







数据集介绍
使用的数据集是肺癌和结肠癌组织病理学图像,该据集包含了25000张组织病理图像,所有图像的皆为 768 x 768 像素。该数据集共有 5个类别,分别为结肠腺癌、良性结肠组织、肺腺癌、肺鳞状细胞癌和良性肺组织,每类各有5000 张图像。以深度学习算法为代表的人工智能技术正在积极推动医学影像领域的发展,但这项技术需要大量的临床数据予以支持。肺癌和结肠癌作为临床上常见的两种癌症,公开的、能够提供给研发人员的相关影像数据却十分稀少。为此,作者在James A. Haley Veterans'医院的支持和帮助下,完成了该数据集的图像采集与标注工作,同时允许所有人免费下载,助力人工智能技术在这一领域的创新与应用。
结构如下:
代码
ResNet模型
from d2l import torch as d2l
import torch
from torch import nn
import matplotlib.pyplot as plt
class Residual(nn.Module):
def __init__(self, input_channels, num_channels, use_1x1conv2d=False, stride=1):
super(Residual, self).__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1, stride=stride)
self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3, padding=1)
if use_1x1conv2d:
self.conv3 = nn.Conv2d(input_channels, num_channels, kernel_size=1, stride=stride)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, X):
Y = self.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y = X + Y
return self.relu(Y)
b1 = nn.Sequential(nn.Conv2d(in_channels=1,out_channels=64,kernel_size=7,padding=3,stride=2),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,padding=1,stride=2))
def resnet_block(input_channels, num_channels, num_residuals, first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(
Residual(input_channels, num_channels, use_1x1conv2d=True, stride=2)
)
else:
blk.append(
Residual(num_channels, num_channels)
)
return blk
b2 = nn.Sequential(
*resnet_block(64, 64, 2, first_block=True)
)
b3 = nn.Sequential(
*resnet_block(64, 128, 2)
)
b4 = nn.Sequential(
*resnet_block(128, 256, 2)
)
b5 = nn.Sequential(
*resnet_block(256, 512, 2)
)
net = nn.Sequential(
b1, b2, b3, b4, b5, nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(),
nn.Linear(512, 10)
)
AlexNet模型
class AlexNet(nn.Module):
def __init__(self, num_classes: int = 1000, dropout: float = 0.5) -> None:
super().__init__()
_log_api_usage_once(self)
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(p=dropout),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=dropout),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x自定义数据集代码
MyData.py
import os
from torch.utils.data import Dataset
from PIL import Image
import torchvision.transforms as transforms
class ColonDataset(Dataset):
def __init__(self, root_dir, transform=None):
self.root_dir = root_dir
self.transform = transform
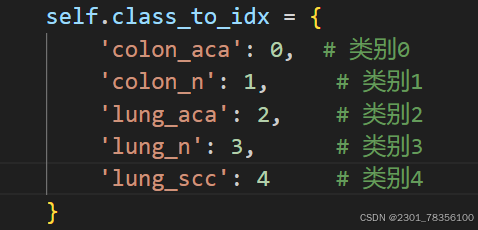
# 定义类别到标签的映射
self.class_to_idx = {
'colon_aca': 0, # 类别0
'colon_n': 1, # 类别1
'lung_aca': 2, # 类别2
'lung_n': 3, # 类别3
'lung_scc': 4 # 类别4
}
# 存储所有图像路径和对应标签
self.images = []
self.labels = []
# 遍历两个文件夹
for class_name in self.class_to_idx.keys():
class_dir = os.path.join(root_dir, class_name)
for img_name in os.listdir(class_dir):
if img_name.endswith('.jpeg'): # 确保只处理jpeg文件
img_path = os.path.join(class_dir, img_name)
self.images.append(img_path)
self.labels.append(self.class_to_idx[class_name])
def __len__(self):
"""返回数据集大小"""
return len(self.images)
def __getitem__(self, idx):
"""根据索引返回图像和标签"""
img_path = self.images[idx]
label = self.labels[idx]
# 加载图像
image = Image.open(img_path).convert('RGB') # 转换为RGB格式
# 应用变换(如果有)
if self.transform:
