







一、实验目的和要求
题目:实现数据去重、离群点检测、缺失值处理等数据预处理。
要求:
用(但不限于)Bengaluru_House_Data.csv数据集、weight-height.csv数据集(kaggle下载)进行离群点检测与处理实验;
用weather_data.csv 、titanic_train.csv数据集(kaggle下载)进行缺失值处理实验;设计实验方案、编制相关程序并提交实验报告。
二、实验类型
实践型实验
三、主要仪器设备
1.电脑一台(Mac系统),搭载STS运行jupyter
四、实验原理
1.数据去重
数据去重是为了移除数据集中重复的记录,避免在后续分析中引入偏差。
方法:
使用 pandas 的 drop_duplicates() 方法。
可以选择保留第一个或最后一个重复项,或者完全移除所有重复项。
2.离群点检测与处理
离群点可能会影响数据分析的结果,因此需要检测和处理这些异常值。
方法:
IQR 方法:基于四分位数范围(IQR)检测离群点。
Z-Score 方法:基于标准差检测离群点。
可视化:使用箱线图(Boxplot)或散点图可视化离群点。
3.缺失值处理
处理数据中的缺失值,以确保数据的完整性和分析的准确性。
方法:
删除缺失值:直接移除包含缺失值的行或列。
填充缺失值:
使用均值、中位数或众数填充数值型或分类型列。
使用前向填充(ffill)或后向填充(bfill)。
使用插值方法(如线性插值)。
预测缺失值:使用机器学习模型预测缺失值。
五、实验内容及实验数据记录
(一)用Bengaluru_House_Data.csv数据集进行离群点检测与处理实验;
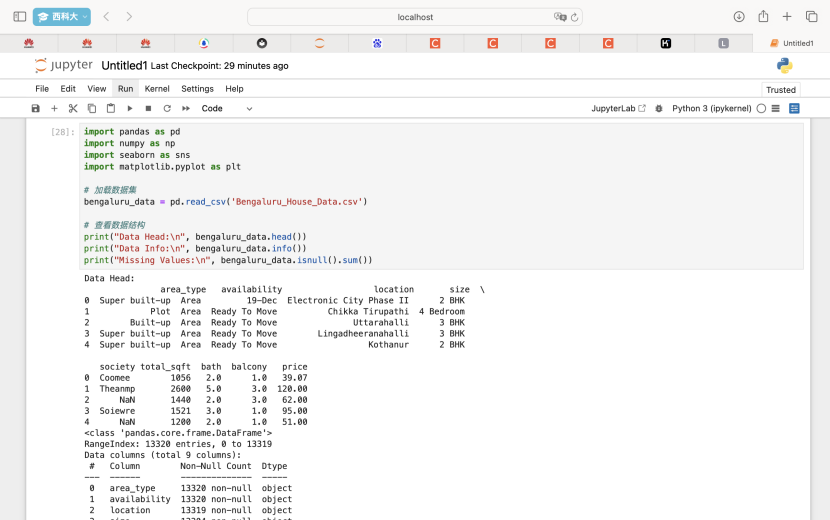
1. 数据预处理
加载数据集,并检查数据的基本信息和缺失值情况。

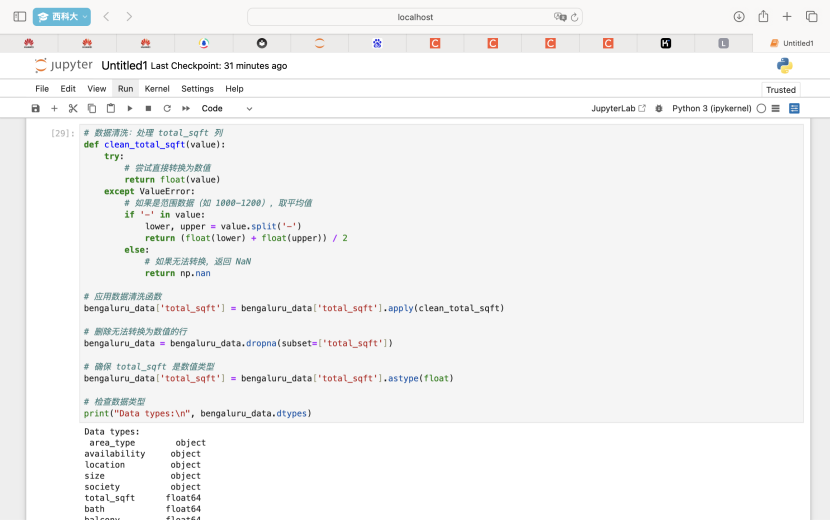
