







 本文讨论了MySQL数据库中的主键选择策略,自增ID的优势以及为何推荐使用B+树索引。还介绍了事务特性、分布式事务实现方法,以及MySQL性能优化策略,包括分页、索引、SQL优化和硬件升级。此外,还涉及了主从同步过程、延迟管理及解决策略,以及海量数据处理和全局唯一ID的设计。
本文讨论了MySQL数据库中的主键选择策略,自增ID的优势以及为何推荐使用B+树索引。还介绍了事务特性、分布式事务实现方法,以及MySQL性能优化策略,包括分页、索引、SQL优化和硬件升级。此外,还涉及了主从同步过程、延迟管理及解决策略,以及海量数据处理和全局唯一ID的设计。
- 4、还可以使用虚拟列和联合索引来提升复杂查询的执行效率。
官方为什么建议采用自增id 作为主键?
答案:自增id是连续的,插入过程也是顺序的,总是插入在最后,减少了页分裂,有效减少数据的移动。所以尽量不要使用字符串(如:UUID)作为主键。
索引为什么采用B+树,而不用B-树,红黑树?
答案:提升查询速度,首先要减少磁盘IO次数,也就是要降低树的高度。
-
平衡二叉树、红黑树,都属于二叉树。时间复杂度为O(n),当表的数据量上千万时,树的深度很深,mysql读取时消耗大量 IO。另外,InnoDB引擎采用
页为单位读取,每个节点一页,但是二叉树每个节点储存一个关键词,导致空间浪费。 -
B-树,非叶子节点存储数据,占用较多空间,导致每个节点的
指针少很多,无形增加了树的深度。 -
B+树数据都存储在叶子节点,非叶子节点只存储
健值+指针,索引树更加扁平,三层深度可以支持千万级表存储。同时叶子节点之间通过链表关联,范围查找更快。 -
更多内容,参考 mysql 一棵 B+ 树能存多少条数据?
事务的特性有哪些?
答案:ACID。
-
原子性。一个事务中的操作要么全部成功,要么全部失败。
-
持久性。永久保存在数据库中。
-
一致性。总是从一个一致性的状态转换到另一个一致性的状态
-
隔离性。一个事务的修改在提交前,其他事务是感知不到的
如何实现分布式事务?
答案:
-
1、流水任务,最终一致性,前提是接口要支持幂等性
-
2、事务消息
-
3、二阶段提交
-
4、三阶段提交
-
5、TCC
-
6、Seata 框架
日常工作中,MySQL 如何做优化?
答案:
-
1、分页优化。比如电梯直达,
limit 100000,10先查找起始的主键id,再通过id>#{value}往后取10条 -
2、尽量使用
覆盖索引,索引的叶节点中已经包含要查询的字段,减少回表查询 -
3、SQL优化(索引优化、小表驱动大表、虚拟列、适当增加冗余字段减少连表查询、联合索引、排序优化、慢日志 Explain 分析执行计划)。
-
4、设计优化(避免使用NULL、用简单数据类型如int、减少 text 类型、分库分表)。
-
5、硬件优化(使用SSD 减少 I/O 时间、足够大的网络带宽、尽量大的内存)
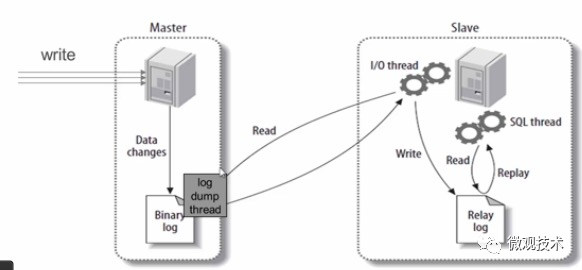
mysql 主从同步具体过程?
答案:
-
master主库,有数据更新,将此次更新的事件类型写入到主库的binlog文件中
-
主库会创建
log dump 线程通知slave有数据更新 -
slave,向master节点的 log dump线程请求一份指定binlog文件位置的副本,并将请求回来的
binlog存到本地的Relay log中继日志中 -
slave 再开启一个
SQL 线程读取Relay log事件,并在本地执行redo操作。将发生在主库的事件在本地重新执行一遍,从而保证主从数据同步
什么是主从延迟?
答案:指一个写入SQL操作在主库执行完后,将数据完整同步到从库会有一个时间差,称之为主从延迟。计算公式:
-
主库生成一条写入SQL的binlog,里面会有一个时间字段,记录写入的时间戳 t1
-
binlog 同步到从库后,一旦开始执行,取当前时间 t2
-
t2-t1,就是延迟时间
注意:不同服务器要保持时钟一致
主从延迟排查方法?
答案:通过 show slave status 命令输出的Seconds_Behind_Master参数的值来判断
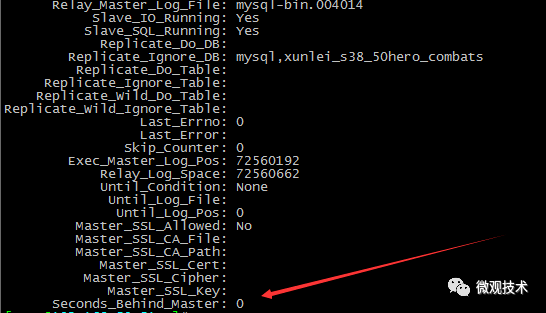
-
为零:表示主从复制良好
-
正值:表示主从已经出现延时,数字越大,表示从库延迟越严重
主从延迟要怎么解决?
答案:
-
看业务的接受程度。如果不能接受延迟,那么建议强制走主库查询
-
可以考虑引入缓存,更新主库后同步写入缓存,保证缓存的及时性
-
提升从库的机器配置,提高从库binlog的同步效率
-
缩短主、从库的网络距离,减少binlog的网络传输时间
-
一主多从,每个从库都启一个线程从主库同步 binlog,导致主库压力过大,可以采用
canal增量订阅&消费组件,缓解主库压力。 -
因为数据库必须要等到事务完成之后才会写入binlog,所以减少大事务的执行,尽量控制数量,分批执行。
-
5.6版本之前,从库是单线程复制,当遇到执行慢的sql时,就会阻塞后面的同步。5.7 版本后支持多线程复制,可以在从服务上设置
slave_parallel_workers为一个大于0的数,然后把slave_parallel_type参数设置为LOGICAL_CLOCK -
为从库增加浮动IP,并通过脚本检测从库的延迟,延迟大于指定阈值时,将浮动IP切换至Master库,追平后再切换回从库。
如果数据量太大怎么办?
答案:mysql表的数据量一般控制在千万级别,如果再大的话,就要考虑分库分表。除了分表外,列举了面对海量数据业务的一些常见优化手段
-
缓存加速
-
读写分离
-
垂直拆分
-
分库分表
-
冷热数据分离
-
ES助力复杂搜索
-
NoSQL
-
NewSQL
分表后ID如何保证全局唯一呢?
答案:分库分表后,多张表共用一套全局id,原来单表主键自增方式满足不了要求。我们需要重新设计一套id生成器。特点:全局唯一、高性能、高可用、方便接入。
-
UUID
-
数据库自增ID
-
数据库的号段模式,每个业务定义起始值、步长,一次拉取多个id号码
最后
针对最近很多人都在面试,我这边也整理了相当多的面试专题资料,也有其他大厂的面经。希望可以帮助到大家。

上述的面试题答案都整理成文档笔记。 也还整理了一些面试资料&最新2021收集的一些大厂的面试真题(都整理成文档,小部分截图)

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
-
数据库自增ID
-
数据库的号段模式,每个业务定义起始值、步长,一次拉取多个id号码
最后
针对最近很多人都在面试,我这边也整理了相当多的面试专题资料,也有其他大厂的面经。希望可以帮助到大家。
[外链图片转存中…(img-jMQiWLbv-1714422976647)]
上述的面试题答案都整理成文档笔记。 也还整理了一些面试资料&最新2021收集的一些大厂的面试真题(都整理成文档,小部分截图)
[外链图片转存中…(img-Eww3YYpn-1714422976647)]
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。















 652
652











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









