






 本文通过导入pandas和机器学习模块,使用卡方检验分析了年龄、性别、BMI等变量对家庭保险费支出的影响,发现年龄、孩子数量和体重指数是主要影响因素。
本文通过导入pandas和机器学习模块,使用卡方检验分析了年龄、性别、BMI等变量对家庭保险费支出的影响,发现年龄、孩子数量和体重指数是主要影响因素。
1、使用数据集的说明:
数据表如下:
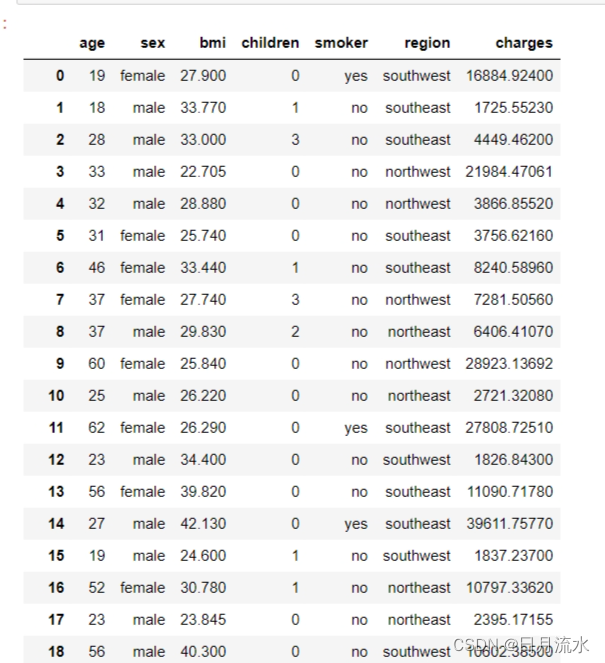
数据表的第一列分别为年龄、性别、体重指数、孩子数量、是否吸烟、所在区域、保险收费。
本文的主要目的是分析在年龄、性别、体重指数、孩子数量、是否吸烟、所在区域中这些因素中,哪些因素对家庭的保险费支出影响最大。上表的美国一区域的家庭保险费支出的历史数据。
2、首先导入pandans和一些机器学习模块,文中使用了卡方检验。
import pandas as pd
i mport numpy as np
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
df = pd.read_csv(r'F:\桌面\练习表格1\insurance.csv')
df
3、数据表的一些信息:
df.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 1338 entries, 0 to 1337 Data columns (total 7 columns): age 1338 non-null int64 sex 1338 non-null object bmi 1338 non-null float64 children 1338 non-null int64 smoker 1338 non-null object region 1338 non-null object charges 1338 non-null float64 dtypes: float64(2), int64(2), object(3) memory usage: 73.2+ KB
数据共1338行,无非空值。
4、使用数据的格式化:因为在该表中,sex、smoker和region都是非数字特征和非有序特征的普通分类序列,所有应该使用get_dummies方法来对这些列进行编码和格式化。
needcoded_columns = ['sex','smoker','region']
df_coded = pd.get_dummies(df,columns = needcode_columns,prefix = needcode_columns,dummy_na = True,drop_first = True)
5、编码和格式化后的序列为:df_coded.head()

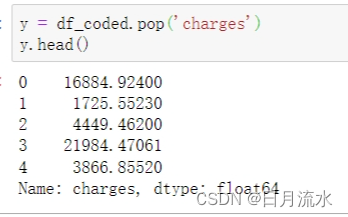
6、分离后特征序列和结果序列:
y = df_coded.pop('charges')
y.head()
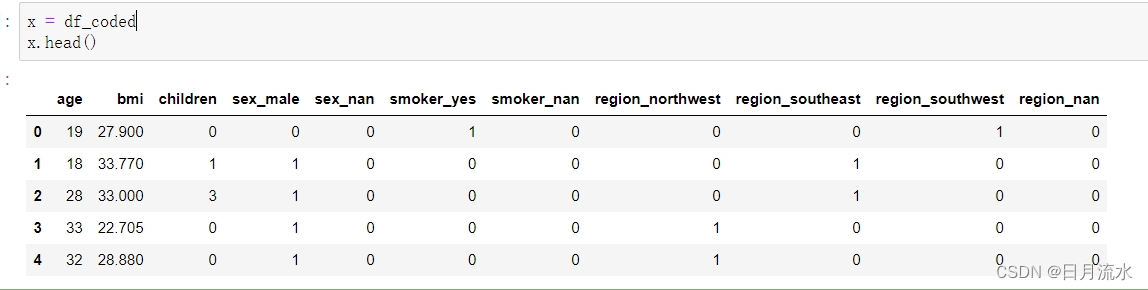
x = df_coded
x.head()
运行得到:
6、进行机器学习训练:
bestfeatures = SelectKBest(score_func = chi2,k = len(x.columns))
fit = bestfeatures.fit(x,y.astype(int))
df_scores = pd.DataFrame(fit.scores_)
df_scores
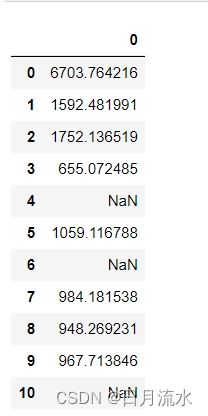
df_columns = pd.DataFrame(x.columns)
df_columns

7、对两列进行组合和连接。
df_feature_scores = pd.concat([df_scores,df_columns],axis = 1)
df_feature_scores.columns = ['scores','feature_names']
df_feature_scores
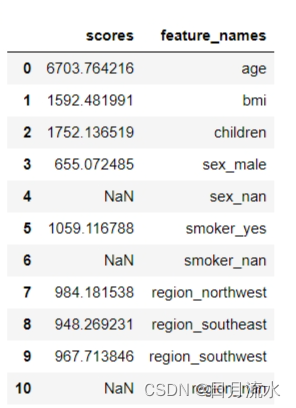
8、对数据列进行排序:df_feature_scores.sort_values(by = 'scores',ascending = False)
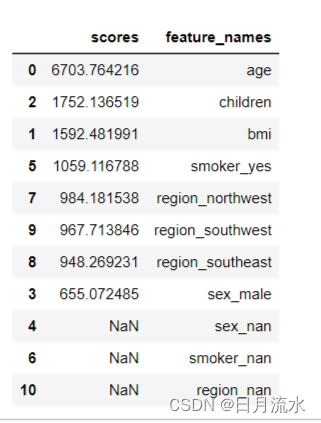
9、结论:由此得出在这些影响保险费的一些特征因素中,年龄对保险费的影响最大,其次是家庭的孩子数量对保险费的影响,再次就是体重指数,对保险支出的影响也较大。。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









