






 本文详细介绍了栈和队列这两种基础数据结构,包括它们的定义、操作以及在软件和硬件层面的应用。特别强调了栈的后进先出特性,队列的先进先出特性,并给出了使用顺序表和链表实现的示例。最后提到了数据结构在游戏开发中的实际应用场景。
本文详细介绍了栈和队列这两种基础数据结构,包括它们的定义、操作以及在软件和硬件层面的应用。特别强调了栈的后进先出特性,队列的先进先出特性,并给出了使用顺序表和链表实现的示例。最后提到了数据结构在游戏开发中的实际应用场景。
一.栈
1.栈介绍
在计算机这个学科中有两个栈,一个是软件层面的栈,一个是硬件层面的栈
软件的栈是指一种“后入先出(Last In First Out)”数据结构,用于在内存中存储、管理数据
硬件的栈是指,在计算机硬件中,由CPU管理的一块特殊的内存区域,用于支持程序的执行
学习栈和队列需要用到顺序表和链表,不熟悉的可以在这篇文章里看一看
链表与顺序表
本篇文章介绍的是数据结构中的栈,并非硬件的栈
栈底层由顺序表或链表实现,栈分为栈顶和栈底,栈顶用于插入数据和弹出数据,栈底没啥用(也许唯一的作用就是读取一下栈底的数据了)
从栈顶插入数据被称为压栈或入栈或进栈
从栈顶删除(也叫弹出)数据被称为出栈或弹栈
这个栈你可以把它想象成一个瓶子,咱们向瓶子里放东西不都是从瓶口向里面放,然后再从瓶口向外拿嘛,
咱从瓶子里拿东西的时候得先拿 后进去的东西吧,如果你不把这些后进的拿走,那怎么可能拿得到 先进瓶子的东西呢,先进的东西 被 后进的压在下面呀
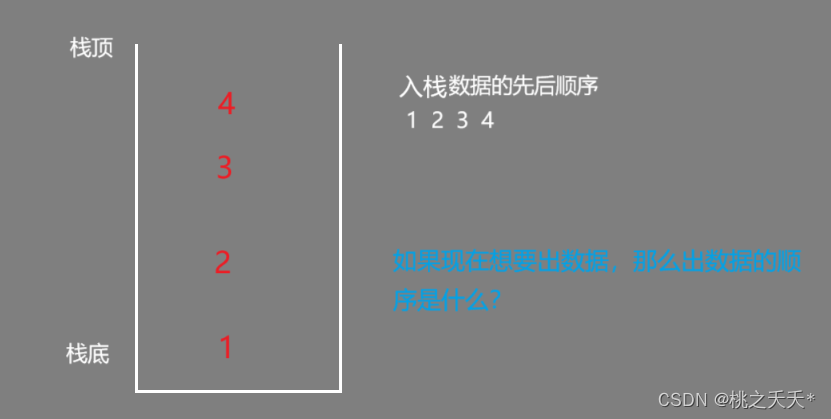
出数据的顺序应为4 3 2 1
从栈里面拿数据一定得注意顺序!!!,你要满足后进先出的规则(可以进一个出一个)
来看道题
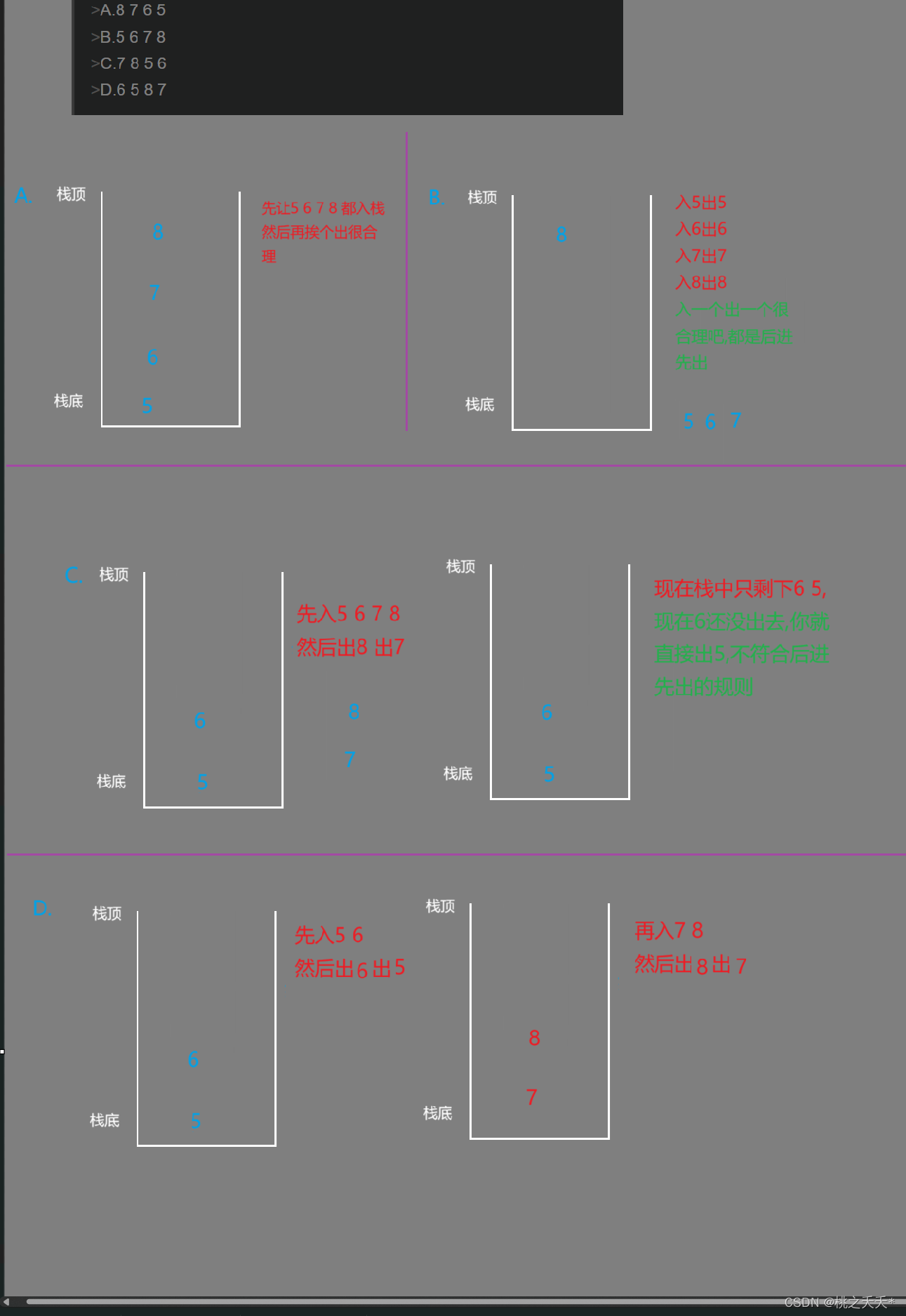
现有一栈,入数据的顺序为5 6 7 8,那么出数据时不可能的顺序是 ( )
A.8 7 6 5
B.5 6 7 8
C.7 8 5 6
D.6 5 8 7
答案是C
试想一下如果使用顺序表来实现栈,那么我们应该使用顺序表的哪一端用来充当栈顶呢?
从效率上来讲,更推荐使用顺序表的尾来充当栈顶,因为顺序表尾插的效率很高,而头插效率就很低了.用链表实现也是一样的道理,哪里效率高就用哪里充当栈顶。
2.栈的定义
struct Stack
{
int a;//数据
int size;//有效数据个数
int capacity;//容量
};
为了方便使用给他重命名一下
typedef int SDataType;
typedef struct Stack
{
SDataType* a;//数据
int size;//有效数据个数
int capacity;//容量
}Stack;
3.栈的各种操作
栈是用于存储数据的,所以他的各种接口与链表的各种接口也大差不差
void InitStack(Stack* stack);//初始化栈
