






第二讲:词向量、词义和神经网络分类器
1. 课程组织(3分钟)
2. 完成对词向量和word2vec的讨论(15分钟)
3. 我们是否可以通过计数更有效地捕捉词义的本质?(10分钟)
4. 评估词向量(10分钟)
5. 词义(8分钟)
6. 分类回顾以及神经网络的差异(14分钟)
7. 引入神经网络(10分钟)
主要目标:在课程结束时能够阅读词嵌入论文。
归一化项在输出类别较多时计算成本很高:
• 因此,在标准的word2vec和HW2中,你们使用了负采样来实现skip-gram模型
• 主要思想:训练二元逻辑回归来区分真实对(中心词和其上下文窗口中的词)与几个“噪声”对(中心词与随机词配对)。
理解词嵌入中的每个词有两个向量通常涉及到讨论两种不同的词嵌入方法,例如 Word2Vec 中的 Skip-gram 模型和 CBOW 模型。在这些方法中,每个词通常有两个相关的词向量,一个用于表示词作为上下文的角色,另一个用于表示词作为目标的角色。我将通过一个例子来解释这个概念。
**例子:Skip-gram 模型**
假设我们有一个小型的词汇表,包含以下单词:{"apple", "banana", "juice", "orange"}。
在 Skip-gram 模型中,每个单词都有两个词向量:一个用于表示单词作为中心词(target word),另一个用于表示单词作为上下文词(context word)。这两个向量是在训练过程中学习得到的。
假设我们的训练数据包括以下句子:
1. "I love apple juice."
2. "She enjoys eating banana."对于句子1中的 "apple",我们有一个词向量表示它作为中心词,另一个表示它作为上下文词。类似地,对于句子2中的 "banana",我们也有两个相关的词向量。
举例来说,假设用
表示 "apple" 作为中心词的词向量,
表示 "apple" 作为上下文词的词向量。同样,用 (
\和
分别表示 "banana" 的中心词和上下文词的词向量。
在训练过程中,模型会优化这些词向量,以使得在给定上下文时,目标词的概率最大化。这样,每个单词会学习两个向量,以在不同角色下更好地捕捉其语义信息。
需要注意的是,这个例子是为了说明概念,实际训练过程和向量的表示可能更加复杂。在其他词嵌入方法中,如 CBOW 模型,也有类似的思想,但角色可能有所不同。
Word2Vec算法族(Mikolov等,2013):更多细节
为什么要使用两个向量?更容易优化。最后将两者求平均。
• 但是也可以只使用一个向量来实现算法……这会稍微有所帮助。
两种模型变体:
1. Skip-grams(SG)
预测给定中心词时的上下文("外部")词(与位置无关)
2. 连续词袋模型(CBOW)
从(词袋中的)上下文词预测中心词(完形填空)
我们介绍了:Skip-gram模型
用于训练的损失函数:
1. Naïve softmax(简单但成本高昂的损失函数,当输出类别很多时)
2. 更优化的变体,如分层softmax
3. 负采样
到目前为止,我们解释了Naïve softmax。
负采样的skip-gram模型(HW2)
• 引入自:《单词和短语的分布式表示及其组合》(Mikolov等,2013)
• 整体目标函数(他们最大化):
• 逻辑/sigmoid函数:
(我们很快会成为好朋友)
• 我们最大化两个单词共现的概率在第一个对数中,最小化噪声单词在第二部分中的概率。Skip-gram 模型结合负采样(Negative Sampling)是一种用于训练词向量的方法,它通过简化 Softmax 计算来提高训练效率。以下是 Skip-gram 模型与负采样相结合的公式:
假设我们有一个词汇表大小为V,上下文窗口大小为c,以及中心词
和上下文词
。
1. **Sigmoid 函数:**
在负采样中,我们使用 Sigmoid 函数来计算目标词与上下文词之间的概率。Sigmoid 函数可以表示为:
2. **目标函数:**
Skip-gram 模型的目标是最大化给定上下文词情况下生成目标词的概率。而负采样则是通过最小化负样本的概率来达到这个目标。最终的目标函数可以表示为:
其中:
表示中心词
表示上下文词
表示负样本词
的词向量。
是负样本的数量。
是 Sigmoid 函数。
上述目标函数的第一项表示正样本(目标词与上下文词)的概率,第二项表示负样本(负样本词与上下文词)的概率。最终目标是最大化整体的目标函数,即最大化正确上下文词的概率,同时最小化负样本的概率。
需要注意,这是负采样的一种形式,还有其他的变体和方法。负采样的主要目的是加速训练过程,从而使得模型在大规模语料库上能够更高效地训练词向量。
3. 为什么不直接捕获共现次数?