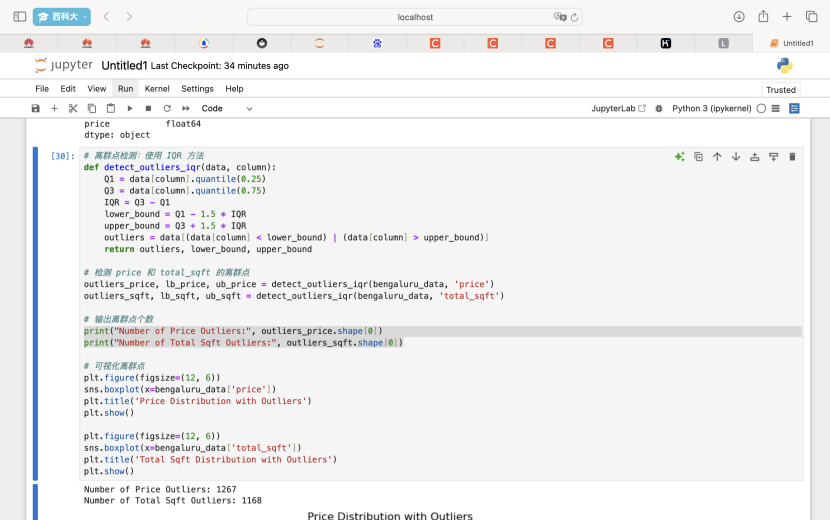
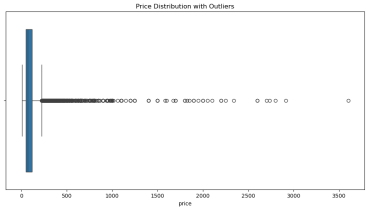
2.使用 IQR 方法检测 price 和 total_sqft 列的离群点。
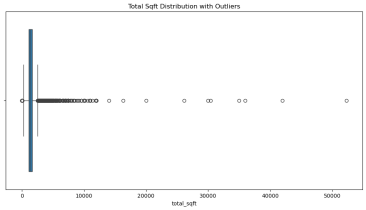
3.处理离群点

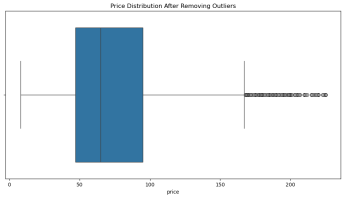
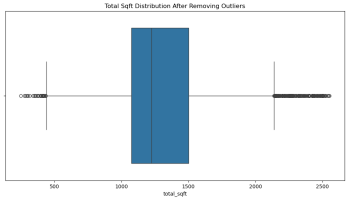
(二)用weight-height.csv数据集进行离群点检测与处理实验
1. 数据预处理
加载数据集,并检查数据的基本信息和缺失值情况。
2.离群点检测(使用 IQR 方法)并输出离群点个数
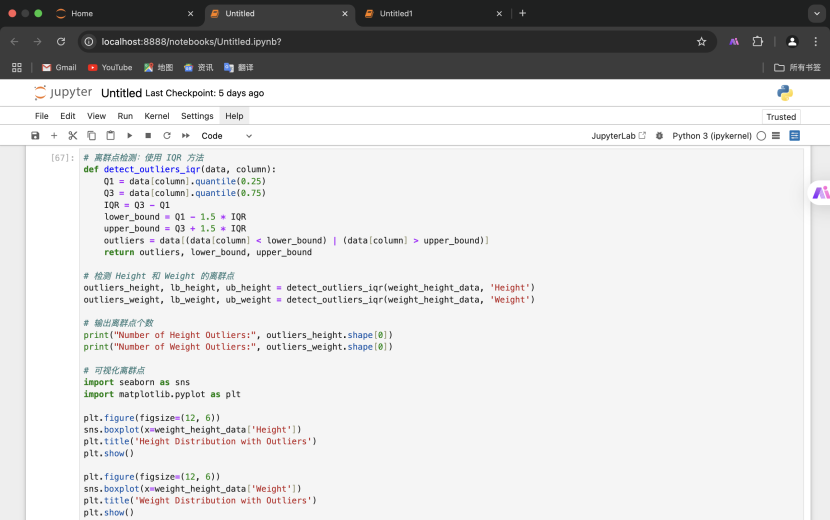
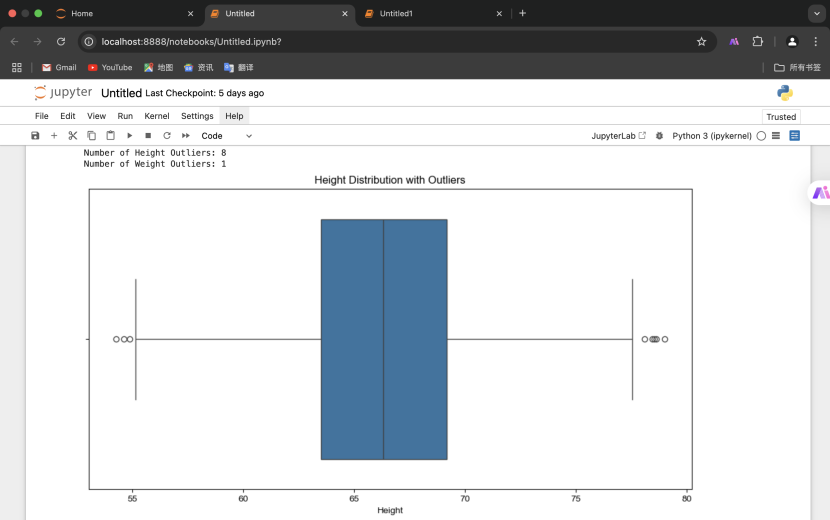