void PushTop(Stack* stack, SDataType x);//从栈顶插入数据
void PopTop(Stack* stack);//从栈底删除数据
SDataType ReadTop(Stack* stack);//读取栈顶数据
SDataType ReadBack(Stack* stack);//读取栈底数据
bool IsEmptyStack(Stack* stack);//判断栈是否为空
bool IsFullStack(Stack* stack);//判断栈是否已满
void DestroyStack(Stack* stack);//销毁栈
(1)"InitStack"初始化栈
void InitStack(Stack* stack)
{
//与链表一样,你连个栈类型的变量都没有还谈什么初始化
assert(stack);
stack->a = NULL;
stack->capacity = stack->size = 0;
}
(2)"PushTop"从栈顶插入数据
void PushTop(Stack* stack, SDataType x)
{
//与链表一样,你连个栈类型的变量都没有还谈什么插入数据
assert(stack);
//防止扩容失败,原数据被覆盖
if (stack->size == stack->capacity)//这个判断一定要加,否则你每调用一次Pushcapacity就会扩大一次
{
int newcapacity = stack->capacity == 0 ? 4 : stack->capacity * 2;
SDataType* tmp = (SDataType*)realloc(stack->a, sizeof(SDataType) * newcapacity);
if (tmp == NULL)
{
perror("PushTop :: realloc : fail");
return;
}
stack->capacity = newcapacity;
stack->a = tmp;
}
stack->a[stack->size] = x;//从栈顶插入数据
stack->size++;
}
(3)"PopTop"弹出栈顶数据
bool IsEmptyStack(Stack* stack)
{
assert(stack);
return stack->size == 0;//为NULL就返回真,不为空返回假
}
(4)"ReadTop"读取栈顶数据
SDataType ReadTop(Stack* stack)
{
assert(stack);
//要返回栈顶数据这个栈首先得不为空
if (!IsEmptyStack(stack))
{
//我们说了,顺序表尾部是栈顶
return stack->a[stack->size - 1];//返回栈顶数据
}
