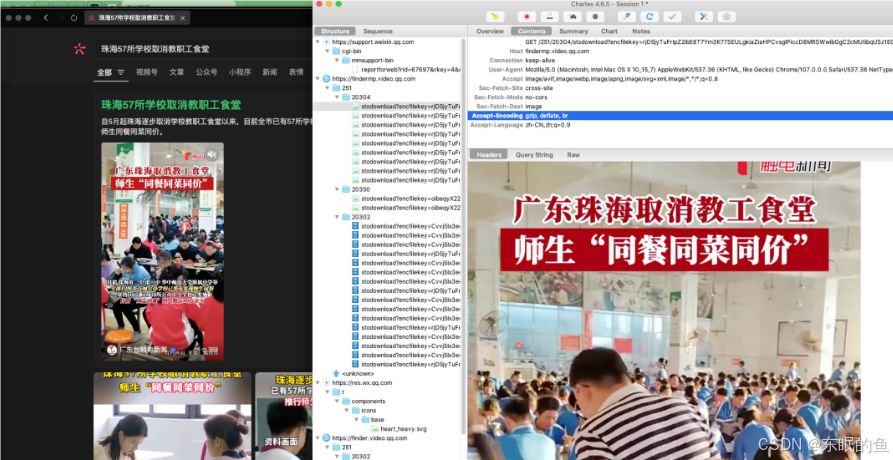
后来我又测试几次,在Charles里找到了一个接口里有一些内容,通过relatedarticle接口名字可以看出来,这是相关文章的接口。只返回了3篇文章的URL
https://mp.weixin.qq.com/mp/relatedarticle?action=getlist&article_url=https%3A%2F%2Fmp.weixin.qq.com%2Fs%3F__biz%3DMjM5NTAwMjAyMA%3D%3D%26mid%3D2697235946%26idx%3D2%26sn%3Dc711624e34303dbb32ceda5dac0c1b7a%26chksm%3D828981a7d3f2f32120fc83695b923ed0367c2d09d4ce7d238ca6e479a34e385a3aaee6bf28d6%26scene%3D126%26sessionid%3D1716531295%23rd&__biz=MjM5NTAwMjAyMA==&mid=2697235946&idx=2&has_related_article_info=0&is_pay=0&is_from_recommand=0&scene=126&subscene=0&is_open_comment=undefined&uin=&key=&pass_ticket=&wxtoken=777&devicetype=&clientversion=&__biz=MjM5NTAwMjAyMA%3D%3D&appmsg_token=&x5=0&f=json
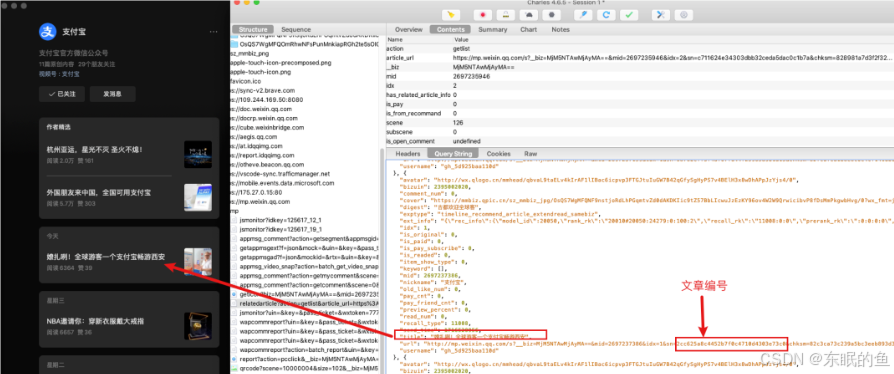
这里再说下微信公众号文章的URL链接组成,经过我测试只需要以下4个参数可以直接访问公众号文章。
1.__biz是公众号的唯一标识2.idx是文章在公众号中的位置3.mid是文章的唯一标识4.sn是一个由字母和数字组成的参数(重要)
其中1和2参数比较好获取,mid是文章唯一标识,最后还需要一个sn参数,并且sn参数是必须携带的。
sn参数解释
每篇文章都会对应一个独立的sn参数,用于标识该篇文章。这个参数是如何生成的呢?
首先,微信服务器会根据公众号的AppID和AppSecret生成一个AccessToken,用于访问微信API接口。然后,在用户访问某篇文章时,微信服务器会根据AccessToken、时间戳、随机数等信息生成一个签名(signature),并将签名和其他相关参数返回给用户。
其中,与sn相关的参数有:timestamp、nonce、signature和jsapi_ticket。它们分别表示当前时间戳、随机数、签名和jsapi_ticket。
