






1、描述性统计
爬取数据(AJAX)并进行清洗(jieba)后,可视化如下
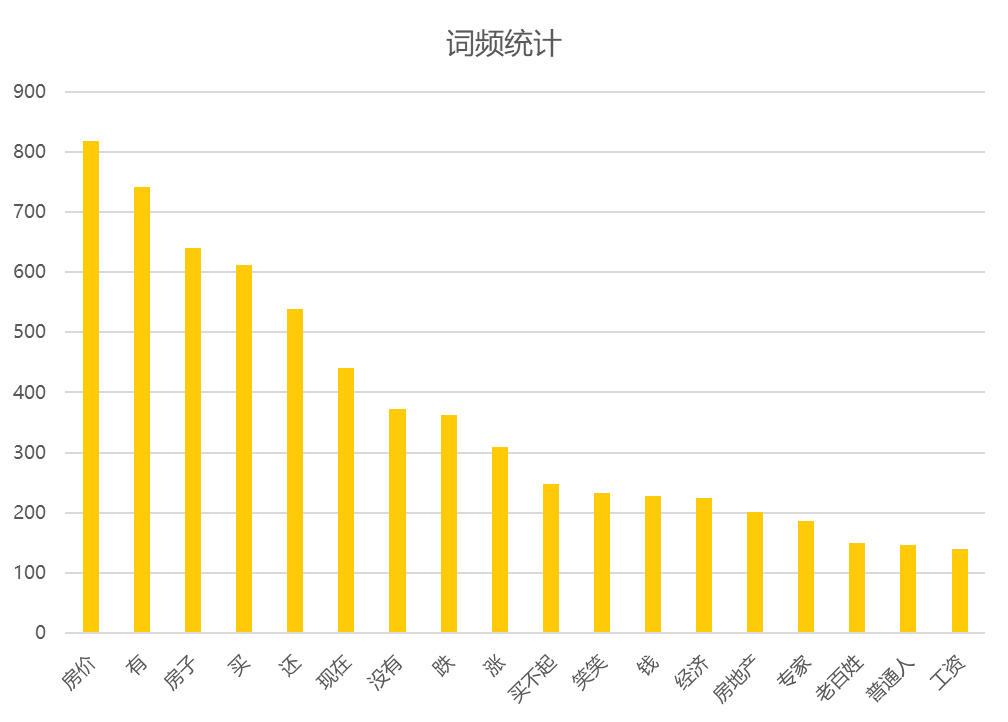

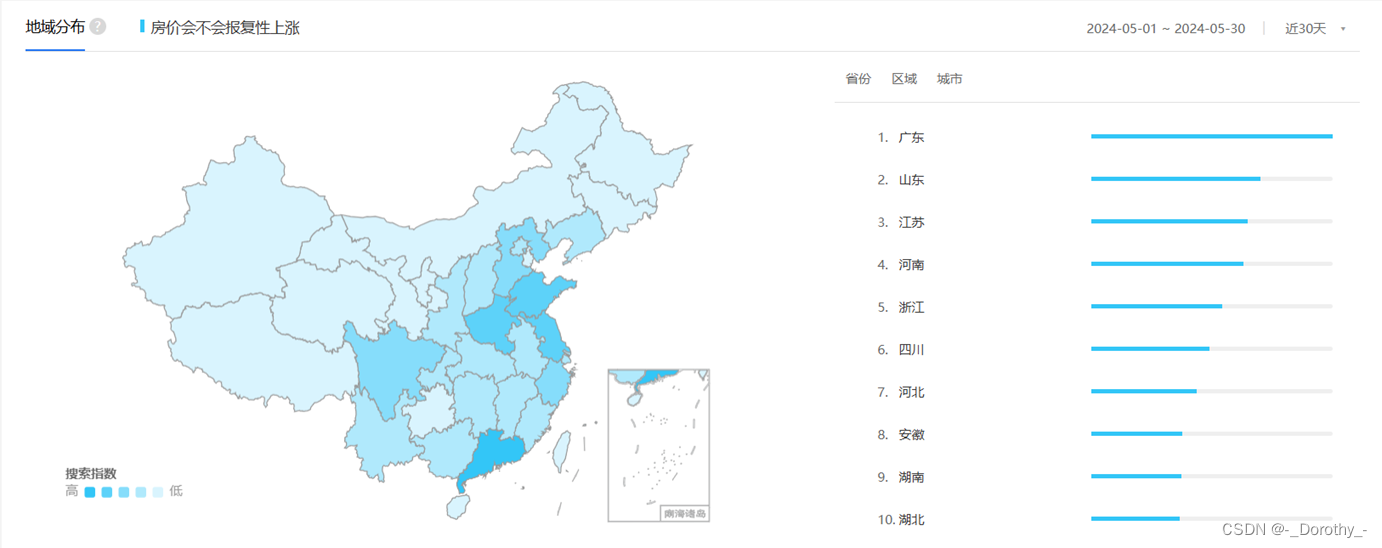
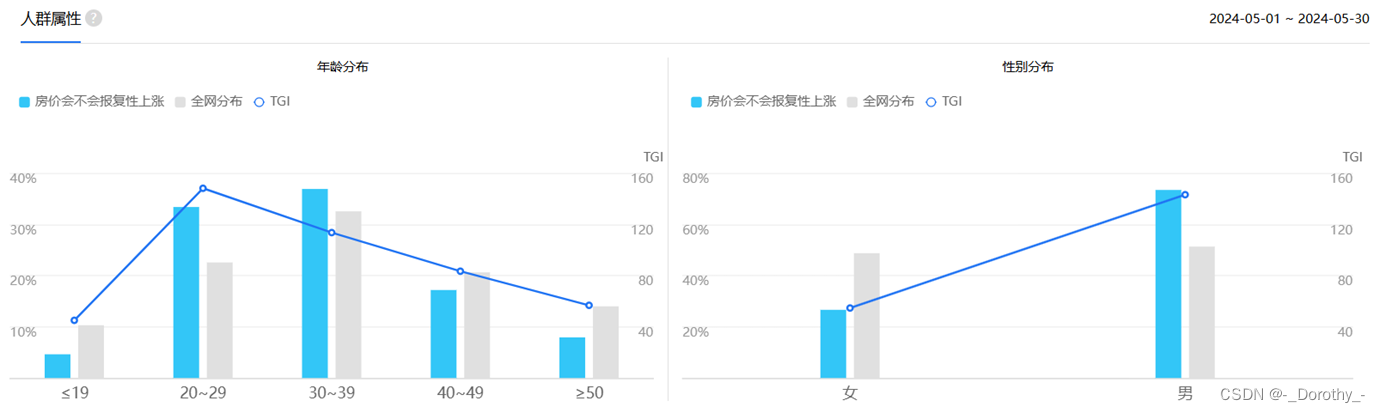
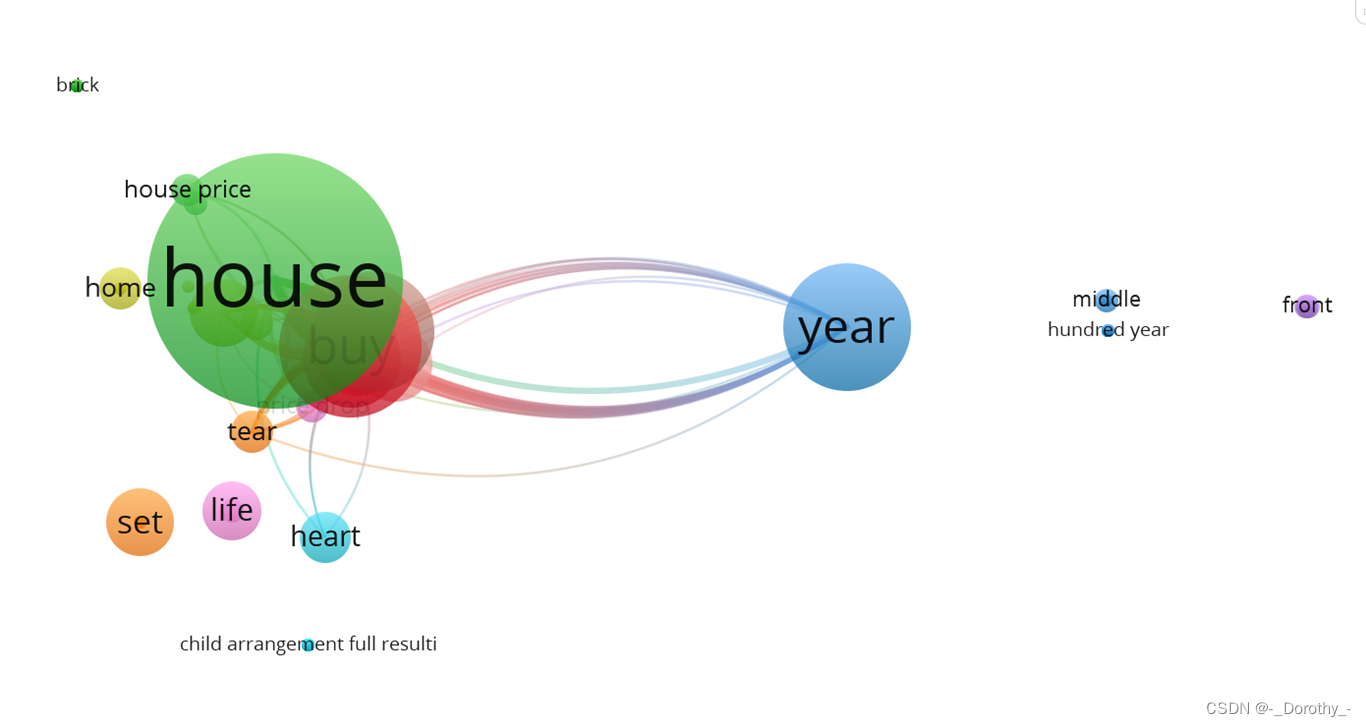
2、主题聚类
2.1 VOSviewer显示聚类效果
2.1.1 准备工作:利用百度翻译API对文本进行翻译
2.1.2 连线及圆半径的意义
1. 连线的意义
表示关系强度:在数据挖掘中,VOSVIEWER的连线通常用于表示不同数据项之间的关系。连线的粗细或颜色深浅可以直接反映这种关系的强度。
2. 圆半径的意义
表示数据点的重要性:在VOSVIEWER中,圆半径的大小通常用于表示数据点的重要性或权重。这种重要性或权重可能是基于数据的某种属性或特征计算得出的
建模分析
2.2 准备工作—— 文本特征提取——TF-IDF(Term Frequency-Inverse Document Frequency)
