








第一章 安装
1. 1 开发环境
官网 https://www.python.org
稳定版 Stable Releases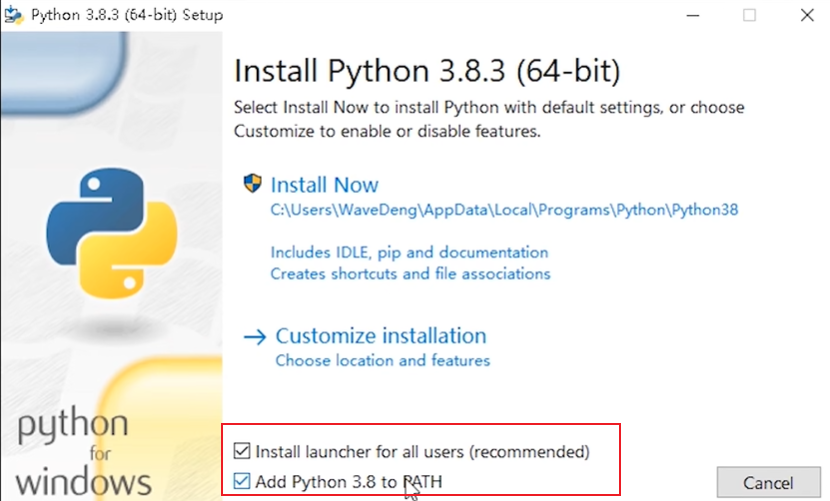
检验(cmd 命令):python --version
1.2 开发工具
PyCharm官网 https://www.jetbrains.com/pycharm/download/#section=windowsHttps://www.jetbrains.com/pycharm/download/#section=windows
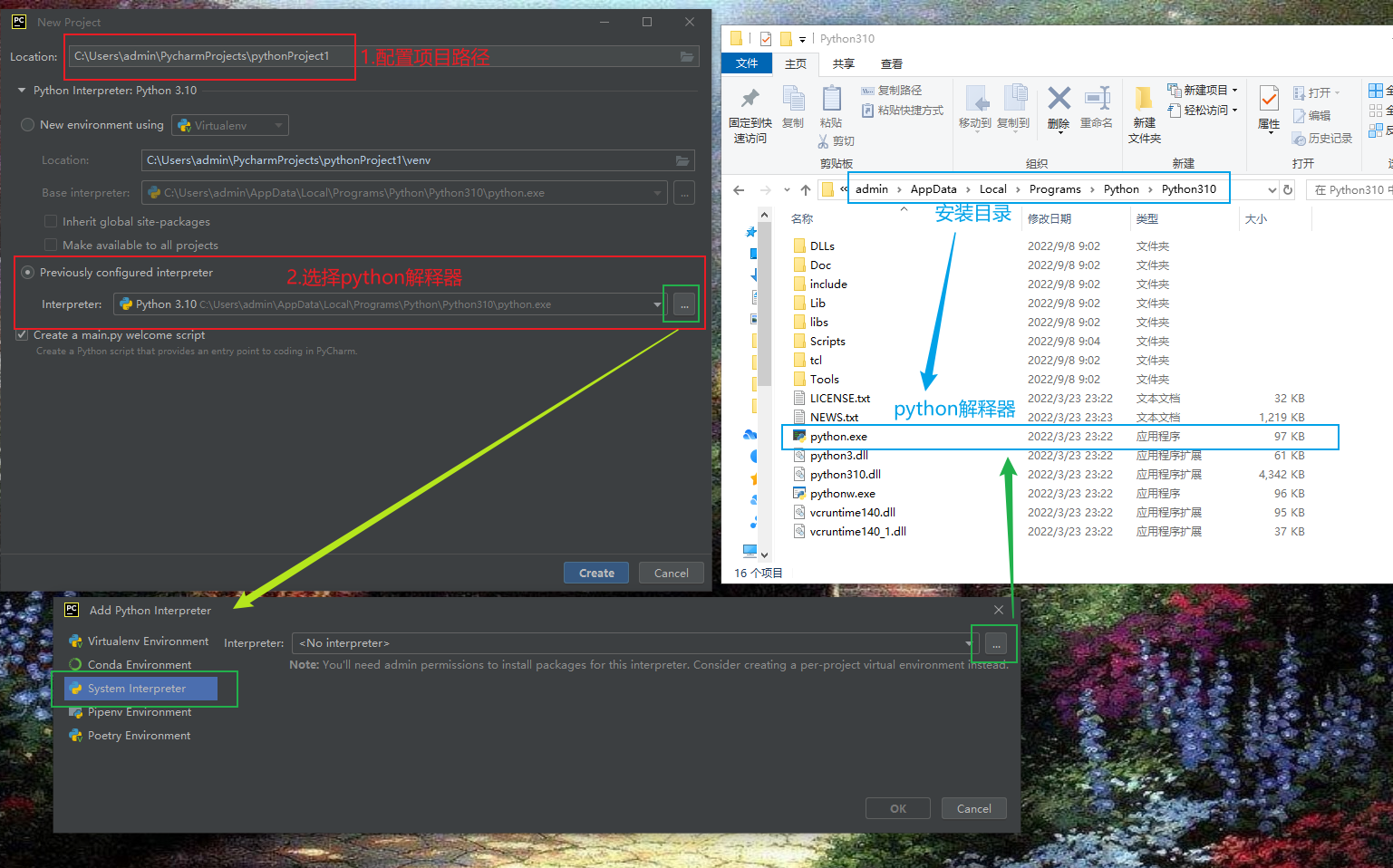
1.新建项目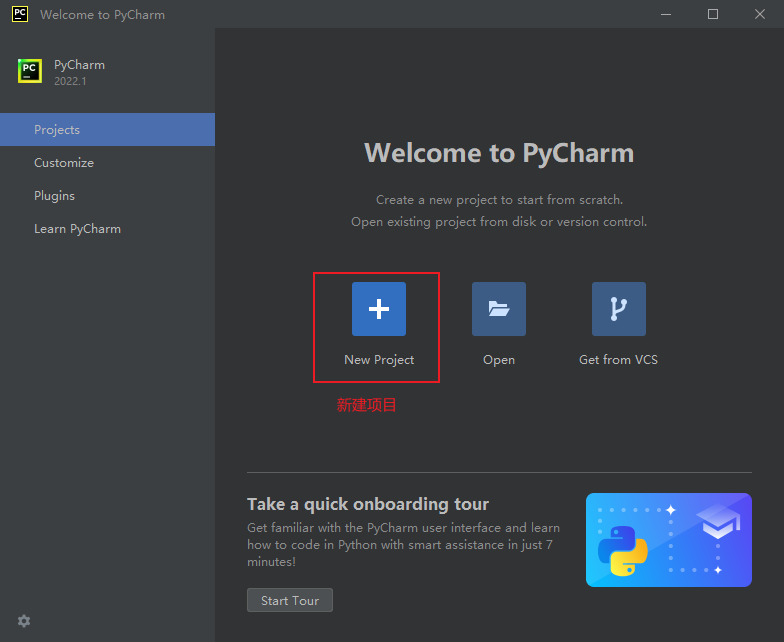