接下来,微信服务器会根据这些参数和一个固定的字符串(即“jsapi_ticket”),生成一个新的字符串,并对这个字符串进行SHA1加密。最终,将加密后的结果作为sn参数返回给用户。
1.sn参数是由微信服务器生成的,用户无法自行指定;2.sn参数与文章内容无关,只是用于标识一篇文章;3.sn参数是有时效性的,同一篇文章在不同时间访问,其sn参数可能不同;4.sn参数不是必须的,如果用户访问文章时没有携带sn参数,微信服务器也会正常返回文章内容;5.由于sn参数是由微信服务器生成的,因此无法通过其他方式获取。
经过以上测试,总结起来这个方案不太可行,不太好抓包,即使能抓到包也很难处理参数逆向问题。放弃!
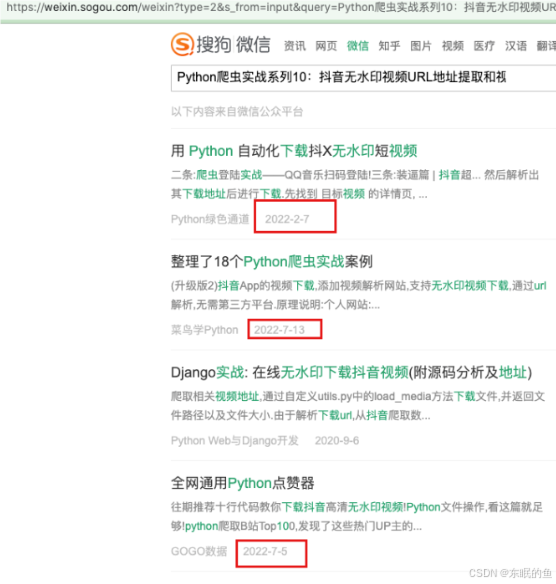
方案2:搜狗微信爬取
这个也是网上各种博客写的比较多的一个方案,但是 搜狗微信在2019.10.29日已下线,所以获取不到最新注册的公众号内容
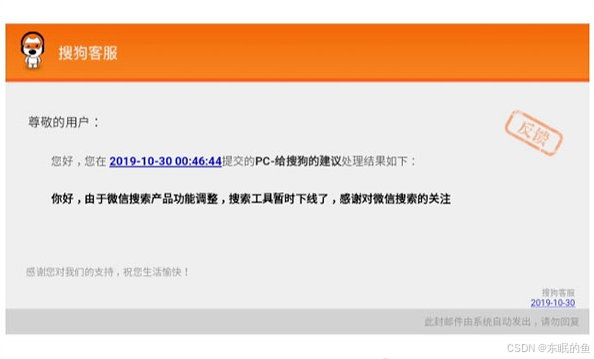
注意这里说的是抓不到在2019.10.29至今注册的公众号,如果在2019.10.29之前注册的公众号发表的文章应该是可以抓到的,我这边没测试过。
比如搜索我的公众号文章,也是搜不到的。。。
方案3:通过Hook来拦截获取微信的消息
很多人应该都知道hook这个技术,整体来说hook技术实现后相对稳定,扩展性强。但是 技术难道大,环境不好处理,需反编译源码分析原功能逻辑,hook后需要对数据解码,以下是目前搜索到的一些针对微信的hook方案供参考:
1.搜狗微信下线了怎么获取公众号文章?手把手教你最新获取方式:https://juejin.cn/post/68449039872509870212.Hook WeChat / 微信逆向:https://github.com/ttttupup/wxhelper3.DaenMax/WeChat-Hook-千寻:https://gitee.com/daenmax/pc-wechat-hook-http-api
Hook方案:封号的风险很大!请各位自行搜索~
方案4:微信公众号转RSS方案
网上还有一种方式,是通过订阅RSS的方案来获取指定公众号新发布的文章内容
例如:https://wechat2rss.xlab.app/
这个方案具体没测试过,写在这里只是作为一个思路供大家参考。
方案5:微信公众号后台引用链接方式爬取
接下来说下本文尝试过的这种简单方案,公众号后台的方式。整体思路很简单,就是借助公众号发文章的后台来获取别的公众号发布的文章列表。
1.打开公众号后台,新建图文文章2.点击添加超链接,选择公众号,然后分析请求即可