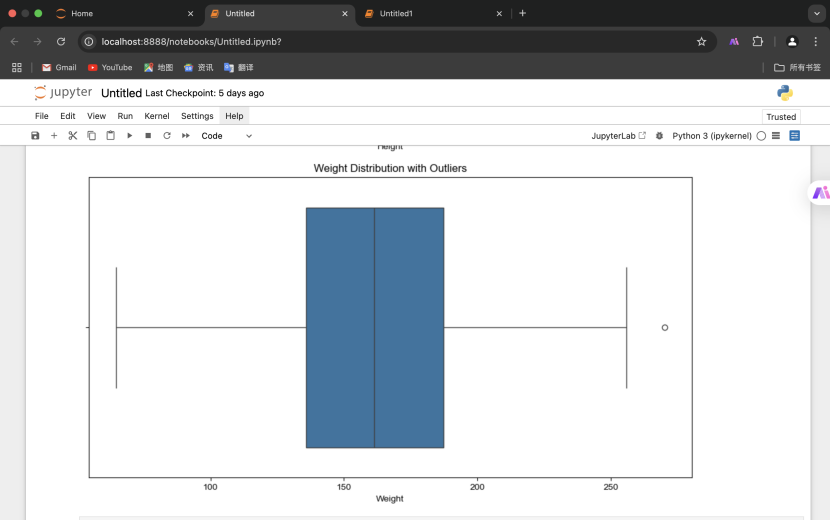 3.删除离群点并可视化
3.删除离群点并可视化
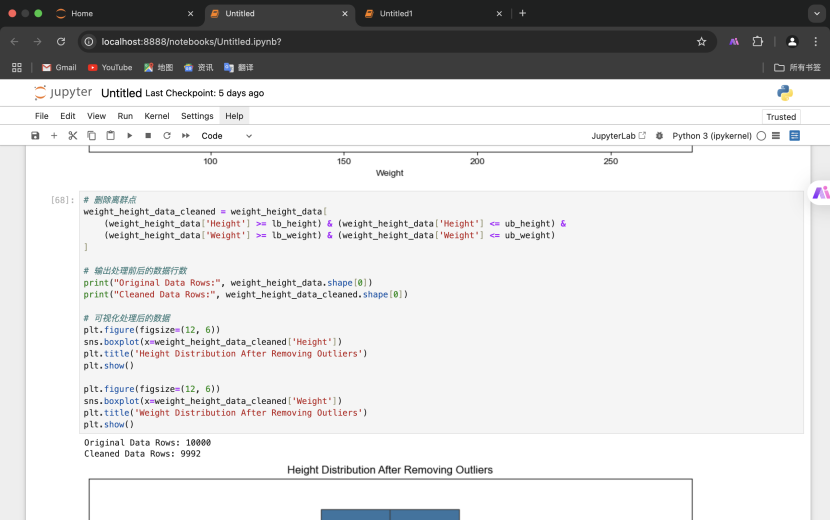
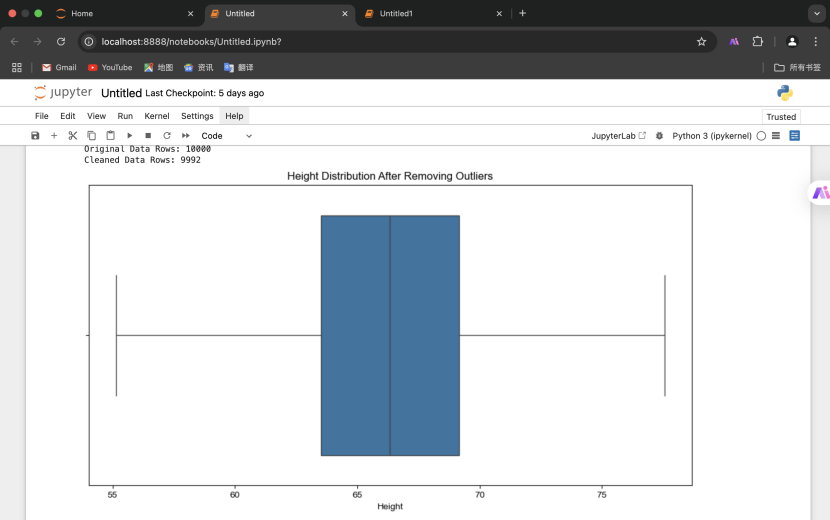
(三)用weather_data.csv进行缺失值处理实验
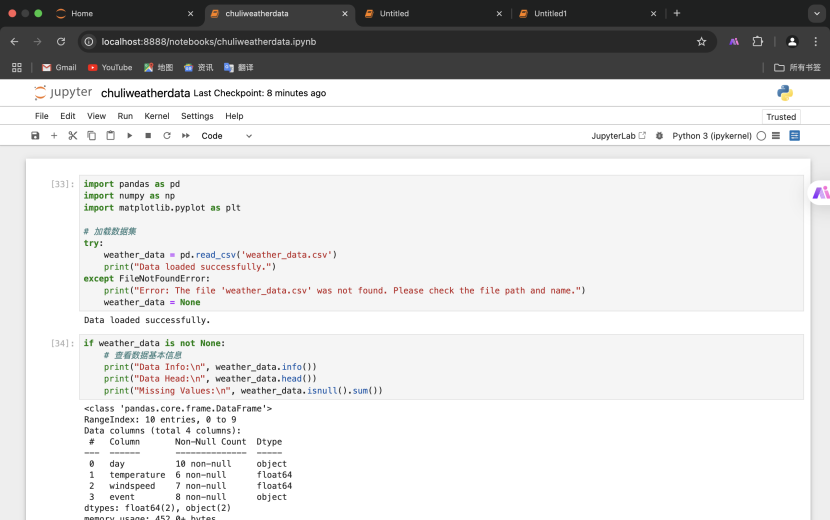
1.数据预处理
加载数据集,查看数据基本信息。
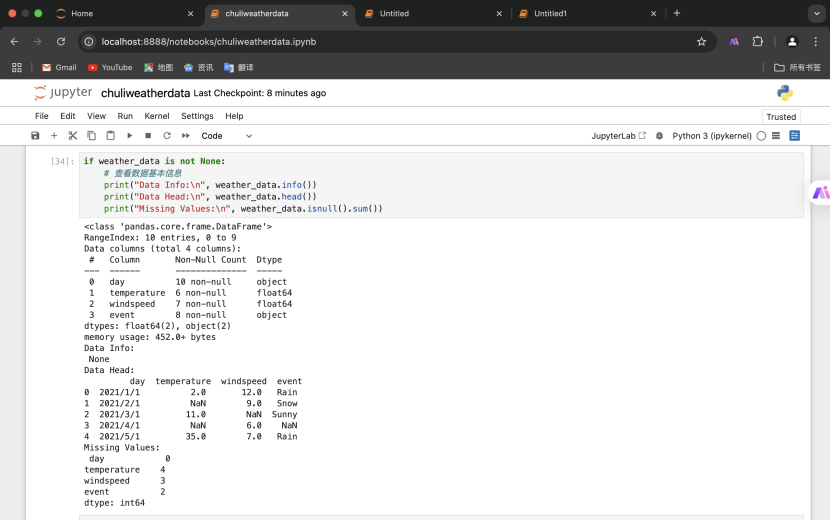
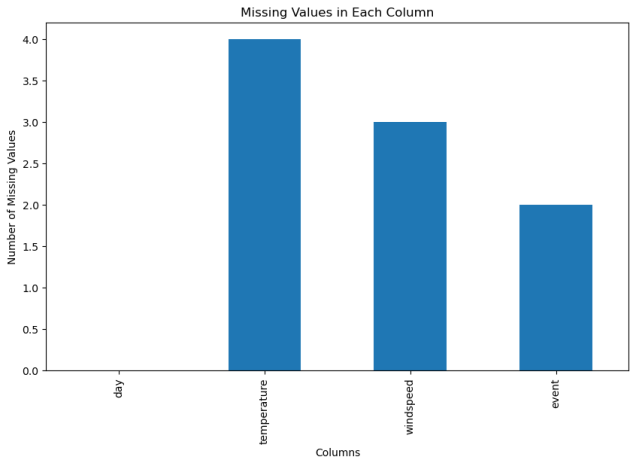
2.可视化缺失值

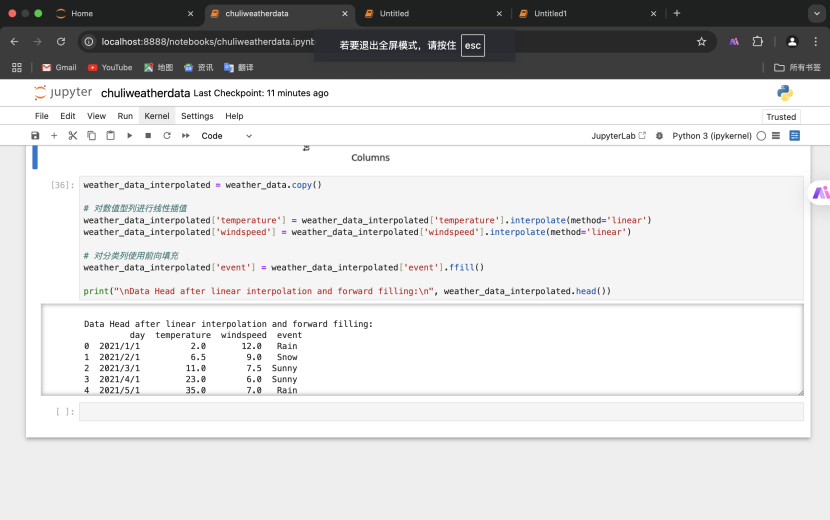
3.对数值型列进行线性插值,对分类列使用前向填充
(四)用titanic_train.csv数据集进行缺失值处理实验
