






-
第一步:下载HTK:
登录HTK Speech Recognition Toolkit ,需注册账号才可下载。
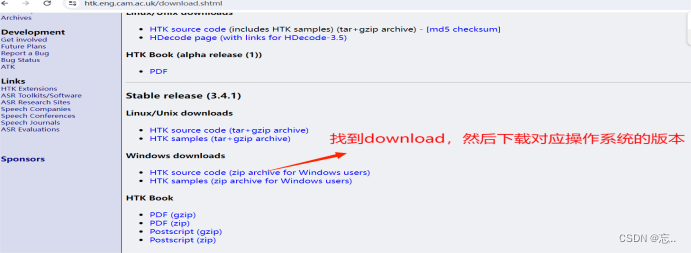
进入htk路径下:cd /d D:\jiankang\htk,前提是已经完成了相关环境变量的配置,其中包括HTKLib,HTKTools等路径。

-
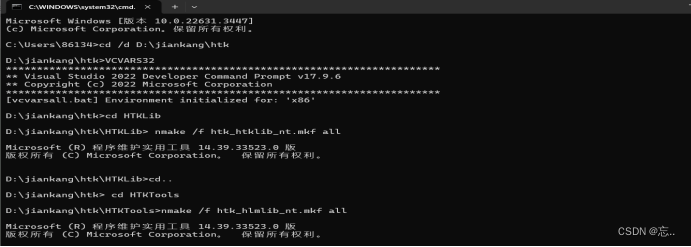
第二步:运行VCVARS32
出现Visual Studio的版本号,操作位数即表示成功。
-
第三步:编译HTK
-
1.编译Library
输入以下代码:
cd HTKLib(进入路径)
nmake /f htk_htklib_nt.mkf all

-
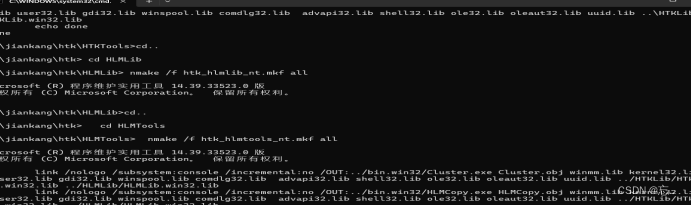
2.同理编译HTK TOOLS
前提是cd..返回htk目录下输入以下命令:
cd HTKTools
nmake /f htk_htktools_nt.mkf all
运行成功不报错会出现一些工具版本号等等信息意味编译成功。
-
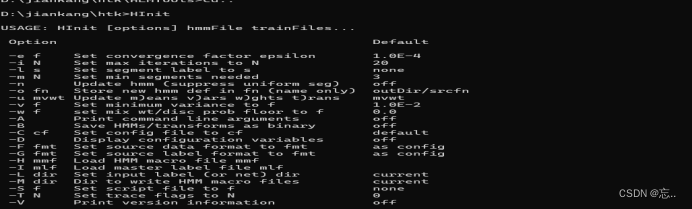
3.验证HTK编译
在编译完这些工具后,在htk所在路径下运行HInit后若出现以下界面,则表示编译成功
-
第四步:使用HSLAB录音
-
1.终端打开HSLAB工具
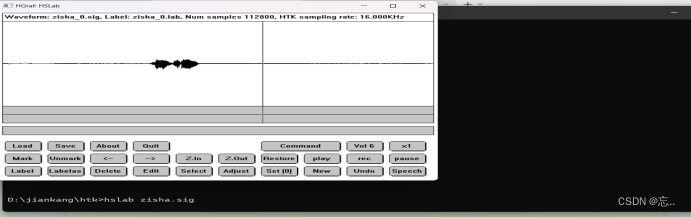
完成环境搭建后,使用HTK自带的工具HSLAB,运行cmd,在工作目录中输入hslab zisha.sig 则可弹出以下页面,然后进行点击rec录音,save保存即可。
-
2.提取特征文件
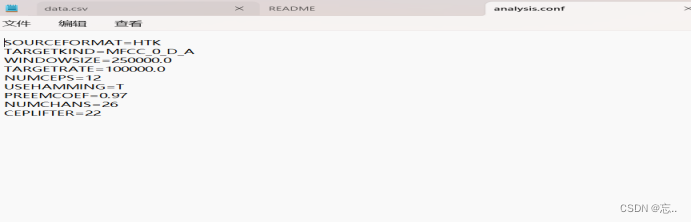
- 在htk路径下建一个test文件夹,在test文件夹内新建一个analysis.conf文件,文件内容如下:
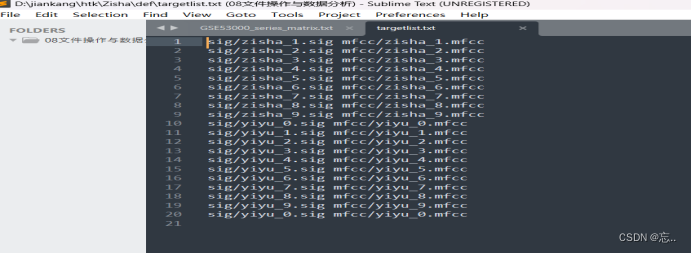
- 在def文件夹中新建一个targetlist.txt,内容如下:
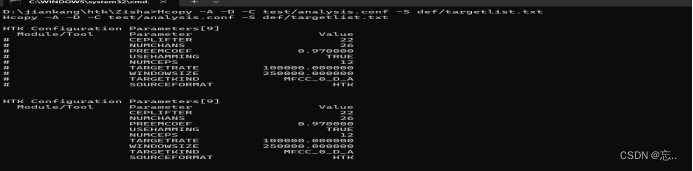
- 完成上面后,输入Hcopy -A -D -C test/analysis.conf -S def/targetlist.txt,运行成功后得到以下界面和20个mfcc文件。