常用快捷键
Ctrl + Alt + s 打开软件设置
Ctrl + D 复制光标所在整行代码
Shift + Alt + ↑ 或 ↓ 将整行代码上移或下移
Ctrl + Shift +F10 运行当前代码文件
Shift + F6 重命名文件
Ctrl + F 搜索
第二章 基础语法
2.1.1 字面量
在代码中,被写下来的固定的值,称之为字面量。
2.1.2 常用的字面量类型
| 类型 | 描述 | 说明 |
|---|---|---|
| 数字(Number) | 整数(int) | 如10,-10 |
| 浮点数(float) | 如12.13,-12.16 | |
| 复数(complex) | 如3+4j,以j结尾表示复数 | |
| 布尔(bool) | True记作1,False记作0 | |
| 字符串(String) | 用于描述文本 | 由任意数量的字符组成,python中字符串类型须带英文双引号 |
| 列表(List) | 有序的可变序列 | python中使用最频繁的数据类型,可有序记录一堆数字 |
| 元组(Tuple) | 有序的不可变序列 | 可有序的记录一堆不可变的python数据集合 |
| 集合(set) | 无序不重复集合 | 可无序记录一堆不重复的python数据集合 |
| 字典(Dictionary) | 无序Key-Value集合 | 可无序记录一堆Key-Value型的python数据集合 |
2.2 注释
1.单行注释
# print("Hello Word")
[注]'#'号和注释内容之间建议用一个空格符隔开
2.多行注释(三个双引号或单引号)
"""
print("Hello Word")
print("Hello Word")
print("Hello Word")
"""
3.快捷键
Ctrl + /
2.3 变量
在程序运行时,能存储计算结果或能表示值的抽象概念。
money = 50
bql = 10
kl = 5
print("当前钱包余额:",money,"元")
print("购买了冰淇淋,花费:",bql,"元")
print("购买了可乐,花费:",kl,"元")
print("最终,钱包剩余",money-bql-kl,"元")
2.4 数据类型
| 类型 | 描述 | 说明 |
|---|---|---|
| String | 字符串 | 用引号引起来的数据都是字符串 |
| int | 整型(有符号) | 数字类型,存放整数(如 -1,10,0) |
| Float | 浮点型(有符号) | 数字类型,存放小数(如 -3.14,6.66) |
2.4.1 type() 语句
语法: type(数据)
用于查看数据的数据类型。
例1:查看“3.14159”和“hello”的数据类型
print(type(3.14159))
print(type("hello"))
例2:查看变量a的数据的数据类型
a = type("芜湖")
print(a)
2.4.2 数据类型转换
| 语句(函数) | 说明 |
|---|---|
| int(x) | 将x转换为一个整数 |
| float(x) | 将x转换为一个浮点数 |
| str(x) | 将对象x转换为字符串 |
# 浮点数转整数(会丢失精度)
float_num = float(3.16)
print(int(float_num))
# 整数转浮点数
Int_num = int(2)
print(float(Int_num))(float(Int_num))
# int转字符串(万物皆可转字符串)
int_num = int(2)
print(str(int_num))
2.5 标识符
标识符用户在编程的时候所使用的一系列名字,用于给变量、类、方法等命名。
2.5.1 标识符命名规则
1.内容限定
英文 ,中文 ,数字 ,下划线 _
[注]:一般情况下不推荐使用中文;数字不做开头。
2.大小写敏感
3.不可使用关键字
| False | True | None | and | as | assert |
|---|---|---|---|---|---|
| break | class | continue | def | del | elif |
| else | excpet | finally | for | from | global |
| if | import | in | is | lambda | nonlocal |
| not | or | pass | raise | return | try |
| while | with | yield | – | – | – |
2.5.2 变量名命名规范
1.望文生义
a = "张三" | name = "张三"
b = 18 | age = 18
2.下划线命名法
userid = "张三" | user_id = "张三"
userpwd = 12345 | user_pwd = 12345
3.英文字母全小写
Name = "张三" | name = "张三"
Age = 18 | age = 18
2.6 运算符
2.6.1 算术运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加 | 两个对象相加 a + b 输出结果 |
| - | 减 | 两个对象相减 a - b 输出结果 |
| * | 乘 | 两个对象相乘 a * b 输出结果 |
| / | 除 | 两个对象相除 a / b 输出结果 |
| // | 取整除 | 两个对象相除 a / b 输出商的整数部分 |
| % | 取余 | 两个对象相除 a / b 输出商的余数部分 |
| ** | 指数 | a**b表示a的b次方 |
# 算术运算符
a = 5
b = 2
print("a+b=",a+b)
print("a-b=",a-b)
print("a*b=",a*b)
print("a/b=",a/b)
print("a//b=",a//b)
print("a%b=",a%b)
print("a**b=",a**b)
2.6.2 赋值运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 赋值运算符 | 把等号右边的结果赋给左边的变量,如 num = 1+1,输出结果num 值为 2 |
2.6.3 复合赋值运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| += | 加法赋值运算符 | a +=b 等效于 a = a+b |
| -= | 减法赋值运算符 | a -= b 等效于 a = a - b |
| *= | 乘法赋值运算符 | a *= b 等效于 a = a * b |
| /= | 除法赋值运算符 | a /= b 等效于 a = a / b |
| %= | 取模赋值运算符 | a %= b 等效于 a = a % b |
| **= | 幂赋值运算符 | a **= b 等效于 a = a * * b |
| //= | 取整除赋值运算符 | a //= b 等效于 a = a // b |
2.6.3 逻辑运算符
| and | 与运算符,用来比较两个或多个运算符是否全部为真 一假则假,全真才真 |
|---|---|
| or | 或运算符,用来比较两个或多个运算符是否其中一个为True 一真则真,全假则假 |
| not | 非运算符,真就是假,假就是真 |
2.7 字符串扩展
2.7.1 定义字符串
- 单引号定义法
name = '芜湖'
- 双引号定义法
name = "芜湖"
- 三引号定义法
name = """
芜湖
芜湖
芜湖
"""
#[注] 三引号支持换行操作;使用变量接收即为字符串;不使用变量接收可以作为多行注释使用。
2.7.2 字符串的引号嵌套
-- 如何输出引号?
- 1.输出内容包含双引号
name = '"芜湖"'
print(name)
- 2.输出内容包含单引号
name = "'芜湖'"
print(name)
- 3.使用转义字符取消引号作用
print("\"芜湖\"")
print('\'芜湖'\')
2.7.3 字符串拼接
name = "张三"
tel = "123456"
print("姓名:"+name+" 电话:"+tel)
[注] 加号拼接只能用于字符串类型,其他类型须先转换为字符串
2.7.4 字符串格式化
- 例1.单个变量占位
name = "张三"
message = "姓名:%s"% name
print(message)
- 例2.多个变量占位
name = "张三"
tel = "123456"
message = "姓名:%s,电话:%s"%(name,tel)
------------------------------------
[%] 表示占位
[s] 表示将变量变成字符串放入占位的地方
+---------+--------------------------------+
| 格式符号 | 转化 |
+------------------------------------------+
| %s | 将内容转换成字符串,放入占位位置 |
+---------+--------------------------------+
| %d | 将内容转换成整数,放入占位位置 |
+---------+--------------------------------+
| %f | 将内容转换成浮点型,放入占位位置 |
-------------------------------------------+
2.7.5 格式化的精度控制
使用辅助符号 %m.n 来控制数据的宽度和精度 <br /> **·** m, 控制宽度,要求是数字,设置的宽度小于自身则不生效<br /> **·** .n, 控制小数点精度,要求是数字,会进行小数部分的四舍五入
num_a = 12
num_b = 13.141
print("12宽度控制5:%5d"%num_a)
print("12宽度控制3:%3d"%num_a)
print("12宽度控制1:%1d"%num_a)
print("13.141宽度不控制,小数精度控制2:%.2f"%num_b)
print("13.141宽度不控制,小数精度控制5:%.5f"%num_b)
print("13.141宽度控制2,小数精度控制5:%2.5f"%num_b)
---------------------------------------
12宽度控制5: 12
12宽度控制3: 12
12宽度控制1:12
13.141宽度不控制,小数精度控制2:13.14
13.141宽度不控制,小数精度控制5:13.14100
13.141宽度控制2,小数精度控制5:13.14100
---------
[注] %5d:表示将整数的宽度控制在5位,不满足的位数会以空格形式输出。
%5.2f:表示将宽度控制为5,小数精度设置为2。
%.5f:表示不限制宽度,只设置小数精度为5。
2.5.8 字符串格式化的快速写法
f"内容{变量}"
----------------------------------
name = "张三"
age = 13
message = f"我叫{name},今年{age}岁了"
print(message) 或者 print(f"我叫{name},今年{age}岁了")
2.5.9 表达式的格式化
表达式就是一个具有明确结果的代码语句。
f"{表达式}"
"%s\%d\%f"%(表达式、表达式、表达式)
-------------------
print("1+1=%d"%(1+1))
print(f"2*2={2*2}")
print("3.14159的数据类型是%s"%type(3.14159))
2.8 数据输入
2.8.1 input() 语句
# 获取用户输入的姓名并存入变量name
name = input()
print(name)
------应用--------
print("你是谁呀?")
name = input()
print(f"索嘎,你是{name}")
------优化--------
name = input("你是谁呀?")
print(f"索嘎,你是{name}")
2.8.1 input() 语句的数据类型
通过 type() 可判断,inpt() 输出的均为字符串类型
message = input("输入任意类型值")
print(type(message))
可通过数据类型转换实现不同类型的输出
# 转换为int
message = int(input("输入任意int类型值"))
print(type(message))
# 转换为float
message = float(input("输入任意float类型值"))
print(type(message))
2.9 数据输出
print("内容……") 换行输出
print("内容……",end='') 不换行输出
print("hello,",end='')
print("word",end='')
折行输出
print("hello "
"word")
输出引号
# 输出单引号或双引号
print("''") # 单引号
print('""') # 双引号
# 转义字符
print("\"") # 双引号
print('\'') # 单引号
制表位输出
例如输出一行结果hello word(\t等效于a)
print("hello \tword")
print(“内容……”,end=‘’) 还可用于结尾格式定义
# 1.以固定字符结尾
print("内容……",end="某字符或字符串")
# 2.以空格符结尾
print("内容……",end=" ")
# 3.以制表位结尾
print("内容……",end='/t')
转义字符
+-----+--------------------------------------+
| \n | 换行符(new line),光标移至下一行开头 |
+-----+--------------------------------------+
| \t | 制表符(tab),输出一个制表位 |
+-----+--------------------------------------+
| \r | 返回符(return),输出符号以后的内容 |
+-----+--------------------------------------+
| \a | 主机蜂鸣器响铃 |
+-----+--------------------------------------+
| \b | 退格符(Backspace) |
+-----+--------------------------------------+
| \\ | 输出一个\ |
+-----+--------------------------------------+
| \ | 在结尾时表示续行(不断行) |
+-----+--------------------------------------+
| \v | 纵向制表符 |
+-----+--------------------------------------+
| \f | 换页符 |
+-----+--------------------------------------+
2.4 数据类型
第三章 Python 判断语句
3.1 布尔类型和比较运算符
布尔(bool)类型表达现实生活中的逻辑,即真或假
True 真 1
False 假 0
定义语法 : 变量名 = 布尔类型字面量
# 定义bool型值
a = True
b = False
print(type(a))
print(type(b))
| 比较运算符 | ||
|---|---|---|
| 运算符 | 名称 | 说明 |
| == | 等于 | 例:a == 10 |
| != | 不等于 | 例:a != 10 |
| > | 大于 | 例:a > 10 |
| < | 小于 | 例:a < 10 |
| <= | 小于等于 | 例:a <= 10 |
| >= | 大于等于 | 例:a >= 10 |
# 使用bool判断表达式
compare = 10 > 22
print(bool(compare))
3.2 判断语法
3.2.1 if 语句的基本格式
if 要判断的条件:
条件成立则执行.......
# 定义变量,判断是否成年
age = 19
if age >= 18:
print("不再受《未成年人保护法》保护")
[注] 判断语句的结果必须是布尔类型True或False
True则执行if内代码语句
False则不会执行
3.2.2 if else 语句
if 要判断的条件:
条件成立则执行.......
else:
条件不成立则执行.......
# 通过input语句获取键盘输入的身高,判断是否超过120cm,并通过print给出提示信息
print("欢迎来到黑马动物园")
height = int(input("请输入身高(cm):"))
if height >= 120:
print("您的身高超出120cm,游玩须购票10元")
print("祝您游玩愉快!")
else:
print("您的身高未超出120cm,可以免费畅玩")
print("祝您游玩愉快!")
3.2.3 if elif else
if 要判断的条件1:
条件1成立则执行.......
elif 要判断的条件2:
条件2成立则执行.......
elif 要判断的条件n:
条件n成立则执行.......
else:
以上条件都不成立则执行.......
# 例1.通过input语句获取键盘输入的身高,判断是否超过120cm,超过则判断vip等级是否高于3,并通过print给出提示信息
print("欢迎.....")
if int(input("您的身高是")) <= 120 :
print("您的身高未超出120cm,可以免费畅玩")
elif int(input("请输入vip等级")) >= 3:
print("vvvip用户欢迎您")
elif int(input("请输入当前星期数")) == 1:
print("周一会员日免费畅玩")
else:
print("请补票十元")
print("祝您游玩愉快")
--------------------------------------------------------------------
# 例2.定义一个数字,使用input获取键盘输入的值,三次机会。
num = 9
if int(input("第一次猜:")) == num:
print("哇哦,第一次就猜对了呢")
elif int(input("不对哦,重新来第二次猜:")) == num:
print("恭喜你猜对了")
elif int(input("咦拉跨,最后一次机会了哦,猜:")) == num:
print("真不错,终于猜到了")
else:
print("噫~ 怕是这辈子都猜不到了")
3.2.4 判断语句的嵌套
if 要判断的条件1:
条件1成立则执行.......
if 要判断的条件2:
同时条件1和2成立则执行.......
if 要判断的条件n:
同时满足条件1,2,n成立则执行.......
[注] python中空格缩进表示层级关系
#通过input语句获取键盘输入的身高,判断是否超过120cm,超过则判断vip等级是否高于3,并通过print给出提示信息
print("欢迎.....")
if int(input("您的身高是")) <= 120 :
print("您的身高未超出120cm,可以免费畅玩")
elif int(input("请输入vip等级")) >= 3:
print("vvvip用户欢迎您")
elif int(input("请输入当前星期数")) == 1:
print("周一会员日免费畅玩")
else:
print("请补票十元")
print("祝您游玩愉快")
----------------------------------------------------------------------
# 使用嵌套if改写
print("欢迎.....")
if int(input("您的身高是:")) > 120:
if int(input("您的会员等级是:")) < 3:
if int(input("请输入当前星期数")) != 1:
print("不满足优惠条件,请补票十元")
else:
print("周一会员日免费畅玩")
else:
print("欢迎vvvip用户免费畅玩")
else:
print("您的身高未超出120cm,可以免费畅玩")
第四章 Python 循环语句
4.1 while 循环
4.1.1 while 循环基础
while 要判断的条件:
条件成立时循环内容.......
条件成立时循环内容.......
条件成立时循环内容.......
条件不成立时结束循环......
[注] while判断条件的结果必须为bool型,True继续,False停止
# 员工工资为1(单位:k),每月涨1k工资,涨到10k截至,使用while循环输出每月工资明细
salary = 1
month = 1
while salary <= 10:
print(f"%s月工资为:"%month,salary)
salary += 1
month += 1
# 通过while循环,计算1累加到100的和
num = 1
while num <= 100:
print(f"1+%s={1+num}"%num)
num += 1
----------------------------------------------------------------------
# 通过while循环,依次输出计算1累加到100的和(结果为5050)
num_1 = 0
num_2 = 1
while num_2 <= 100:
num_1 += num_2 # num_1 = num_1 + num2
num_2 += 1 # num_2 = num_2 + 1
print(num_1)
----------------------------------------------------------------------
# 初始工资为100元,每天涨工资10元,涨到200
salary = 100
time = 1
while time <= 10:
time += 1
print(f"第{time}天")
salary += 10
print(f"当前工资{salary}")
4.1.2 猜数字游戏案例
# 猜数字游戏:
# 设置一个范围1-100的随机数变量,通过while循环,配合input语句,判断输入数字是否等于随机数
# 1.无限次机会,直到猜中为止 2.猜不中时提示大了或小了 3.猜中数字输出猜了几次
import random
num = random.randint(1,100) # 设置一个随机函数,随机输出1~100
flag = True # 定义循环初始变量为True,猜对时变为False
time = 0 # 设置次数初始值为0,每循环一次加一
while flag :
guess = int(input("你可以猜一个1~100的随机整数"))
time += 1
if guess == num:
flag = False
print(f"猜对啦!一共用了{time}次机会")
elif guess < num:
print("猜小了")
elif guess > num:
print("猜大了")
4.1.3 while 循环的嵌套应用
while 要判断的条件1:
条件1成立时循环内容.......
条件1成立时循环内容.......
while 要判断的条件2:
条件2成立时循环内容.......
条件2成立时循环内容.......
# 坚持每天表白,每次送10支花,100次即表白成功
day = 1
while day <=100:
print(f"第{day}天表白")
day += 1
flower = 1
while flower <=10:
flower += 1
print(f"第{day-1}天表白送的第{flower-1}枝花")
print("满100天啦,表白成功")
------------------------------------------------------------------------
day =1
while day <= 100:
print(f"第{day}天")
day += 1
flower = 1
while flower <=10:
print(f"\t\t\t送花*{flower}")
flower += 1
[注] 使用<=或>=时,实际值可能大于期望值,所以要注意对输出结果的处理
# 打印输出九九乘法表
line = 1 # 从第一行开始
while line <= 9: # 行数<=9
field = 1 # 每列从1开始
print() #换行
while field <= line:
print(f"{field}*{line}={line * field}\t",end='')
field += 1
line += 1 # 外循环每行结束后line+1
----------------------------------------------------------------------
line = 1
while line <= 9:
field = 1
while field <= line:
print(f"{field}*{line}={field*line}",end="\t")
field += 1
print()
line += 1
4.2 for 循环
4.2.1 for 循环基础
while和for的区别
1.while循环的循环条件是自定义的,自行控制循环条件,for循环无法控制循环条件。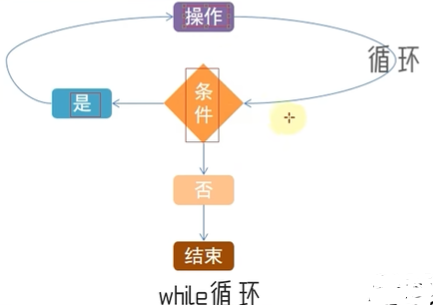
2.for循环是一种轮询机制,对一批内容进行逐个处理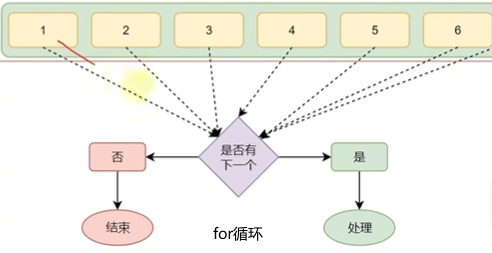
3.python中被处理的数据集不可能无限大,所以for循环无法构建无限循环。
for 临时变量 in 待处理的数据集 (序列):
循环满足条件执行的代码
name = "skaldsk" # 定义变量name
for a in name: # 将name的值依次取出赋予a临时变量
print(a)
[注] for循环可将字符串的字符依次取出,故又称“遍历循环”。
----------------------------------
s
k
a
l
d
s
k
进程已结束,退出代码0
# 案例:定义一个变量,计算a的数量
name = "itheima is a brand of itcast"
calculate = 0 # 定义一个变量计算a的数量
for x in name:
if x == "a":
calculate += 1
print(f"name中有{calculate}个a")
4.2.2 range 语句
用法:
for x in range():
print(x)
语法1:
range(num)
# 获取一个从0开始,到num结束的数字序列(不包括num本身)
如range(3) => [0,1,2]
----------------------------------------------------------------------
语法2:
range(num1,num2)
# 获取一个从num1开始,到num2结束的数字序列(不包括num2本身)
如range(3,6) => [3,4,5]
----------------------------------------------------------------------
语法3:
range(num1,num2,step)
# 获取一个从num1开始,到num2结束的数字序列(不包括num2本身)
step为数字之间的步长(默认1)
如range(1,5,2) => [1,3]
# 案例:定义一个变量,计算1到100(不包括100)中的偶数
num = 0
for x in range(1,100):
if x % 2 == 0:
num += 1
print(f"1~100(不包括100)中偶数有{num}个")
变量作用域
for循环基本格式为:
for 临时变量 in 待处理的数据集 (序列):
循环满足条件执行的代码
[注] 在编程规范上,临时变量的作用范围(作用域),只限定在for循环内部;如需在循环外访问临时变量,可以预先在循环外定义它。
4.2.3 for 循环嵌套
# 案例:坚持表白100天,每天送10支花
for day in range(100):
print(f"表白第{day+1}天")
for flower in range(10):
print(f"送出第{flower+1}支花")
----------------------------------------------------------------------
# 案例:九九乘法表
line = 1
for line in range(1,10):
field = 1
print()
for field in range(1,line+1):
print(f"{line}*{field}={line*field}",end="\t")
4.2.4 循环中断 break和continue
1.continue关键字:临时中断,中断所在循环的当次循环,进行下一次循环
-----------------
for x in range(10): |
print("语句1") | 使用continue关键字跳过后
continue | print("语句2")将不会执行
print("语句2") | 直接输出语句1和语句3
print("语句3") |
------------------
2.break关键字:永久中断#,直接结束所在的循环
只能结束break所在的循环
-----------------
for x in range(5): |
print("语句1") | 使用break关键字跳过后
break | print("语句2")将不会执行
print("语句2") | 直接输出5次语句1和一次语句3
print("语句3") |
------------------
4.2.5 循环案例
# 员工编号emp_num,1~20
# 每人发放工资1000 当公司余额不足时停止发放
# 绩效评分 performance,随机1~10,绩效评分低于5时不予发放
# 公司总额 sum_money=10000
import random
sum_money = 10000
for emp_num in range(1,21):
performance = random.randint(1, 11)
if performance < 5:
print(f"员工{emp_num},绩效分{performance},绩效分低于5,不发工资,下一位")
continue
elif performance >= 5:
sum_money -= 1000
if sum_money < 0:
print("工资发完了,下个月再领吧")
break
print(f"员工{emp_num},绩效分{performance},向{emp_num}员工发放工资1000元,"
f"公司账户余额还剩{sum_money},下一位")
----------------------------------------------------------------------
员工1,绩效分4,绩效分低于5,不发工资,下一位
员工1,绩效分4,向1员工发放工资1000元,公司账户余额还剩10000,下一位
员工2,绩效分5,向2员工发放工资1000元,公司账户余额还剩9000,下一位
员工3,绩效分2,绩效分低于5,不发工资,下一位
员工3,绩效分2,向3员工发放工资1000元,公司账户余额还剩9000,下一位
员工4,绩效分1,绩效分低于5,不发工资,下一位
员工4,绩效分1,向4员工发放工资1000元,公司账户余额还剩9000,下一位
员工5,绩效分6,向5员工发放工资1000元,公司账户余额还剩8000,下一位
员工6,绩效分5,向6员工发放工资1000元,公司账户余额还剩7000,下一位
员工7,绩效分9,向7员工发放工资1000元,公司账户余额还剩6000,下一位
员工8,绩效分6,向8员工发放工资1000元,公司账户余额还剩5000,下一位
员工9,绩效分6,向9员工发放工资1000元,公司账户余额还剩4000,下一位
员工10,绩效分7,向10员工发放工资1000元,公司账户余额还剩3000,下一位
员工11,绩效分1,绩效分低于5,不发工资,下一位
员工11,绩效分1,向11员工发放工资1000元,公司账户余额还剩3000,下一位
员工12,绩效分6,向12员工发放工资1000元,公司账户余额还剩2000,下一位
员工13,绩效分4,绩效分低于5,不发工资,下一位
员工13,绩效分4,向13员工发放工资1000元,公司账户余额还剩2000,下一位
员工14,绩效分10,向14员工发放工资1000元,公司账户余额还剩1000,下一位
员工15,绩效分7,向15员工发放工资1000元,公司账户余额还剩0,下一位
工资发完了,下个月再领吧
第五章 Python 函数
5.1 函数介绍
函数:是组织好的,可重复使用的,用来实现特定功能的代码段。
有点:提高代码的复用性,减少重复代码,提高开发效率。
5.1.1 函数的定义
1.函数的定义
def 函数名(传入参数): | ① 参数如果不需要可以省略,但须保留括号
函数体 | ② 返回值如果不需要可以省略
return 返回值 | ③ 函数必须先定义后使用
2.函数的调用
函数名(参数)
# 定义函数
def hi(name):
print(f"亲爱的{name},您好!请出示72小时核酸证明")
#调用函数
hi("王梓骅")
----------------------------------------------------------------------
亲爱的王梓骅,您好!请出示72小时核酸证明
5.1.2 函数的参数
传入参数的功能是:在函数进行计算时,接收外部(调用时)提供的数据
def plus(num1,num2):#num1和num2为形式参数(形参),表示函数声明将要使用2个参数
print(f"{num1}+{num2}={num1+num2}")
plus(1,9)
#函数调用时,传入的两个参数称为实际参数(实参),表示函数执行时真正使用的参数值,注意按照顺序传入参数。
----------------------------------------------------------------------
1+9=10
def temperature(value):
if float(value) <= 37.5:
print(f"欢迎来到XXX博物馆,当前体温{value}度,体温正常")
else:
print(f"欢迎来到XXX博物馆,当前体温{value}度,体温异常,请自行前往隔离区")
temperature(38)
----------------------------------------------------------------------
欢迎来到XXX博物馆,当前体温38度,体温异常,请自行前往隔离区
5.1.3 函数的返回值
程序中函数完成事情后,返回给调用者的结果。
def 函数(参数): # 定义函数
函数体
return 返回值
变量 = 函数(参数) # 调用函数
def plus(num1,num2):
add = f"{num1}+{num2}={num1+num2}" # 定义一个变量add,用于接收函数结果
return add # 返回变量add
x = plus(1,6) # 定义一个变量x,调用plus函数,传入参数1和6
print(x) # 打印输出x
[注] return表示返回并结束,return关键字以后的语句将不被执行。
----------------------------------------------------------------------
1+6=7
5.1.4 None字面量
1.None字面量
None可以主动使用return返回,效果等同于不写return语句。
在函数未使用return关键字时依然有返回值,此时返回值的类型是NoneType,实际上就是返回了None这个字面量。
None表示:空的、无实际意义的意思;函数返回的None,就表示这个函数没有返回什么有意义的内容,也就是返回了空的意思。
2.None类型的应用场景
· 用在函数无返回值上
· 用在 if 判断上
在 if 判断中,None等同于False
一般用于在函数中主动返回 None,配合 if 判断做相关处理
def age(num): # 定义一个函数判断是否成年
if num >= 18:
print("成年")
a = age(10) # 调用函数,传入一个不满足条件的参数
print(a) # 打印输出(结果返回None,等效于Fale)
----------------------------------------------------------------------
None
· 用于声明无初始内容的变量上
5.2 函数说明文档
在函数体之前,使用多行注释进行解释说明,在PyCharm中使用鼠标悬停可以查看到该函数的说明。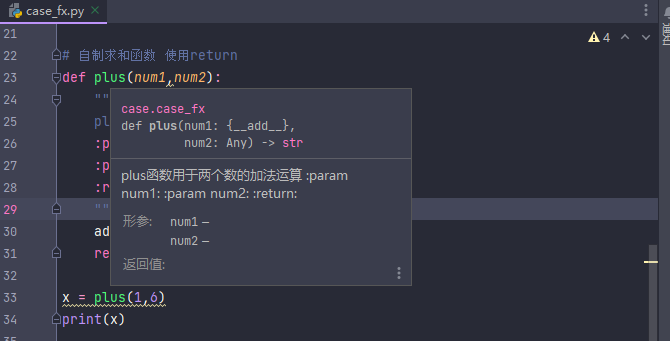
# 自制求和函数 输入三次引号再加回车即可生成说明文档
def plus(num1,num2):
"""
plus函数用于两个数的加法运算
:param num1: 传入第一个加数
:param num2: 传入第二个加数
:return: 返回值
"""
add = f"{num1}+{num2}={num1+num2}"
return add
x = plus(1,6)
print(x)
5.3 函数的嵌套调用
在一个函数的函数体中调用另一个函数,如以下实例,执行函数b时,先执行函数a的内容,再继续执行函数b剩余的内容。
def a(): # 定义第一个函数a
print("---a---")
def b(): # 定义第二个函数b
a() # 在函数体中嵌套调用函数a
print("---b---")
b() # 输出调用函数b
----------------------------------------------------------------------
---a--- | 调用函数b执行结果同时输出函数a和b
---b--- |
5.4 变量在函数中的作用域
变量的作用域是指变量的作用范围;主要分局部变量和全局变量。
1.局部变量:定义在函数体内部的变量,即只在函数体内部生效。
作 用:在函数运行时临时存储数据,完成调用后就会被销毁。
# 局部变量举例
def test():
num = 10 # 定义一个局部变量
print(num)
test() # 输出10
print(num) # 输出报错,因为num是函数内的局部变量
2.全局变量:在函数体内外都能生效的变量。
作 用:
# 全局变量举例
num = 100 # 定义一个全局变量
def a():
print(num) # 在函数a中调用该变量
def b():b
print(num) # 在函数b中调用该变量
a() # 调用函数a输出,结果为100
b() # 调用函数b输出,结果为100
print(num) # 直接输出变量,结果为100
global关键字
用于将局部变量转换为全局变量
# global关键字举例
num = 100 # ① 定义一个全局变量
def a():
num = 500 # ② 在函数中将num变量值更改为500
print(num)
a() # 调用该函数输出结果为500
print(num) # 直接输出该变量,结果还是100,因为②处相当于在函数a中定义了一 个局部变量,故结果未发生改变
-----------------------------------------------------------------
num = 100 # ① 定义一个全局变量
def a():
global num # ② 将局部变量声明为全局变量
num = 500 # ③ 在函数中将num变量值更改为500
print(num)
a() # 调用该函数输出结果为500
print(num) # 直接输出该变量,结果变为500,因为②处将num声明成了全局变 量,故结果发生改变
5.5 综合案例 ATM机
要求:
1.灵活使用全局变量和局部变量,实现用户登陆后的存取款和查询打印业务。
2.定义函数:主菜单、存款、取款、查询、打印。
3.程序启动后要求客户输入用户名
4.符合一定的现实ATM机逻辑
import datetime # 导入时间函数
balance = 0.00 # 初始余额为零
name = None # 用户名
now = datetime.datetime.now() # 调用时间函数
business = None # 选择业务
deposit = 0.00 # 默认存款为零
withdrawal = 0.00 # 默认取款为零
# 定义主菜单函数
def menu(name):
print(f"{name},您好!欢迎来到子画银行", '\n',
now.strftime("%Y-%m-%d %H:%M"), '\n', '\t',
"余额查询 【1】", '\n''\t',
"存款业务 【2】", '\n''\t',
"取款业务 【3】", '\n''\t',
"打印凭条 【4】"'\n''\t',
"退 出 【5】"'\t')
global business # 声明为全局变量
business = int(input("请选择您的操作:")) # 选择业务
return business # 返回值
# 循环函数
def circulation():
flag = True
while flag:
operation = int(input("返回上级【1】 退出【2】"))
if operation == 1:
break
elif operation == 2:
print("感谢使用本行业务!")
flag = False
global flag_1
flag_1 = False
# 定义查询余额函数
def select():
print("-------------------- 查 询 -----------------------")
print("尊敬的%s!您的可用余额为%.2f" % (name, balance))
print(now.strftime("%Y-%m-%d %H:%M:%S"))
print()
circulation()
# 定义存款函数
def deposit_fx():
global deposit
print("-------------------- 存 款 -----------------------")
deposit = float(input(f"尊敬的{name}!您的存款金额为:"))
print(now.strftime("%Y-%m-%d %H:%M:%S"))
print("已为您生成业务流水....")
print()
global balance
balance += deposit
print("已为您存入\t%.2f" % deposit)
print("您的账户当前可用余额为\t%.2f" % balance)
print()
circulation()
# 定义取款函数
def withdrawal_fx():
global balance
global withdrawal
print("-------------------- 取 款 -----------------------")
flag = True
while flag:
withdrawal = float(input("请输入取款金额:"))
print()
if withdrawal > balance:
print("对不起!您的余额不足")
print()
operation = int(input("重新输入【1】 返回菜单【2】"))
if operation == 1:
continue
elif operation == 2:
break
if withdrawal <= balance:
balance -= withdrawal
print(now.strftime("%Y-%m-%d %H:%M:%S"))
print("出账:%.2f元"%withdrawal)
print("当前账户余额%.2f元"%balance)
print("已为您生成业务流水....")
print()
operation = int(input("继续取款【1】 返回菜单【2】"))
if operation == 1:
continue
elif operation == 2:
print()
print("感谢使用本行业务!")
print()
break
# 定义打印函数
def receipts():
print("凭条打印中……………………")
print('\n''\n''\n')
print("=================================")
print(" 字画银行业务明细账单 ")
print(f"用户:{name}", now.strftime("%Y-%m-%d %H:%M:%S"))
print("*********************************")
print("动账信息:存入:%.2f 支出:%.2f" % (deposit, withdrawal))
print("当前余额:%2.f" % balance)
print(" 感谢使用本行业务!")
print('\n''\n''\n')
circulation()
# case
print("-------------------- 登 录 -----------------------")
name = input("请输入用户名")
print()
flag_1 = True
while flag_1:
business = menu(name)
print()
if business == 1:
select()
print()
elif business == 2:
deposit_fx()
print()
elif business == 3:
withdrawal_fx()
print()
elif business == 4:
receipts()
print()
elif business == 5:
break
print("感谢使用本行业务!")
else:
print("请规范输入对应选项的序号!")
第六章 数据容器
6.1 数据容器入门
Python 中的数据容器:
一种可以容纳多份数据的数据类型,容纳的每一份数据称之为1个元素;
元素可以是任意类型的数据,如字符串、数字、布尔等。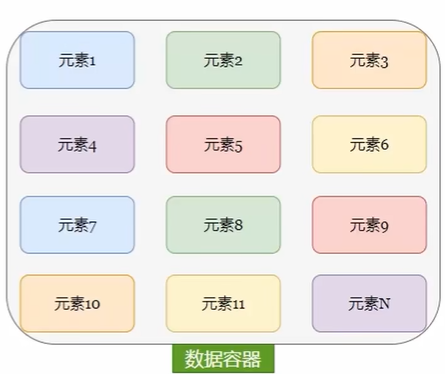
容器分为5类:
列表(list)、元组(tuple)、字符串(str)、集合(set)、字典(dict)
6.2 列表 list
· 可容纳多个元素(上限为2**63-1个)
· 可以容纳不同类型的元素(混装)
· 数据是有序存储的(有下标索引)
· 允许重复数据的存在
· 可以修改数据内容
6.2.1 列表的定义
# 字面量
[元素1,元素2,元素3,元素n....]
# 定义变量
变量名 = [元素1,元素2,元素3,元素n....]
# 定义空列表
变量名 = []
变量名 = list()
________________________
列表内每一个数据称为元素
· 以 [] 为标识
· 列表内元素用逗号隔开
列表内一次可存储多个数据,且可以为不同的数据类型,支持嵌套。
# 定义一个列表
list_0 = ['a','b','c'] # 相同数据类型
list_1 = ['java',100,3.14,True] # 不相同数据类型
# 定义一个嵌套的列表
list_2 = [list_1,['java',3.14,True],555,3.14,333]
print(list_2)
print(type(list_2))
6.2.2 列表的下标索引



