








最近我根据上述的技术体系图搜集了几十套腾讯、头条、阿里、美团等公司21年的面试题,把技术点整理成了视频(实际上比预期多花了不少精力),包含知识脉络 + 诸多细节,由于篇幅有限,这里以图片的形式给大家展示一部分

关键点总结如下:
1.该库中最近一次死锁发生的时间是什么时候?
4行:2020-07-14 23:34:29 0x7f958f1d5700得知,最近一次死锁发生在 2020-07-14 23:34:29
2.该次死锁导致的两个事务的重要信息?
12行:RECORD LOCKS space id 71816 page no 4 n bits 80 index idx_user_id of table mall.test_table trx id 95146580 lock_mode X locks rec but not gap waiting得知,事务 1 等待的锁为:lock_mode X locks rec but not gap waiting
24行:RECORD LOCKS space id 71816 page no 4 n bits 80 index idx_user_id of table mall.test_table trx id 95146581 lock_mode X locks rec but not gap得知,事务 2 持有的锁为:lock_mode X locks rec but not gap
34行:RECORD LOCKS space id 71816 page no 4 n bits 80 index idx_user_id of table mall.test_table trx id 95146581 lock_mode X locks rec but not gap waiting得知,事务 2 等待的锁为:lock_mode X locks rec but not gap waiting
39行:*** WE ROLL BACK TRANSACTION (2)得知,最后回滚的是事务 1
从 12、24、34 行:index idx_user_id of table mall.test_table得知:导致该次死锁的索引为:idx_user_id
3.能知道导致死锁的两个具体 SQL 吗?
不能,产生死锁的情况各式各样,事务中的 SQL 可能不止有两个 SQL,单从死锁日志是没法知道具体原因的,必须要结合业务代码查看事务上下文查看
2. 理论知识
============
排查过程中发现有个特点,影响的都是是线上的大用户。由于当时我很久没看死锁相关的理论知识,因此先去了解下相关死锁的基本知识。
2.1 死锁的条件
=============
-
互斥条件:一个资源每次只能被一个进程使用。
-
占有且等待:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
-
不可强行占有:进程已获得的资源,在未使用完之前,不能强行剥夺。
-
循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
破坏死锁也很简单,四个条件破一个即可。(本案例是破坏的 4)
2.2 数据库的锁类型
===============
数据库的死锁比较复杂,主要是由 Insert、Update(其实在开发中 Delete 或 For Update 是不怎么不考虑的,因为在实际业务代码中我们一般不会有 Delete 或 For Update 的操作,删除都是物理删除,for update 建议少用,除非你知道非用不可)。InnoDB 的锁:
-
共享锁与独占锁(S、X)
-
意向锁
-
记录锁(Record Locks)
-
间隙锁(Gap Locks)
-
Next-Key Locks
-
插入意向锁
-
自增锁
-
空间索引断言锁
这里参考了官网的 Innodb 锁分类,从死锁日志的 lock_mode X locks rec but not gap ,大致能知道,这里可能涉及了 X 锁、记录锁、间隙锁(但是有个 not,说明不涉及)。
3. 从死锁日志分析
===============
分析之前先得到该表的建表语句:show create table test_table;:
CREATE TABLE test_table (
id bigint(20) NOT NULL AUTO_INCREMENT,
money bigint(20) NOT NULL,
user_id bigint(20) NOT NULL,
PRIMARY KEY (id),
KEY idx_user_id (user_id)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8