在整个语料库上进行迭代(可能多次)似乎有些奇怪;为什么我们不只是累积所有单词在彼此附近出现的统计信息呢?!
构建共现矩阵 X
• 两个选项:窗口与整个文档
• 窗口:类似于word2vec,使用每个单词周围的窗口,可以捕捉一些句法和语义信息("词空间")
• 单词-文档共现矩阵将提供一般主题(所有与体育相关的术语将具有相似的条目),从而引导到"潜在语义分析"("文档空间")。共现向量
• 简单计数的共现向量
• 向量的大小随词汇量增加而增加
• 维度非常高:需要大量存储空间(虽然稀疏)
• 后续的分类模型存在稀疏问题,导致模型不太稳健
• 低维向量
• 思路:将“大部分”重要信息存储在固定数量的维度中,这些维度数量较小:密集向量
• 通常是 25-1000 维,与word2vec类似
• 如何降低维度?经典方法:对 X 进行降维(HW1)
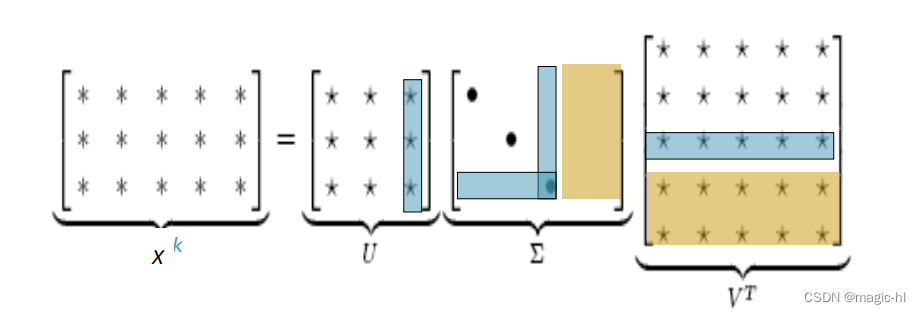
共现矩阵 X 的奇异值分解(Singular Value Decomposition,SVD)
将 X 分解为 UΣVT,其中 U 和 V 是正交的
仅保留前 k 个奇异值,以便进行泛化。
𝑋̂ 是 X 的最佳秩 k 近似,从最小二乘的角度来看。
经典线性代数结果。计算大矩阵时计算成本高昂。对 X 的改进方法(Rohde等人在COALS中使用了几种方法)
• 直接在原始计数上运行SVD效果不好!!!
• 对单元格中的计数进行缩放可以帮助很多
• 问题:功能词(the,he,has)太频繁了,语法影响太大。一些修复方法:
• 对频率取对数
• min(X, t),其中 t ≈ 100
• 忽略功能词
• 斜坡窗口,比进一步的词更多地计数接近的词
• 使用Pearson相关性代替计数,然后将负值设为0
• 等等。GloVe [Pennington、Socher 和 Manning,EMNLP 2014]:
在向量差异中编码含义组件
问:我们如何在词向量空间中捕捉共现概率比例作为线性含义组件?
• 快速训练
• 可扩展到庞大的语料库
4. 如何评估词向量?