return -1;//栈中无数据
}
(5)"PopTop"弹出栈顶数据
//从栈顶删除(也叫弹出)数据被称为 出栈或弹栈
void PopTop(Stack* stack)
{
assert(stack);
//要删除数据首先栈中得有数据
if (!IsEmptyStack(stack))
{
stack->size--;
}
else
{
printf("栈已为空\n");
}
}
"test"测试以上代码
void test()
{
Stack s;
InitStack(&s);
PushTop(&s, 1);
PushTop(&s, 2);
PushTop(&s, 3);
PushTop(&s, 4);
PushTop(&s, 5);//看看扩容是否正确
PushTop(&s, 6);
PushTop(&s, 7);
PushTop(&s, 8);
PushTop(&s, 9);
//读取栈,你可以把这个操作封装成函数,我这里就不搞了
//有多少个数据读多少次
while (s.size)
{
printf("%d ", ReadTop(&s));
PopTop(&s);
//从这个栈中读取数据很特殊,
// 因为每读一个数据都需要把这个数据从栈顶弹出才能读取下一个
// 所以每次从栈顶读完数据都需要Pop一下把栈顶数据删除
}
}
我非常建议写完一段代码就写几个测试检查一下写的对不对!!!不要全都写完了才检查,到时候一测试,代码崩溃了你也崩溃了!!!
测试时要尽量想一些极端情况,例如边界处理
对于所有的插入和删除操作最好都测试一下为空的情况
(6)"ReadBack"读取栈底数据
SDataType ReadBack(Stack* stack)
{
assert(stack);
if (!IsEmptyStack(stack))
{
return stack->a[0];//顺序表头就是栈底
}
else
{
printf("栈中无数据\n");
return -1;
}
}
(7)"IsFullStack"判断栈是否已满
bool IsFullStack(Stack* stack)
{
assert(stack);
//有效数据个数和数组空间大小相同就代表满了
return stack->size == stack->capacity;//满了返回真,不满返回假
}
(8)"DestroyStack"销毁栈
void DestroyStack(Stack* stack)
{
assert(stack);
free(stack->a);
stack->a = NULL;
stack->capacity = stack->size = 0;
}
二.队列
1.队列介绍
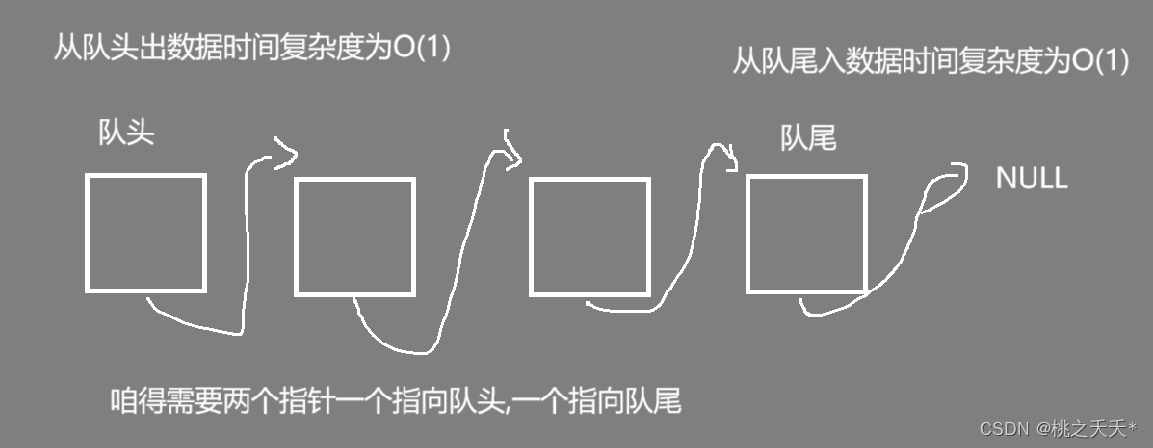
队列也是一种数据结构,它与栈正好相反,它是一种先进先出(First In First Out)的数据结构.