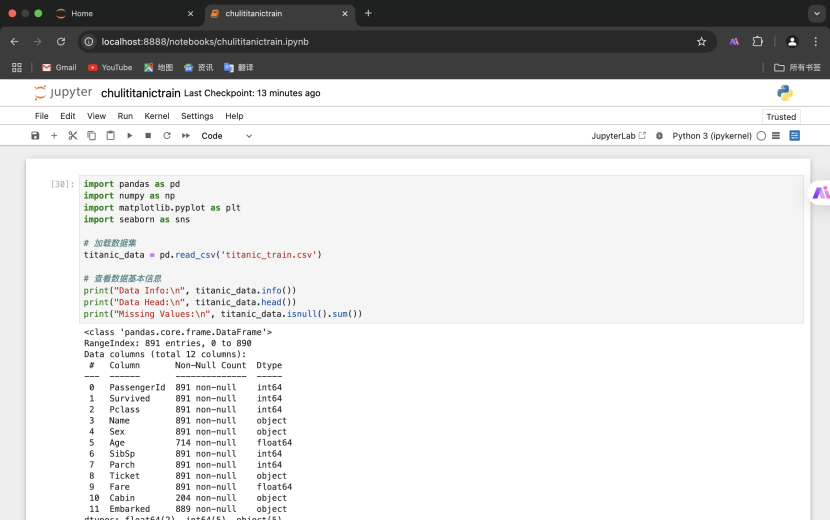
1.数据预处理
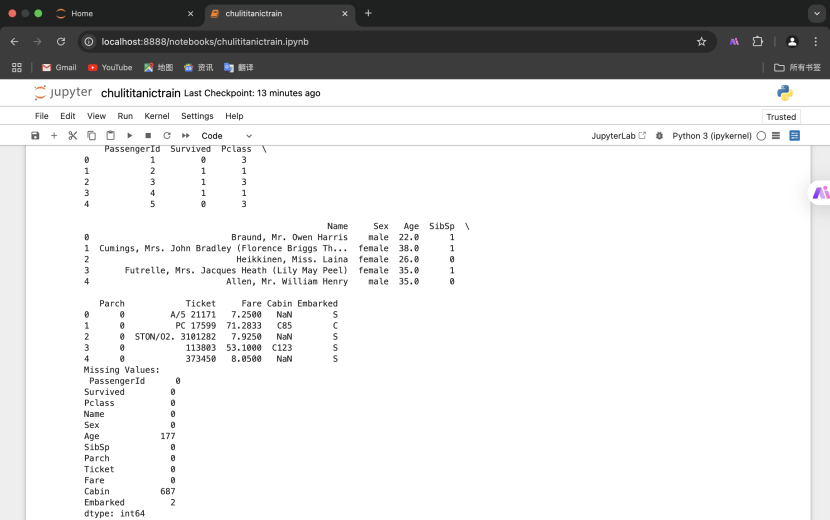 2.使用中位数填充 Age 列
2.使用中位数填充 Age 列
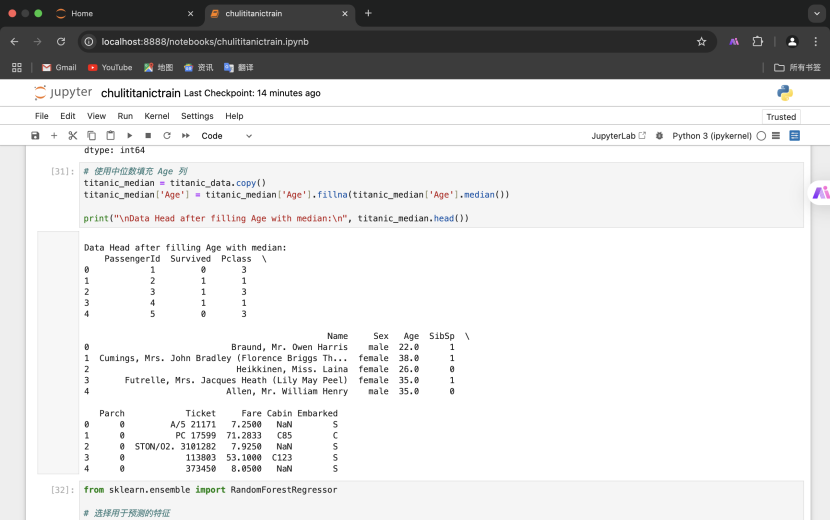
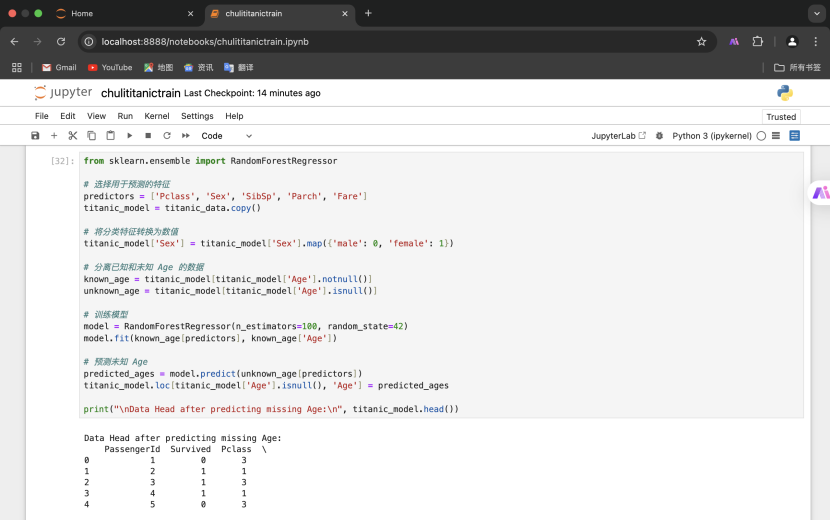
3.使用模型预测缺失值(随机森林回归)

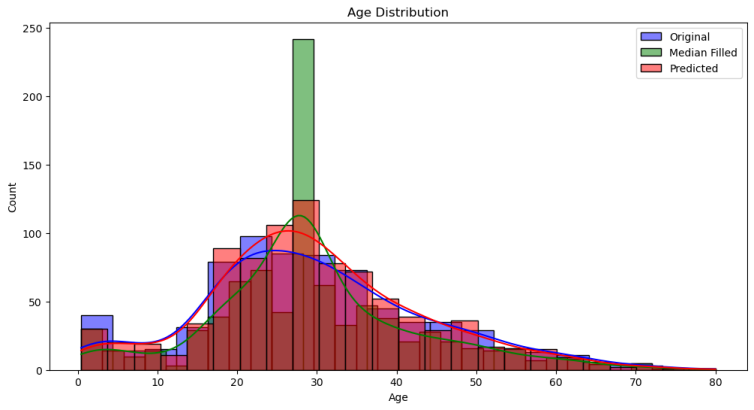
4.可视化比较Age列不同方法

 5.处理 Embarked 列的缺失值
5.处理 Embarked 列的缺失值
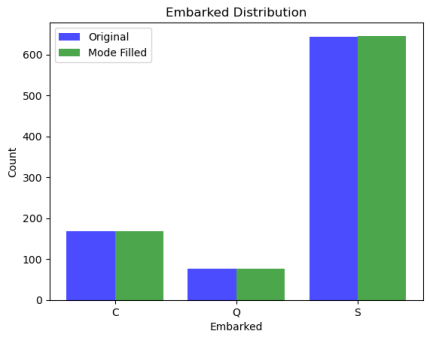
6.可视化比较 Embarked 列不同方法

7.处理 Cabin 列的缺失值,填充默认值 'Unknown'
六、心得体会