-
第五步:初始化HMM模型
-
1.models文件夹配置
- 在models文件夹下新建三个无后缀文件hmm_zisha、hmm_yiyu、hmm_sil。在test文件中新建trainlist.txt文件。

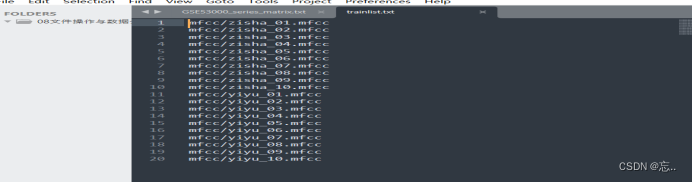
-
2.hmm文件配置
-
在hmms文件夹中新建hmm0文件夹
-
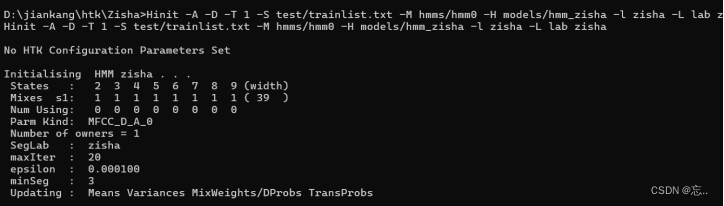
执行以下命令:
Hinit -A -D -T 1 -S test/trainlist.txt -M hmms/hmm0 -H models/hmm_zisha -l zisha -L lab zisha
Hinit -A -D -T 1 -S test/trainlist.txt -M hmms/hmm0 -H models/hmm_yiyu -l yiyu -L lab yiyu
Hinit -A -D -T 1 -S test/trainlist.txt -M hmms/hmm0 -H models/hmm_sil -l sil -L lab sil
3.输出结果
运行成功后可以在hmm0文件夹内得到hmm_zisha、hmm_yiyu、hmm_sil 这三个文件。
-
4.这一步我遇到的问题
-
EROR [+2121] HInit: Too Few Observation Sequences [0]FATAL ERROR - Terminating program Hinit
- 当然这过程到这一步出了个小插曲:EROR [+2121] HInit: Too Few Observation Sequences [0]FATAL ERROR - Terminating program Hinit这个错误信息通常出现在使用HInit初始化模型时,表示没有足够的观测序列用于初始化模型。观测序列是用于训练模型的数据序列,如果没有足够的数据来训练模型,就会导致这个错误。可能的原因包括:训练数据集中没有足够的观测序列,导致无法初始化模型。数据集中的观测序列数量非常少,不足以提供足够的信息来训练模型。数据集中的数据格式不正确,导致无法正确读取观测序列。