# 定义一个嵌套的列表
list_1 = ['java',100,3.14,True]
list_2 = [list_1,['java',3.14,True],555,3.14] # 嵌套列表
print(list_2)
print(type(list_2))
——————————————
[['java', 100, 3.14, True], ['java', 3.14, True], 555, 3.14]
<class 'list'>
# 通过下标索引取出对应位置的数据(顺序)
list_1 = ['java',100,3.14,True]
print(list_1[2])
————————————————
3.14
# 通过下标索引取出对应位置的数据(倒序)
list_1 = ['java',100,3.14,True]
print(list_1[-2])
—————————————————
3.14
# 通过下标索引取出对应位置的列表(倒序)
list_1 = ['java',100,3.14,True]
list_2 = [list_1,['java',3.14,True],555,3.14,333]
print(list_2[0])
——————————————————
['java', 100, 3.14, True]
# 取出嵌套列表的元素
list_1 = ['java',100,3.14,True]
list_2 = [list_1,['java',3.14,True],555,3.14]
print(list_2)
—————————————————
[['java', 100, 3.14, True], ['java', 3.14, True], [555, 3.14, 333]]
6.2.3 列表的常用操作
1.列表的查询功能(方法)
用于查找指定元素在列表的下标(Value报错即为找不到)。
语法:列表.index(元素)
index是列表对象(变量)内置的方法(函数)
list_1 = ['java',100,3.14,True]
print(list_1.index(100))
________________________________________________
1
list_1 = ['java',100,3.14,True]
print(list_1.index(10))
________________________________________________
ValueError: 10 is not in list
# 语法:列表[下标]
list_1 = ['java',100,3.14,True]
print(list_1[0])
________________________________________________
java
-
修改特定位置(索引)的元素
语法:列表[下标] = 值
list_1 = ['java',100,3.14,True]
print( "修改前的list_1:",list_1)
list_1[0] = 'Python' # 正向
print( "修改后的list_1:",list_1)
________________________________________________
修改前的list_1: ['java', 100, 3.14, True]
修改后的list_1: ['Python', 100, 3.14, True]
list_1 = ['java',100,3.14,True]
print( "修改前的list_1:",list_1)
list_1[-4] = 'Python' # 反向
print( "修改后的list_1:",list_1)
________________________________________________
修改前的list_1: ['java', 100, 3.14, True]
修改后的list_1: ['Python', 100, 3.14, True]
-
插入元素
语法:列表.insert(下标,元素)
用于在指定的下标位置,插入指定的元素。
list_1 = ['java',100,3.14,True]
print( "插入前的list_1:",list_1)
list_1.insert(0,'Python')
print( "插入后的list_1:",list_1)
________________________________________________
插入前的list_1: ['java', 100, 3.14, True]
插入后的list_1: ['Python', 'java', 100, 3.14, True]
-
追加元素
语法:列表.append(元素)
用于将指定单个元素追加到列表的尾部。
list_1 = ['java',100,3.14,True]
print( "追加前的list_1:",list_1)
list_1.append('Python')
print( "追加后的list_1:",list_1)
________________________________________________
追加前的list_1: ['java', 100, 3.14, True]
追加后的list_1: ['java', 100, 3.14, True, 'Python']
-
列表的修改功能(方法)
语法:列表.extend(其他数据容器)
将指定数据容器的内容取出,依次追加到列表尾部
list_0 = ['a','b','c','c','c']
list_3 = [1,2,3]
print("list_0更改前:",list_0)
list_0.extend(list_3)
print("list_0更改后:",list_0)
________________________________________________
list_0更改前: ['a', 'b', 'c', 'c', 'c']
list_0更改后: ['a', 'b', 'c', 'c', 'c', 1, 2, 3]
-
删除元素
语法1:del列表[下标]
list_1 = ['java',100,3.14,True]
print("lins_1的值为:",list_1)
del list_1[0]
print( "删除list_1的第0个元素:",list_1)
________________________________________________
lins_1的值为: ['java', 100, 3.14, True]
删除list_1的第0个元素: [100, 3.14, True]
语法2:列表.pop(下标)
list_1 = ['java',100,3.14,True]
print("lins_1的值为:",list_1)
list_1.pop(0)
print( "删除list_1的第0个元素:",list_1)
________________________________________________
lins_1的值为: ['java', 100, 3.14, True]
删除list_1的第0个元素: [100, 3.14, True]
-
删除某元素在列表中的某一个匹配项
语法:列表.remove(元素)
list_1 = ['java',100,3.14,True]
print("lins_1的值为:",list_1)
list_1.remove('java')
print( "删除list_1的'java'元素:",list_1)
________________________________________________
lins_1的值为: ['java', 100, 3.14, True]
删除list_1的'java'元素: [100, 3.14, True]
-
清空列表内容
语法:列表.clear()
list_1 = ['java',100,3.14,True]
print("lins_1的值为:",list_1)
list_1.clear()
print( "清空list_1后:",list_1) # 剩余一个无内容的空列表
________________________________________________
lins_1的值为: ['java', 100, 3.14, True]
清空list_1后: []
-
统计某元素在列表内的数量
语法:列表.cont(元素)
list_0 = ['a','b','c','c','c']
print("lins_0的值为:",list_0)
quantity = list_0.count('c')
print("列表lins_0中‘c‘元素的数量为:",quantity)
________________________________________________
lins_0的值为: ['a', 'b', 'c', 'c', 'c']
列表lins_0中‘c‘元素的数量为: 3
- 统计列表中全部元素的数量
语法:len(列表)
list_0 = ['a','b','c','c','c']
print("lins_0的值为:",list_0)
quantity = len(list_0)
print("列表lins_0中元素的数量为:",quantity)
________________________________________________
lins_0的值为: ['a', 'b', 'c', 'c', 'c']
列表lins_0中元素的数量为: 5
进程已结束,退出代码0
6.2.4 方法总览:
| 方 法 | 作 用 |
|---|---|
| 列表.append( 元素 ) | 向列表末尾追加一个元素 |
| 列表.extend( 容器 ) | 将数据容器的内容依次取出,追加到列表尾部 |
| 列表.insert( 下标,元素 ) | 在指定下标处,插入指定的元素 |
| del 列表[ 下标 ] | 删除列表指定的下标元素 |
| 列表.pop( 下标 ) | 删除列表指定的下标元素 |
| 列表.remove( 元素 ) | 从前向后,删除元素第一个匹配项 |
| 列表.clear( ) | 清空列表 |
| 列表.count( 元素 ) | 统计此元素在列表中出现的次数 |
| 列表.index( 元素 ) | 查找指定元素所在列表的下标 找不到即报错Value Error |
| len( 列表 ) | 统计容器内有多少元素 |
6.2.4 案例练习
# 列表内容:[21,25,21,23,22,20],记录的是一批学生的年龄
# 通过列表的功能(方法),对其进行如下操作:
# 1.定义这个列表,并用变量接收它
student_age = [21,25,21,23,22,30]
# 2.追加一个数字31,到列表的尾部
print("case_1:",student_age)
student_age.append(31)
# 3.追加一个新列表[29,33,30],到列表尾部
student_age.append([29,33,30])
print("case_2:",student_age)
# 4.取出第一个元素(21)
print("case_3:",student_age[0])
# 5.取出最后一个元素(30)
print("case_4:",student_age[5])
# 6.查找元素31所对应的下标索引
print("case_5:",student_age.index(31))
——————————————————————————————————————————————————————————
case_1: [21, 25, 21, 23, 22, 30]
case_2: [21, 25, 21, 23, 22, 30, 31, [29, 33, 30]]
case_3: 21
case_4: 30
case_5: 6
进程已结束,退出代码0
6.2.5 列表的循环遍历
1.将容器内的元素依次取出进行处理的行为称为:遍历、迭代。
2.1 使用 while 循环遍历
# 使用 `列表[下标]` 取出元素
# 定义一个变量表示下标,从0开始,循环条件为 下标值 < 列表的元素数量
index = 0
while index < len(列表):
元素 = 列表[index]
对元素进行处理
index += 1
# 循环控制变量通过下标索引控制
# 每一次循环将下标索引变量+1
# 循环条件:下标索隐变量<列表元素数量
student_age = [11,12,13,14,15,16,17]
indexes = 0 # 定义一个变量标记列表下标
while indexes < len(student_age): # 下标索引 < 元素数量
print(student_age[indexes])
indexes += 1
——————————————————————————————————————————
11
12
13
14
15
16
17
进程已结束,退出代码0
2.2 使用 for 循环遍历
表示从容器中依次取出元素,并赋值到临时变量上;在每一次循环中,可以对临时变量(元素)进行处理。
for 临时变量 in数据容器:
对临时变量进行处理
student_age = [11,12,13,14,15,16,17]
for x in student_age:
print(x)
——————————————————————————————————————————
11
12
13
14
15
16
17
进程已结束,退出代码0
3.while 循环和 for 循环的区别
| While | For | |
|---|---|---|
| 在循环控制上 | 可自定义循环条件,并且自行控制 | 不可以自定义循环条件,只可以一个个从容器中取出数据 |
| 在无限循环上 | 可以通过条件控制实现无限循环 | 理论上不能实现,因为被遍历的容器容量不是无限的 |
| 使用场景上 | 适用于任何想要循环的场景 | 适用于遍历数据容器的场景或简单的固定次数循环场景 |
4.案例练习
# 定义一个列表:[1,2,3,4,5,6,7,8,9,10]
# 分别使用两种方法遍历该列表,取出其中的偶数,并存入一个新的列表对象中
case_list = [1,2,3,4,5,6,7,8,9,10]
even_list = []
# while
indexes = 0
while indexes < len(case_list):
values = case_list[indexes]
if values % 2 == 0:
even_list.append(values)
indexes += 1
print(even_list)
# for
for x in case_list:
if x % 2 == 0:
even_list.append(x)
x += 1
print(even_list)
——————————————————————————————————————
[2, 4, 6, 8, 10]
[2, 4, 6, 8, 10, 2, 4, 6, 8, 10] # 因为经历了两次循环的数据追加,故有两次
进程已结束,退出代码0
6.3 元组 tuple
· 元组不可被修改!
· 可以容纳不同类型的数据
· 数据是有序存储的(下标索引)
· 允许重复数据的存在
· 支持 for 循环
6.3.1 元组的定义
定义元组使用小括号,且使用逗号隔开各个数据,可以存储数据类型不同的数据。
# 定义元组字面量
(元素,元素,元素,......)
# 定义元组变量
变量名 = (元素,元素,元素,......) | tuple_1 = (1,'abc',True)
# 定义空元组(两种方法)
变量名 = () | tuple_1 = ()
变量名 = tuple() | tuple_2 = tuple()
# 定义单个元素的元组(注意:单个元素时,结尾必须带逗号,否则不是元组类型)
变量名 = (元素,) | tuple_1 = ('abc',)
tuple_1 = (3,'abc',True)
tuple_2 = tuple()
tuple_4 = (tuple_1,tuple_2,(1,2,3)) # 嵌套
print(tuple_4)
——————————————————————————————————————————————————
((1, 'abc', True), (),(1,2,3))
进程已结束,退出代码0
6.3.2 元组的操作
- 通过下标索引取出内容语法:元组变量名[下标]
tuple_4 = ((3, 'abc', True), (),(1,2,3))
value = tuple_4[0]
print(value)
——————————————————————————————————————————————————
(1, 'abc', True)
进程已结束,退出代码0
-
查找某个数据(若存在则返回对应的下标,否则报错)
语法:元组.index(元素)
tuple_1 = (3, 'abc', True)
value = tuple_1.index('abc')
print(value)
__________________________
1
进程已结束,退出代码0
-
统计某个数据在当前元组出现的次数
语法:元组.count(元素)
tuple_1 = (3, 'abc', True)
value = tuple_1.count('abc')
print(value)
__________________________
1
进程已结束,退出代码0
-
统计元组内元素个数
语法:len(元组)
tuple_1 = (3, 'abc', True)
value = len(tuple_1)
print(value)
__________________________
3
进程已结束,退出代码0
-
修改元组内列表的内容
语法:元组[列表在元组中的下标] [列表中对应值的下标] = 值
student = ('王梓骅',11,["computer","music"])
print("修改前的student:",student)
del student[2][1] # 删除列表中索引为1的值
print("修改后的student:",student)
__________________________
修改前的student: ('王梓骅', 11, ['computer', 'music'])
修改后的student: ('王梓骅', 11, ['computer'])
进程已结束,退出代码0
6.3.3 元组的遍历
tuple_7 = (1,2,3,4,5,6,7,8,9)
for x in tuple_7:
print(x)
x += 1
__________________________
1
2
3
4
5
6
7
8
9
进程已结束,退出代码0
tuple_7 = (1,2,3,4,5,6,7,8,9)
indexes = 0
while indexes < len(tuple_7):
value = tuple_7[indexes]
print(value)
indexes += 1
__________________________
1
2
3
4
5
6
7
8
9
进程已结束,退出代码0
6.3.3 案例练习
# 定义一个元组存储学生信息('小明',11,["computer","music"]),分别对应姓名、年龄、爱好
student = ('小明',11,["computer","music"])
# 通过元组的功能(方法),对其进行如下操作
# 1.查询其年龄所在的下标位置
age_indexes = student.index(11)
print("case1:",age_indexes)
# 2.查询学生姓名
name = student[0]
print("case2:",name)
# 3.删除学生爱好中的music
print("修改前的student:",student)
del student[2][1]
print("修改后的student:",student)
# 4.增加爱好coding
print("修改前的student:",student)
student[2].append("coding")
print("修改后的student:",student)
————————————————————————————————————————————
case1: 1
case2: 小明
修改前的student: ('小明', 11, ['computer', 'music'])
修改后的student: ('小明', 11, ['computer'])
修改前的student: ('小明', 11, ['computer'])
修改后的student: ('小明', 11, ['computer', 'coding'])
进程已结束,退出代码0
6.4 字符串 str

· 字符串是一个无法修改的数据容器。
· 只可以存储字符串
· 长度任意(取决于内存大小)
· 支持下标索引
· 允许重复字符串存在
· 支持 for 循环
6.4.1 字符串常用操作
- 通过下标索引取值
str1 = "Holl Word"
print("str1的第0位是",str1[0]) # 顺序从0开始
print("str1的第-4位是",str1[-4]) # 倒序从-1开始
————————————————————————————
str1的第0位是 H
str1的第-4位是 W
进程已结束,退出代码0
- index 方法
str1 = "Holl Word"
indexes = str1.index("H")
print("str1中‘H’的索引下标是",indexes)
————————————————————————————
str1中‘H’的索引下标是 0
进程已结束,退出代码0
-
字符串替换
语法:字符串.replace(字符串1,字符串2)
功能:将字符串内全部的字符串1替换成字符串2
注意:不是修改字符串本身,而是得到了一个新字符串
str1 = "Holl Word"
print("str1字符串替换前:",str1)
value = str1.replace("o","1")
print("str1字符串替换前:",value)
————————————————————————————
str1字符串替换前: Holl Word
str1字符串替换前: H1ll W1rd
进程已结束,退出代码0
-
字符串分割
语法:字符串.split(分隔符字符串)
功能:按照指定的分隔符字符串,将字符串划分为多个字符串,存入列表对象中
注意:字符串本身不变,而是得到了一个列表对象
str1 = "java python c++ c# go"
value = str1.split(" ") # 按照空格分开
print(value)
—————————————————————————————
['java', 'python', 'c++', 'c#', 'go']
进程已结束,退出代码0
a = "123123123123"
print(a.split("3"))
print(a.split("3",3))
—————————————————————————————
['12', '12', '12', '12', '']
['12', '12', '12', '123']
进程已结束,退出代码0
-
字符串的规整操作
语法1(去除前后空格):字符串.strip()
语法2(去除前后指定字符串):字符串.strip(字符串)
str1 = " over java python c++ go "
s1 = str1.strip() # 语法1:默认规整空格
s2 = str1.strip(" o ") # 语法2:指定规整的字符和空格
print("语法1的值",s1)
print("语法2的值",s2)
————————————————————————————————————
语法1的值 over java python c++ go # 开头结尾的空格已被规整去除
语法2的值 ver java python c++ g # 去除了首尾的字符和空格
进程已结束,退出代码0
- 统计字符串中某字符串出现的次数
str1 = "over java python c++ go"
count = str1.count("o")
print(f"str1中字母o出现了{count}次")
————————————————————————————————————
str1中字母o出现了3次
进程已结束,退出代码0
- 删除字符串中指定连续字符
a = "11111 1 123123 1 1111"
print(a.rstrip("1")) # 删除右边连续的字符“1”
print(a.lstrip("1")) # 删除左边连续的字符“1”
————————————————————————————————————
11111 1 123123 1
1 123123 1 1111
进程已结束,退出代码0
- 统计字符串长度
str1 = "over java python c++ go"
count = len(str1)
print(f"str1中有{count}个字符")
————————————————————————————————————
str1中有23个字符
进程已结束,退出代码0
6.4.2 字符串遍历
str1 = "Holl Word"
for x in str1:
print(x)
————————————————————————————
H
o
l
l
W
o
r
d
进程已结束,退出代码0
str1 = "Holl Word"
indexes = 0
while indexes < len(str1):
value = str1[indexes]
print(value)
indexes += 1
————————————————————————————
H
o
l
l
W
o
r
d
进程已结束,退出代码0
6.4.3 方法总览
| 操作 | 说明 |
|---|---|
| 字符串[ 下标 ] | 根据下标索引取出指定位置的字符 |
| 字符串.index( 字符串 ) | 查询指定字符的下标 |
| 字符串.replace( 字符串1,字符串2,number ) | 从左往右,将字符串1替换为字符串2(不会修改原字符串,而是得到一个新的字符串) number为代替的个数,不写时默认为-1(全部的意思) |
| 字符串.split( 字符串 ,number) | 按照给定字符串,对字符串进行分隔,不会修改原字符串,而是得到一个新的列表 number为分割的次数,不写时默认为-1(全部的意思) |
| 字符串.strip( ) 字符串.strip( 字符串 ) | 移除首尾的空格和换行符或指定字符串 |
| 字符串.rstrip( 字符 ) | 只删除右边指定连续字符 |
| 字符串.lstrip( 字符 ) | 只删除左边指定连续字符 |
| 字符串.count( 字符串 ) | 统计字符串内某字符串的出现次数 |
| 字符串.upper() | 字符串的字母全改为大写 |
| 字符串.lower() | 字符串的字母全改为小写 |
| 字符串.title() | 字符串每个单词(空格区分)的首字母大写(类似大驼峰法) |
| 字符串.find(字符) | 查询字符串中是否含有该字符(-1为不存在),输出该字符在字符串中的下标索引 |
| 字符串.endswith(字符) | 查询字符串结尾是否含义该字符,输出bool值(常用于判断文件后缀) |
| 字符串.isdigit() | 判断字符串是否为纯数字组成,输出bool值(常用作str转int时做判断) |
| len( 字符串 ) | 统计字符串发字符个数 |
6.4.4 案例练习
# 定义一个字符串存储"itheima itcast bixuegu"
str1 = "itheima itcast bixuegu"
# 统计字符串内有多少个“it”字符
count = str1.count("it")
print(f"str1中有 {count} 个it字符")
# 将字符串内的空格全部替换为“|”
str_replace = str1.replace(" ","|")
print(f"替换后:{str_replace}")
# 按照“|”分割字符串,得到列表
separator = str_replace.split("|")
print(f"分隔后:{separator}")
——————————————————————————————————————————————
str1中有 2 个it字符
替换后:itheima|itcast|bixuegu
分隔后:['itheima', 'itcast', 'bixuegu']
进程已结束,退出代码0
6.4.5 [扩] 字符串的大小比较
- ASCII 码字符串进行比较时就是基于字符串对应的码值大小进行比较的
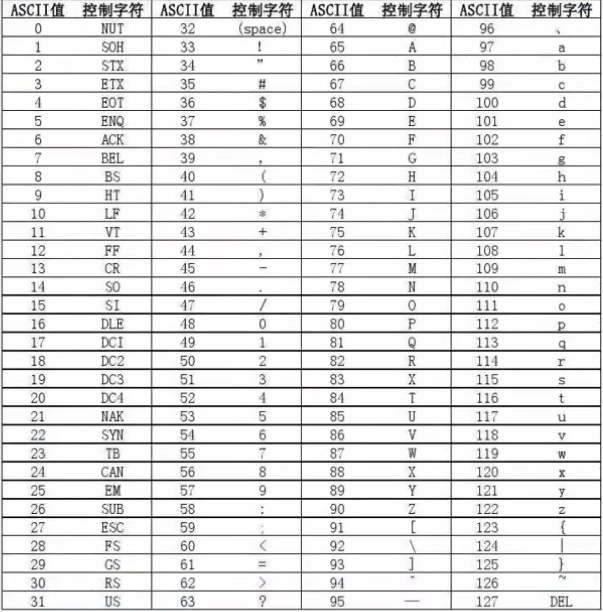
- 字符串是按位比较的,只要一位大,那么整体都大。