队列分为队头和队尾
向队尾插入数据称为入队
从队头出数据成为出队
这个队列顾名思义,就像排队一样,如果有新的人来了,那他就得在队尾,你不能让他去队伍中间或队头吧,那叫插队.
如果有人要离开就得从队头离开(但你硬要从队尾离开也没办法,挺合理的,对吧?)

队列也可用顺序表或链表实现,这里队列用链表,上面的栈使用顺序表
那么使用链表的队列应该从哪端入,哪端出效率高呢?
2.队列的定义
//队列与栈一样可以选择数组、双向链表、单链表实现
// 另外还可以用栈实现队列,栈也可以用队列实现,但效率都很低
// 证明栈和队列是相同的
//
//此次选则单链表实现
typedef int QDataType;
typedef struct QueueNode
{
QDataType val;
struct QueueNode* next;
}QN;//队列
//把指向队列头和尾的指针封装成了一个结构体
typedef struct QHT
{
struct QueueNode* head;//指向队列头
int size;//记录当前数据总数
struct QueueNode* tail;//指向队列尾
}QHT;
3.队列需实现的接口
void InitQueue(QHT* point);//初始化
void Destroy(QHT* queue);//销毁
//void PushQueue(QN* queue, QN* tail,QDataType x);//队列要先进先出,尾进头出,所以要有一个指向尾的指针,否则时间复杂度为O(N)
//这里传两个指针看着很怪,所以用一个结构体把头和尾封装起来
void PushQueue(QHT*, QDataType x);//队尾入队列
void PopQueue(QHT* queue);//队头出队列
bool IsEmptyQueue(QHT* queue);//判断队列是否为NULL
QDataType BackQueue(QHT* queue);//获取队列尾部元素
QDataType FrontQueue(QHT* queue);//获取队列头部元素
这边的传参为什么不是下面这个QN类型而是QHT类型呢?这QN类型明明才是是对队列的定义。
typedef struct QueueNode
{
QDataType val;
struct QueueNode* next;
}QN;//队列
还记不记得单链表,在对单链表传参的时候是不是需要定义一个链表结构类型的指针,然后传递这个指针的地址,像这样
void test()
{
ListNode* list = NULL;//定义链表类型的指针
PushList(&list,1);//插入节点
}
在队列中不传递QN的队列类型的原因跟这个是一样的,在这个链表中,需要一个指针来标记链表头的位置,所以需要在函数外定义一个指向链表头的指针。
而在上面定义的QHT结构中,它的成员变量是QN类型的,所以我们只需要传递QHT类型的参数就可以使他的成员指向链表头,这样就有了指向链表头的指针,而因为我们需要一个指向队头一个指向队尾两个指针,所以才会把它封装成一个结构体,若不想用结构体那下面这个方法与它也是等价的
void test1()
{
QN* head = NULL;//指向队头
QN* tail = NULL;//指向队尾
PushQueue(&head, &tail, 1);//在队列中插入数据
}
(1)"test"传参与测试
这个测试是极简版,你们最好多测点,这里主要还是解释传参的问题
void test()
{
QHT ht;//定义指向链表头和尾的指针
//创建变量编译器会自动为其成员开辟适当空间。若创建指针需手动开辟
InitQueue(&ht);
PushQueue(&ht, 1);
PushQueue(&ht, 2);
PushQueue(&ht, 3);
PushQueue(&ht, 4);
}
(2)"InitQueue"初始化
void InitQueue(QHT* point)//初始化
{
assert(point);
point->head = NULL;
point->tail = NULL;
point->size = 0;
}
(3)"PushQueue"入队
void PushQueue(QHT* ht, QDataType x)
{
assert(ht);
QN* tmp = (QN*)malloc(sizeof(QN));