image = self.transform(image)
return image, label
# data_transforms = transforms.Compose([
# transforms.Resize((224, 224)), # 调整大小,可以根据需要修改
# transforms.ToTensor(), # 转换为张量
# transforms.Normalize(mean=[0.485, 0.456, 0.406], # 标准化(可选)
# std=[0.229, 0.224, 0.225])
# ])
# # 创建数据集实例
# dataset = ColonDataset(
# root_dir='./data', # data文件夹路径
# transform=data_transforms
# )
# # 检查数据集大小
# print(f"数据集大小: {len(dataset)}")
# image, label = dataset[6666]
# print(f"第一个样本 - 图像形状: {image.shape}, 标签: {label}")训练代码
train.py
import torch
import torch.nn as nn
from torchvision import models,transforms
from torch.utils.data import DataLoader,random_split
from tqdm import tqdm
from MyData import ColonDataset
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 数据集路径
root_dir = './data'
# 设置超参数
batch_size = 128
lr = 2e-4
epochs = 10
weight_decay = 1e-3
num_classes = 5
# 数据增强
transform = transforms.Compose([
transforms.Resize(256),
transforms.RandomRotation(20),
transforms.RandomHorizontalFlip(),
transforms.CenterCrop(224),
transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
dataset = ColonDataset(root_dir=root_dir, transform=transform)
total_size = len(dataset)
train_size = int(total_size * 0.7)
valid_size = total_size - train_size
train_dataset, valid_dataset = random_split(dataset, [train_size, valid_size])
# 创建dataloader
train_loader = DataLoader(train_dataset, batch_size, shuffle=True, num_workers=4)
valid_loader = DataLoader(valid_dataset, batch_size, num_workers=4)
# 加载模型
# model = models.resnet50(weights=models.ResNet50_Weights.IMAGENET1K_V1)
model = models.AlexNet(num_classes=5)
# model.fc = nn.Linear(model.fc.in_features, num_classes)
model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr, weight_decay=weight_decay)
for epoch in range(epochs):
model.train()
print(f'第{epoch+1}个eopch开始了!!!!!!')
train_losses = []
train_accs = []
for batch in tqdm(train_loader, desc="Epoch {epoch + 1}/{epochs}"):
img, label = batch
img, label = img.to(device), label.to(device)
outputs = model(img)
loss = criterion(outputs, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
acc = (outputs.argmax(dim=-1) == label).float().mean()
train_losses.append(loss.item())
train_accs.append(acc)
train_loss = sum(train_losses) / len(train_losses)
train_acc = sum(train_accs) / len(train_accs)
print(f"[ Train | {epoch + 1:03d}/{epochs:03d} ] loss = {train_loss:.5f}, acc = {train_acc:.5f}")
# 验证阶段
model.eval()
with torch.no_grad():
valid_losses = []
valid_accs = []
for batch in tqdm(valid_loader, desc="valid"):
img, label = batch
img, label = img.to(device), label.to(device)
outputs = model(img)
loss = criterion(outputs, label)
acc = (outputs.argmax(dim=-1) == label.to(device)).float().mean()
valid_losses.append(loss.item())
valid_accs.append(acc)
valid_loss = sum(valid_losses) / len(valid_losses)
valid_acc = sum(valid_accs) / len(valid_accs)
print(f"[ Valid | {epoch + 1:03d}/{epochs:03d} ] loss = {valid_loss:.5f}, acc = {valid_acc:.5f}")
结果
使用预训练的resnet50 5个epoch准确率就能达到0.97
如果从头训练resnet50 10个epoch准确率能达到0.92
使用简单的AlexNet网络从头训练 10个epoch准确率能达到0.88


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