print(f"abc < abd: {'abc' < 'bcd'}")
print(f"abc > abd: {'abc' > 'bcd'}")
————————————————————————————————————————————————————————
abc < abd: True
abc > abd: False
进程已结束,退出代码0
6.5 序列的切片
序列:内容连续、有序,支持下标索引的一类数据容器
序列支持切片,即:列表、元组、字符串均支持进行切片操作。
切片: 从一个序列中,取出一个子序列
语法:序列[ 起始下标 : 结束下标 : 步长 ]
注意:切片操作不会影响序列本身,而是会得到一个新的序列
表示从序列中,从指定位置开始依次取出元素,到指定位置结束,得到一个新的序列
序列[ 起始下标 : 结束下标 : 步长 ]
indexse[x:y:n]
x:y 表示元素范围索引,不包括y(可以留空,留空表示开头结尾)
步长n为1时表示挨个取元素
步长n为2时,每次跳过一个元素
步长为n时,每次跳过n-1个元素,取下一个
步长为负数表示反向取,结尾处从-1开始(x和y也要反向取)
#print(表名[x:y:z])
# 输出结果为[第x位,去除首位的第z位];范围为x到y,不包含y,第x位,z-1的下一位...]
#
# 对list进行切片,从头开始,到最后结束,步长1
list_1 = [0,1,2,3,4,5,6]
case_1 = list_1[ : :1]
print(f"case_1:{case_1}") # [0,1,2,3,4,5,6]
# 对tuple进行切片,从头开始,到最后结束,步长1
tuple_1 = (0,1,2,3,4,5,6)
case_2 = tuple_1[ : :1]
print(f"case_2:{case_2}") # (0,1,2,3,4,5,6)
# 对str进行切片,从头开始,到最后结束,步长2
str_1 = "0123456"
case_3 = str_1[ : :2]
print(f"case_3:{case_3}") # 0246
# 对str进行切片,从头开始到最后结束,步长-1
str_1 = "0123456"
case_4 = str_1[ : :-1] # 步长为负数时倒序取值
print(f"case_4:{case_4}") # 6543210
# 对列表进行切片,从3开始,到1结束,步长-1
list_1 = [0,1,2,3,4,5,6]
case_5 = list_1[3:1:-1]
print(f"case_5:{case_5}") # [3,2]
# 对元组进行切片,,从头开始,到最后结束,步长-2
tuple_1 = (0,1,2,3,4,5,6)
case_6 = tuple_1[ : :-2]
print(f"case_6:{case_6}") # (6,4,2,0)
——————————————————————————————————————————————————————————————————
case_1:[0, 1, 2, 3, 4, 5, 6]
case_2:(0, 1, 2, 3, 4, 5, 6)
case_3:0246
case_4:6543210
case_5:[3, 2]
case_6:(6, 4, 2, 0)
进程已结束,退出代码0
# 案例:取出“芜湖”
# 方法一
my_str = "游一此到子王小,湖芜"
value_1 = my_str.replace('游一此到子王小,','') # 使用replace将不需要内容替换为空
value_2 = value_1[::-1] # 将得到的内容切片倒序输出
print("方法一:",value_2)
# 方法二
value_3 = my_str[-1:-3:-1] # 将内容切片倒序输出
print("方法二:",value_3)
————————————————————————————————————————————————————
方法一: 芜湖
方法二: 芜湖
进程已结束,退出代码0
6.6 集合 set
6.6.1 集合的定义
# 定义集合字面量
{元素,元素,元素......}
# 定义集合变量
变量名 = {元素,元素,......}
# 定义空集合
变量名 = set()
6.6.2 集合的常用操作
集合是无序的,故此不支持下标索引访问,但可以修改。
- 添加新元素语法:集合.add(元素)作用:将指定元素添加到集合中结果:此操作修改的是集合本身,添加新元素
my_set = {1,2,3,4,5}
print("添加前:",my_set)
my_set.add("java")
print("添加后:",my_set)
———————————————————————————————————————
添加前: {1, 2, 3, 4, 5}
添加后: {1, 2, 3, 4, 5, 'java'}
进程已结束,退出代码0
-
移除元素
语法:集合.remove(元素)
作用:将指定元素从集合中移除
结果:此操作修改的是集合本身,移除某元素
my_set = {1, 2, 3, 4, 5, 'java'}
print("移除前:",my_set)
my_set.remove("java")
print("移除后:",my_set)
————————————————————————————————————————
移除前: {1, 2, 3, 4, 5, 'java'}
移除后: {1, 2, 3, 4, 5}
- 取出元素.
语法:集合.pop()
作用:从集合中随机取出一个元素
结果:会得到一个元素结果。同时集合本身会被修改,元素被移除。
my_set = {1,2,3,4,5,6}
print(f"初始my_set为{my_set}")
value = my_set.pop()
print(f"my_set集合中随机取出一个元素:{value}")
print(f"随机取出一个元素后,my_set为{my_set}")
————————————————————————————————————————————————
初始my_set为{1, 2, 3, 4, 5, 6}
my_set集合中随机取出一个元素:1
随机取出一个元素后,my_set为{2, 3, 4, 5, 6}
进程已结束,退出代码0
- 清空集合
语法:集合.clear()
作用:清空集合
结果:集合本身被清空
my_set = {1,2,3,4,5,6}
print(f"初始my_set为{my_set}")
value = my_set.clear()
print(f"清空集合后,my_set为{my_set}")
——————————————————————————————————————————————————
初始my_set为{1, 2, 3, 4, 5, 6}
清空集合后,my_set为set()
进程已结束,退出代码0
- 取出2个集合的差集
语法:集合1.difference( 集合2 )
作用:取出集合1和集合2的差集(集合1有而集合2没有的)
结果:得到一个新的集合,集合1和集合2不变
set_1 = {1,2,3,4,5,6}
set_2 = {1,3,5}
value = set_1.difference(set_2)
print(f"set_1和set_2的差集为{value}")
print(f"set_1:{set_1}")
print(f"set_2:{set_2}") # 差集运算不影响原集合
——————————————————————————————————————————
set_1和set_2的差集为{2, 4, 6}
set_1:{1, 2, 3, 4, 5, 6}
set_2:{1, 3, 5}
进程已结束,退出代码0
- 消除2个集合的差集
语法:集合1.difference_update(集合2)
功能:对比集合1和集合2,在集合1内,删除和集合2相同的元素结果:集合1被修改,集合2不变
set_1 = {1,2,3,4,5,6}
set_2 = {1,3,5}
print(f"初始set_1为{set_1}")
print(f"初始set_2为{set_2}")
value = set_1.difference_update(set_2) # 删除和集合2相同的元素
print(f"消除差集后set_1为{set_1}")
print(f"消除差集后set_2为{set_2}")
——————————————————————————————————————————————————
初始set_1为{1, 2, 3, 4, 5, 6}
初始set_2为{1, 3, 5}
消除差集后set_1为{2, 4, 6} #集合1被修改
消除差集后set_2为{1, 3, 5} #集合2不变
进程已结束,退出代码0
- 将2个集合合并
语法:集合1.union(集合2)
功能:将集合1和集合2组合成新集合(重复值只记录一次)
结果:得到新集合,集合1和集合2不变
set_1 = {1,2,3,4,5,6}
set_2 = {1,3,5}
values = set_1.union(set_2)
print(f"集合1为{set_1}")
print(f"集合2为{set_2}")
print(f"合并后的集合为{values}")
————————————————————————————————————————
集合1为{1, 2, 3, 4, 5, 6}
集合2为{1, 3, 5,7}
合并后的集合为{1, 2, 3, 4, 5, 6,7} # 重复值{1,3,5}只记录一次
进程已结束,退出代码0
- 统计集合元素数量语法:len( 集合 )
set_1 = {1,2,3,4,5,6}
set_2 = {1,2,3,4,5,6,1,2,3,4,5,6,7}
count_1 = len(set_1)
count_2 = len(set_2)
print(f"set_1中元素数量为{count_1}")
print(f"set_2中元素数量为{count_2}")
___________________________________
set_1中元素数量为6
set_2中元素数量为7 # 集合2中重复值{1,2,3,4,5,6}只记录一次,故结果为7
进程已结束,退出代码0
6.6.3 方法总览
| 操作 | 说明 |
|---|---|
| 集合.add( 元素 ) | 集合内添加一个元素 |
| 集合.remove( 元素 ) | 移除集合内指定的元素 |
| 集合.pop( ) | 从集合中随机取出一个元素 |
| 集合.clear( ) | 清空集合 |
| 集合1.difference( 集合2 ) | 得到一个新集合,内含2个集合的差集,原有集合的内容不变。 |
| 集合1.difference_update(集合2) | 在集合1中,删除集合2中存在的元素,集合1 被修改,集合2不变。 |
| 集合1.union( 集合2 ) | 得到一个新集合,内含2个集合的全部元素,原有的2个集合内容不变 |
| 集合.remove(元素) 集合.discard(元素) | remove:删除元素,元素不存在即报错 discard:删除元素,元素不存在也不会报错 |
| set1 & set2 交集 set1 | set2 并集 set1 - set2 差集 | 交集:获取俩个集合相同的数值 并集:获取两个集合全部的数值 差集:获取左边集合中右边没有的数值 |
| len( 集合 ) | 得到一个整数,记录了集合的元素数量。 |
6.6.4 集合的遍历
集合是无序存储数据的,不支持下标索引,故无法使用while循环遍历
my_set = {1,2,3,4}
for x in my_set:
print(x)
——————————————————————————————————
1
2
3
4
进程已结束,退出代码0
6.7 字典、映射 dit
字典不能使用下标索引,但是可以通过Key值来取得对应的Value
字典不允许重复的key,重复添加会覆盖原数据
键值对 key 和 value 可以是任意类型(key不可为字典)
6.7.1 字典的定义
字典的定义使用 {} ,存储的是一个个的键值对
# 定义字典的字面量
{key:value,key:value,key:value......}
# 定义字典变量
变量名 = {key:value,key:value,key:value......}
# 定义空字典
变量名 = {}
变量名 = dict()
# 定义字典
my_dict1 = {'wang':19,'zhang':12,'li':17}
print(f"my_dict1:{my_dict1}")
# 定义空字典
my_dict2 = dict()
my_dict3 = {}
print(f"my_dict2:{my_dict2}")
print(f"my_dict3:{my_dict3}")
————————————————————————————————————————————————————
my_dict1:{'wang': 19, 'zhang': 12, 'li': 17}
my_dict2:{}
my_dict3:{}
进程已结束,退出代码0
# 定义重复Key的字典
my_dict1 = {'wang':19,'zhang':12,'li':17,'zhang':190}
print(f"my_dict1:{my_dict1}")
# 重复定义了相同的‘zhang’键不同的值,后者值‘190’会覆盖前面的‘12’
——————————————————————————————————————————————————————
my_dict1:{'wang': 19, 'zhang': 190, 'li': 17}
进程已结束,退出代码0
# 基于Key值获取Value
my_dict1 = {'wang':19,'zhang':12,'li':17}
value = my_dict1['wang']
print(f"'wang'对应的value是{value}")
———————————————————————————————————————————————————————
'wang'对应的value是19
进程已结束,退出代码0
6.7.2 嵌套字典
#将如下成绩单存储为字典
# +--------+------------+--------+---------+
# | 姓名 | Chinese | math | englis |
# +--------+------------+--------+---------+
# | wang | 77 | 66 | 33 |
# +--------+------------+--------+---------+
# | zhou | 88 | 86 | 55 |
# +--------+------------+--------+---------+
# | huang | 99 | 96 | 66 |
# +--------+------------+--------+---------+
# 定义嵌套字典
grade = {
# 姓名为Key,信息为value
'wang':{'chinese':77,'math':66,'english':33},
'zhou':{'chinese':88,'math':86,'english':55},
'huang':{'chinese':99,'math':96,'english':66}
}
# 从嵌套字典中获取数据
value = grade['wang']['math'] # 变量名 = 字典[外层key][内层key]
print(f"Wang同学的数学成绩是{value}")
—————————————————————————————————————————————————————————————————————
Wang同学的数学成绩是66
进程已结束,退出代码0
6.7.3 字典的常用操作
- 新增元素
语法:字典[Key] = Value
结果:字典被修改,新增了元素
my_dict = {'wang':19,'zhang':12,'li':17}
print(f"修改前的my_dict{my_dict}")
my_dict['huang'] = 999
print(f"修改后的my_dict{my_dict}")
————————————————————————————————————————————————————
修改前的my_dict{'wang': 19, 'zhang': 12, 'li': 17}
修改后的my_dict{'wang': 19, 'zhang': 12, 'li': 17, 'huang': 999}
进程已结束,退出代码0
- 更新元素
语法:字典[Key] = Value # 若key存在即更新,不存在则新增
结果:字典被修改,元素被更新
注意:字典 Key 不可重复,故对已存在的 Key 执行上述操作,就是更新 Value 值
my_dict = {'wang':19,'zhang':12,'li':17}
print(f"修改前的my_dict{my_dict}")
my_dict['wang'] = 888
print(f"修改后的my_dict{my_dict}")
————————————————————————————————————————————————————
修改前的my_dict{'wang': 19, 'zhang': 12, 'li': 17}
修改后的my_dict{'wang': 888, 'zhang': 12, 'li': 17}
进程已结束,退出代码0
- 删除元素
语法:字典.pop( Key )
结果:获得指定的 Key 的 Value,同时字典被修改,指定 Key 的数据被删除。
grade = {'chinese':77,'math':66,'english':33}
print(f"修改前:{grade}")
grade.pop('math')
print(f"修改后:{grade}")
——————————————————————————————————————————————————
修改前:{'chinese': 77, 'math': 66, 'english': 33}
修改后:{'chinese': 77, 'english': 33}
进程已结束,退出代码0
- 清空字典
语法:字典.clear( )
结果:字典被修改,元素被清空
grade = {'chinese':77,'math':66,'english':33}
print(f"修改前:{grade}")
grade.clear()
print(f"修改后:{grade}")
————————————————————————————————————————————————————
修改前:{'chinese': 77, 'math': 66, 'english': 33}
修改后:{}
进程已结束,退出代码0
- 获取全部的 Key
语法:字典.keys( )
结果:得到字典中全部 Key
grade = {'chinese':77,'math':66,'english':33}
all_value = grade.keys()
print(type(all_value)) #<class 'dict_keys'>
print(all_value)
_________________________________________________________
<class 'dict_keys'>
dict_keys(['chinese', 'math', 'english'])
进程已结束,退出代码0
- 统计字典中元素数量语法:len( 字典 )
grade = {'chinese':77,'math':66,'english':33}
count = len(grade)
print(f"grade中元素数量:{count}")
_________________________________________________________
grade中元素数量:3
进程已结束,退出代码0
6.7.4 字典的遍历
grade = {'chinese':77,'math':66,'english':33}
all_key = grade.keys() # 取出所有key
for x in grade:
all_value = grade[x] # 取出所有value
print(f"{x}:{all_value}") # 组合成键值对
————————————————————————————————————————————————————————————————
chinese:77
math:66
english:33
进程已结束,退出代码0
i = {'Chinese':77,'math':66,'english':33}
for x in i: # 遍历出字典中所有的键
a = i[x] # 定义一个变量使用键匹配对应的值
print(f"{x}:{a}") # 组装输出
————————————————————————————————————————————————————————————————
chinese:77
math:66
english:33
进程已结束,退出代码0
6.7.5 方法总览
| 操作 | 说明 |
|---|---|
| 字典[ key ] | 获取指定key对应的value值 |
| 字典[ key ] = Value | 添加或更新键值对 |
| 字典.pop( Key ) | 取出Key对应的Value并在字典内删除此Key对应的键值对 |
| 字典.popitem() | 随机删除键值对(国内一般情况是删除最右边的一个键值对) |
| 字典.clear( ) | 清空字典 |
| 字典.clear( ) | 获取字典的全部key,可用于for循环遍历字典 |
| 字典.update( {key:value} ) | 1.字典中有相同Key值时update为更新操作 2.字典中没有相同Key值时update为新增操作 |
| del 字典 del 字典[Key] | 删除字典 删除字典指定键值对 |
| 字典.setdefault(key,default) | 设置默认值 不写default时默认为字典添加Key(Value为None) Key相同时无效果 |
| 字典.get(key,default=None) | Key值存在时返回Value值 Key值存在时:若没有设置default值就返回None,若设置了default值就返回设置的default值。 |
| 字典.items() | 获取字典全部Key值和Value值,以元组形式放在列表中 |
| 字典.values() | 获取字典的全部Value值,以列表形式输出 |
| 字典.keys() | 获取字典的全部Key值,以列表形式输出 |
| 变量名=字典2.fromkeys(keys,default=None) | 用于创建或者批量创建相同数值的字典,输出字典 (fromkeys本身无任何添加功能,需要另一个变量进行储存或相同变量名覆盖) |
| len( 字典 ) | 计算字典内的元素数量 |
6.7.6 案例练习
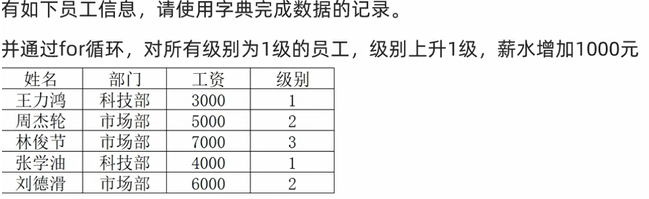
salary = {
"王力鸿":{'部门':'科技部','工资':3000,'级别':1},
"周杰轮":{'部门':'市场部','工资':5000,'级别':2},
"林俊节":{'部门':'市场部','工资':7000,'级别':3},
"张学油":{'部门':'科技部','工资':4000,'级别':1},
"刘德滑":{'部门':'市场部','工资':6000,'级别':2},
}
all_key = salary.keys() # 取出所有的key
for x in all_key: # 遍历所有的key
all_value = salary[x] # 取出单个key对应的value
k_v = f"{x}:{all_value}" # 格式化为键值对字符串
rank = all_value['级别'] # 定义一个变量存储’级别‘
if rank == 1: # 判断级别是否为1
all_value['级别'] += 1 # 级别为1时自增1
all_value['工资'] += 1000 # 级别为1时工资自增1000
print(salary,end='\n')
——————————————————————————————————————————————————————————————
{'王力鸿': {'部门': '科技部', '工资': 4000, '级别': 2}, '周杰轮': {'部门': '市场部', '工资': 5000, '级别': 2}, '林俊节': {'部门': '市场部', '工资': 7000, '级别': 3}, '张学油': {'部门': '科技部', '工资': 5000, '级别': 2}, '刘德滑': {'部门': '市场部', '工资': 6000, '级别': 2}}
进程已结束,退出代码0
salary = {
"王力鸿":{'部门':'科技部','工资':3000,'级别':1},
"周杰轮":{'部门':'市场部','工资':5000,'级别':2},
"林俊节":{'部门':'市场部','工资':7000,'级别':3},
"张学油":{'部门':'科技部','工资':4000,'级别':1},
"刘德滑":{'部门':'市场部','工资':6000,'级别':2},
}
for x in salary: # for 循环遍历字典
rank = salary[x]['级别'] # 定义“级别”变量
if rank == 1: # if判断级别符合条件的员工
salary[x]['级别'] += 1 # 级别自增1
salary[x]['工资'] += 1000 # 工资自增1000
print(salary) # 输出
——————————————————————————————————————————————————————————————
{'王力鸿': {'部门': '科技部', '工资': 4000, '级别': 2}, '周杰轮': {'部门': '市场部', '工资': 5000, '级别': 2}, '林俊节': {'部门': '市场部', '工资': 7000, '级别': 3}, '张学油': {'部门': '科技部', '工资': 5000, '级别': 2}, '刘德滑': {'部门': '市场部', '工资': 6000, '级别': 2}}
进程已结束,退出代码0
6.8 数据容器对比总结
- 容器的分类
| \ | 列表 | 元组 | 字符串 | 集合 | 字典 |
|---|---|---|---|---|---|
| 下标索引 | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| 重复元素 | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| 可以修改 | 支持 | 不支持 | 不支持 | 支持 | 支持 |
- 数据容器特点对比
| \ | 列表 | 元组 | 字符串 | 集合 | 字典 |
|---|---|---|---|---|---|
| 元素数量 | 支持多个 | 支持多个 | 支持多个 | 支持多个 | 支持多个 |
| 元素类型 | 任意 | 任意 | 仅字符 | 任意 | Key:Value kye:除字典外任意类型 value:任意类型 |
| 下标索引 | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| 重复元素 | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| 可修改性 | 支持 | 不支持 | 不支持 | 支持 | 支持 |
| 数据有序 | 是 | 是 | 是 | 否 | 否 |
| 使用场景 | 可修改、可重复的一批数据记录 | 不可修改、可重复的一批数据记录 | 一串字符的记录 | 不可重复的数据记录 | 以 Key 检索 Value 的数据记录 |
6.9 数据容器的通用操作
- 遍历
| 列表 | 元组 | 字符串 | 集合 | 字典 | |
|---|---|---|---|---|---|
| While | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| For | 支持 | 支持 | 支持 | 支持 | 支持 |
- 容器通用统计功能
- len( 容器 ):统计容器内的元素个数
my_list = [1,2,3,4,5,6]
my_tuple = (1,2,3,4,5,6)
my_str = 'abcdef'
my_set = {1,2,3,4,5,6}
my_dict = {'key1': 1,'key2': 2,'key3': 3,'key4': 4,'key5': 5,'key6': 6}
print(len(my_list))
print(len(my_tuple))
print(len(my_str))
print(len(my_set))
print(len(my_dict))
——————————————————————————————————
6
6
6
6
6
进程已结束,退出代码0
- max( 容器 ):统计容器内的最大元素
my_list = [1,2,3,4,5,6]
my_tuple = (1,2,3,4,5,6)
my_str = 'abcdef'
my_set = {1,2,3,4,5,6}
my_dict = {'key1': 1,'key2': 2,'key3': 3,'key4': 4,'key5': 5,'key6': 6}
print(max(my_list))
print(max(my_tuple))
print(max(my_str))
print(max(my_set))
print(max(my_dict))
——————————————————————————————————
6
6
f
6
key6
进程已结束,退出代码0
- min( 容器 ):统计容器内的最小元素
my_list = [1,2,3,4,5,6]
my_tuple = (1,2,3,4,5,6)
my_str = 'abcdef'
my_set = {1,2,3,4,5,6}
my_dict = {'key1': 1,'key2': 2,'key3': 3,'key4': 4,'key5': 5,'key6': 6}
print(min(my_list))
print(min(my_tuple))
print(min(my_str))
print(min(my_set))
print(min(my_dict))
——————————————————————————————————
1
1
a
1
key1
进程已结束,退出代码0
- 容器通用转换功能
- list( 容器 ):将给定容器转换为列表
my_list = [1,2,3,4,5,6]
my_tuple = (1,2,3,4,5,6)
my_str = 'abcdef'
my_set = {1,2,3,4,5,6}
my_dict = {'key1': 1,'key2': 2,'key3': 3,'key4': 4,'key5': 5,'key6': 6}
print(f"元组转列表:{list(my_tuple)}")
print(f"字符串转列表:{list(my_str)}")
print(f"集合转列表:{list(my_set)}")
print(f"字典转列表:{list(my_dict)}")
————————————————————————————————————————————————————————————————————————————
元组转列表:[1, 2, 3, 4, 5, 6]
字符串转列表:['a', 'b', 'c', 'd', 'e', 'f']
集合转列表:[1, 2, 3, 4, 5, 6]
字典转列表:['key1', 'key2', 'key3', 'key4', 'key5', 'key6']
进程已结束,退出代码0
- tuple( 容器 ):将给定容器转换为元组
my_list = [1,2,3,4,5,6]
my_tuple = (1,2,3,4,5,6)
my_str = 'abcdef'
my_set = {1,2,3,4,5,6}
my_dict = {'key1': 1,'key2': 2,'key3': 3,'key4': 4,'key5': 5,'key6': 6}
print(f"列表转元组:{tuple(my_list)}")
print(f"字符串转元组:{tuple(my_str)}")
print(f"集合转元组:{tuple(my_set)}")
print(f"字典转元组:{tuple(my_dict)}")
————————————————————————————————————————————————————————————————————————————
列表转元组:(1, 2, 3, 4, 5, 6)
字符串转元组:('a', 'b', 'c', 'd', 'e', 'f')
集合转元组:(1, 2, 3, 4, 5, 6)
字典转元组:('key1', 'key2', 'key3', 'key4', 'key5', 'key6')
进程已结束,退出代码0
- str( 容器 ):将给定容器转换为字符串
my_list = [1,2,3,4,5,6]
my_tuple = (1,2,3,4,5,6)
my_str = 'abcdef'
my_set = {1,2,3,4,5,6}
my_dict = {'key1': 1,'key2': 2,'key3': 3,'key4': 4,'key5': 5,'key6': 6}
print(f"列表转字符串:{str(my_list)}")
print(f"元组转字符串:{str(my_str)}")
print(f"集合转字符串:{str(my_set)}")
print(f"字典转字符串:{str(my_dict)}")
————————————————————————————————————————————————————————————————————————————
列表转字符串:[1, 2, 3, 4, 5, 6]
元组转字符串:abcdef
集合转字符串:{1, 2, 3, 4, 5, 6}
字典转字符串:{'key1': 1, 'key2': 2, 'key3': 3, 'key4': 4, 'key5': 5, 'key6': 6}
进程已结束,退出代码0
- set( 容器 ):将给定容器转换为集合
my_list = [1,2,3,4,5,6]
my_tuple = (1,2,3,4,5,6)
my_str = 'abcdef'
my_set = {1,2,3,4,5,6}
my_dict = {'key1': 1,'key2': 2,'key3': 3,'key4': 4,'key5': 5,'key6': 6}
print(f"列表转集合:{set(my_list)}")
print(f"元组转集合:{set(my_tuple)}")
print(f"字符串转集合:{set(my_str)}")
print(f"字典转集合:{set(my_dict)}")
————————————————————————————————————————————————————————————————————————————
列表转集合:{1, 2, 3, 4, 5, 6}
元组转集合:{1, 2, 3, 4, 5, 6}
字符串转集合:{'d', 'a', 'c', 'f', 'e', 'b'}
字典转集合:{'key1', 'key5', 'key6', 'key2', 'key3', 'key4'}
进程已结束,退出代码0
- 容器通用排序功能
sorted( 容器,[ reverse=True ] ) 将给定容器进行排序(结果以列表形式显示) [ reverse=True ] 是可选项,表示反转,不写就默认升序
my_list = [3,4,6,5,2,1]
my_tuple = (6,5,3,4,1,2)
my_str = 'facdbe'
my_set = {5,3,2,4,1,6}
my_dict = {'key3': 3,'key2': 2,'key4': 4,'key6': 6,'key5': 5,'key3': 3}
print(f"将列表升序排序{sorted(my_list)}")
print(f"将元组升序排序{sorted(my_tuple)}")
print(f"将字符串升序排序{sorted(my_str)}")
print(f"将集合升序排序{sorted(my_set)}")
print(f"将字典升序排序{sorted(my_dict)}")
——————————————————————————————————————————————————————————————————————
将列表升序排序[1, 2, 3, 4, 5, 6]
将元组升序排序[1, 2, 3, 4, 5, 6]
将字符串升序排序['a', 'b', 'c', 'd', 'e', 'f']
将集合升序排序[1, 2, 3, 4, 5, 6]
将字典升序排序['key2', 'key3', 'key4', 'key5', 'key6']
进程已结束,退出代码0
my_list = [3,4,6,5,2,1]
my_tuple = (6,5,3,4,1,2)
my_str = 'facdbe'
my_set = {5,3,2,4,1,6}
my_dict = {'key3': 3,'key2': 2,'key4': 4,'key6': 6,'key5': 5,'key3': 3}
print(f"将列表降序排序{sorted(my_list,reverse=True)}")
print(f"将元组降序排序{sorted(my_tuple,reverse=True)}")
print(f"将字符串降序排序{sorted(my_str,reverse=True)}")
print(f"将集合降序排序{sorted(my_set,reverse=True)}")
print(f"将字典降序排序{sorted(my_dict,reverse=True)}")
————————————————————————————————————————————————————————————————————
将列表降序排序[6, 5, 4, 3, 2, 1]
将元组降序排序[6, 5, 4, 3, 2, 1]
将字符串降序排序['f', 'e', 'd', 'c', 'b', 'a']
将集合降序排序[6, 5, 4, 3, 2, 1]
将字典降序排序['key6', 'key5', 'key4', 'key3', 'key2']
进程已结束,退出代码0
第七章 Python函数进阶
7.1 函数多返回值
def return_num(): # 定义函数
return 1,2 # 设置多个返回值,用逗号隔开,可设置不同类型
x,y = return_num() # 分别用两个值调用函数
print(x) # 按返回值顺序输出
print(y)
________________________________________________________
1
2
进程已结束,退出代码0
7.2 函数多种传参方式
函数参数种类
· 位置参数
· 关键字参数
· 缺省参数
· 不定长参数
7.2.1 位置参数
调用函数时根据函数定义的参数位置来传递参数(传递参数和定义的参数的顺序和个数必须一致)
def info(name,age,tel):
format = (f"学生姓名:{name} 年龄:{age} 电话:{tel}")
return format
student = info("wang",19,13108758920)
print(student)
————————————————————————————————————————————————————————————————————————
学生姓名:wang 年龄:19 电话:13108758920
进程已结束,退出代码0
7.2.2 关键字参数
调用时通过 “ 键 = 值 ” 的形式传递参数(如果有位置参数时,位置参数必须在关键字参数的前面)
关键字参数之间不存在先后顺序
def info(name,age,tel):
format = (f"学生姓名:{name} 年龄:{age} 电话:{tel}")
return format
student_1 = info(name = 'Wang',age = 19,tel = 13108758920)
student_2 = info(age = 19,name = 'Wang',tel = 13108758920)
student_3 = info('zhao',tel = 15750058427,age = 29)
# 位置参数必须在关键字参数的前面
print(student_1)
print(student_2)
print(student_3)
————————————————————————————————————————————————————————————————
学生姓名:Wang 年龄:19 电话:13108758920
学生姓名:Wang 年龄:19 电话:13108758920 # 不按顺序传参也可得到相同结果
学生姓名:zhao 年龄:29 电话:15750058427 # 位置参数和关键字参数混用不影响结果
进程已结束,退出代码0
7.2.3 缺省参数
也叫默认参数,用于定义函数,为参数提供默认值,调用函数时可不传该默认参数的值(所有位置参数必须出现在默认参数前,包括函数定义和调用)
def info(name,age ,tel = None): # tel默认为空(缺省参数只能定义在最后)
format = (f"学生姓名:{name} 年龄:{age} 电话:{tel}")
return format
student_1 = info(name = 'Wang',age = 19,tel = 13108758920)
student_2 = info(name = 'zhao',age = 29)
print(student_1)
print(student_2)
———————————————————————————————————————————————————————————————————————
学生姓名:Wang 年龄:19 电话:13108758920
学生姓名:zhao 年龄:29 电话:None # 当缺省参数无参数传入时会使用默认值输出
进程已结束,退出代码0
7.2.4 不定长参数
也叫做可变参数,用于不确定调用的时候会传递多少个参数(不传参也可以)的场景。
4.1 位置传递类型
传进的所有参数都会被 args 变量收集,它会根据传进参数的位置合并为一个元组(tuple),args 是元组类型。
def info(*args): # *表示数量不受限制
print(args)
user_1 = info('wang',19) # 可传入多个值,长度不受限制
——————————————————————————————————————————————————————————————————
('wang', 19) # 根据传进参数的位置合并为一个元组
进程已结束,退出代码0
4.2 关键字传递类型
参数是 ” 键 = 值 “ 形式的情况下,所有的 “ 键 = 值 ” 都会被 kwargs 接受,同时根据 “ 键 = 值 ” 组成字典
def info(**kwargs):
print(kwargs)
user_2 = info(name='wang',sex='男',tel=13108758920)
#长度不受限制,但必须KY对应
——————————————————————————————————————————————————————————————————
{'name': 'wang', 'sex': '男', 'tel': 13108758920} # 根据传入参数组成字典
进程已结束,退出代码0
7.3 匿名函数
7.3.1 函数作为参数传递
函数本身可以作为参数,传入另一个函数中使用;<br /> 作用是传入计算逻辑。
# func需要一个函数作为参数传入,这个函数需要接收2个数字进行计算,计算逻辑由这个被传入函数决定
def func(count): # count作为参数,传入到func函数中使用
sum = count(1,2) # count函数接收2个数字对其进行计算
print(sum)
def count(x,y):
return x+y
func(count)
——————————————————————————————————————————————————————
3
进程已结束,退出代码0
7.3.2 lambda 匿名函数
在函数的定义中:<br /> **·** def 关键字,可以定义**带有名称**的函数<br /> **·** lambda 关键字,可**定义匿名**函数(无名称)<br /> 有名称的函数,可以基于名称**重复使用**<br /> 无名称的匿名函数,只可**临时使用一次**
匿名函数定义语法:
lambda 传入参数: 函数体( )
# lambda 表示传入参数
# 函数体就是函数的执行逻辑(只能写一行!)
def func(count):
sum = count(1,2)
print(f"结果为{sum}")
func(lambda x,y: x+y)
func(lambda x,y: x-y)
——————————————————————————————————————
结果为3
结果为-1
进程已结束,退出代码0
7.4 闭包与修饰器
def func():
def inner(): # inner为函数名,可自定义
代码块.....
return inner # 返回的时内层函数的本身,用于将内部代码返回到外部,而非调用!!
【注】单纯的闭包没有任何意义,必须结合装饰器使用
def func():
def inner():
print("这是一个闭包")
return inner
func()() # func() => inner func()() => inner()
______________________________________
这是一个闭包
进程已结束,退出代码0
1.其本身是一个闭包
2.函数作为参数传递
用于在不修改源代码和调用方式的情况下,给源代码增加或修改功能
格式:
def func1(源代码函数名): # 传入要修改的源代码
def inner(): # inner为函数名
代码块.... # 写入要增加或修改的功能
return inner
def a(): # 源代码a
print("我是一份源代码")
def func(a): # 装饰器,传入源代码
def inner():
print("增加功能....") # 为源代码增加一个功能
a()
return inner
func(a)() # 调用功能
______________________________________
增加功能....
我是一份源代码
进程已结束,退出代码0
# 使调用装饰器语法更加简洁
def func(func1):
def inner():
print("增加功能....")
func1()
return inner
@func # 可理解为调用了一个装饰器给源代码
def a():
print("源代码....")
a()
______________________________________
增加功能....
源代码
进程已结束,退出代码0
# 编写add函数,实现加法运算;编写装饰器代码增加输出提示。
def func(add): # 装饰器框架 =》 传入要修饰的代码
def inner(x,y): # 传入所需的参数
print("计算中...") # 增加功能
add(x,y)
print("结束!")
return inner
@func # 使用语法糖调用
def add(x,y):
print(f"{x}+{y}={x+y}")
add(1,3) # 调用源代码
______________________________________
计算中...
1+3=4
结束!
进程已结束,退出代码0
# 使用不定长参数可将一个装饰器应用于多个源代码函数 ==》 通用装饰器
def func(func1):
def inner(*args,**kwargs):
print("计算中...")
func1(*args,**kwargs)
print("结束!")
return inner
@func
def add(num1,num2,num3):
print(f"{num1}+{num2}+{num3}={num1+num2+num3}")
@func
def sub(num1,num2):
print(f"{num1}-{num2}={num1-num2}")
sub(3,2)
add(3,5,9)
______________________________________
计算中...
3-2=1
结束!
计算中...
3+5+9=17
结束!
7.5 递归、迭代器与生成器
1)递归
递归的本质就是一个函数,通过调用自己本身的函数来执行
def func():
print("Info....")
return func() # 函数结果返回该函数
2)迭代器
# 可迭代对象会内置__iter__的属性,故字符串、字典、列表、元组、集合等都是可迭代对象
num1 = "1"
num2 = {1:1}
num3 = [1]
num4 = (1,)
num5 = {1}
num6 = range(1,10)
print(num1.__iter__)
print(num2.__iter__)
print(num3.__iter__)
print(num4.__iter__)
print(num5.__iter__)
print(num6.__iter__)
——————————————————————————————————————————
<method-wrapper '__iter__' of str object at 0x000002242A9D64F0>
<method-wrapper '__iter__' of dict object at 0x000002242AD8BA80>
<method-wrapper '__iter__' of list object at 0x000002242AD9F480>
<method-wrapper '__iter__' of tuple object at 0x000002242AD75360>
<method-wrapper '__iter__' of set object at 0x000002242ADC6880>
<method-wrapper '__iter__' of range object at 0x000002242ADB7C00>
进程已结束,退出代码0
# 变量名 = 可迭代对象.__iter__() 声明迭代器的对象必须要可迭代对象
a = list(range(1,11))
print(a)
a = a.__iter__()
print(a)
a = iter(a)
print(a)
__________________________________________
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
<list_iterator object at 0x000001A818896C80>
<list_iterator object at 0x000001A818896C80>
进程已结束,退出代码0
a = range(1,11) # 用于返回迭代器的下一个项目
a = iter(a)
print(a)
print(next(a))
print(next(a))
print(next(a))
print(next(a))
__________________________________________
<range_iterator object at 0x000002B8D540DAB0>
1
2
3
4
# 当该迭代器没有下一项值时,会输出default值。
# 格式: next(迭代器,default)
a = range(1,5)
a = iter(a)
print(next(a,False))
print(next(a,False))
print(next(a,False))
print(next(a,False))
print(next(a,False))
__________________________________________
1
2
3
4
False # 若未设置default值时会输出报错
进程已结束,退出代码0
迭代器的优缺点
- 提供通用的取值方法,不依赖于下标索引index或者字典key值进行取值
- 节省内存(序列索引会消耗一部分空间进行存储index或key值),迭代器取完后就销毁,去取下一个,迭代器的取值不可逆,无法去到上一个值
3)生成器
本质上就是一个迭代器,通过yield关键字制定规则生成数据,其本质就是一个迭代器。
def func(): # yield 只能用于函数体内
print("start...")
for i in range(1,100):
yield i # 运行到yield时,就会把函数变成生成器
print("go on...")
a = func()
print(a)
for i in range(1,11): # 函数变为生成器时,需要next运行代码
print(next(a)) # 1~10取完,下一次从11开始
print("-"*50)
for i in range(1,11):
print(next(a)) # 11~20取完,下一次从21开始
_______________________________________________________________
<generator object func at 0x0000012228790430>
start...
1
go on...
2
go on...
3
go on...
4
go on...
5
go on...
6
go on...
7
go on...
8
go on...
9
go on...
10
--------------------------------------------------
go on...
11
go on...
12
go on...
13
go on...
14
go on...
15
go on...
16
go on...
17
go on...
18
go on...
19
go on...
20
进程已结束,退出代码0
第八章 Python文件操作
8.1 文件编码
编码就是一种规则集合,记录了内容和二进制间进行相互转换的逻辑。
8.2 文件的读取
文件三步走:
1.打开
2.读 / 写
3.关闭
8.2.1 open( ) 打开函数
- 语法
# 打开一个已存在的文件,或创建一个新文件,语法如下:
open(name,mode,encoding)
# name: 是要打开的目标文件名的字符串(可以包含文件所在的具体路径)
# mode:设置打开文件的模式(访问模式):只读、写入、追加等。
# encoding:编码格式(推荐使用 UTF-8)
- mode 常用的三种基础访问模式
| 模式 | 描述 |
|---|---|
| r | read 以只读方式打开文件。文件的指针将会放在文件的开头(默认该模式)。 |
| w | write打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,原有内容会被删除。如果该文件不存在,则创建新文件。 |
| a | append打开一个文件用于追加。如果该文件已存在,新的内容将会被写入到已有的内容之后。如果该文件不存在,则创建新文件进行写入。 |
- 操作字符
open(文件路径/文件名,操作模式+操作字符类型,字符编码)
# 操作字符: b -> byte:二进制模式,常用于操作二进制文件(如视频、音频、图片)
# t -> txt:文本模式(不指定操作字符类型时默认以该模式打开)
将文本写入二进制文件时须先使用encode()方法将文本转换为数据流再进行写入
8.2.2 读取函数
- read( ) 方法
文件对象.read(num)
# num 表示要从文件中读取的数据的长度(单位:字节),如果没有传入num,那么就表示读取文件中所有的数据。
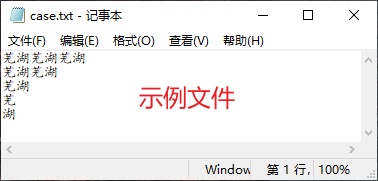
f = open("E:\desk\case.txt","r",encoding="UTF-8") # 打开文件
print(f.read(6)) # 读取6字节内容
__________________________________________________
芜湖芜湖芜
进程已结束,退出代码0
f = open("E:\desk\case.txt","r",encoding="UTF-8") # 打开文件
print(f.read()) # 读取所有内容
___________________________________________________
芜湖芜湖芜湖
芜湖芜湖
芜湖
芜
湖
进程已结束,退出代码0
- readlines( ) 方法
readlines可以按照行的方式把整个文件中的内容进行一次性读取,并且返回一个列表,其中每一行的数据为一个元素。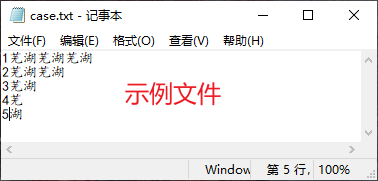
f = open("E:\desk\case.txt","r",encoding="UTF-8") # 打开文件
print(f.readlines()) # 读取文件的全部行,封装到列表
____________________________________________________
['\ufeff芜湖芜湖芜湖\n', '芜湖芜湖\n', '芜湖\n', '芜\n', '湖']
进程已结束,退出代码0
f = open("E:\desk\case.txt","r",encoding="UTF-8") # 打开文件
lin1 = f.readline() # 按行读取
lin2 = f.readline()
lin3 = f.readline()
print(f"第一行:{lin1}")
print(f"第二行:{lin2}")
print(f"第三行:{lin3}")
____________________________________________________
第一行:1芜湖芜湖芜湖
第二行:2芜湖芜湖
第三行:3芜湖
进程已结束,退出代码0
# for 循环读取内容
f = open("E:\desk\case.txt","r",encoding="UTF-8") # 打开文件
for x in f:
print(x)
——————————————————————————————————————————————————————
1芜湖芜湖芜湖
2芜湖芜湖
3芜湖
4芜
5湖
进程已结束,退出代码0
8.2.3 close( ) 关闭文件对象
f = open("E:\desk\case.txt","r",encoding="UTF-8") # 打开文件
f.close()
# 最后通过close,关闭文件对象,也就是关闭对文件的占用
# 如果不调用close,同时程序没有停止运作,那么这个文件将一直被程序占用
print(变量.closed) # 可用于打印文件关闭状态,输出bool值
8.2.4 with open 操作文件
with open(...) as 对象名:
对象名.方法名()
# 可以在with open的语句块中对文件进行操作,操作完成后自动关闭文件对象。
import time
with open("E:\desk\case.txt","r",encoding="UTF-8") as f:
for line in f:
print(line)
time.sleep(6) # 延后六秒执行下一行,此时文件解除占用
8.2.5 异常情况
UnicodeDecodeError报错
原因:编码与预设不一致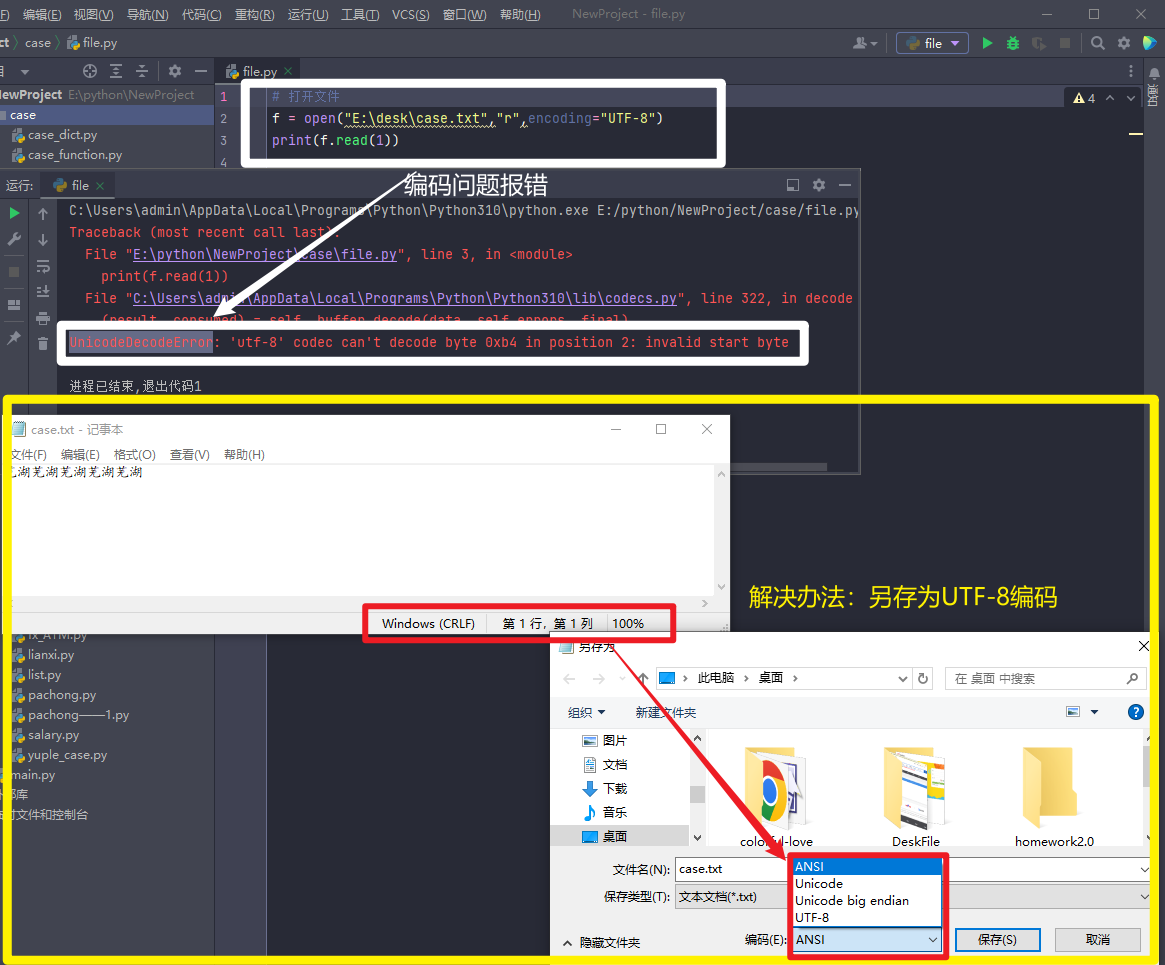
出现空集情况
原因:没有关闭对文件的占用
8.2.6 操作总览
| 操作 | 功能 |
|---|---|
| 文件对象名 = open( file,mode,encoding) | 打开文件获得文件对象 |
| 文件对象名.read( num ) | 读取指定长度(单位:字节)数据,不指定长度时默认读取全部数据 |
| 文件对象名.readline( ) | 读取一行数据 |
| 文件对象名.readlines( ) | 读取全部数据,得到一个列表 |
| for line in 文件对象名 | for循环文件行,一次循环得到一行数据 |
| 文件对象名.close( ) | 关闭文件对象 |
| with open(…) as 对象名 | 通过with open语法打开文件,可以自动关闭 |
8.2.7 案例练习
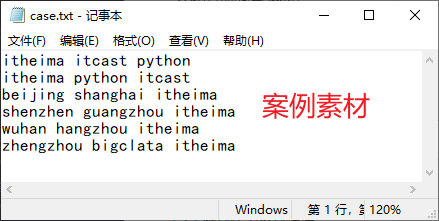
创建文本文档,输入素材内容并保存,通过所学内容,输出计算出文本中 ‘itheima’ 出现的次数。
# 方法一(不推荐)
with open("E:\desk\case.txt","r",encoding="UTF-8") as f:
count = 0 # 计算itheima数量(初始值为0)
for line in f: # 遍历文件内容
blank_value = line.split( ) # *将全部内容按空格分开
for x in blank_value: # 遍历列表
if x == 'itheima': # 判断列表元素中是否有itheima
count += 1 # 如果有则count+1
print(f"文本中 ‘itheima’ 出现{count}次")
——————————————————————————————————————————————————————————————————————————
文本中 ‘itheima’ 出现5次
进程已结束,退出代码0
# 在*处输出后,第一行内容变为['\ufeffitheima', 'itcast', 'python'],无法识别第一个‘itheima’,故计算结果为5
# 方法二 读取全部内容
with open("E:\desk\case.txt","r",encoding="UTF-8") as f: # 打开文件
txt = f.read() # 读取出内容
count = txt.count('itheima') # 计算‘itheima’ 出现的次数
print(f"文本中 ‘itheima’ 出现{count}次")
——————————————————————————————————————————————————————————————————————————
文本中 ‘itheima’ 出现6次
进程已结束,退出代码0
# 方法三 逐行查找
with open("E:\desk\case.txt","r",encoding="UTF-8") as f:
value = 0 # 定义一个变量计算‘itheima’出现的次数(初始值为0)
for line in f: # 循环遍历每一行内容
count = line.count('itheima') # 在每一行检索‘itheima’字符串(出现目标字符串时标记1)
if count == 1: # 当出现目标字符串被标记为1时:
value += 1 # value自增1
print(f"文本中 ‘itheima’ 出现{value}次")
——————————————————————————————————————————————————————————————————————————
文本中 ‘itheima’ 出现6次
进程已结束,退出代码0
8.3 文件的写入
文件对象 = open(file,'w') # 打开文件
文件对象.write('内容') # 写入内容
文件对象.flush() # 内容刷新
----------------
· 直接调用wirte,内容并未真正写入,而是会积攒在程序的内存中,称之为缓冲区
· 当调用flush的时候,内容会真正写入文件
· 目的是避免频繁的操作硬盘,导致效率下降(积攒一堆,一次性写入磁盘)
· 会清空原有数据,再重新写入新数据
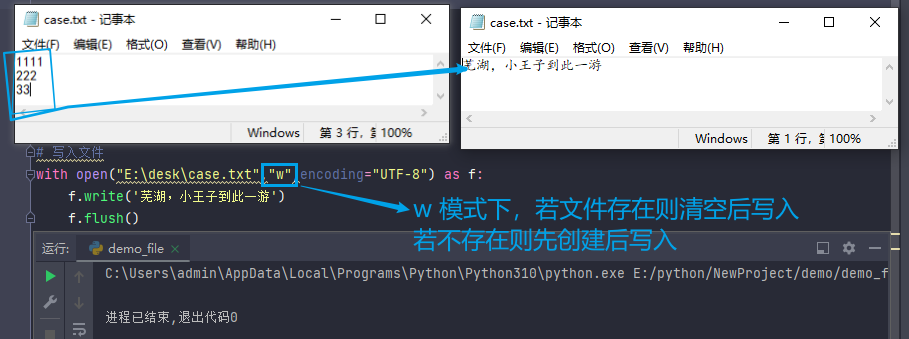
with open("E:\desk\case.txt","w",encoding="UTF-8") as f: # 打开文件
f.write('芜湖,小王子到此一游') # 将内容写入内存中
f.flush() # 将内存中数据写入磁盘
————————————————————————————————————————————————
进程已结束,退出代码0
8.4 文件的追加
文件对象 = open(file,'a') # 打开文件
文件对象.write('内容') # 写入内容
文件对象.flush() # 内容刷新
----------------------
# a模式下,文件不存在会创建文件,若存在则会在文件最后追加写入内容。