这是一种常用的文本特征提取方法,用于衡量单词在文档集中的重要性。其主要思想是:
- TF(词频,Term Frequency):衡量单词在一个文档中出现的频率。
- IDF(逆文档频率,Inverse Document Frequency):衡量单词在整个文档集中出现的频率。IDF的公式为: IDF ( t ) = log ( N n t ) \text{IDF}(t) = \log \left(\frac{N}{n_t}\right) IDF(t)=log(ntN) 其中,( N ) 是文档集中文档的总数,( n_t ) 是包含词语 ( t ) 的文档数。
TF-IDF的公式为: TF-IDF ( t , d ) = TF ( t , d ) × IDF ( t ) \text{TF-IDF}(t,d) = \text{TF}(t,d) \times \text{IDF}(t) TF-IDF(t,d)=TF(t,d)×IDF(t) 其中,( t ) 是单词,( d ) 是文档。
TF-IDF特征向量矩阵:通过TF-IDF向量化器,将文本转化为数值向量表示,其中每个向量的每个元素对应于某个单词在该文档中的TF-IDF值。
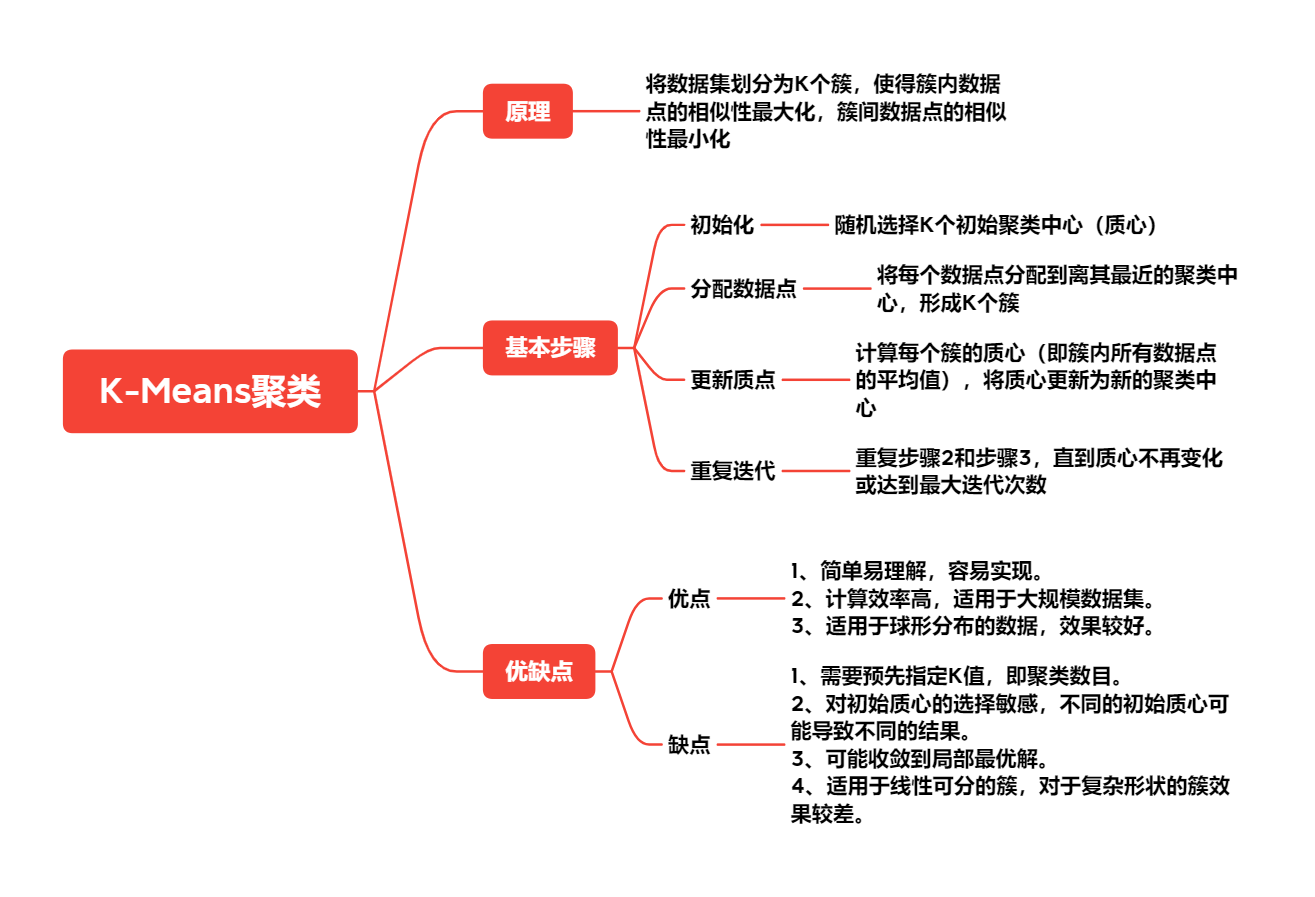
2.3 K-Means聚类
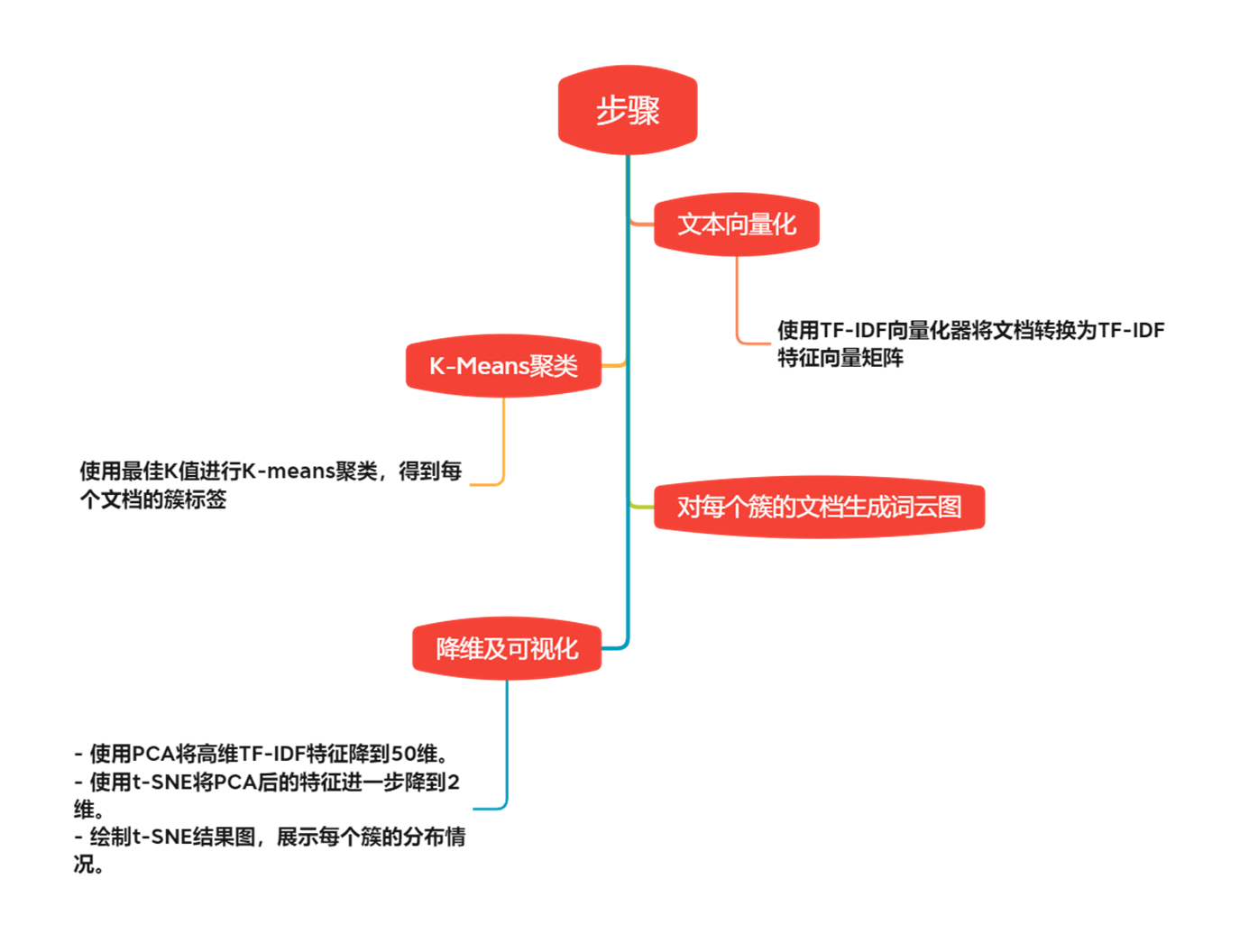
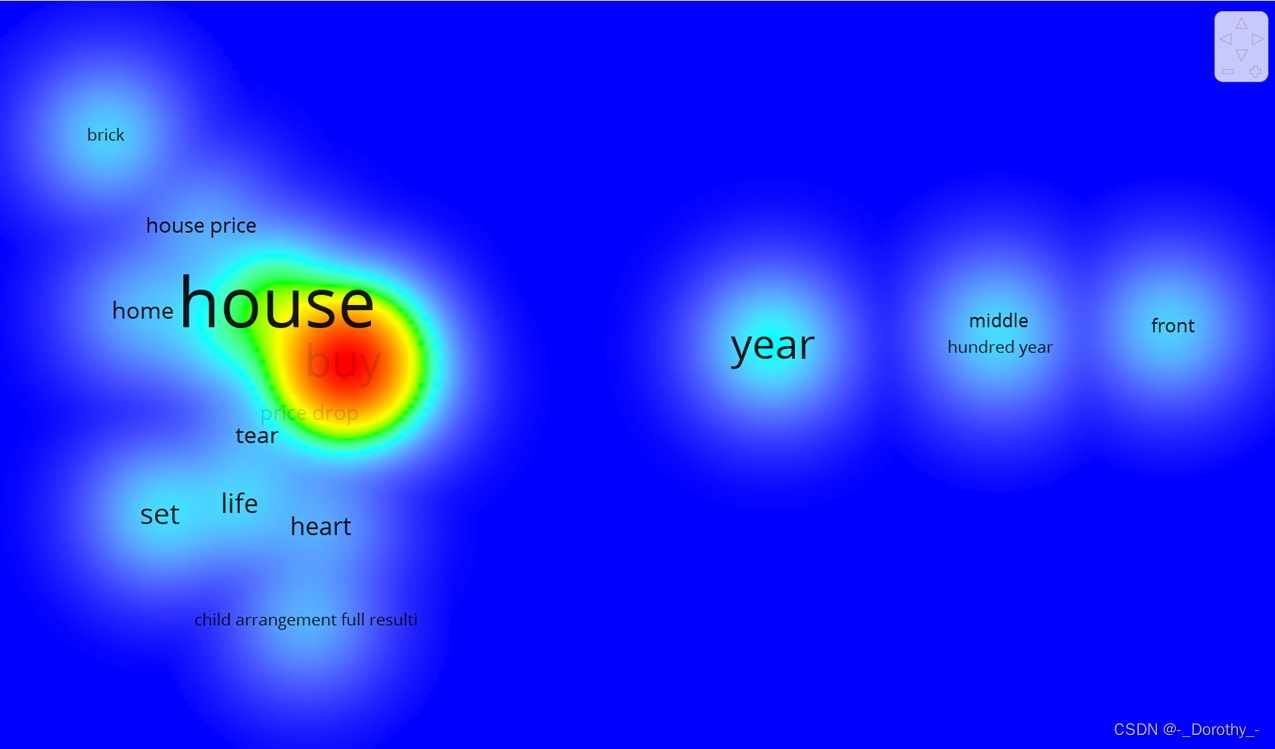
2.3.1 轮廓系数图、词云图
下面这张图片展示了K-means聚类算法的轮廓系数(Silhouette Score)随簇数(K)的变化情况。轮廓系数是一种评估聚类效果的指标,值越高,说明聚类效果越好。
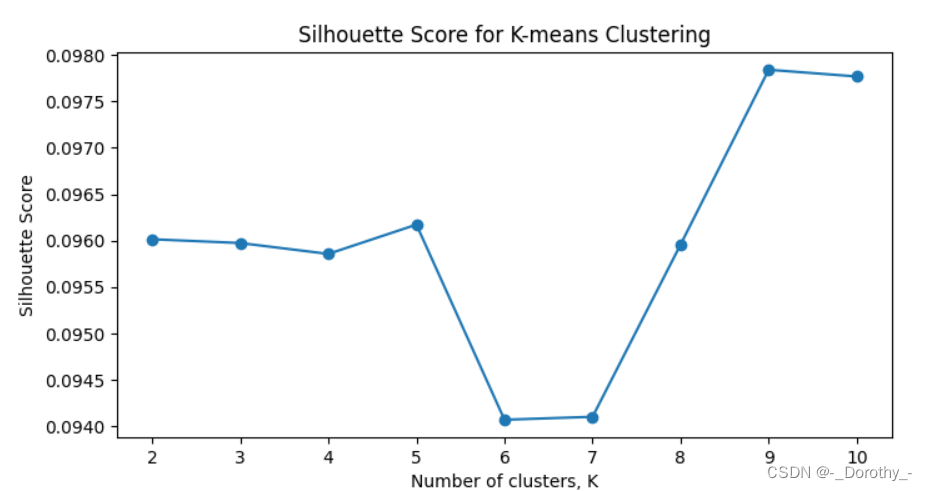
从这张图中,我们可以得到以下信息和结论:
-
轮廓系数(Silhouette Score):
- 轮廓系数是一种评估聚类效果的指标,其值在 -1 到 1 之间。值越高,表示聚类效果越好。一般来说,0.5 以上的值表示聚类效果较好,0.25 到 0.5 表示聚类效果中等,低于 0.25 表示聚类效果较差。