• 与NLP中的一般评估相关:内在 vs. 外在
• 内在:
• 在特定/中间子任务上进行评估
• 计算速度快
• 有助于理解系统
• 除非与真实任务的相关性建立,否则不清楚是否真的有帮助
• 外在:
• 在真实任务上进行评估
• 计算准确率可能需要很长时间
• 不清楚是子系统是问题,还是其相互作用或其他子系统
• 如果用另一个子系统精确替换一个子系统可以提高准确率内在词向量评估
• 词向量类比
• 通过加法后的余弦距离来评估词向量,以捕捉直观的语义和句法类比问题
• 从搜索中排除输入单词(!)
• 问题:如果信息存在但不是线性的怎么办?
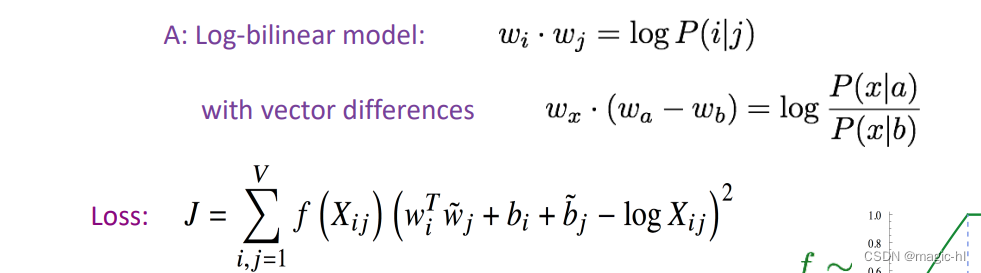

5. 词义和词义的多义性
• 大多数单词有许多含义!
• 特别是常见词
• 特别是存在已久的词
• 例如:pike
• 一个向量能否捕捉所有这些含义,还是我们有一团糟?
pike
• 尖锐的尖端或杆
• 一种纺长的鱼
• 铁路线或系统
• 一种道路
• 未来(即将到来)
• 一种身体姿势(如潜水)
• 用长矛杀死或穿刺
• 前进或行进
• 在澳大利亚英语中,pike表示放弃做某事:我估计他本来可以爬上那个悬崖,但他放弃了!
词义的线性代数结构,及其在多义性方面的应用(Arora等,TACL 2018)
• 一个词的不同含义在标准词向量(如word2vec)中以线性叠加(加权和)的形式存在
• pike = α1 × sense1 + α2 × sense2 + α3 × sense3
• 其中 α1、α2、α3 等表示频率 f1、f2、f3 等的权重
• 令人惊讶的结果:
• 基于稀疏编码的思想,实际上可以将这些含义分开(前提是它们相对常见)!
深度学习分类:命名实体识别(NER) • 任务:通过为单词标记来查找和分类文本中的名称,例如: 昨晚,巴黎希尔顿(Paris Hilton)穿着一袭闪亮的礼服,令人惊叹。 PER PER 塞缪尔·奎因(Samuel Quinn)于1989年4月在巴黎希尔顿酒店被捕。 PER PER LOC LOC LOC DATE DATE • 可能的用途: • 在文档中跟踪特定实体的提及 • 对于问题回答,答案通常是命名实体 • 将情感分析与讨论中的实体相关联 • 通常后面会跟随实体链接/规范化,将其连接到诸如Wikidata之类的知识库中。
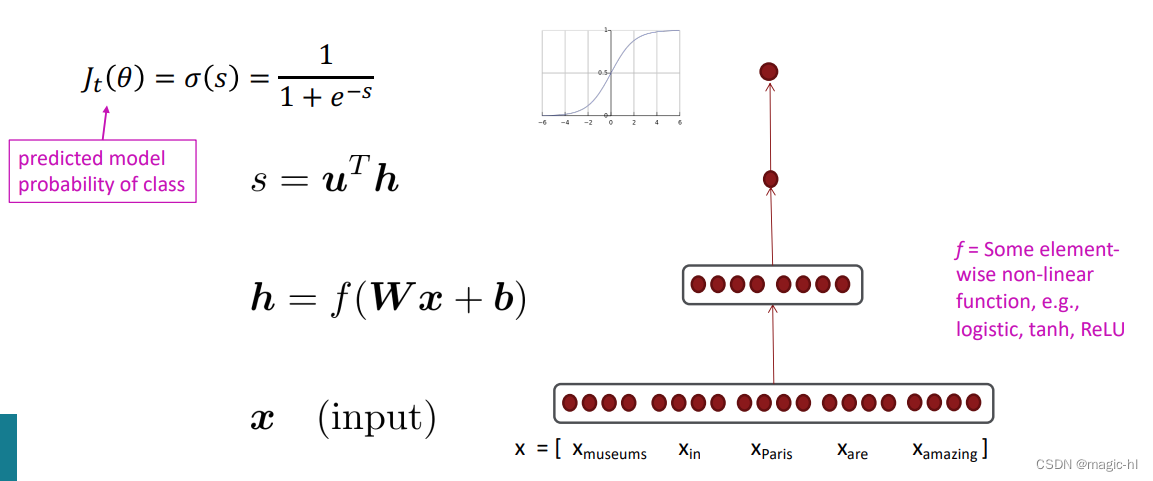
简单的命名实体识别:使用二元逻辑分类器的窗口分类法
• 思路:在邻近单词的上下文窗口中对每个单词进行分类
• 在手工标记的数据上训练逻辑分类器,根据窗口中单词向量的串联对每个类别的中心单词进行分类(是/否)
• 实际上,我们通常使用多类别softmax,但我们正在尝试保持简单 J