8.5 序列化与反序列化
# 序列化就是将数据流进行编译 (python转json字符串)
import json
p_list = [{"姓名:":"王","性别:":"男","年龄":"19"},
{"姓名:":"张","性别:":"男","年龄":"14"},
{"姓名:":"李","性别:":"女","年龄":"16"}]
j_data = json.dumps(p_list)
print(j_data)
print(type(j_data))
________________________________________
[{"\u59d3\u540d\uff1a": "\u738b", "\u6027\u522b\uff1a": "\u7537", "\u5e74\u9f84": "19"}, {"\u59d3\u540d\uff1a": "\u5f20", "\u6027\u522b\uff1a": "\u7537", "\u5e74\u9f84": "14"}, {"\u59d3\u540d\uff1a": "\u674e", "\u6027\u522b\uff1a": "\u5973", "\u5e74\u9f84": "16"}]
<class 'str'>
进程已结束,退出代码0
# 反序列化是将原数据进行反编译 (json字符串转python字典)
import json
j_data = '{"姓名:":"王","性别:":"男","年龄":"19"}' # 注意!只能是字符串格式!
p_data = json.loads(j_data)
print(p_data)
print(type(p_data))
________________________________________
{'姓名:': '王', '性别:': '男', '年龄': '19'}
<class 'dict'>
进程已结束,退出代码0
dump和load只能在文本格式使用
dumps和loads不能在with中使用
8.6 文件操作综合案例
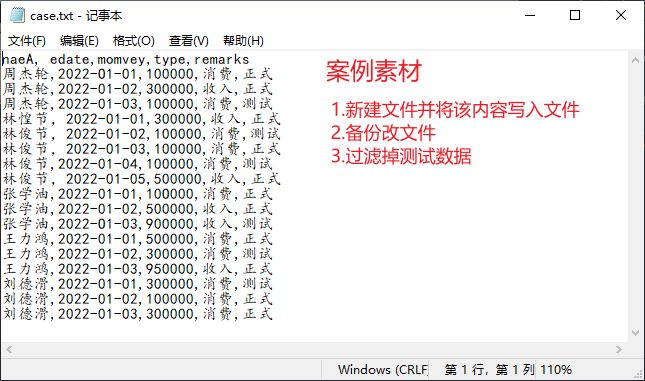
# 备份:
f_1 = open("E:\desk\case.txt",'r',encoding='UTF-8') # 打开文件
read_all = f_1.read() # 读取全部数据
f_2 = open("E:\desk\jack.txt",'a',encoding='UTF-8') # 打开另一个文件
f_2.write(read_all) # 将读取到的数据写入另一个文件中,完成备份操作
f_2.flush() # 刷新
f_2.close() # 关闭
f_1.close() # 关闭
# 判断方法一:
f_1 = open("E:\desk\case.txt",'r',encoding='UTF-8') # 重新打开文件
for line in f_1: # 循环遍历文件数据
count = line.count('正式') # 判断字符,当出现目标字符时count=1
if count == 1: # 当出现count=1时
f_3 = open("E:\desk\jackes.txt", 'a', encoding='UTF-8') # 打开另一个文件,用于数据写入
f_3.write(line) # 将count=1的数据写入
f_1.close() # 关闭
f_3.close() # 关闭
# 判断方法二
f_1 = open("E:\desk\case.txt",'r',encoding='UTF-8') # 重新打开文件
for line in f_1: # 循环遍历文件数据
lose_info1 = line.strip() # 去除首位空格
lose_info2 = lose_info1.split(',') # 按逗号隔开
if lose_info2[-1] == '测试':
f_3 = open("E:\desk\jackes.txt", 'a', encoding='UTF-8')
f_3.write(line)
f_1.close() # 关闭
f_3.close() # 关闭
with open("E:\desk\lalala.txt","r") as f_1: # 读取案例文件
for x in f_1: # 遍历文件每行内容
b = x.split(',') # 按照逗号分隔开保存为列表
if b[-1] == '正式\n': # 使用切片得到目标值并进行判断
with open("E:\desk\lalala.txt.bak","a") as f_2: # 新建第二个文件进行追加
f_2.write(x)
第九章 Python异常、模块与包
9.1 异常
当检测到一个错误时,Python解释器无法执行,并返回一些错误提示。
9.1.1 异常的捕获
- 捕获常规异常
try:
可能发生错误的代码
except:
如果出现异常则执行的代码
# r模式打开一个不存在的文件 => 报错
with open("E:\desk\py.txt","r",encoding="UTF-8") as f:
f.read()
——————————————————————————————————————————————
Traceback (most recent call last):
File "E:\python\NewProject\case\case_error.py", line 2, in <module>
with open("E:\desk\py.txt","r",encoding="UTF-8") as f:
FileNotFoundError: [Errno 2] No such file or directory: 'E:\\desk\\py.txt'
进程已结束,退出代码1
# 抛出异常 => 不报错
try:
f = open("E:\desk\py.txt", "r", encoding="UTF-8")
except:
print("发现异常,目标不存在,应改为‘w’模式")
f = open("E:\desk\py.txt", "w", encoding="UTF-8")
——————————————————————————————————————————————
发现异常,目标不存在,应改为‘w’模式
进程已结束,退出代码0
- 捕获指定异常
try:
print(name)
except NameError as 别名 # 只能捕获NameError异常,出现其他异常会报错
print("变量未定义")
-----------------
· 如果尝试执行的代码的异常类型和要捕获的异常类型不一致,则无法捕获异常。
· 一般try下方只放一行尝试执行的代码。
- 捕获多个异常
try:
.....
except(多个异常类型...): # 使用元组形式进行书写
.....
try:
f = open("E:\desk\py.txt", "r", encoding="UTF-8")
except (NameError,FileNotFoundError,TypeError): # 未正确设置捕获异常类型,将无法捕获异常
print("异常....")
- 捕获所有异常
try:
.....
except Exception as 别名:
.....
try:
f = open("E:\desk\py.txt", "r", encoding="UTF-8")
except Exception:
print("异常....")
try:
a = 1/0
except Exception as e:
print("有异常.....")
print(e)
——————————————————————————————————————————
有异常.....
division by zero
进程已结束,退出代码0
9.1.2 异常else
try:
.....
except Exception as 别名:
.....
else:
无异常时执行
try:
print("1234567")
except Exception:
print("发现异常....")
else:
print("执行完毕!未发现异常")
————————————————————————————————————————
1234567
执行完毕!未发现异常
进程已结束,退出代码0
9.1.3 异常finally
无论是否异常都要执行的代码。
try:
......
except Exception:
print("异常....")
else:
print("执行完毕!未发现异常")
finally:
...... # 无论是否异常都要执行的代码
try:
f = open("E:\desk\py.txt", "r", encoding="UTF-8")
except Exception:
print("出现异常....")
f = open("E:\desk\py.txt", "w", encoding="UTF-8")
else:
print("执行完毕!未发现异常")
finally:
f.close() # 无论是否异常都关闭文件
9.1.4 异常的传递

