








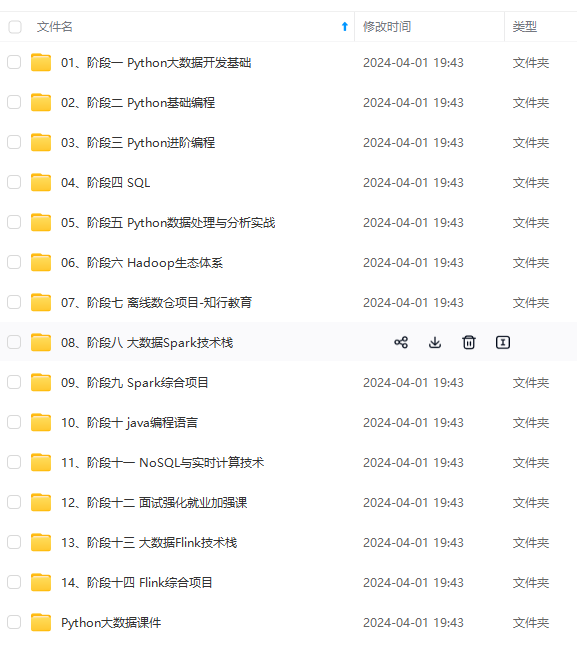
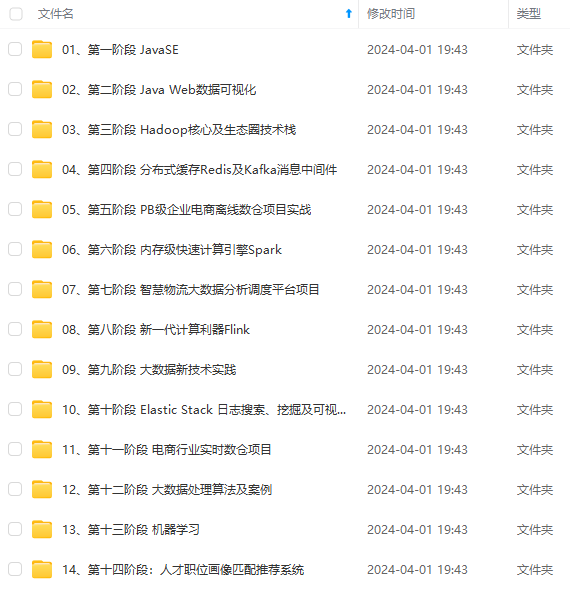
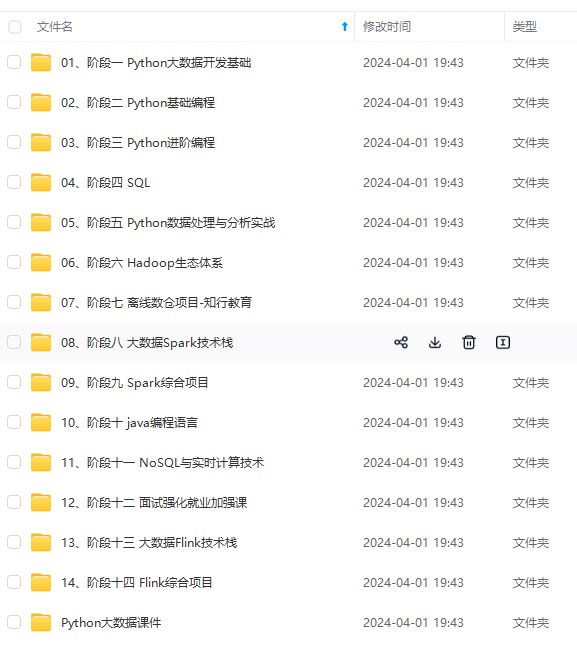
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
16)Storm事务案例升级之按天计算
17)Storm分区事务案例实战
18)Storm不透明分区事务案例实战
19)DRPC精解和案例分析
20)Storm Trident 入门
21)Trident API和概念
22)Storm Trident实战之计算网站PV
23)ITridentSpout、FirstN(取Top N)实现、流合并和Join
24)Storm Trident之函数、流聚合及核心概念State
25)Storm Trident综合实战一(基于HBase的State)
26)Storm Trident综合实战二
27)Storm Trident综合实战三
28)Storm集群和作业监控告警开发
八、Spark技术实战之基础篇 -Scala语言从入门到精通
为什么要学习Scala?源于Spark的流行,Spark是当前最流行的开源大数据内存计算框架,采用Scala语言实现,各大公司都在使用Spark:IBM宣布承诺大力推进Apache Spark项目,并称该项目为:在以数据为主导的,未来十年最为重要的新的开源项目。这一承诺的核心是将Spark嵌入IBM业内领先的分析和商务平台,Scala具有数据处理的天然优势,Scala是未来大数据处理的主流语言
1)-Spark的前世今生
2)-课程介绍、特色与价值
3)-Scala编程详解:基础语法
4)-Scala编程详解:条件控制与循环
5)-Scala编程详解:函数入门
6)-Scala编程详解:函数入门之默认参数和带名参数
7)-Scala编程详解:函数入门之变长参数
8)-Scala编程详解:函数入门之过程、lazy值和异常
9)-Scala编程详解:数组操作之Array、ArrayBuffer以及遍历数组
10)-Scala编程详解:数组操作之数组转换
11)-Scala编程详解:Map与Tuple
12)-Scala编程详解:面向对象编程之类
13)-Scala编程详解:面向对象编程之对象
14)-Scala编程详解:面向对象编程之继承
15)-Scala编程详解:面向对象编程之Trait
16)-Scala编程详解:函数式编程
17)-Scala编程详解:函数式编程之集合操作
18)-Scala编程详解:模式匹配
19)-Scala编程详解:类型参数
20)-Scala编程详解:隐式转换与隐式参数
21)-Scala编程详解:Actor入门
九、大数据核心开发技术 - 内存计算框架Spark
Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点。启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。Spark Streaming: 构建在Spark上处理Stream数据的框架,基本的原理是将Stream数据分成小的时间片断(几秒),以类似batch批量处理的方式来处理这小部分数据
1)Spark 初识入门
2)Spark 概述、生态系统、与MapReduce比较
3)Spark 编译、安装部署(Standalone Mode)及测试
4)Spark应用提交工具(spark-submit,spark-shell)
5)Scala基本知识讲解(变量,类,高阶函数)
6)Spark 核心RDD
7)RDD特性、常见操作、缓存策略
8)RDD Dependency、Stage常、源码分析
9)Spark 核心组件概述
10)案例分析
11)Spark 高阶应用
12)Spark on YARN运行原理、运行模式及测试
13)Spark HistoryServer历史应用监控
14)Spark Streaming流式计算
15)Spark Streaming 原理、DStream设计
16)Spark Streaming 常见input、out
17)Spark Streaming 与Kafka集成
18)使用Spark进行分析
十、大数据核心开发技术 - Spark深入剖析
1)Scala编程、Hadoop与Spark集群搭建、Spark核心编程、Spark内核源码深度剖析、Spark性能调优
2)Spark源码剖析
十一、企业大数据平台高级应用
完成大数据相关企业场景与解决方案的剖析应用及结合一个电子商务平台进行实战分析,主要包括有: 企业大数据平台概述、搭建企业大数据平台、真实服务器手把手环境部署、使用CM 5.3.x管理CDH 5.3.x集群
1)企业大数据平台概述
2)大数据平台基本组件
3)Hadoop 发行版本、比较、选择
4)集群环境的准备(系统、基本配置、规划等)
5)搭建企业大数据平台
6)以实际企业项目需求为依据,搭建平台
7)需求分析(主要业务)
8)框架选择(Hive\HBase\Spark等)
9)真实服务器手把手环境部署
10)安装Cloudera Manager 5.3.x
11)使用CM 5.3.x安装CDH 5.3.x
12)如何使用CM 5.3.x管理CDH 5.3.x集群
13)基本配置,优化
14)基本性能测试
15)各个组件如何使用
十二、项目实战:驴妈妈旅游网大型离线数据电商分析平台
离线数据分析平台是一种利用hadoop集群开发工具的一种方式,主要作用是帮助公司对网站的应用有一个比较好的了解。尤其是在电商、旅游、银行、证券、游戏等领域有非常广泛,因为这些领域对数据和用户的特性把握要求比较高,所以对于离线数据的分析就有比较高的要求了。 本课程讲师本人之前在游戏、旅游等公司专门从事离线数据分析平台的搭建和开发等,通过此项目将所有大数据内容贯穿,并前后展示!
