






课程计划
第一讲:介绍与词向量
1. 课程概述(10分钟)
2. 人类语言和词义(15分钟)
3. Word2vec 简介(15分钟)
4. Word2vec 目标函数梯度(25分钟)
5. 优化基础(5分钟)
6. 查看词向量(10分钟或更短)
今日主要学习内容:令人惊奇的结果,即词义可以相当好地用一组(高维)实数向量来表示。
我们希望教授什么?(也称为“学习目标”)
1. 对于应用于自然语言处理(NLP)的深度学习有效现代方法的基础知识
• 首先是基础知识,然后是在2023年用于NLP的关键方法:词向量、前馈网络、循环网络、注意力、编码器-解码器模型、 Transformer、大规模预训练语言模型等。
2. 对人类语言以及通过计算机理解和生成它们的困难有一个全局的理解
3. 理解并能够使用PyTorch构建一些主要NLP问题的系统:
• 词义、依赖解析、机器翻译、问答等。
我们如何表示一个词的含义?
定义:意义(Webster字典)
• 由一个词、短语等所代表的思想。
• 一个人通过使用词语、标志等来表达的思想。
• 在文学作品、艺术作品等中表达的思想。
最常见的语言学思考意义的方式:
意符(符号)⟺ 所指(思想或事物)
= 指示语义
树 ⟺ {🌳, 🌲, 🌴, …}
如何在计算机中获得可用的含义?
以前最常见的自然语言处理解决方案:使用诸如WordNet之类的工具,其中包含了同义词集合和上位词("是一个"关系)的列表。
像WordNet之类的资源存在的问题
• 是一个有用的资源,但缺乏细微之处
• 例如,“proficient”被列为“good”的同义词在某些上下文中这才是正确的
• 此外,WordNet在某些同义词集合中列出了带有冒犯性的同义词,但没有涵盖单词的内涵或适用性
• 缺少单词的新含义:
例如,wicked、badass、nifty、wizard、genius、ninja、bombest
• 不可能保持最新!
• 主观
• 需要人力来创建和适应
• 不能准确地用于计算词语相似性(请参阅下面的幻灯片)
传统机器学系向量太稀疏
单词作为离散符号的问题
例子:在网络搜索中,如果用户搜索“西雅图汽车旅馆”,我们希望匹配包含“西雅图酒店”的文档
但是:
motel = [0 0 0 0 0 0 0 0 0 0 1 0 0 0 0]
hotel = [0 0 0 0 0 0 0 1 0 0 0 0 0 0 0]
这两个向量是正交的
对于单热编码向量,没有自然的相似性概念!
解决方案:
• 可以尝试依赖于WordNet的同义词列表来获取相似性?
• 但是众所周知,它很容易出现严重问题:不完整等
• 相反:学习将相似性编码在向量中本身
通过其上下文表示词语
• 分布式语义学:一个词的含义由其附近频繁出现的词决定
• “你将通过它的伙伴认识一个词”(J. R. Firth 1957: 11)
• 是现代统计自然语言处理中最成功的思想之一!
• 当一个词 w 出现在文本中时,其上下文是出现在附近的词的集合(在一个固定大小的窗口内)。
• 我们使用词 w 的许多上下文来构建 w 的表示
…政府债务问题变成了银行危机,就像2009年发生的那样…
…说欧洲需要统一的银行监管来取代大杂烩…
…印度刚刚给了其银行体系一剂强心针…
这些上下文词将表示银行。词向量
我们将为每个单词构建一个密集向量,选择使其类似于出现在相似上下文中的单词的向量,通过向量点(标量)乘积来衡量相似性。
注意:词向量也称为单词嵌入或神经单词表示。它们是分布式表示。
3. Word2vec:概述
Word2vec(Mikolov等,2013)是一种学习词向量的框架
思想:
• 我们有一个大语料库("主体")的文本:一个长单词列表
• 固定词汇表中的每个单词都由一个向量表示
• 遍历文本中的每个位置 t,其中有一个中心词 c 和上下文("外部")词 o
• 使用 c 和 o 的词向量的相似性来计算给定 c 时 o 的概率(反之亦然)
• 不断调整词向量以最大化此概率。
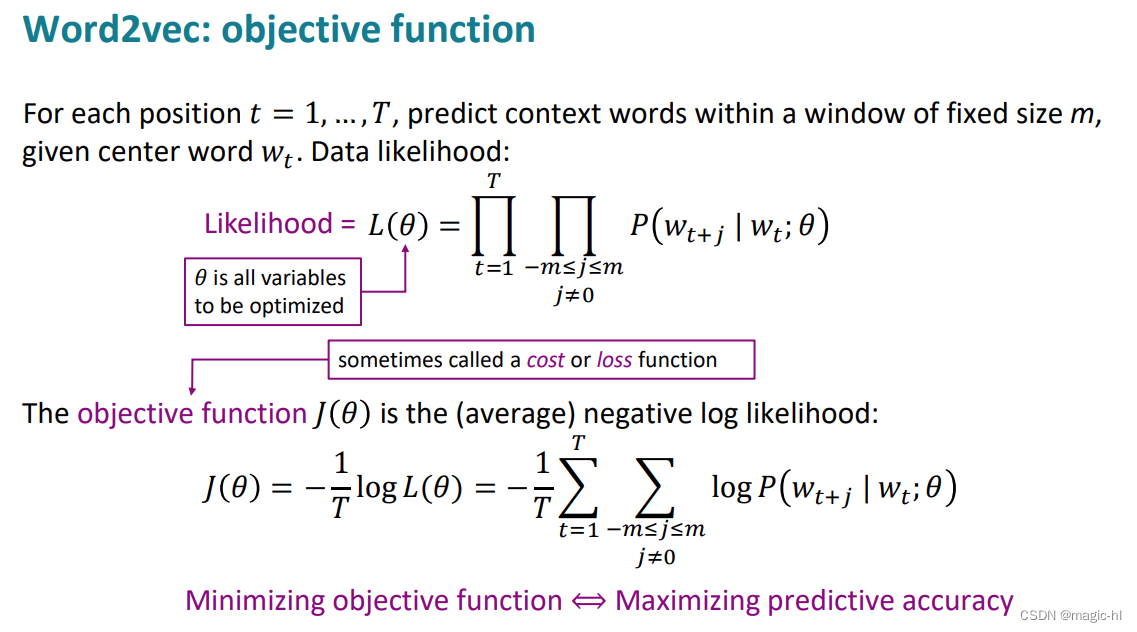
明白为什么是两个连乘,因为两个变量,一个是中心词,另一个是滑窗
问题:如何计算 𝑃(𝑤𝑡+𝑗|𝑤𝑡;𝜃) ?用softmax
答案:我们将为每个词 w 使用两个向量:
• 当 w 是中心词时使用 𝑣𝑤
• 当 w 是上下文词时使用 𝑢𝑤 然后对于中心词 c 和上下文词 o:
似然函数为:
目标函数(Objective Function):
概率的计算:
训练模型:优化参数值以最小化损失
为了训练模型,我们逐步调整参数以最小化损失
• 回顾:𝜃 表示所有模型参数,构成一个长向量
• 在我们的情况下,对于 d 维向量和 V 个词,我们有 →
• 记住:每个词都有两个向量(即它的中心词向量和上下文向量)
• 我们通过沿着梯度下降(见右图)来优化这些参数
• 我们计算所有向量的梯度!
终于明白滑窗了,就是说我们的词向量分布只要合适就行,不必全部包含完。















 658
658











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