- 从图中可以看到,轮廓系数的值在 0.098 到 0.102 之间,表明聚类效果一般或较差。
-
最佳聚类数量(K):
- 轮廓系数在 K 值为 10 时达到最大值(约 0.102),表明在这一点上聚类效果最好。因此,K = 10 可能是最佳的聚类数量。
- 但是,即使在最佳 K 值时,轮廓系数也并不高,这表明数据可能并不适合使用 K-means 进行聚类,或者需要进一步的特征工程和数据处理。
-
K 值选择的影响:
- 当 K 值从 2 增加到 6 时,轮廓系数逐渐下降,表明聚类效果变差。
- 从 K = 7 开始,轮廓系数迅速上升,特别是在 K = 8 到 K = 10 之间,聚类效果显著改善。

2.3.2 t-SNE降维后的聚类结果
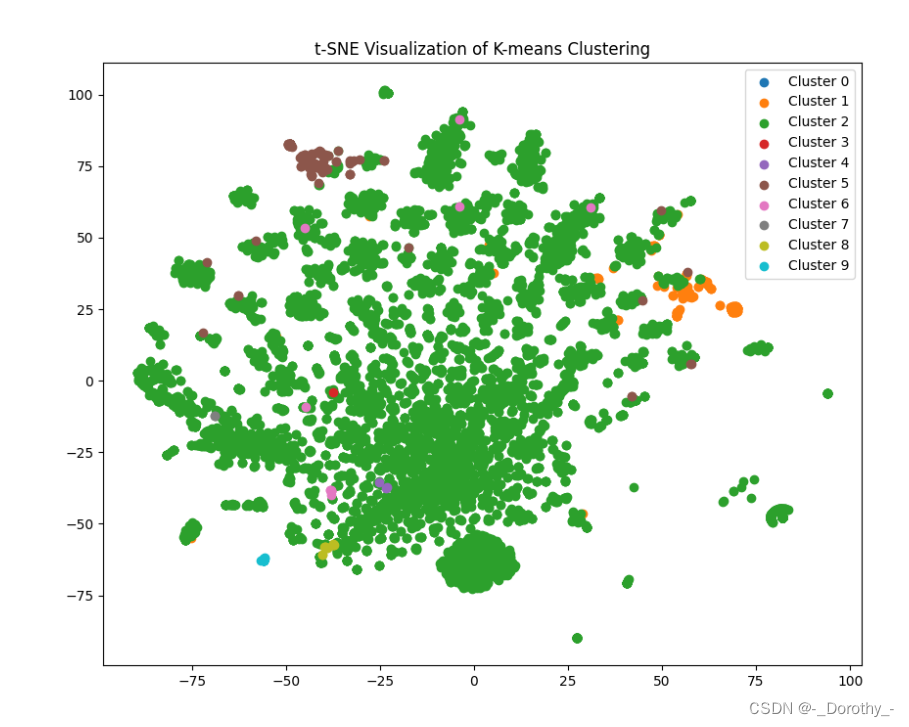
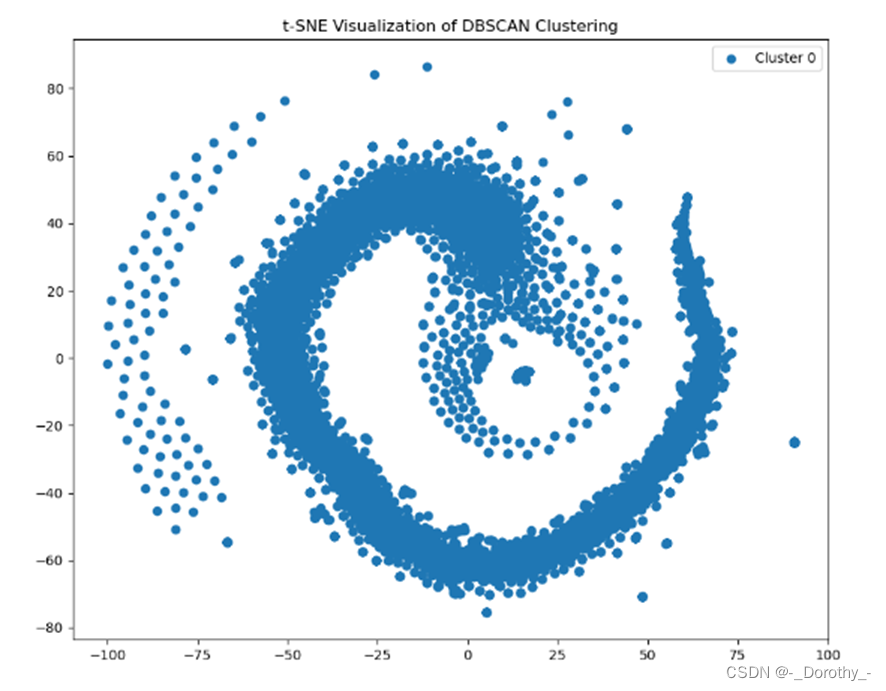
大多数数据点都集中在一个簇(Cluster 0),而其他簇的数据点较少且分散。这可能表明 K-means 聚类在这种情况下效果不佳。
可能的原因和改进方法:
- 数据本身的性质:您的数据可能不适合使用 K-means 聚类。K-means 假设簇是球形的,并且簇之间的方差相似。如果您的数据不满足这些假设,K-means 的效果可能会很差。
- 特征工程:可以尝试不同的文本预处理方法,例如去除低频词、使用不同的向量化方法(如 Word2Vec 或 BERT)等,以提高特征表示的质量。
- 聚类算法:尝试其他聚类算法,例如 DBSCAN、层次聚类(Hierarchical Clustering)或 Gaussian Mixture Models (GMM),这些算法在处理不同形状和密度的簇时可能会表现更好
- 降维方法:除了 t-SNE,还可以尝试其他降维方法,如 UMAP,以更好地可视化高维数据。
2.4、改进——文本预处理——利用使用不同的向量化方法( Word2Vec 、 BERT)提高特征表示的质量。
2.4.1 Word2Vec向量化
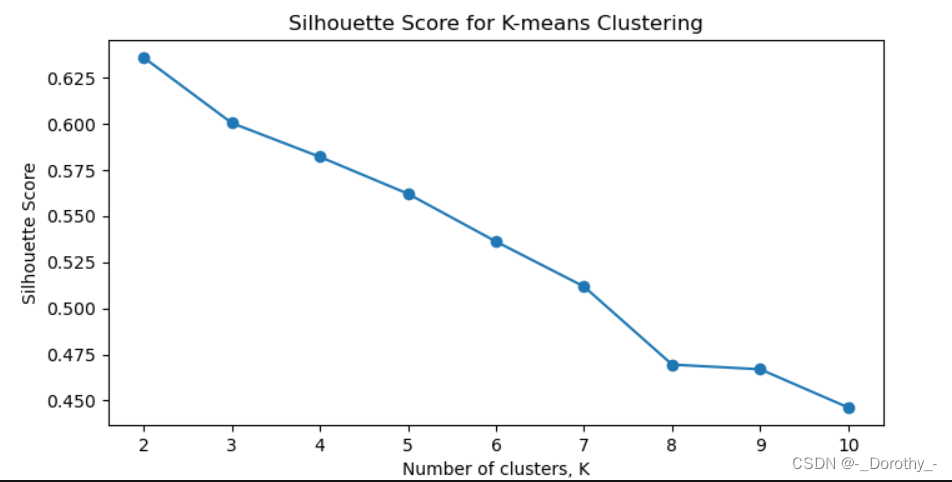
2.4.1.1 轮廓系数图、词云图
K=2 时的轮廓系数最高,表明在这个点上聚类效果最好。