通过本次的实验,系统实践了数据去重、离群点检测、缺失值处理等数据预处理,采用对比了多种方法。
在数据预处理阶段,数据去重、离群点检测与处理以及缺失值处理是三个核心环节,它们对提升数据质量和分析结果的准确性至关重要。通过实践,我深刻体会到这些环节不仅需要技术手段,还需要对数据的特性和业务逻辑有深入的理解。
数据去重是数据清洗的第一步,看似简单,但稍有不慎就可能误删重要信息。因此,在去重前,必须明确哪些字段是唯一标识记录的关键字段,避免因错误操作导致数据丢失或信息不完整。去重后,还需重新检查数据的完整性和一致性,确保数据质量不受影响。
离群点检测与处理更具挑战性。离群点可能对数据分析和模型训练产生极大影响,因此需要准确检测并合理处理。实践中,我尝试了多种方法,如 IQR 方法、Z-Score 方法等,每种方法都有其适用场景。处理离群点时,不能简单地删除,因为它们可能包含有价值的信息。结合业务知识和数据特性进行综合判断是关键。此外,可视化工具(如箱线图)在离群点检测中非常有用,能直观展示数据分布和离群点位置。
缺失值处理是数据预处理中最常见且复杂的问题。数据缺失可能导致模型训练失败或分析结果不准确,因此需要谨慎处理。实践中,我尝试了多种方法,如删除缺失值、填充缺失值(均值、中位数、众数等)以及使用模型预测缺失值。选择合适的方法需根据数据特性和缺失值性质决定。填充后,还需重新检查数据的统计特性,确保填充值未对数据分布产生过大影响。
在实验中也遇到了一些问题,比如说在第二个问题中,处理一个输出时一直报错,最后利用AI发现问题可能出现在data.mean()计算时。DataFrame.mean()方法默认只对数值型列进行计算,但如果数据集中包含非数值型列(如Gender列通常是字符串类型),则会导致问题。为了解决这个问题,需要确保只对数值型列进行填充操作。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