- 于是我又重新录入数据,录入多一点的数据试试(我不知是环境没配置完全,还是咋地,但是按照书上步骤运行前面也没报错也都能正常运行),也修改了定义的参数,也报错。然后就查阅了些许资料然后还是解决了这步,得到以下结果(hmm0内自动生成了三个文件):
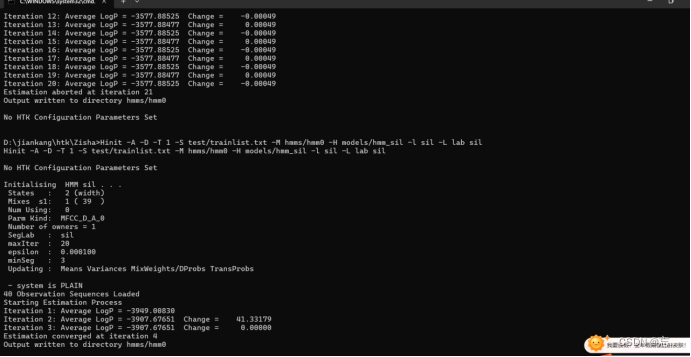
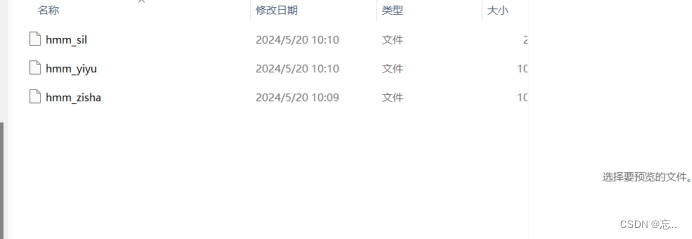
-
第六步:HMM模型训练
-
1.hmms文件夹配置
- 前面步骤完成后就到了HMM模型训练,在hmms文件中新建三个文件夹hmm1、hmm2、hmm3.使用以下命令:
HRest -A -D -T 1 -S test/trainlist.txt -M hmms/hmm1 -H hmms/hmm0/hmm_zisha -l zisha -L lab zisha
HRest -A -D -T 1 -S test/trainlist.txt -M hmms/hmm2 -H hmms/hmm1/hmm_zisha -l zisha -L lab zisha
HRest -A -D -T 1 -S test/trainlist.txt -M hmms/hmm3 -H hmms/hmm2/hmm_zisha -l zisha -L lab zisha
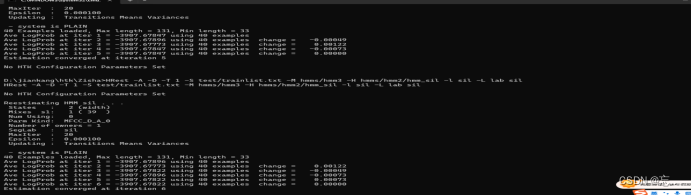

2.重复替代操作
将上述命令中的“zisha”替换为“yiyu”和“sil”,分别运行一次。运行成功后可以在hmm3文件夹中得到hmm_zisha、hmm_yiyu和hmm_sil三个文件。
-
3.建立语法和字典
-
1.def文件夹配置
在def中新建gram.txt文件,在def文件夹建立dict.txt,内容如下:


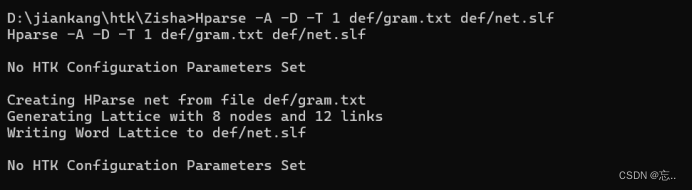
2.建立工作网络
然后建立工作网络,输入以下命令:Hparse -A -D -T 1 def/gram.txt def/net.slf
3.result文件夹和test文件夹配置
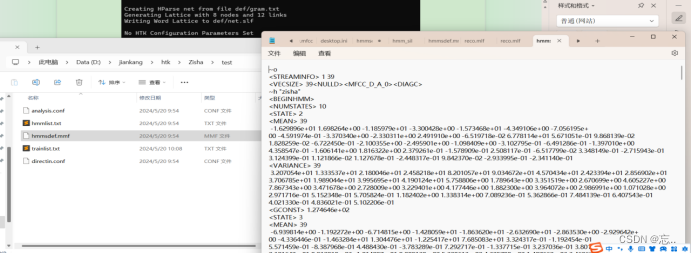
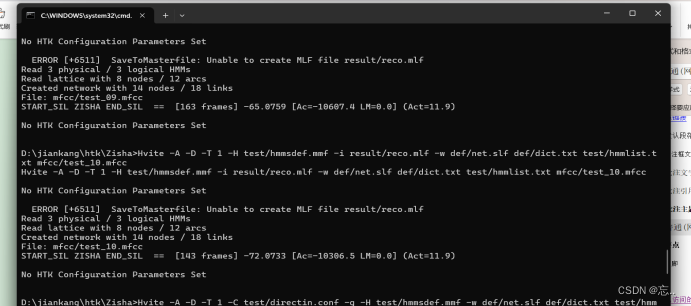
识别results文件夹中新建reco.mlf文件。在test文件夹中新建hmmsdef.mmf文件,其内容为hmms/hmm3文件夹中的所有hmm_xxx文件的数据,第一个复制进去的文件保留全部数据,剩下的文件从第一个~h开始复制,即只保留第一个~o。在test文件中新建hmmlist.txt,内容如下:zishayiyu sil 然后输入命令:
Hvite -A -D -T 1 -H test/hmmsdef.mmf -i result/reco.mlf -w def/net.slf def/dict.txt test/hmmlist.txt mfcc/test_01.mfcc
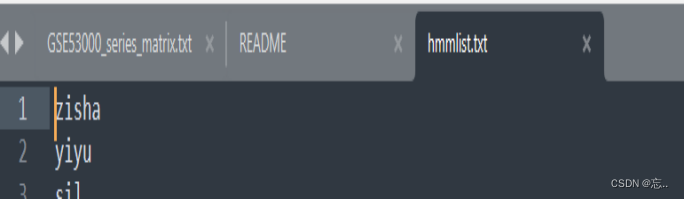
4.test文件中新建hmmlist.txt
在test文件中新建hmmlist.txt,然后输入命令:
Hvite -A -D -T 1 -H test/hmmsdef.mmf -i result/reco.mlf -w def/net.slf def/dict.txt test/hmmlist.txt mfcc/test_01.mfcc 重复完成多次,成功即得到如下结果。
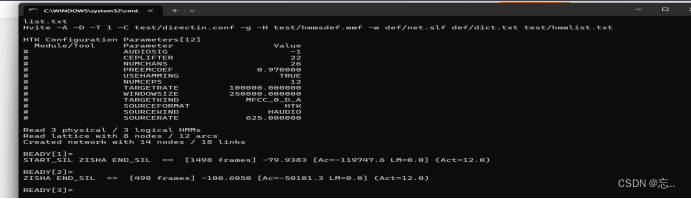
5.test文件夹中建一个directin.conf文件
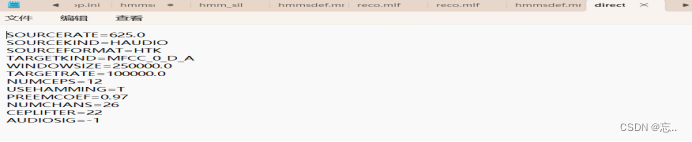
在test文件夹中建一个directin.conf文件,然后输入命令:Hvite -A -D -T 1 -H test/directin.conf -g -H test/hmmsdef.mmf -w def/net.slf def/dict.txt test/hmmlist.txt,出现“ready”后可说话,回车出现识别结果。如下:
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