2.4.1.3t-SNE降维后的聚类结果
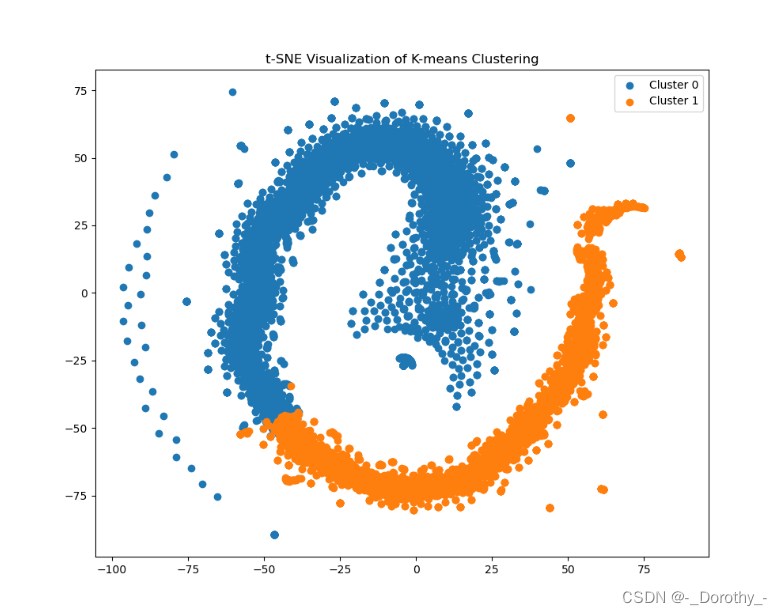
1.簇的形状:
1.Cluster 0 和 Cluster 1 分别呈现出螺旋状的分布,这表明数据在高维空间中的分布可能是非线性的。
2.t-SNE 是一种非线性降维方法,能够捕捉到高维数据中的复杂结构,因此在二维空间中显示出这种螺旋状的分布。
2.簇的密度:
1.Cluster 0 在中心区域的密度较高,而 Cluster 1 在外围区域的密度较高。
2.这表明在高维空间中,Cluster 0 可能包含更多相似的文档,而 Cluster 1 可能包含一些相对离散的文档。
3.注意:
1.K-Means 聚类假设簇是球形的,而 t-SNE 显示的螺旋状分布可能与这一假设不完全一致。因此,如果数据在高维空间中的实际分布是非线性的,需要考虑其他聚类方法( DBSCAN or 层次聚类)
2.5 DBSAN模型
2.5.1 词云图

2.5.2 t-SNE降维后的聚类结果
2.6 LDA模型

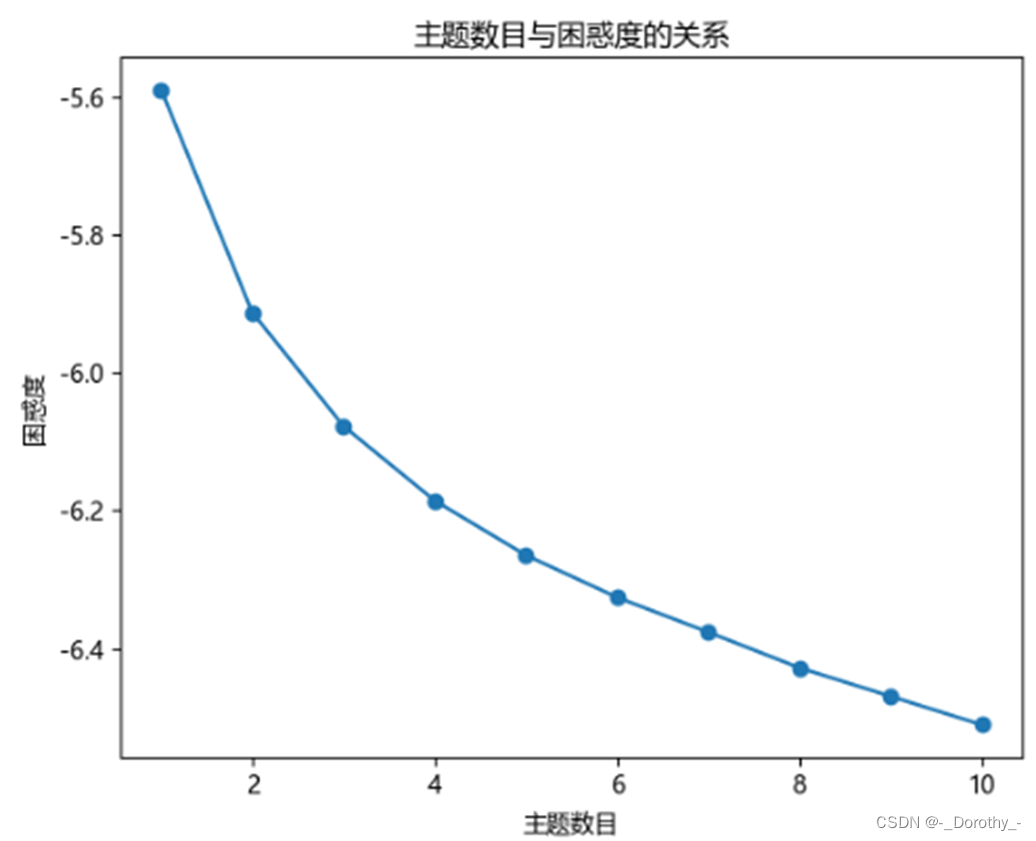
