







一、什么是堆?
在学习堆排序之前要弄清什么是堆以及什么是大顶堆和小顶堆。如下图(图片来源于网络,如有侵权请联系删除):
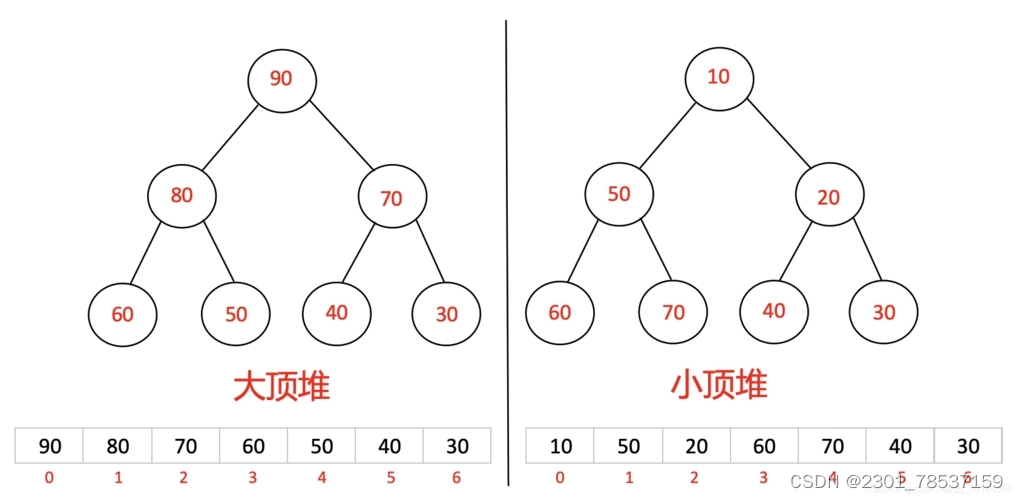
可以理解为堆是一颗完全二叉树,分为大顶堆和小顶堆。图中,其逻辑存储结构中,大根堆的每一个父节点的值都大于左孩子和右孩子节点的值;小根堆的每一个父节点的值都小于左孩子和右孩子节点的值;物理存储结构就是一个序列。
二、堆排序思想
堆排序过程主要分为两步:1.建堆。2.排序。
建堆:建堆的过程就是把元素序列调整为一个大顶堆或小顶堆。建堆从最后一个有子节点的节点开始,往前进行调整。
如果父节点下标为:i,则左孩子下标为i*2+1,右孩子下标为:i*2+2。
反之一样,如:最后一个节点元素的下标为n-1,则它的父节点应为:(n-1)//2,这个可以自己推出来。
所以建堆的代码如下:
def build_heap(list_target,n):
"""
实现建堆
:param list_target: 待建堆的列表元素
:param n: 列表的长度
:return:
"""
for i in range((n-1)//2,-1,-1):
heapify(list_target,len(list_target),i)以上代码重点关注i的取值,是从最后一个节点n-1的父节点(n-1)//2开始的,所以建堆要倒着来。其中heapify函数是以i所在的节点为当前父节点来调整堆的,其代码如下:
def heapify(list_target,n,i):
"""
实现对以i为第一个父节点的堆进行调整
:param list_target:待排序元素列表
:param n:列表长度
:param i:待维护元素下标
:return:
"""
lchild = i*2+1
rchild = i*2+2
max = i
if i >= n:
return False
if lchild <n and list_target[lchild] > list_target[max]:
max = lchild
if rchild <n and list_target[rchild] > list_target[max]:
max = rchild
if max != i :
list_target[max],list_target[i] = list_target[i],list_target[max]
heapify(list_target,n,max)把建堆和调整堆分开写,就是一个分而治之的思想。建堆就是从最后一个元素的父节点开始,一直到所有元素的根节点,倒序获取所有元素的根节点传给heapify方法进行调整。heapify方法调整的时候又是从父节点到子节点从上到下调整。这也是我觉得比较难理解的地方,可以多画图体会过程中思想的精妙。
排序:以大顶堆为例,会发现建堆后最大的元素是L[0],相当于找出了序列的最大值,把它和最后一个元素进行交换,也就是相当于把最大值存到了序列的最后面(通常用列表存储)。交换后会发现堆不再是大顶堆,这是就需要把它调整为大顶堆。
调整时从L[0]开始,调整的序列不再是先前的整个序列(因为最大值已经放到了最后面),而是慢慢变短,当调整到L[0]时,又变成了大顶堆。
以上循环下去,一直到待调整的元素个数为0时,就全部排序好了。排序的代码如下:
def heap_sort(list_target,n):
#1.建堆
build_heap(list_target,len(list_target))
#2.排序:第0个和最后1个交换,维护堆性质;第0个和倒数第2个,维护堆性质;第0个和倒数第3个,维护堆性质;......第0个和第1个,维护堆性质。
for i in range(len(list_target)-1,-1,-1):
list_target[0],list_target[i] = list_target[i],list_target[0]
#注意:这里交换之后,最后的元素已经是有序的了,维护堆性质的第二个参数(传入i,从n-1到1,长度慢慢减小到1)
heapify(list_target,i,0)排序是从最后一个元素开始的,先把L[0]和L[i]进行交换,然后再调整堆。这里需要注意的是,用了一个很巧妙的办法,然i不断减小后传入i的值作为下一次调整时列表长度的参数,即作为heapify(list_target,i,0)的第2个参数,列表长度本身并没有减小,而是取的范围变小,相当于障眼法。
要理解整个排序的动态过程,可以参考网址:
思考1:建堆的时候为什么要从最后一个节点的父节点开始?
答:这是因为大顶堆的大元素都在上面,小元素都在下面,从最后一个节点的父节点开始,可以把大的元素从堆底往上冒,向冒泡一样。
思考2:排序的时候,调整堆为什么不从最后面一个元素的父节点开始,而是从第0个节点(即根节点)开始?
答:这里我觉得很巧妙,画图模拟后会发现,交换元素后,只有根顶部的元素发生了变化,最后一个元素去掉了,所以只需要从根节点开始调整。
总结:建堆的时候,从最后一个元素的父节点开始到根节点,调整很多次;而排序的时候,交换一次,只需调整一次(当然要递归调整下层父节点,如果有的话)。















 2672
2672











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