当函数 func01 发生异常,并且没有捕获处理这个异常的时候,异常会传递到函数 func02,
当 func02 也没有捕获处理这个异常时,main 函数会捕获这个异常,当所有函数都没有捕获异常的时候,程序就会报错。
# 定义一个有异常的函数
def fx_1():
print("NO.1 start")
sum = 1/0 # 编写一条异常代码,而导致整个函数异常
print("NO.1 stop")
# 定义一个无异常的函数,调用异常的函数
def fx_2():
print("NO.2 start")
fx_1() # 调用异常函数,导致整个函数异常
print("NO.2 stop")
def main():
try:
fx_2()
except Exception as a:
print("异常:{a}")
main() # 最终异常函数fx_1的异常会被逐级传递至main(),在main函数中处理异常
________________________________________________
NO.2 start
NO.1 start
异常division by zero
进程已结束,退出代码0
9.2 Python 模块
Python 模块(Module),是一个 Python 文件,以 .py 结尾。<br /> 模块可以定义函数,类和变量,模块里也能包含可执行的代码。
模块的分类
- 内置模块
- 第三方模块
PyCharm终端pip更新命令:python -m pip install --upgrade pip
- 自定义模块
9.2.1 模块的导入
# 语法
[from 模块名] import [模块 | 类 | 变量 | 函数 |*][as 别名]
------------
常用的组合形式:
· import 模块名
· from 模块名 import 类、变量、方法等
· from 模块名 import *
· import 模块名 as 别名
· from 模块名 import 功能名 as 别名
# 模块语句之间的点表示层级关系,模块导入语句一般写在开头位置
- import 模块名
import 模块名
import 模块名1,模块名2
模块名.功能名()
import time # 导入时间模块
print("开始")
time.sleep(3) # 模块名.功能名()
print("结束")
_____________________________
开始 # time.sleep(3) 程序睡眠(阻塞)3秒后执行下一句
结束
进程已结束,退出代码0
- from 模块名 import 功能名
from 模块名 import 功能名
功能名()
from time import sleep # 导入时间模块的sleep功能
print("开始")
sleep(3)
print("结束")
from time import * # *表示全部功能
print("开始")
sleep(3)
print("结束")
9.2.2 自定义模块
- 使用 as 给特定功能加上别名
import 模块名 as 模块别名
....
模块别名.功能名()
....
from 模块名 import 功能名 as 功能别名
......
模块名.功能别名()
......
# 为time模块取别名并调用
import time as t
print("开始")
t.sleep(3)
print("结束")
# 为time模块的sleep功能取别名并调用
from time import sleep as sl
print("开始")
sl(3)
print("结束")
- 制作自定义模块
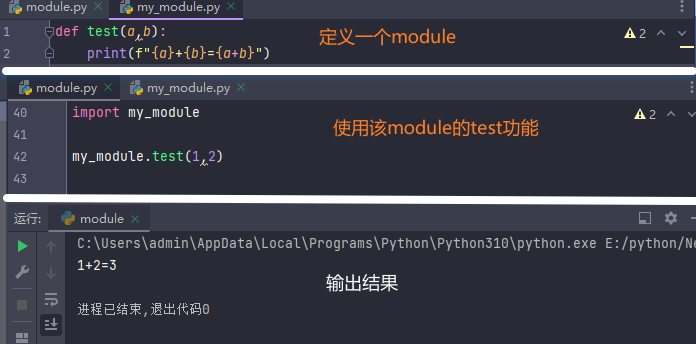
- __ main _ _ 变量
main变量用于模块测试时的数据,不会被外部文件调用输出。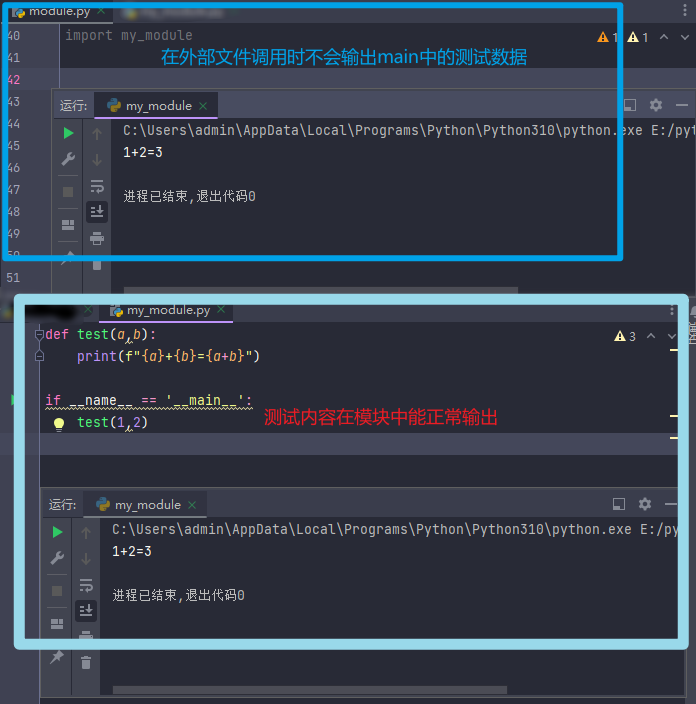
- _ _ all _ _ 变量
用于指定星号使用某功能。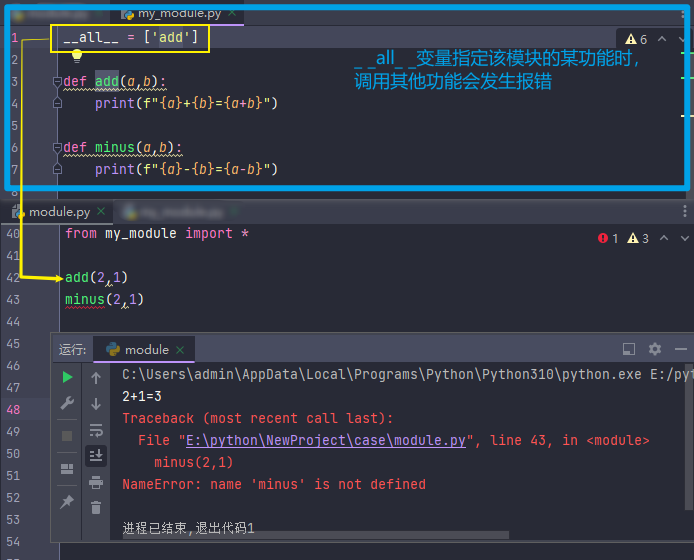
9.2.3 【扩】 re 模块

import re
url = "https://edu.zztion.com/live/index?resourceId=393285196629147648?pwd=p2lh"
a = re.findall("https",url) # 在字符串中查找指定内容,未找到输出空列表
c = re.findall("[0-9]",url)
d = re.match("https",url) # 从起点开始,匹配成功返回对象,匹配不到即返回None
f = re.search("edu",url) # 在整个字符串中查找指定内容,匹配不到即返回None
g = re.sub("pwd=p2lh","****",url) # 在整个字符串中查找指定值,并替换相应值
9.3 Python 包
包就是一个文件夹,可用于存放许多 Python 的模块(代码文件),通过包将一批模块归为一类 ,方便使用。
9.3.1 自定义Python包
- 快速入门
① 新建包 ’my_package‘
② 新建包内模块:‘my_module1’ 和 ‘my_module2’,并写入案例
[注] 新建包后,包内会自动创建 `int_.py``文件,这个文件控制着包的导入行为
- 导入包
① 方法一:
import 包名.模块名
包名.模块名.目标
② 方法二:
# 必须先在`_init_.py`文件中添加`__all__=[]`,控制允许导入的模块列表
from 包名 import *
模块名.目标
————————————————————————————————————
[注] __all__只针对'from ... import *'方式的导入
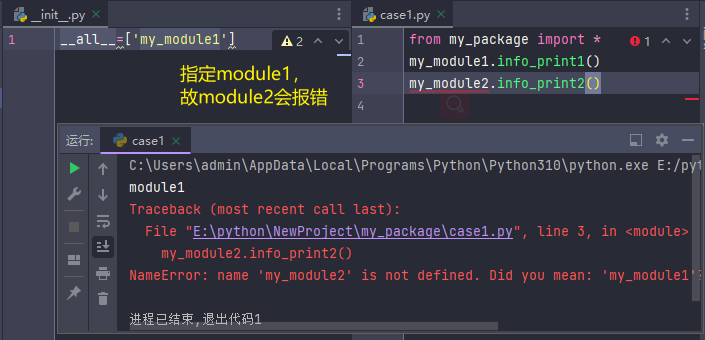
9.3.2 安装第三方 Python 包
- pip命令安装
命令提示符或终端输入:
pip install [] 包名
------
[-i] 用于链接目标网址
https://pypi.tuna.tsinghua.edu.cn/simple 由清华大学提供用于下载第三方包资源
- PyCharm 安装