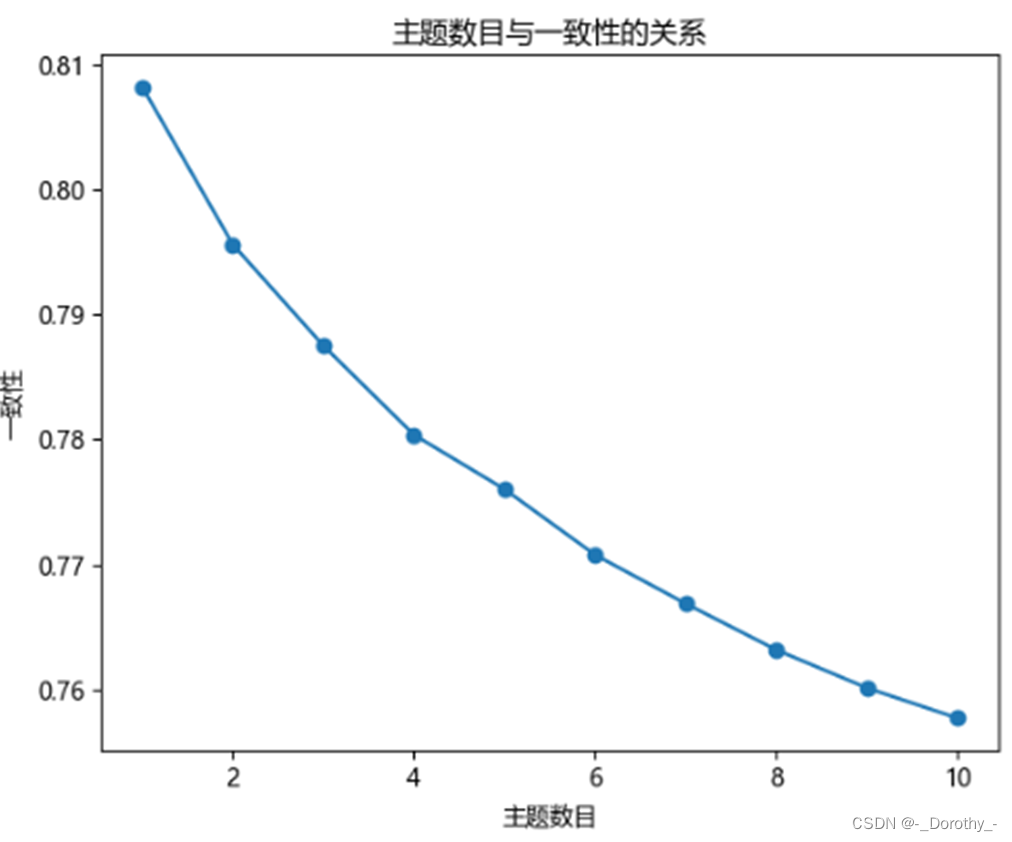
2.6.1 主题数目的确定

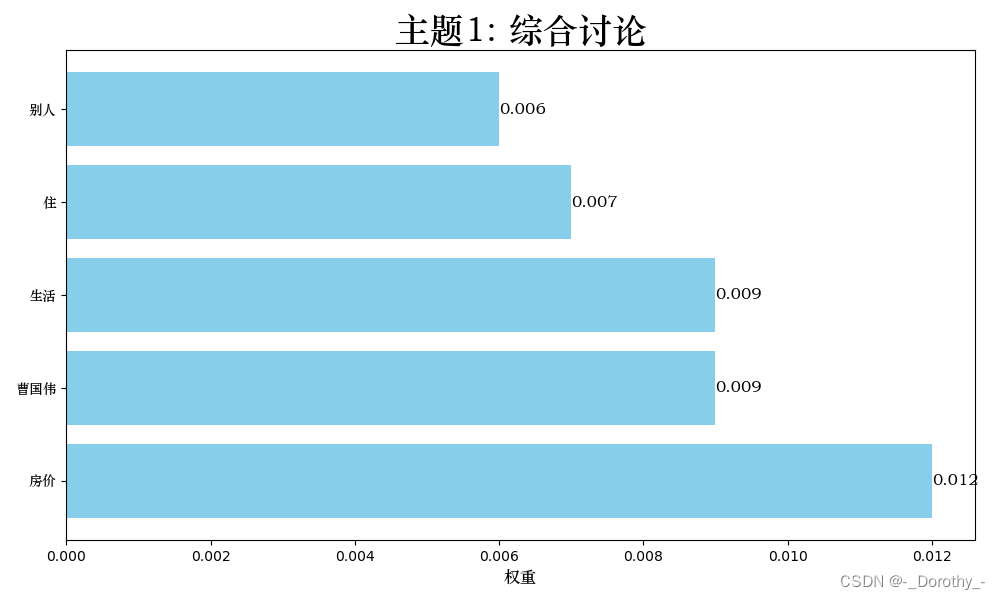
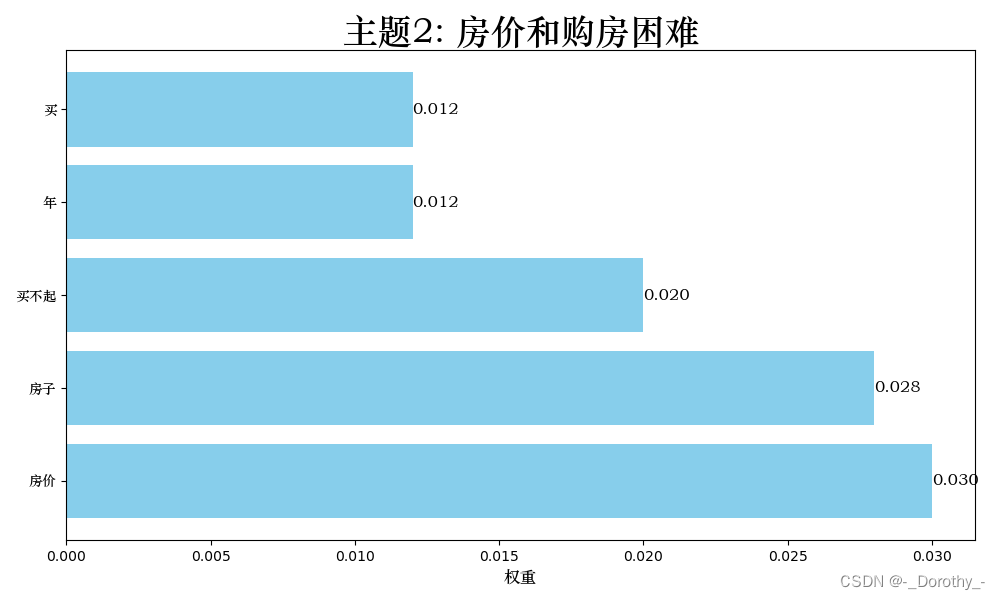
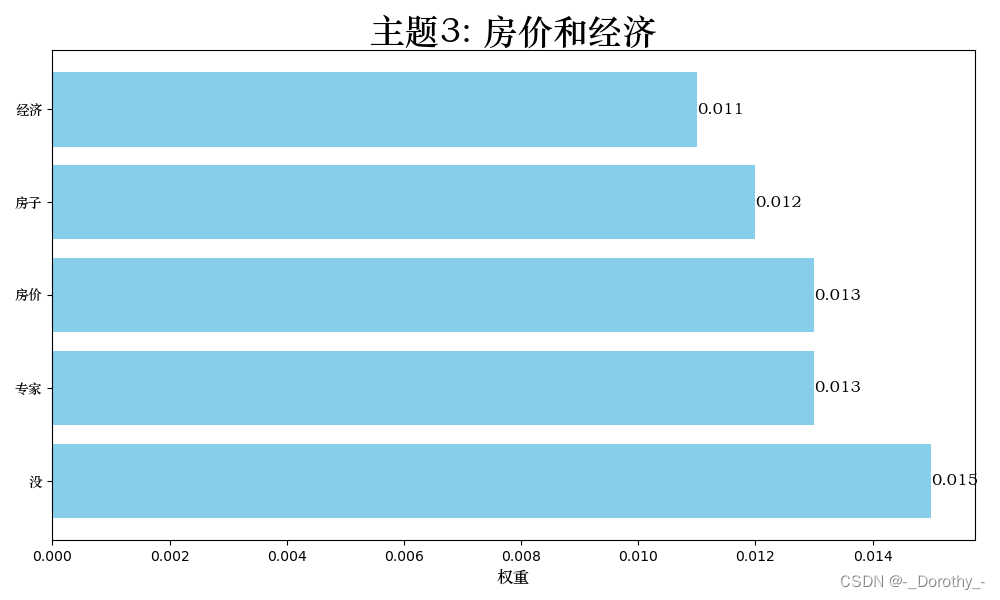
2.6.2 主题可视化
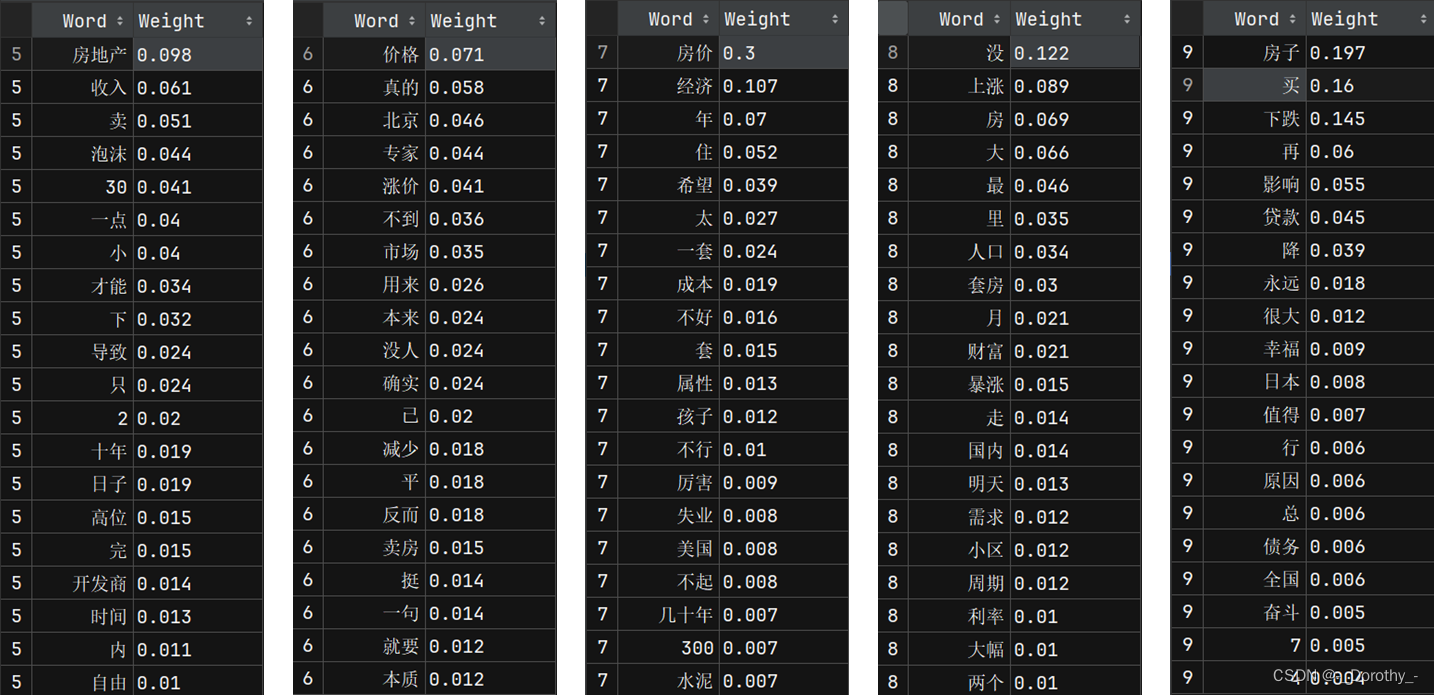
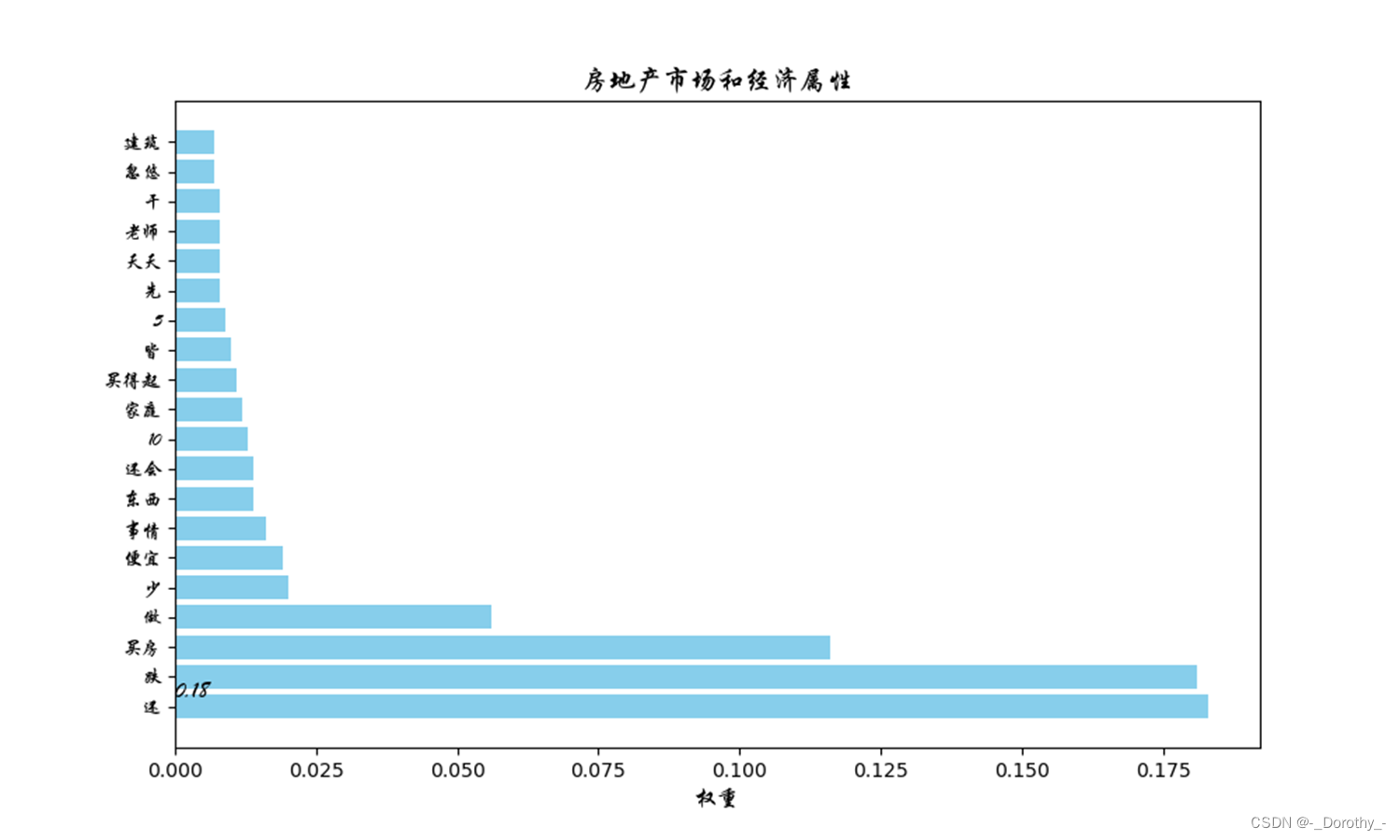
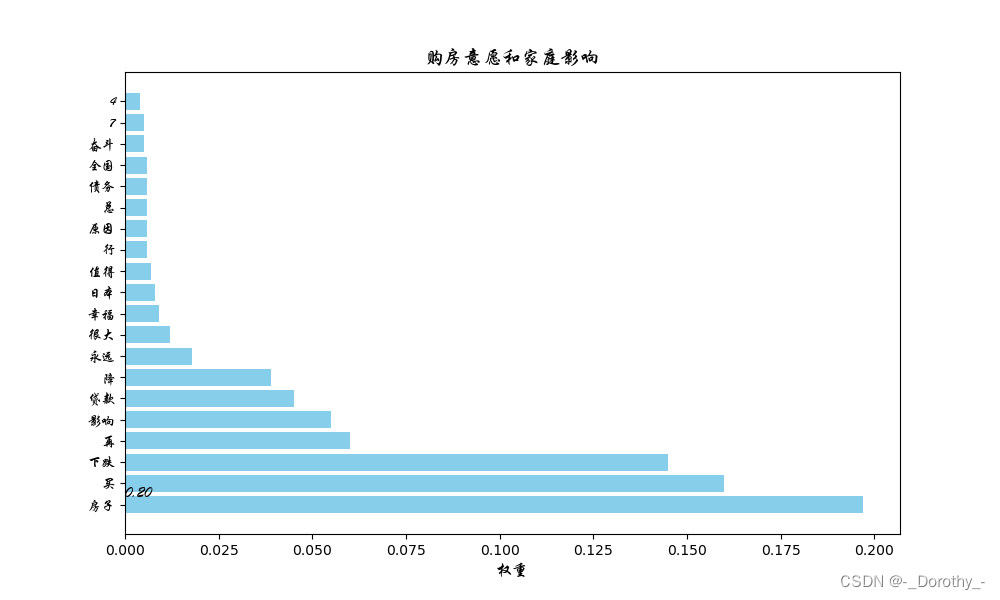
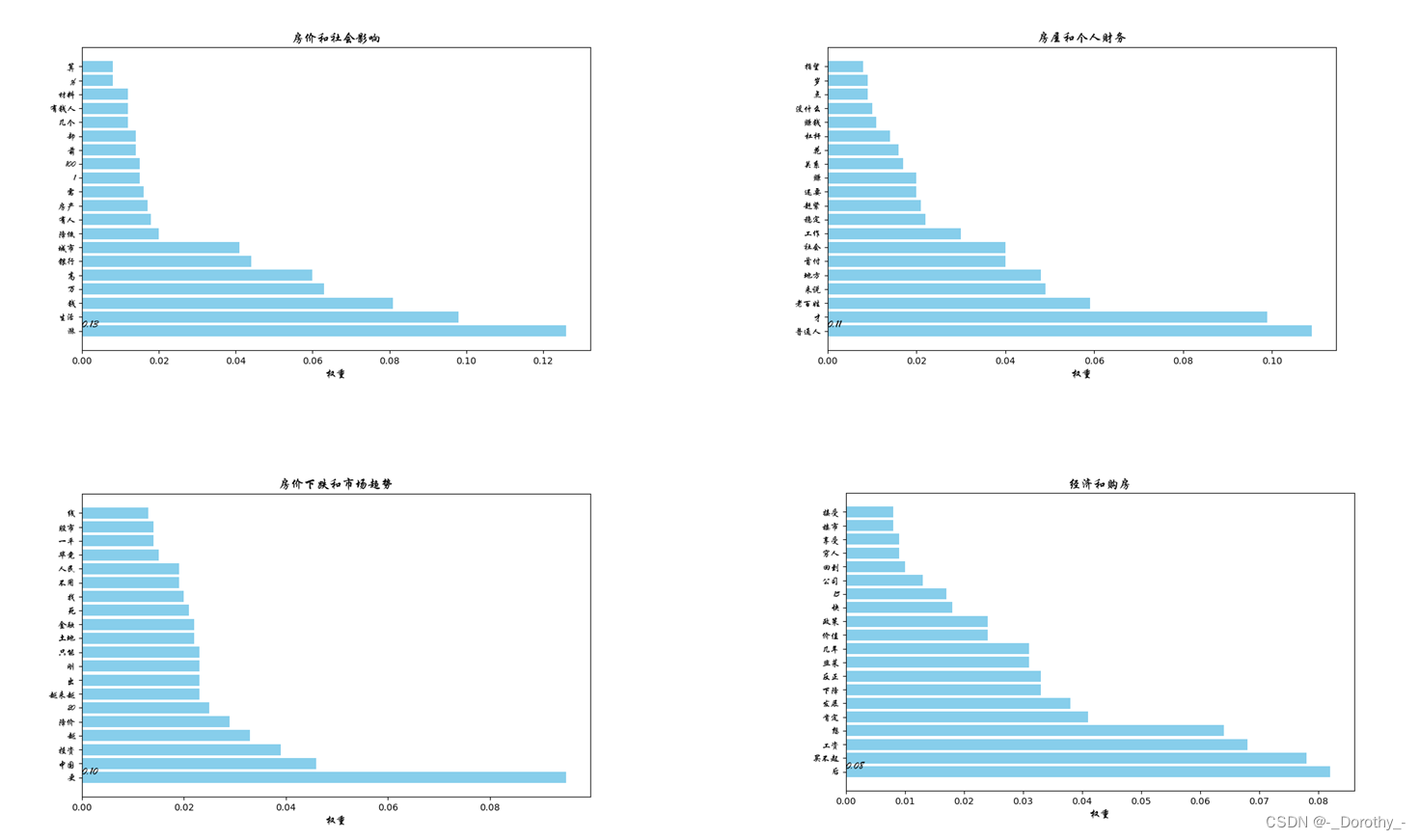
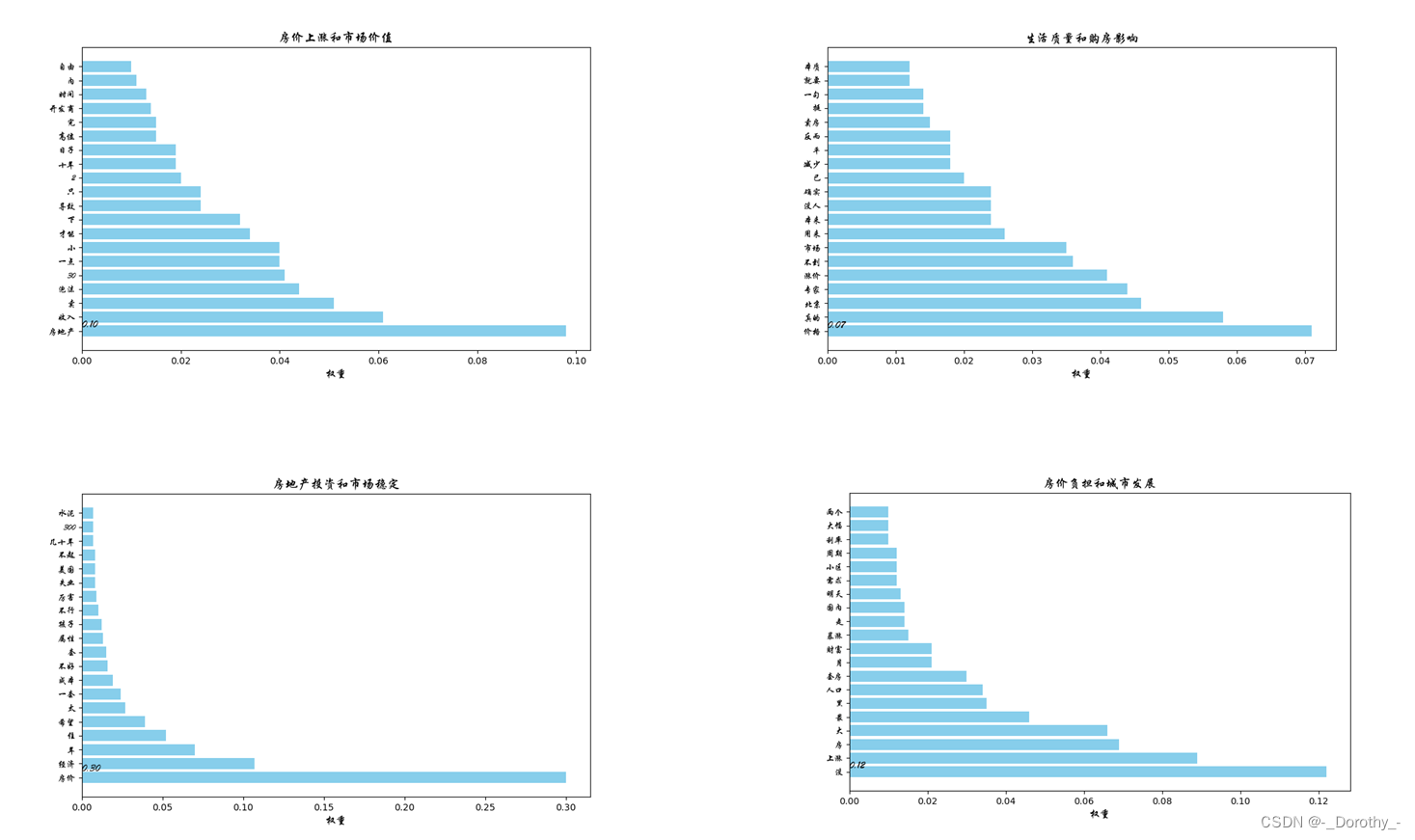
权重表示了关键词在该主题中的重要程度。权重越高表示该词在这个主题中出现的频率越高或越能代表这个主题
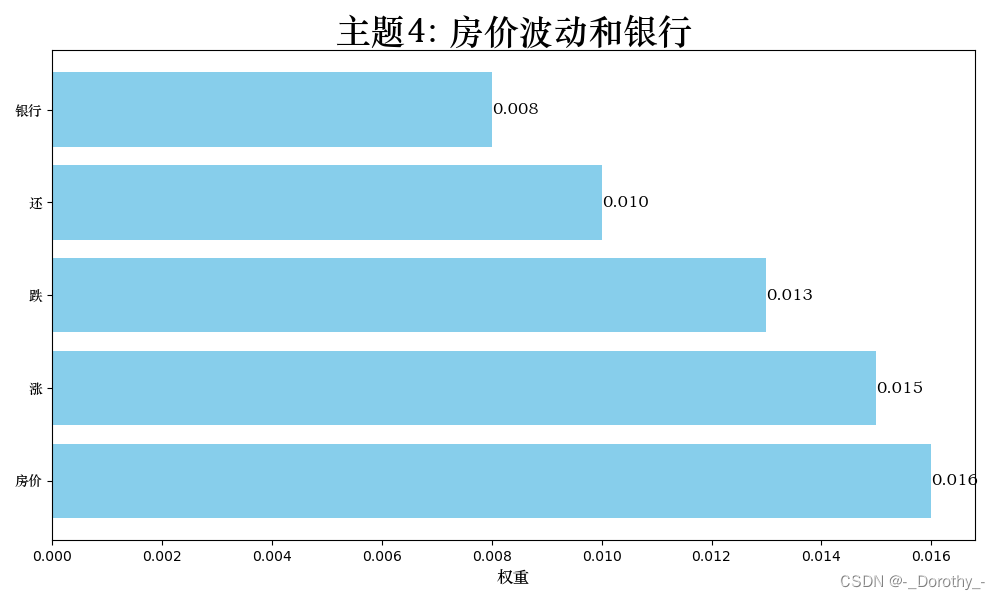