if (tmp == NULL)
{
perror("PushQueue :: malloc\n");
return;
}
tmp->val = x;
tmp->next = NULL;
if (ht->head == NULL)
{
ht->head = tmp;
ht->tail = tmp;
}
else
{
ht->tail->next = tmp;
ht->tail = tmp;
}
ht->size++;
}
(4)"Destroy"销毁队列
void Destroy(QHT* ht)//销毁
{
assert(ht);
QN* del = ht->head;
while (del)
{
ht->head = ht->head->next;
free(del);
del = ht->head;
}
InitQueue(ht);
}
(5)"PopQueue"弹出队头数据
void PopQueue(QHT* ht)
{
assert(ht && ht->head);//无节点
QN* del = ht->head;
ht->head = ht->head->next;//head指向下一个节点
free(del);
if (ht->head == NULL)//若head前进后等于NULL,证明只有一个节点
{
ht->tail = NULL;
}
ht->size--;
}
(6)"IsEmptyQueue"判断队列是否为空
bool IsEmptyQueue(QHT* ht)
{
assert(ht);
return ht->head == NULL;//没数据返回真,有数据返回假
}
(7)"FrontQueue"获取队头元素
QDataType FrontQueue(QHT* queue)//获取队列头部元素
{
assert(queue && queue->head);
return queue->head->val;
}
(8)"BackQueue"获取队尾元素
QDataType BackQueue(QHT* queue)//获取队列尾部元素
{
assert(queue && queue->tail);
return queue->tail->val;
}
4.循环队列
循环队列是一种线性数据结构,其操作表现基于 FIFO(先进先出)原则并且队尾被连接在队首之后以形成一个循环。它也被称为“环形缓冲器”。
循环队列的一个好处是我们可以利用这个队列之前用过的空间。在一个普通队列里,一旦一个队列满了,我们就不能插入下一个元素,即使在队列前面仍有空间。但是使用循环队列,我们能使用这些空间去存储新的值。
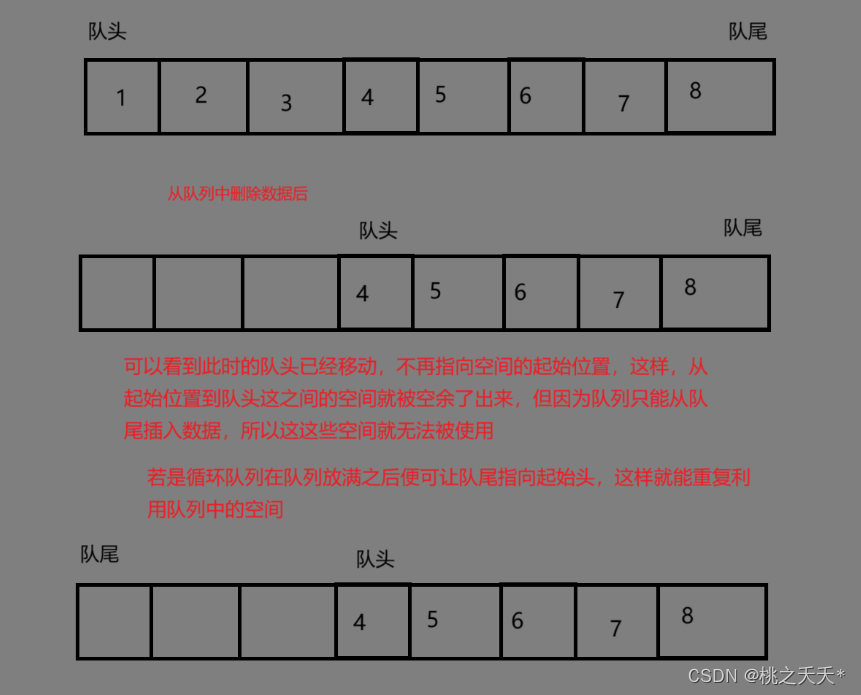
在力扣上有关于循环队列的题和官方讲解,感兴趣的可以去看看
力扣:循环队列
顺带说一句官方题解中的mod是取模(%)的意思,也就是取余数
例如:
根据以上可知,队列判空的条件是 front == rear, 而队列的判满条件是
(rear +1) mod capacity == front
这里他加上一个取模是为了防止越界的情况出现,如果不取模可以这样写
// //队列是否已满
// if((rear+1) % (capacuty) == front)
// {
// return true;//满就返回true
// }
//rear指向队列最后一个有效元素的下一个位置,队列的空间个数也始终比有效元素个数多一个
if(rear+1 >= capacity)//出现这种情况就证明队列尾已经超出数组长度了,
//这时候如果要判满,那就得看队列头是否在数组头的位置,在数组头那就是满了
{
if(0 == obj->front)
{
return true;
}
}
else if(obj->tail + 1 == obj->front)
{
return true;
}
return false;
三.总结
队列和栈都是比较简单的数据结构,他们的主要目的还是为了存储数据
队列是先进先出,队列适宜使用链表
栈是先进后出,栈适宜使用顺序表
从队尾插入数据叫入队
从栈顶插入数据叫入栈、进栈、压栈
从栈顶弹出数据叫 出栈、弹栈
从队头删除数据叫出队















 2414
2414











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