9.4 综合案例

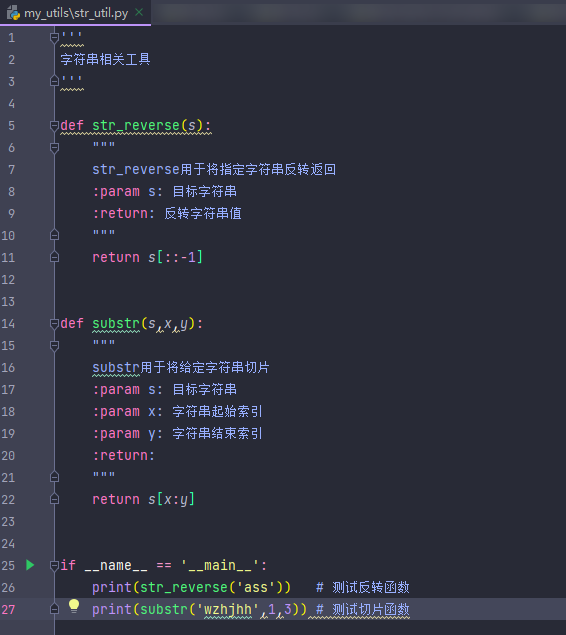

第十章 Python数据可视化综合案例
10.1 数据可视化 – 折线图可视化
10.1.1 json 数据格式
- 什么是 json
· JSON 是一种轻量级的数据交换格式。可以按照 JSON 指定的格式取组织和封装数据。
· JSON 本质上是一个带有特定格式的字符串
- 主要功能
是一种在各个编程语言中流通的数据格式,负责不同编程语言中的数据传递和交互
- json 格式数据转化
-
json 转 python
json.loads(data)
-
import json # 导入json模块
# 将json字符串转换为python
j_data = '{"姓名:":"王","性别:":"男","年龄":"19"}' # 注意!只能是字符串格式!
j_py = json.loads(j_data)
print(j_py)
——————————————————————————————————————————————————————————
{'姓名:': '王', '性别:': '男', '年龄': '19'}
进程已结束,退出代码0
- python 转 jso
json.dumps(date)
import json # 导入json模块
# 将python列表(列表元素为字典)转换为json
py_list = [{"姓名:":"王","性别:":"男","年龄":"19"},
{"姓名:":"张","性别:":"男","年龄":"14"},
{"姓名:":"李","性别:":"女","年龄":"16"}]
# 使用dumps方法将列表转换为json字符串,ensure_ascii=False 用于正常输出中文
json_data1 = json.dumps(py_list,ensure_ascii=False)
print(json_data1)
————————————————————————————————————————————————————————————————
[{"姓名:": "王", "性别:": "男", "年龄": "19"}, {"姓名:": "张", "性别:": "男", "年龄": "14"}, {"姓名:": "李", "性别:": "女", "年龄": "16"}]
进程已结束,退出代码0
import json # 导入json模块
# 将python字典转换为json
py_dirt = {"姓名:":"王","性别:":"男","年龄":"19"}
json_data2 = json.dumps(py_dirt,ensure_ascii=False)
print(json_data2)
————————————————————————————————————————————————————————————————
{"姓名:": "王", "性别:": "男", "年龄": "19"}
进程已结束,退出代码0
10.1.2 pyecharts 模块介绍
- pyecharts 模块安装命令提示符:pip install pyecharts

- 官方画廊:https://gallery.pyecharts.org/#/README
- pyecharts官网:https://pyecharts.org/#/
10.1.3 创建折线图
- 基础折线图
# 1.导包,导入line功能构建折线图对象
from pyecharts.charts import Line
# 得到折线图对象
line = Line()
# 添加x轴数据
line.add_xaxis(["中国","美国","英国"])
# 添加y轴数据
line.add_yaxis("GDP",[30,20,10])
# 生成图表
line.render()
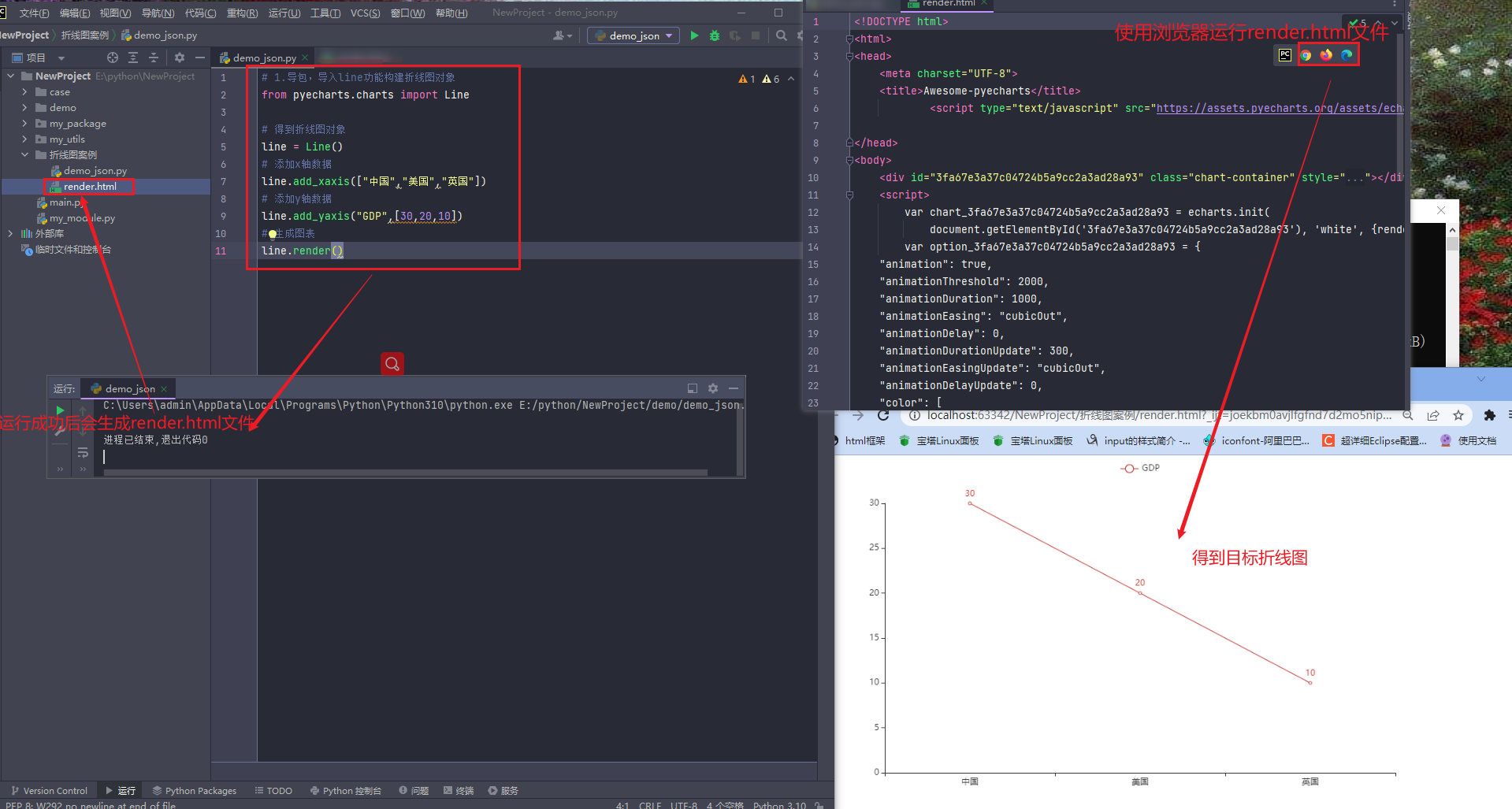
- 全局配置选项
通过 set_global_opts 方法来进行配置
# 1.导包,导入line功能构建折线图对象
from pyecharts.charts import Line
# 2.导入全局配置项的包(用逗号隔开不同的包)
from pyecharts.options import TitleOpts,LegendOpts,ToolboxOpts,VisualMapOpts
# 得到折线图对象
line = Line()
# 添加x轴数据
line.add_xaxis(["中国","美国","英国"])
# 添加y轴数据
line.add_yaxis("GDP",[30,20,10])
# 设置全局配置项 set_global_opts
line.set_global_opts(
# position位置 pos_left位置靠近最左边的距离
title_opts=TitleOpts(title="GDP数据",pos_left="center",pos_bottom="1%"), # 标题控制选项
# 是否展示=True
legend_opts=LegendOpts(is_show=True), # 图例控制选项
toolbox_opts=ToolboxOpts(is_show=True), # 工具箱
visualmap_opts=VisualMapOpts(is_show=True)# 视觉映射
)
# 生成图表
line.render()
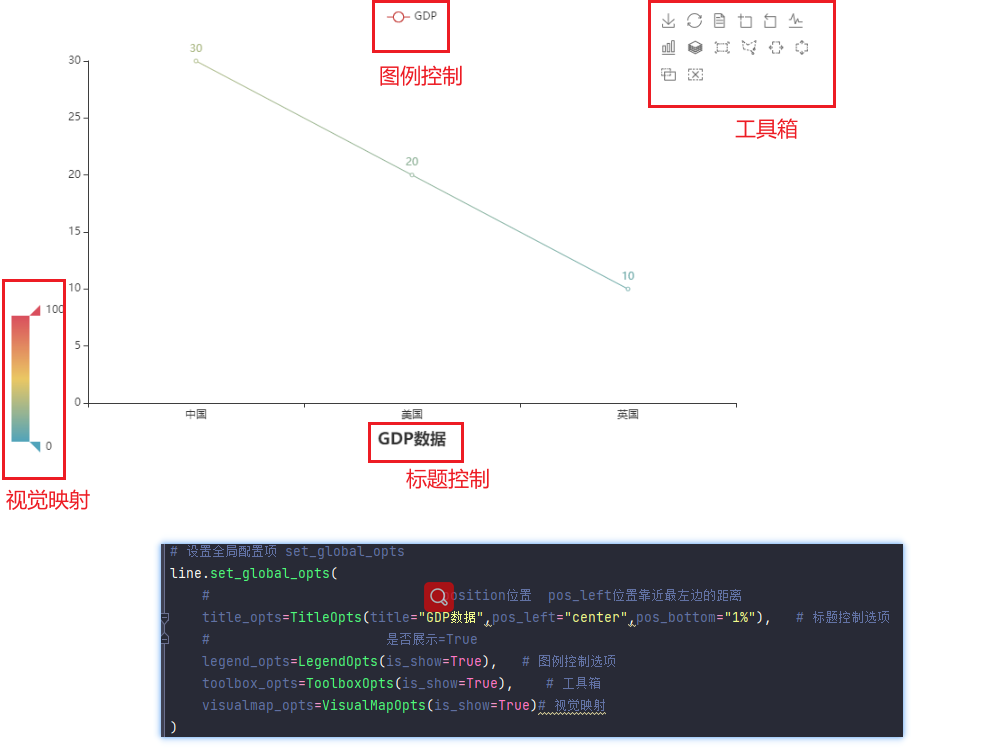
更多全局配置项参照官方文档https://pyecharts.org/#/zh-cn/global_options
10.1.4 数据处理
懒人工具 :http://www.ab173.com/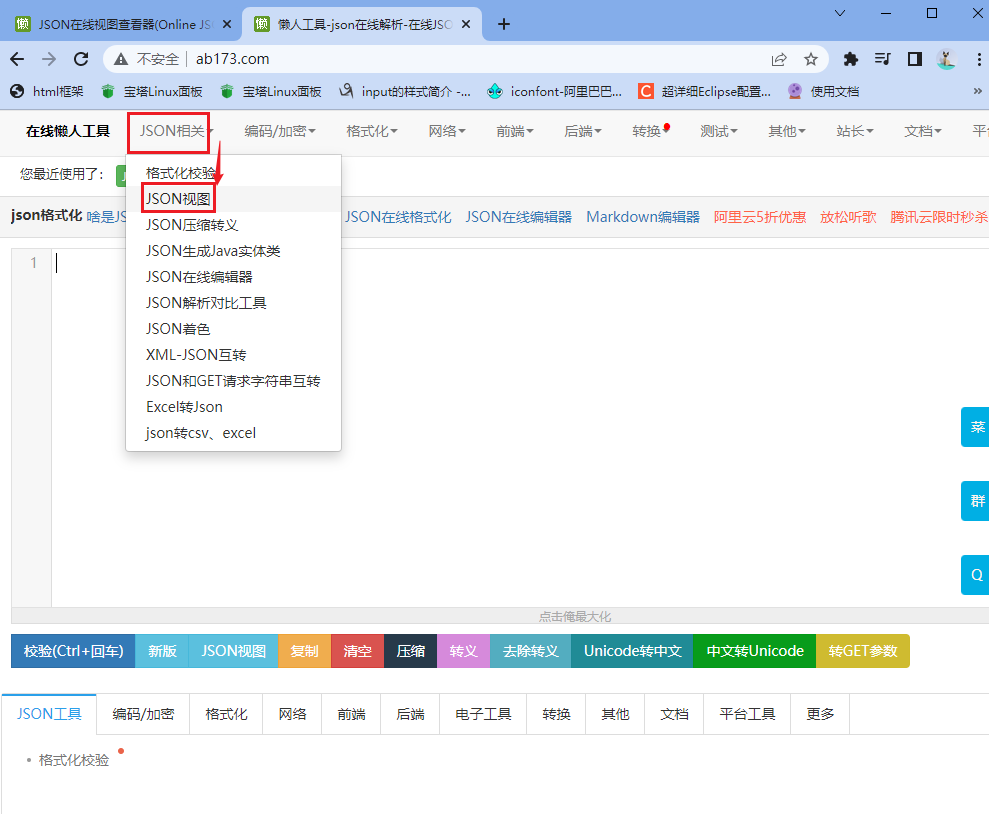
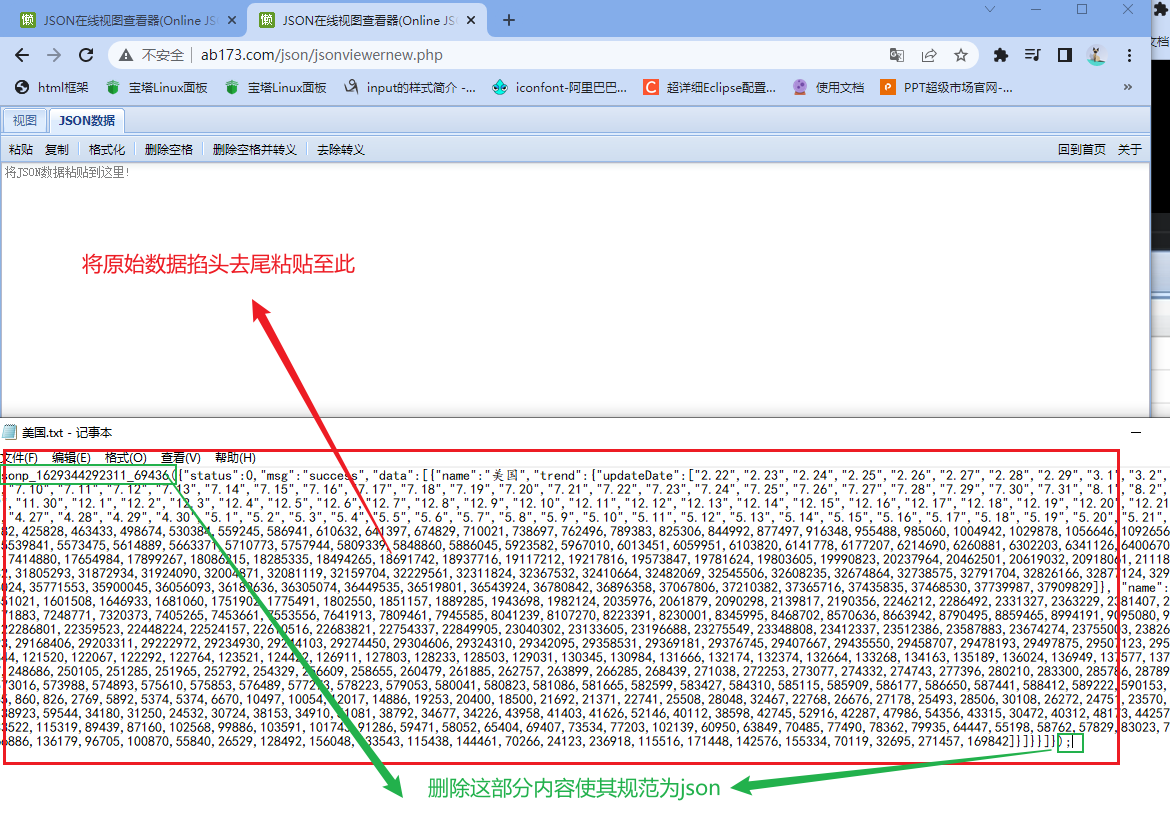
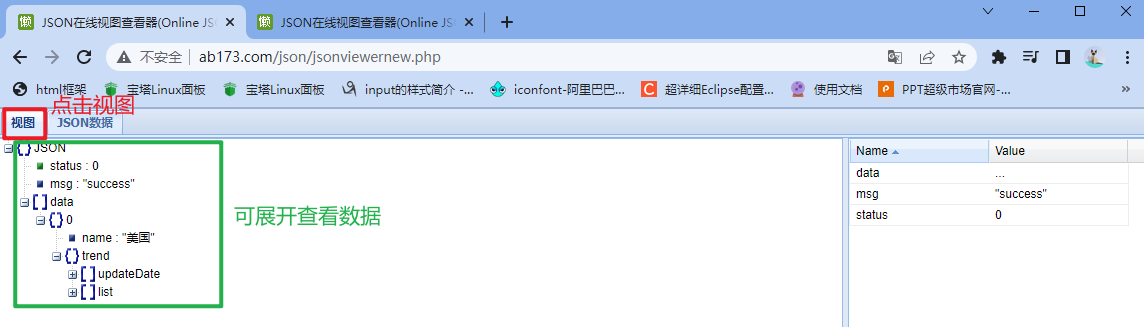
10.1.5 疫情数据折线图案例