简单搜索关键字后,可以看到一个get接口

https://mp.weixin.qq.com/cgi-bin/appmsgpublish?sub=list&search_field=null&begin=0&count=5&query=&fakeid=MjM5NTAwMjAyMA%3D%3D&type=101_1&free_publish_type=1&sub_action=list_ex&token=1615444064&lang=zh_CN&f=json&ajax=1
直接复制为curl,然后转为Python代码运行即可。

该接口每次返回5篇文章,可根据情况调整测试。
import json
import requests
cookies = {
'appmsglist_action_3078708053': 'card'
# 其他cookie信息,请直接从浏览器里复制
}
headers = {
'accept': '*/*',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'no-cache',
'pragma': 'no-cache',
'priority': 'u=1, i',
'sec-ch-ua': '"Chromium";v="124", "Brave";v="124", "Not-A.Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"macOS"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'sec-gpc': '1',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36',
'x-requested-with': 'XMLHttpRequest',
}
params = {
'sub': 'list',
'search_field': 'null',
'begin': '0',
'count': '15', # 采集条数
'query': '',
'fakeid': 'MjM5NTAwMjAyMA==',
'type': '101_1',
'free_publish_type': '1',
'sub_action': 'list_ex',
'token': 'token值', # token值
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
}
response = requests.get('https://mp.weixin.qq.com/cgi-bin/appmsgpublish', params=params, cookies=cookies)
resultStr = response.json()
publish_page = resultStr.get('publish_page')
articleList = json.loads(publish_page)
for article in articleList.get("publish_list"):
publish_info = json.loads(article.get("publish_info"))
title = publish_info['appmsgex'][0]['title']
link = publish_info['appmsgex'][0]['link']
print(title, link)
以上代码运行后获取列表如下图
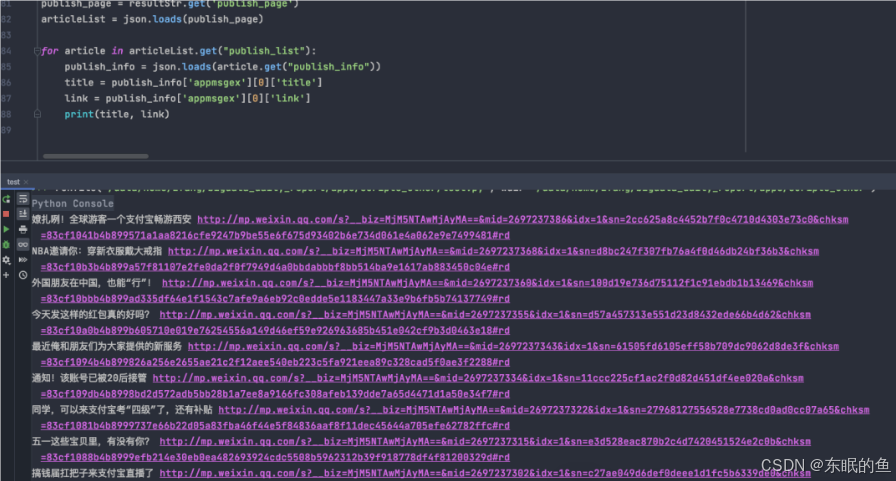
基于公众号后台的采集方案,目前来看至少可行,具体对公众号的封号风险等具体没有测试,请大家自行尝试。这类代码网上也很多,可自行搜索。
总结
本文只是基于近期搜索调研了一些内容后的抛砖引玉总结,具体一些方案详细技术实现大家可私下自己尝试。
1.最终可行方案:hook或微信公众号后台采集2.注意封号风险3.接下来还需要研究获取文章的阅读点赞,在看,转发,留言等数量的获取4. 大家还有哪些方案,欢迎评论区留言一起交流
免责申明
由于信息安全问题,本文章内容及代码只做学习交流使用,作者不负责任何由此引起的任何法律责任。您在引用该代码时代表您已同意该协议,由此引起的任何法律责任由您承担
1.本文内容及代码仅供学习和交流使用,作者对由此引起的任何直接或间接损失不承担责任。2.引用或使用本文内容及代码产生的任何法律责任由使用者自行承担。3.如果您认为本文内容或代码侵犯了您的权益或对公司利益造成了损失,请联系作者进行删除等处理。作者将尽快处理您的请求,以保护公司的合法权益。
关于Python技能储备!
**如果你是准备学习Python或者正在学习(想通过Python兼职),下面这些你应该能用得上:
-
包含编程资料、学习路线图、源代码、软件安装包等!【[点击这里]】!
包括:激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、自动化办公等学习教程。带你从零基础系统性的学好Python!
① Python所有方向的学习路线图,清楚各个方向要学什么东西
② 100多节Python课程视频,涵盖必备基础、爬虫和数据分析
③ 100多个Python实战案例,学习不再是只会理论
④ 华为出品独家Python漫画教程,手机也能学习
⑤ 历年互联网企业Python面试真题,复习时非常方便******


以上就是本次分享的全部内容。我们下期见~

















 3811
3811

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