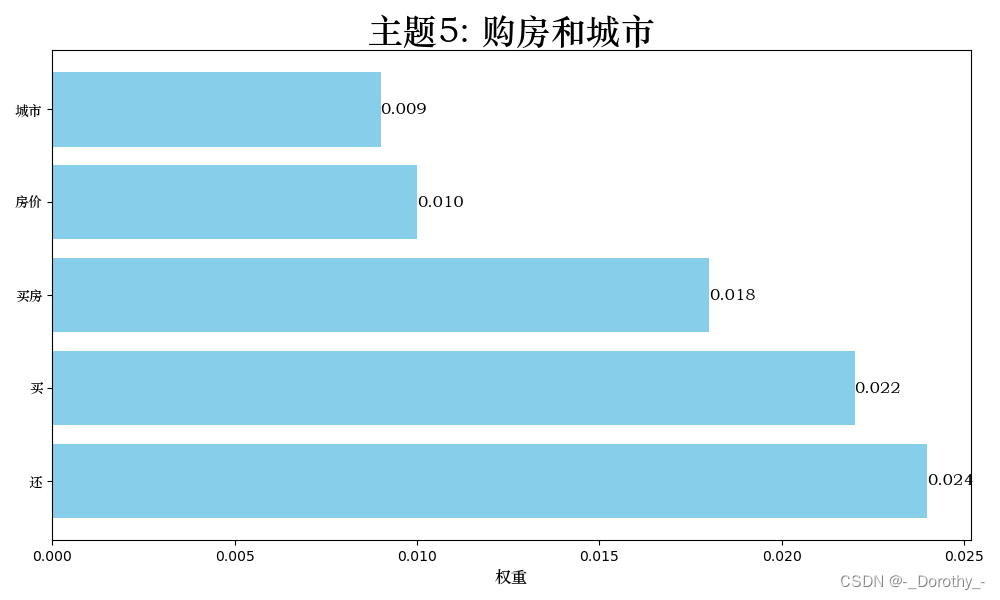
lda_vis可视化
lda_vis
lda_vis优化
各个指标理解
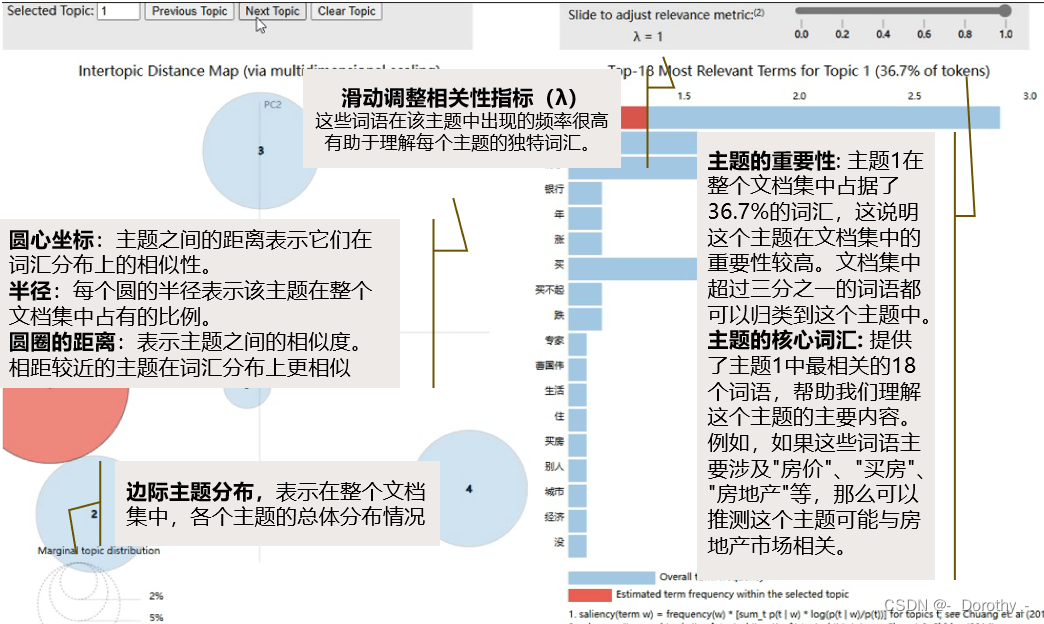
由于当主题数为10时,对文本的解释程度最好,因此这里表示10个主题的各项指标
2.6.3 主题数为10时的词袋及可视化
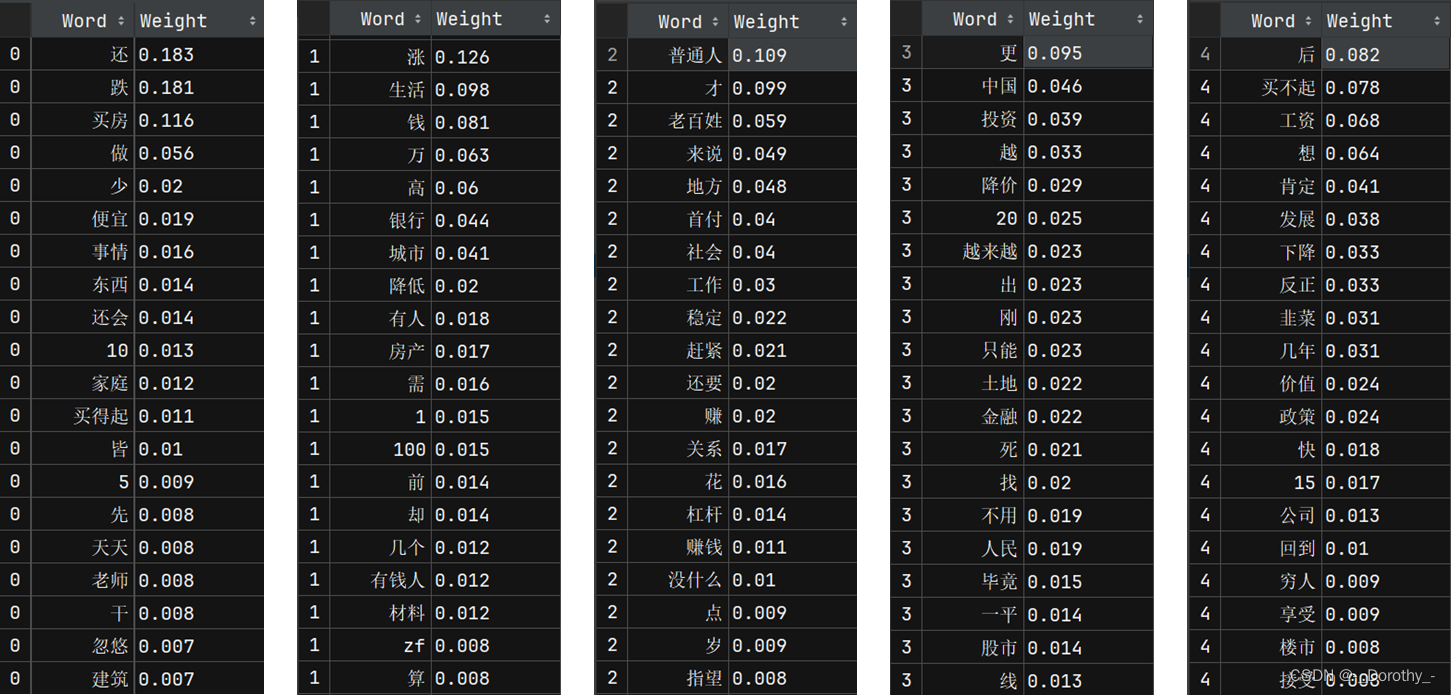
2.7 STM模型
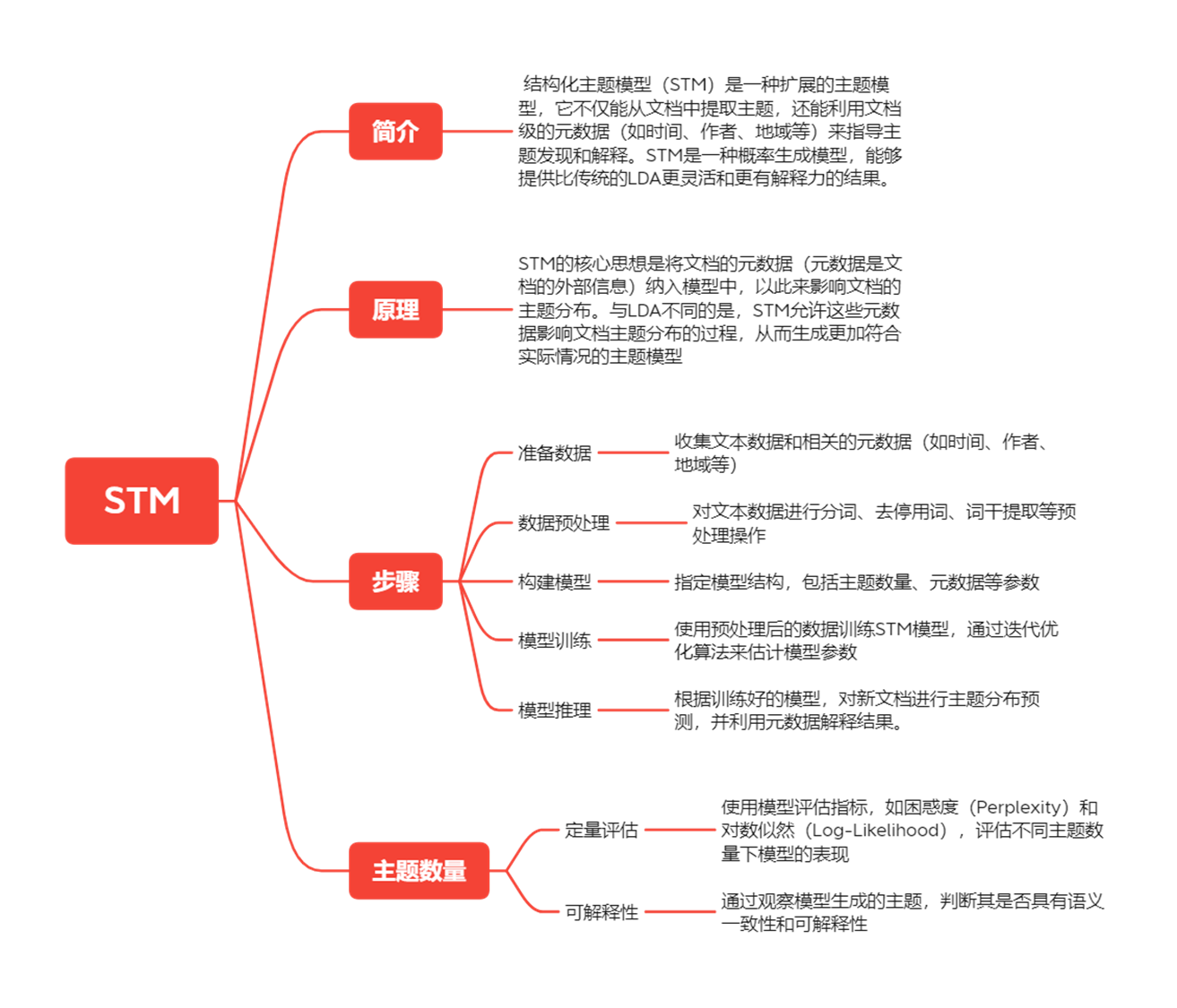
stm相对于lda最大的区别
加入了协变量,并研究协变量对话题(prevaling)流行度或普及度的影响。这种能力使得STM模型在分析文本数据时能够考虑到更多的外部因素,从而提供更全面、更准确的分析结果。这种改进使得STM能够揭示文本的更深层次的语义信息



3 各种聚类方法的横向对比

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