接着结合死锁日志、锁的种类、建表语句得出以下模糊的结论:
1.从死锁日志的 10、12 行结合建表索引得知
10行:UPDATE test_table SET money = money + 5 WHERE user_id = 512行:RECORD LOCKS space id 71816 page no 4 n bits 80 index idx_user_id of table mall.test_table trx id 95146580
事务1的 UPDATE test_table SET money = money + 5 WHERE user_id = 5 语句在等待锁:它通过普通索引 idx_user_id 更新,先获取了 user_id=5 的 X 锁,接着去申请对应行的主键(Record Lock)的行锁但是被阻塞(waiting),并不包括间隙锁(not gap)。具体是哪个主键我们并不清楚。
2.从死锁日志的 22、24 行结合建表索引得知
22行:UPDATE test_table SET money = money + 4 WHERE user_id = 424行:Record lock, heap no 3 PHYSICAL RECORD: n_fields 2; compact format; info bits 0
事务2的 UPDATE test_table SET money = money + 4 WHERE user_id = 4 语句在持有锁:它通过普通索引 idx_user_id 更新,先获取了 user_id=4 的 X 锁,接着去申请对应行的主键(Record Lock)的行锁成功了,并不包括间隙锁(not gap)。具体是成功的哪个主键我们并不清楚。
3.从死锁日志的 22、34 行结合建表索引得知
22行:UPDATE test_table SET money = money + 4 WHERE user_id = 434行:RECORD LOCKS space id 71816 page no 4 n bits 80 index idx_user_id of table mall.test_table trx id 95146581 lock_mode X locks rec but not gap waiting
事务2的 UPDATE test_table SET money = money + 4 WHERE user_id = 4 语句在等待锁:它通过普通索引 idx_user_id 更新,先获取了 user_id=4 的 X 锁,接着去申请对应行的主键(Record Lock)的行锁但是被阻塞(waiting),并不包括间隙锁(not gap)。具体是哪个主键我们并不清楚。
模糊结论肯定是有问题的,最大的问题在于导致的 SQL 语句不正确,即:死锁的原因是真实的,但是具体是因为哪些 SQL 导致的死锁是不清楚的。接着我们整理得到了以下可能有问题的表格:
事务1事务2某些 SQL某些 SQL某个 SQL 的 user_id = 5 新更新操作被阻塞了某个 SQL 的 user_id = 4 获得了锁但是又阻塞了某些 SQL某些 SQL
可以得知,其实单从死锁日志分析是比较片面的,因为 user_id 为 4、5 这两个 update 操作是不会有互相阻塞的问题,肯定是有别的 SQL 因此,我们需要额外从业务日志分析才能还原完整的现场。
4. 从业务日志分析
===============
从死锁日志是不能完全知道导致的关键 SQL 和故障现场的整体流程,因此我们要借助业务日志来完成最后对故障现场的分析:通过前面对业务日志的分析,我们知道最关键的调用方法是 BizManagerImpl.transactionMoney,查看对应源码:
@Override
@Transactional
public boolean transactionMoney(List transactionReqVOList) throws Exception {
for (TransactionReqVO transactionReqVO : transactionReqVOList) {
// 模拟业务操作
Thread.sleep(1000);
int updateCount = testTableService.update(transactionReqVO.getUserId(), transactionReqVO.getMoney());
if (updateCount == 0) {
log.error(“转账异常:” + transactionReqVO);
}
}
return true;
}
可以知道,应该是 for 循环事务的问题,但是具体是哪些 user_id 是不清楚的,接着我们查看业务日志的上下文,通过全链路 traceId(模拟) 做搜索,得到以下的日志:
[ConsumerThread2] org.example.controller.TestController : 全局链路跟踪id:2的日志:[TransactionReqVO(userId=4, money=4), TransactionReqVO(userId=2, money=2), TransactionReqVO(userId=5, money=5)]
[ConsumerThread1] org.example.controller.TestController : 全局链路跟踪id:1的日志:[TransactionReqVO(userId=5, money=5), TransactionReqVO(userId=1, money=1), TransactionReqVO(userId=4, money=4)]
分析到这一步,我们已经可以还原死锁场景了,事务流程图如下:
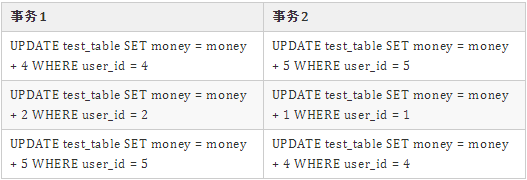
5. 业务日志、死锁日志结合分析
=====================
将死锁日志分析得出的不正确表格加上业务日志分析得出正确表格,我们得出最终带有理解的最终正确的事务表格:
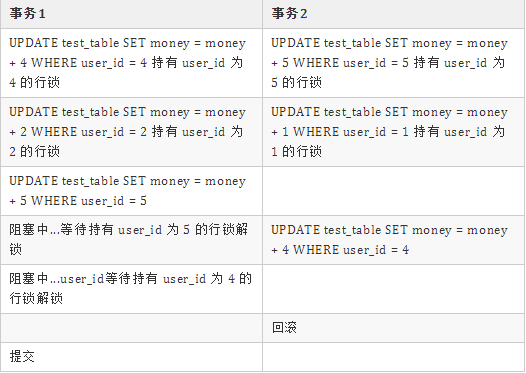
可以知道,其实死锁日志的 SQL 是模糊的,但是原因是正确的,至于具体是哪些 SQL 导致的死锁,是需要从业务日志来判定。
6. 善后
==========
模拟出了事务2的场景,我们就可以对回滚的 SQL 执行,来人工修复受到影响的用户数据(客户第一)。也可以知道其实 transactionMoney() 方法不应该加事务,因为该业务场景每个用户的更新是独立的不应该互相受到影响,但是当某条更新失败时,我们也要打印对应的日志。
这里我们就知道为什么之前大半年都没问题,最近才频发这种异常,因为只有当两个事务同时执行,并且两个事务中包含了相同的两个或两个以上的 user_id 才会可能触发该异常。而这种 user_id 都是所谓的大用户,像该示例中的 user_id 为 1、2 是小用户,虽然它们也受到了影响,但是频率是没有 user_id 为 4、5 这种大用户高的。
在实际的业务场景也证实了这点,不仅是发生故障的时间是集中在高峰期,而且发生故障的用户也经常有那几个熟面孔,经过后面复盘,这几个熟面孔用户也就是我们所说的”大用户“(业务操作频率高的用户)。
7. 模拟项目源码
==============
为了模拟真实场景中的方法调用(消息接收调用执行),使用了线程来模拟。并且使用线程睡眠来保证每个事务执行够长,来让每次模拟执行都出现异常。
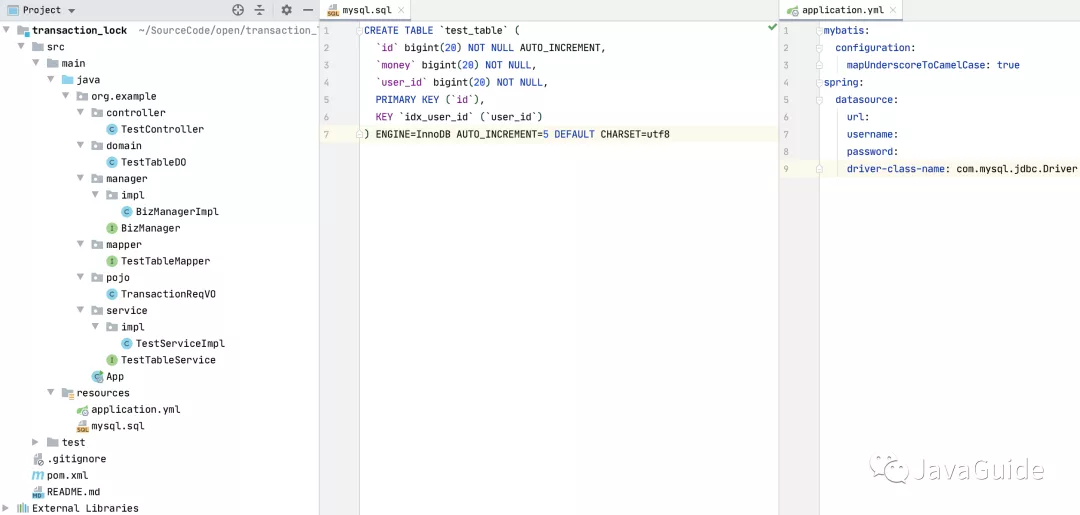
项目结构比较简单, Controller -> Manager -> Service -> Mapper -> DB,执行 curl ‘localhost:8080/test/consumer’ 后,查看命令行输出即可看到业务异常日志。
对应的死锁日志需要到对应的数据库执行:show engine innodb status 后可看到。
8. 最后
==========
中间查阅了很多资料,发现有个项目总结了所有的死锁日志对应的可能 SQL:https://github.com/aneasystone/mysql-deadlocks,里面也讲解了加锁的各个细节过程,是非常值得一看的。以下为该项目的部分截图:
当遇到复杂的业务场景,尤其是不熟悉的时候,这个是一个很好的参考资料。
业务日志记录、全链路跟踪是非常非常重要的
分享
首先分享一份学习大纲,内容较多,涵盖了互联网行业所有的流行以及核心技术,以截图形式分享:
(亿级流量性能调优实战+一线大厂分布式实战+架构师筑基必备技能+设计思想开源框架解读+性能直线提升架构技术+高效存储让项目性能起飞+分布式扩展到微服务架构…实在是太多了)
其次分享一些技术知识,以截图形式分享一部分:
Tomcat架构解析:

算法训练+高分宝典:

Spring Cloud+Docker微服务实战:

最后分享一波面试资料:
切莫死记硬背,小心面试官直接让你出门右拐
1000道互联网Java面试题:

Java高级架构面试知识整理:

死记硬背,小心面试官直接让你出门右拐
1000道互联网Java面试题:
[外链图片转存中…(img-M4vl4J8A-1715267575337)]
Java高级架构面试知识整理:
[外链图片转存中…(img-Zvw6m4b6-1715267575337)]















 290
290











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