import json
from pyecharts.charts import Line # 导入line功能构建折线图对象
# 导入全局配置项的包
from pyecharts.options import TitleOpts,ToolboxOpts,LabelOpts
# 数据处理
f_usa = open("美国.txt","r",encoding="UTF-8")
f_jp = open("日本.txt","r",encoding="UTF-8")
f_in = open("印度.txt","r",encoding="UTF-8")
usa_data = f_usa.read()
jp_data = f_jp.read()
in_data = f_in.read()
# 去掉不合json规范的开头
usa_data = usa_data.replace("jsonp_1629344292311_69436(","")
jp_data = jp_data.replace("jsonp_1629350871167_29498(","")
in_data = in_data.replace("jsonp_1629350745930_63180(","")
# 去掉不合json规范的结尾
usa_data = usa_data[:-2]
jp_data = jp_data[:-2]
in_data = in_data[:-2]
# json转python
usa_data = json.loads(usa_data)
jp_data = json.loads(jp_data)
in_data = json.loads(in_data)
# 获取trend的Key
usa_trend_key = usa_data['data'][0]['trend']
jp_trend_key = jp_data['data'][0]['trend']
in_trend_key = in_data['data'][0]['trend']
# 构建折线图对象
line = Line()
# 获取日期数据,用于x轴(只取2020年数据,到索引为314为止)
date_value = usa_trend_key['updateDate'][:314]
line.add_xaxis(date_value)
# 获取确诊数据,用于y轴(只取2020年数据,到索引为314为止)
usa_case_value = usa_trend_key['list'][0]['data'][:314] # label_opts=LabelOpts选择是否显示数字
line.add_yaxis("美国2020年疫情数据折线图",usa_case_value,label_opts=LabelOpts(is_show=False))
jp_case_value = jp_trend_key['list'][0]['data'][:314]
line.add_yaxis("日本2020年疫情数据折线图",jp_case_value,label_opts=LabelOpts(is_show=False))
in_case_value = in_trend_key['list'][0]['data'][:314]
line.add_yaxis("印度2020年疫情数据折线图",in_case_value,label_opts=LabelOpts(is_show=False))
# 全局配置项
line.set_global_opts(
title_opts=TitleOpts(title="新冠病毒新增病例分析折线图",pos_left="center",pos_bottom="2.5%"),
toolbox_opts=ToolboxOpts(is_show=True)
)
# 生成图表
line.render()
# 关闭文件对象
f_usa.close()
f_jp.close()
f_in.close()
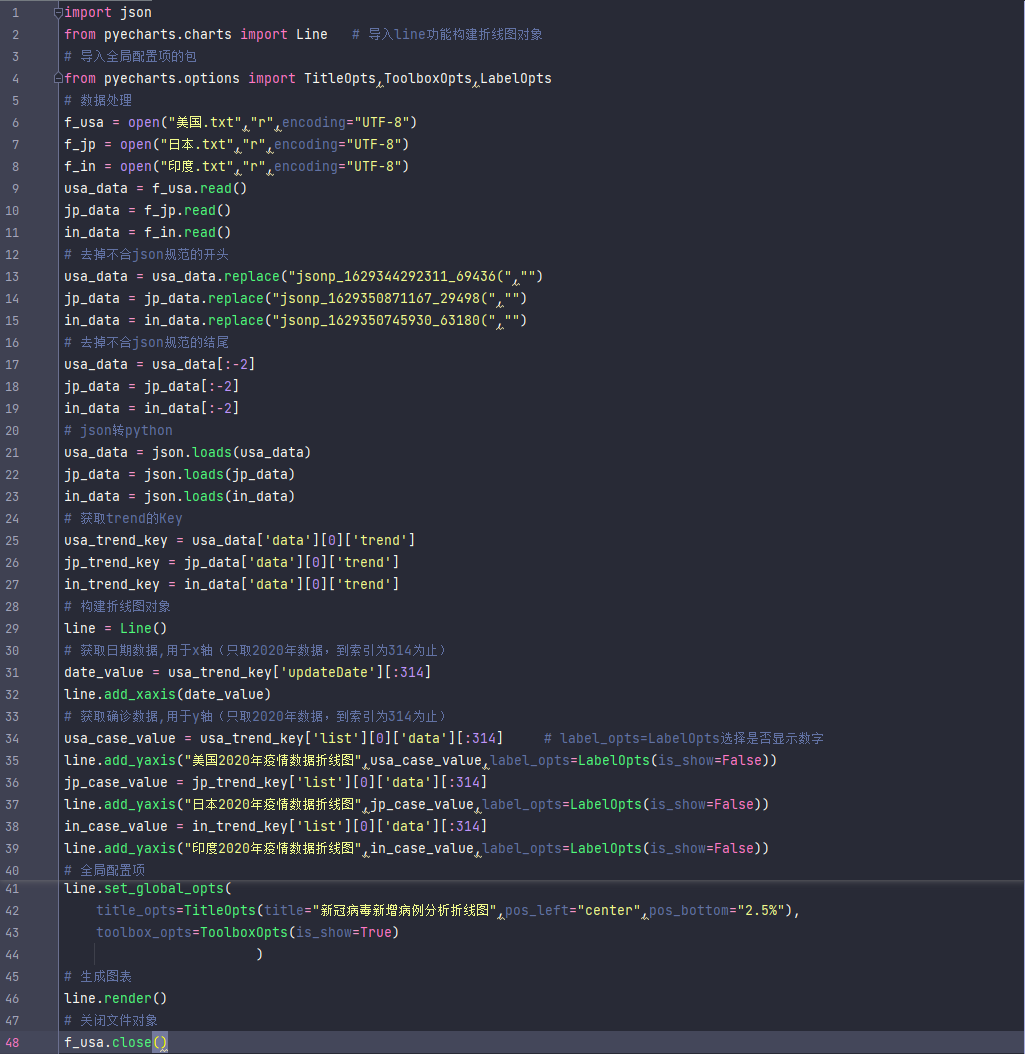
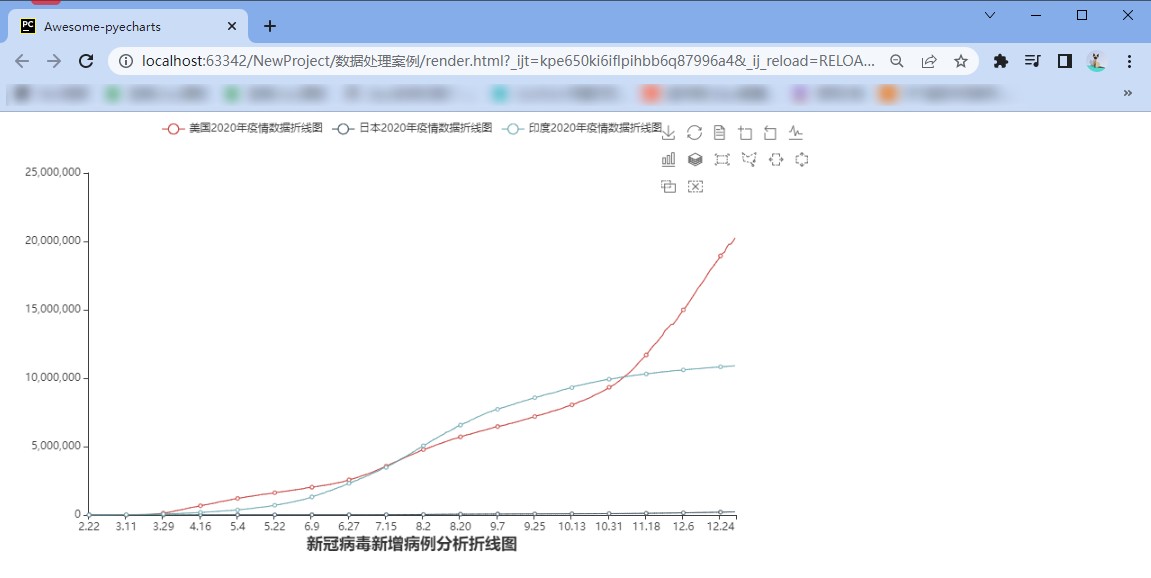
10.2 数据可视化 – 地图可视化
10.2.1 基础地图
from pyecharts.charts import Map # 导入地图
from pyecharts.options import VisualMapOpts # 全局配置项包
# 准备地图对象
map = Map()
# 准备数据
data = [
("云南",0),
("山东",112),
("河南",992),
("湖北",200),
("宁夏",3300),
("新疆",2200),
]
# 添加数据
map.add("中国疫情地图",data,"china")
# 全局配置项
map.set_global_opts(
visualmap_opts=VisualMapOpts( # 视觉映射
is_show=True,
is_piecewise=True, # 手动校准
pieces=[ # 自定义选项(以字典格式存储:最小值、最大值、显示内容、rgb值)
{"min": 0, "max": 0, "label": "0人", "color": "#7be1f9"},
{"min":1,"max":100,"label":"1-100人","color":"#f4bdc5"},
{"min":100,"max":200,"label":"100-200人","color":"#e8455c"},
{"min":200,"max":500,"label":"200-500人","color":"#ca0c27"},
{"min":500,"max":1000,"label":"200-500人","color":"#760d04"},
{"min":1000,"max":90000,"label":"200-500人","color":"#f15309"}
]
)
)
# 绘制图表
map.render()
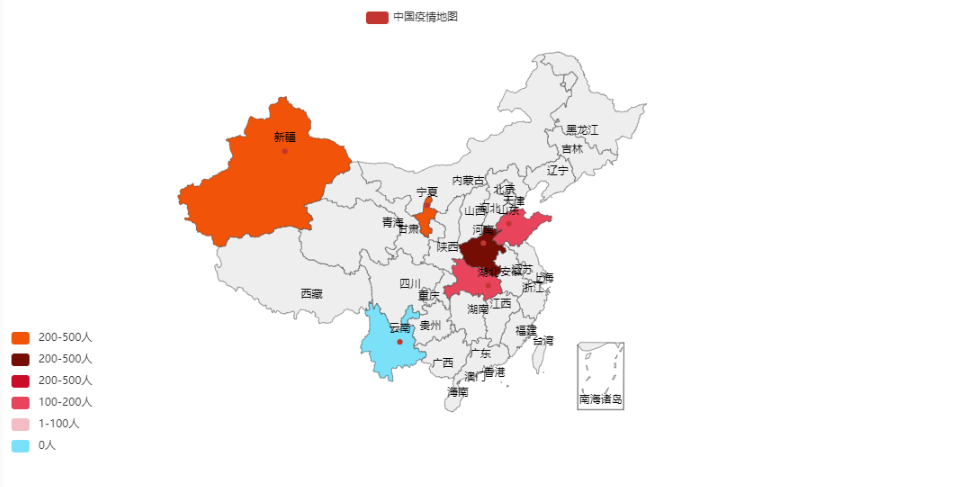
懒人工具 – RGB颜色对照表 http://www.ab173.com/ui/rgb.php
10.2.2 国内疫情地图
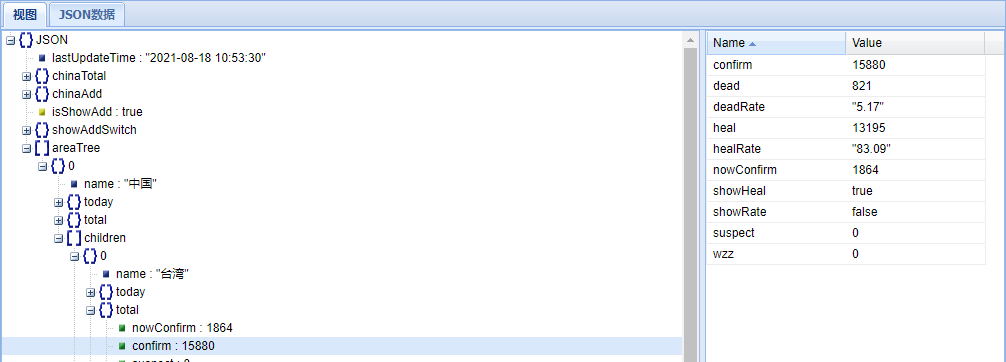
from pyecharts.charts import Map # 导入地图
import json# 导入json
from pyecharts.options import VisualMapOpts # 导入全局配置项
# 准备地图对象
map = Map()
# 准备数据
f = open("疫情.txt","r",encoding="UTF-8") # 打开文件
f_json = f.read() # 读取文件
f.close() # 关闭文件
# json 转 python字典
f_py = json.loads(f_json)
# 通过遍历循环取得各省数据,并组合为元组
p_id = 0 # 省份索引
data = [] # 地图数据空列表
for x in range(33):
province = f_py['areaTree'][0]['children'][p_id]['name'] # 省份
num = f_py['areaTree'][0]['children'][p_id]['total']['confirm'] # 确诊人数
p_id += 1
data.append((province,num)) # 通过append方法将数据以元组形式添加到data列表
# 添加数据
map.add("中国疫情地图",data)
# 全局配置项
map.set_global_opts(
visualmap_opts=VisualMapOpts( # 视觉映射
is_show=True, # 是否显示
is_piecewise=True, # 使用手动校准
pieces=[
{"mim":None,"max":0,"label":"0人","color":"#a1f7f4"},
{"min":1,"max":10,"label":"1~10人","color":"#f9becf"},
{"min":10,"max":50,"label":"10~50人","color":"#f06089"},
{"min":50,"max":100,"label":"50~100人","color":"#ea3958"},
{"min":100,"max":500,"label":"100~500人","color":"#d21939"},
{"min":500,"max":1000,"label":"500~1000人","color":"#b81935"},
{"min":1000,"max":3000,"label":"1000~3000人","color":"#961d27"},
{"min":3000,"max":999999,"label":"3000人以上","color":"#54080f"},
]
)
)
# 绘制图表
map.render()
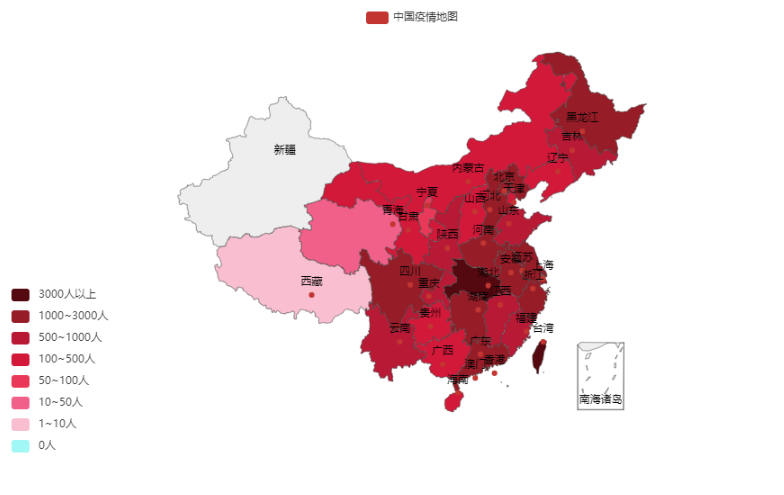
10.2.3 省级疫情地图

from pyecharts.charts import Map # 导入地图包
import json # 导入json包
from pyecharts.options import VisualMapOpts # 导入全局配置项
# 创建地图对象
map = Map()
# 准备数据
# 打开文件
f = open("疫情.txt","r",encoding="UTF-8")
# 读取文件
data = f.read()
# 关闭文件对象
f.close()
# json字符串转python字典
data = json.loads(data)
city_id = 0 # 各市索引
map_data = [] # 定义一个空列表存储地图数据
HeNan = data['areaTree'][0]['children'][3]['children'] # 切片取出河南省的数据
for city in HeNan:
city = HeNan[city_id]['name'] # 切片取出河南省各个市名称
case = HeNan[city_id]['total']['confirm']# 切片取出河南省各个市确诊数据
city_id += 1
map_data.append((city+"市",case)) # 将数据组合成元组传回map_data空列表
# 添加数据到地图对象
map.add("河南省",map_data,"河南")
# 全局配置项
map.set_global_opts(
visualmap_opts=VisualMapOpts( # 视觉映射
is_show=True, # 是否显示
is_piecewise=True, # 使用手动校准
pieces=[
{"mim":None,"max":0,"label":"0人","color":"#a1f7f4"},
{"min":1,"max":10,"label":"1~10人","color":"#f9becf"},
{"min":10,"max":50,"label":"10~50人","color":"#f06089"},
{"min":50,"max":100,"label":"50~100人","color":"#ea3958"},
{"min":100,"max":500,"label":"100~500人","color":"#d21939"},
{"min":500,"max":1000,"label":"500~1000人","color":"#b81935"},
{"min":1000,"max":3000,"label":"1000~3000人","color":"#961d27"},
{"min":3000,"max":999999,"label":"3000人以上","color":"#54080f"},
]
)
)
# 绘制图表(括号内可写入参数,表示生成网页文件名)
map.render("河南省疫情确诊病例数据.html")
10.3 数据可视化 – 动态柱状图
10.3.1 基础柱状图
- 纵向柱状图
# 导入Bar
from pyecharts.charts import Bar
# 构建柱状图对象
bar = Bar()
# 添加x轴数据
bar.add_xaxis(["中国","美国","日本"])
# 添加y轴数据
bar.add_yaxis("GDP",["30","60","50"])
# 绘图
bar.render()
- 反转柱状图(横向)
# 导入Bar
from pyecharts.charts import Bar
# 构建柱状图对象
bar = Bar()
# 添加x轴数据
bar.add_xaxis(["中国","美国","日本"])
# 添加y轴数据
bar.add_yaxis("GDP",["30","60","50"])
# 反转xy轴
bar.reversal_axis()
# 绘图
bar.render()
- 数值标签移至右侧
from pyecharts.charts import Bar # 导入Bar
from pyecharts.options import LabelOpts # 导入LabelOpts
# 构建柱状图对象
bar = Bar()
# 添加x轴数据
bar.add_xaxis(["中国","美国","日本"])
# 添加y轴数据
bar.add_yaxis("GDP",["30","60","50"],label_opts=LabelOpts(position="right"))
# 反转xy轴
bar.reversal_axis()
# 绘图
bar.render()
10.3.2 基础时间线柱状图
# 导入柱状图Bar和时间线Timeline
from pyecharts.charts import Bar,Timeline
from pyecharts.globals import ThemeType # [可选项]导入主题
# 构建多个柱状图对象
bar_1 = Bar()
bar_1.add_xaxis(["保山市","德宏州","大理州","曲靖市","红河州"])
bar_1.add_yaxis("近日新增",[50,50,80,60,60])
bar_1.render()
bar_2 = Bar()
bar_2.add_xaxis(["保山市","德宏州","大理州","曲靖市","红河州"])
bar_2.add_yaxis("近日新增",[60,60,10,90,30])
bar_2.render()
bar_3 = Bar()
bar_3.add_xaxis(["保山市","德宏州","大理州","曲靖市","红河州"])
bar_3.add_yaxis("近日新增",[10,30,30,50,20])
bar_3.render()
# 创建时间线对象
timeline = Timeline({"theme":ThemeType.ROMANTIC}) # [可选项]可设置主题
# 为时间线添加Bar柱状图对象
timeline.add(bar_1,"10.1")
timeline.add(bar_2,"10.2")
timeline.add(bar_3,"10.3")
# [可选项]可设置自动播放
timeline.add_schema(
play_interval=1000, # 间隔几毫秒播放下一张
is_timeline_show=True, # 是否显示时间线
is_auto_play=True, # 是否自动播放
is_loop_play=True # 是否自动循环播放
)
# 绘图
timeline.render()
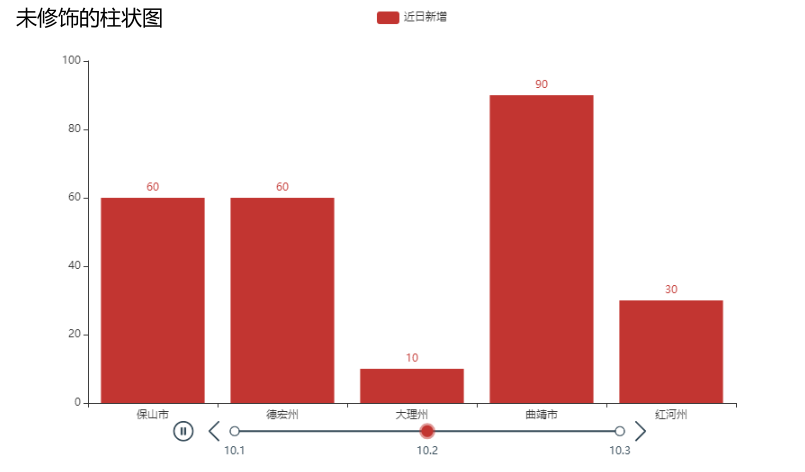
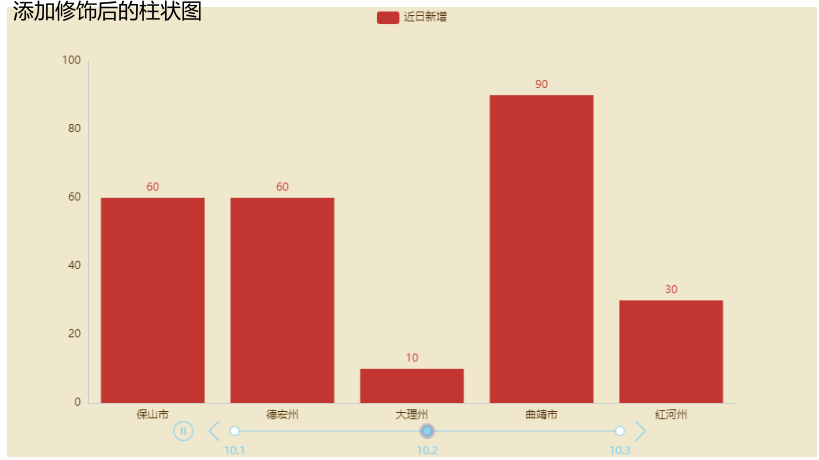
主题选项
| 编号 | 颜色 | 备注 |
|---|---|---|
| ThemeType.WHITE | 红蓝 | 默认颜色等同于 bar=Bar() |
| ThemeType.LIGHT | 蓝黄粉 | 高亮颜色 |
| ThemeType.DARK | 红蓝 | 黑色背景 |
| ThemeType.CHALK | 红蓝 绿 | 黑色背景 |
| ThemeType.ESSOS | 红黄 | 暖色系 |
| ThemeType.INFOGRAPHIC | 红蓝黄 | 偏亮 |
| ThemeType.MACARONS | 紫绿 | |
| ThemeType.PURPLE_PASSION | 粉紫 | 灰色背景 |
| ThemeType.ROMA | 红黑灰 | 偏暗 |
| ThemeType.ROMANTIC | 红粉蓝 | 淡黄色背景 |
10.3.3 GDP动态柱状图绘制
- 指定方式排序 – 带名函数形式
列表.sort(key=排序依据的函数,reverse=True|False)
** ·** 参数 key 传入一个函数(将列表的每一个元素都传入函数中,返回排序的依据) · 参数 reverse,是否反转排序结果(True为降序,False为升序)
my_list = [['a',5],['b',3],['c',4],['d',1],['e',2]]
def order(value): # 定义一个函数,用于传入列表内每一个元素
return value[1] # 返回指定下标的元素作为下一步排序的依据
my_list.sort(key=order,reverse=False) # 指定方式排序
print(my_list)
————————————————————————————————————————————————————————
[['a', 5], ['b', 3], ['c', 4], ['d', 1], ['e', 2]]
进程已结束,退出代码0
- 指定方式排序 – 匿名 lambda 形式
my_list = [['a',5],['b',3],['c',4],['d',1],['e',2]]
my_list.sort(key=lambda order:order[1],reverse=False)
print(my_list) # 可自定义传入形式参数代替函数返回值(例order:order[1])
————————————————————————————————————————————————————————
[['d', 1], ['e', 2], ['b', 3], ['c', 4], ['a', 5]]
进程已结束,退出代码0
















 2309
2309











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