• 例如:在窗口长度为2的情况下,将“Paris”分类为+/-地点:
the museums in Paris are amazing to see.
Xwindow = [ x_museums x_in x_Paris x_are x_amazing ]T
• 得到的向量 xwindow = x ∈ R5d
• 要对所有单词进行分类:对句子中的每个单词上的向量运行每个类别的分类器。
分类回顾和符号表示
• 监督学习:我们有一个由样本 组成的训练数据集
• xi 是输入,例如单词(索引或向量!)、句子、文档等。
• 维度为 d
• yi 是我们要预测的标签(C 类中的一类),例如:
• 类别:情感(+/-)、命名实体、买/卖决策
• 其他词语
• 后续:多词序列
神经分类
• 典型的机器学习/统计学的 softmax 分类器:
• 学习的参数 θ 仅是 W 的元素(不是输入表示 x,x 具有稀疏的符号特征)
• 分类器给出线性决策边界,这可能有限制
• 神经网络分类器的不同之处在于:
• 我们同时学习 W 和(分布式的!)词向量表示
• 单词向量 x 重新表示了一热向量,将它们移动到一个中间层向量空间中,以便使用(线性的)softmax 分类器进行简单分类
• 在概念上,我们有一个嵌入层:x = Le
• 我们使用深度网络——更多层次——让我们多次重新表示和组合数据,从而得到非线性分类器。
Softmax 分类器
同样,我们可以将预测函数分解为三个步骤:
1. 对于 W 的每一行 y,计算与 x 的点积:
2. 应用 softmax 函数以获取归一化概率:
= softmax(θE)
3. 选择具有最大概率的 y
• 对于每个训练示例 (x,y),我们的目标是最大化正确类别 y 的概率,或者我们可以最小化该类别的负对数概率:
NER:中心词作为地点的二元分类
• 我们进行监督训练,如果它是一个地点,我们希望得到高分。
使用“交叉熵损失”进行训练 - 在 PyTorch 中使用这个!
• 到目前为止,我们的目标是最大化正确类别 y 的概率,或者等价地说,我们可以最小化该类别的负对数概率。
• 现在,重新以信息理论中的交叉熵来表述这个目标。
• 让真实的概率分布为 p;让我们计算出的模型概率为 q。
• 交叉熵为:
• 假设一个地面真实(或正确的或黄金的或目标的)概率分布在正确类别处为 1,其他地方为 0,即 p = [0,…,0,1,0,…,0],则:
• 由于独热编码的 p,剩下的唯一项是真实类别 yi 的负对数概率:− log q(yi)。
整个数据集上的分类
• 在完整数据集 {xi, yi}N i=1 上的交叉熵损失函数。















 424
424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









