







一、消息的堆积问题
1.1 什么是消息的堆积问题
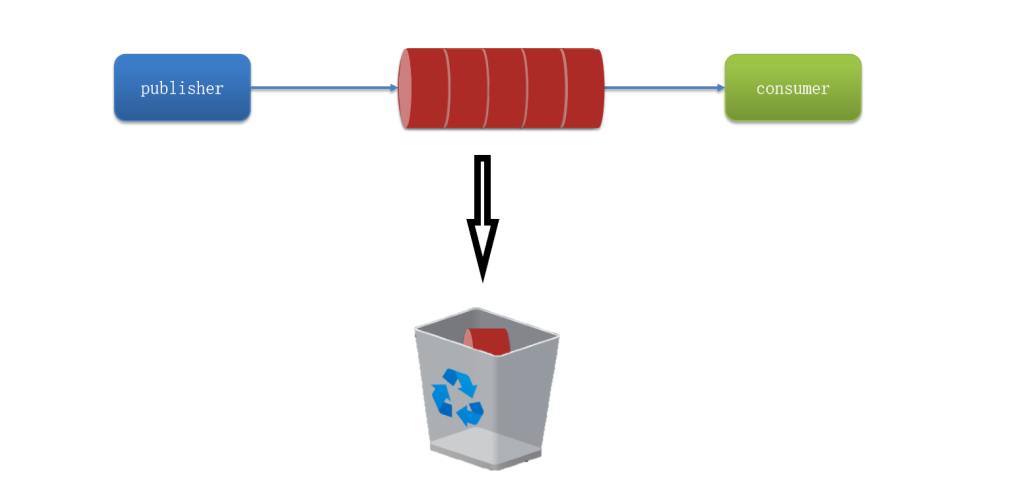
消息的堆积问题是指在消息队列系统中,当生产者以较快的速度发送消息,而消费者处理消息的速度较慢,导致消息在队列中积累并达到队列的存储上限。在这种情况下,最早被发送的消息可能会在队列中滞留较长时间,直到超过队列的容量上限。当队列已满且没有更多的可用空间来存储新消息时,新的消息可能无法进入队列,从而导致消息丢失。这种情况下的消息通常被称为死信,因为它们无法被正常消费。
例如,下图展示了消息堆积问题的情景,其中消息的堆积超出了队列的容量上限,导致部分消息成为死信并被丢弃:
1.2 消息堆积的解决思路
解决消息堆积问题通常需要采取以下三种主要思路:
- 增加更多消费者,提高消费速度:一种解决方案是增加消费者,以提高消息的处理速度。通过增加并行消费者,系统可以更快地处理消息,减少消息在队列中的滞留时间。这种方式适用于可以水平扩展消费者的情况。
- 在消费者内开启线程池加快消息处理速度:在消费者内部采用线程池的方式,可以有效提高消息的处理速度。通过并发处理消息,消费者能够更有效地消费队列中的消息,缓解堆积问题。
- 扩大队列容积,提高堆积上限:增加队列的容量上限是另一种解决方案。通过扩大队列的容积,系统能够容纳更多的消息,延长消息在队列中的存留时间,从而减少消息堆积的概率。这对于短期高峰消息负载的情况可能有帮助。
根据实际需求和资源,可以选择一种或多种解决思路来应对消息的堆积问题。每种方法都有其适用的场景,选择合适的解决方案对于确保消息队列系统的稳定性和性能至关重要。
下面将演示如何创建惰性队列,来解决消息的堆积问题。
二、惰性队列解决消息堆积问题
2.1 惰性队列和普通队列的区别
在消息队列系统中,存储和管理消息通常依赖于内存,这种方式能够提供快速的消息访问和处理。然而,在高并发场景下,当消息量达到数以百万计时,将所有消息存储在内存中可能会引发性能问题。这时,惰性队列应运而生。
自RabbitMQ的3.6.0版本开始,引入了Lazy Queues的概念,也称为惰性队列。惰性队列与普通队列之间存在以下显著区别:
惰性队列的特征:
- 消息存储在磁盘:惰性队列在接收到消息后会直接将消息存储到磁盘上,而不是保存在内存中。这意味着消息不会立即加载到内存,从而减轻了内存的压力。
- 按需加载到内存:当消费者需要消费消息时,惰性队列才会从磁盘中读取消息并加载到内存中。这种按需加载的方式确保了消息在磁盘上等待消费时不会占用大量内存资源,从而提高了系统的性能和可扩展性。
- 支持大规模消息存储:惰性队列具有出色的存储能力,可以容纳数百万条消息,从而确保消息的可靠存储和高可用性。
普通队列与惰性队列的对比:
对于普通的消息队列,如果没有开启消息的持久化,所有进入队列的消息通常都会保存在内存中,以提高消息的处理速度。然而,内存是有限的资源,RabbitMQ 通常会设置内存使用的预警值,通常为内存的40%。在消息堆积的情况下,可能会达到这个内存预警值。
此时,RabbitMQ 将采取一系列措施,通常被称为 “Paged Out”,以防止内存耗尽。这包括将超过内存预警值的消息刷出到磁盘上,从而释放一部分内存。同时,RabbitMQ 还会阻止新的消息进入队列,以避免进一步的内存消耗。这一系列过程会导致 RabbitMQ 进入间歇性的暂停状态,阻止了生产者的写入请求,最终导致消息队列的并发能力出现忽高忽低的情况,性能变得不够稳定。
相比之下,惰性队列将消息直接写入磁盘,难以达到内存预警值,从而提供了更稳定的性能。然而,由于涉及磁盘的读写操作,性能可能会受到一定的限制。在选择队列类型时,需要权衡内存和磁盘的使用情况,根据具体的应用需求和性能要求来做出决策。
2.2 惰性队列的声明方式
- 使用命令行设置惰性队列
要将队列设置为惰性队列,可以通过命令行工具来实现,同时这个方式也可以将运行中的队列设置为惰性队列。以下是在 RabbitMQ 中使用命令设置队列为惰性队列:
rabbitmqctl set_policy Lazy “^lazy-queue$” ‘{“queue-mode”:“lazy”}’ --apply-to queues
对上面命令的解释:
rabbitmqctl:RabbitMQ 的命令行工具,用于执行 RabbitMQ 相关操作。set_policy:命令用于添加一个策略。Lazy:策略的名称,您可以根据需要自定义策略名称。"^lazy-queue$":使用正则表达式来匹配队列的名称。这里的正则表达式匹配队列名为 “lazy-queue” 的队列。'{"queue-mode":"lazy"}':设置队列的模式为 “lazy”,这将使队列成为惰性队列。--apply-to queues:指定策略应用于队列。这表示正在为队列应用 “lazy” 模式。
执行上述命令后,指定的队列将被设置为惰性队列,消息将以惰性队列的方式进行存储和管理。
- 使用
@Bean注解声明惰性队列
要声明一个惰性队列,可以使用Spring的@Bean注解以编程方式创建队列,并将其配置为惰性队列。以下是一个示例,展示如何使用@Bean注解创建惰性队列:
import org.springframework.amqp.core.Queue;
import org.springframework.amqp.core.QueueBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class RabbitMQConfig {
@Bean
public Queue lazyQueue() {
return QueueBuilder.durable(“lazy.queue”)
.lazy() // 设置 x-queue-mode 为 lazy
.build();
}
}
在上述示例中,首先创建一个Queue对象,名称为 “lazy.queue”,并使用QueueBuilder进行配置。然后,通过调用.lazy()方法来设置队列的模式为 “lazy”,这将使队列成为惰性队列。最后,通过调用.build()方法来构建并返回队列。
- 使用
@RabbitListener注解声明惰性队列
同样可以使用Spring的@RabbitListener注解来声明和监听惰性队列。以下是一个示例,展示如何使用@RabbitListener注解声明和监听惰性队列:
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数大数据工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)

由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新*
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)
[外链图片转存中…(img-Qbdx66AG-1712543906123)]














 9216
9216











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