1)Flume、Hadoop、Hbase、Hive、Oozie、Sqoop、离线数据分析,SpringMVC,Highchat
2)Flume+Hadoop+Hbase+SpringMVC+MyBatis+MySQL+Highcharts实现的电商离线数据分析
3)日志收集系统、日志分析、数据展示设计
十三、项目实战:基于1号店的电商实时数据分析系统
1)全面掌握Storm完整项目开发思路和架构设计
2)掌握Storm Trident项目开发模式
3)掌握Kafka运维和API开发、与Storm接口开发
4)掌握HighCharts各类图表开发和实时无刷新加载数据
5)熟练搭建CDH5生态环境完整平台
6)灵活运用HBase作为外部存储
7)可以做到以一己之力完成从后台开发(Storm、Kafka、Hbase开发) 到前台HighCharts图表开发、Jquery运用等,所有工作一个人搞定! 可以一个人搞定淘宝双11大屏幕项目!
十四、项目实战:基于美团网的大型离线电商数据分析平台
本项目使用了Spark技术生态栈中最常用的三个技术框架,Spark Core、Spark SQL和Spark Streaming,进行离线计算和实时计算业务模块的开发。实现了包括用户访问session分析、页面单跳转化率统计、热门商品离线统计、 广告点击流量实时统计4个业务模块。过合理的将实际业务模块进行技术整合与改造,该项目完全涵盖了Spark Core、Spark SQL和Spark Streaming这三个技术框架中几乎所有的功能点、知识点以及性能优化点。 仅一个项目,即可全面掌握Spark技术在实际项目中如何实现各种类型的业务需求!在项目中,重点讲解了实际企业项目中积累下来的宝贵的性能调优 、troubleshooting以及数据倾斜解决方案等知识和技术
1)真实还原完整的企业级大数据项目开发流程:项目中采用完全还原企业大数据项目开发场景的方式来讲解,每一个业务模块的讲解都包括了数据分析、需求分析、方案设计、数据库设计、编码实现、功能测试、性能调优、troubleshooting与解决数据倾斜(后期运维)等环节,真实还原企业级大数据项目开发场景。让学员掌握真实大数据项目的开发流程和经验!
2)现场Excel手工画图与写笔记:所有复杂业务流程、架构原理、Spark技术原理、业务需求分析、技术实现方案等知识的讲解,采用Excel画图或者写详细比较的方式进行讲解与分析,细致入微、形象地透彻剖析理论知识,帮助学员更好的理解、记忆与复习巩固。
十五、机器学习及实践
基于PyMC语言以及一系列常用的Python数据分析框架,如NumPy、SciPy和Matplotlib,通过概率编程的方式,讲解了贝叶斯推断的原理和实现方法。该方法常常可以在避免引入大量数学分析的前提下,有效地解决问题。课程中使用的案例往往是工作中遇到的实际问题,有趣并且实用。回归等算法有较为深入的了解,以Python编程语言为基础,在不涉及大量数学模型与复杂编程知识的前提下,熟悉并且掌握当下最流行的机器学习算法,如回归、决策树、SVM等,并通过代码实例来 展示所讨论的算法的实际应用。
1)Mahout、Spark MLlib概述
2)机器学习概述
3)线性回归及Mahout、SparkMLlib案例
4)Logistic回归、softmax分类及Mahout、SparkMLlib案例
5)KNN及Mahout、SparkMllib案例
6)SVM及Mahout、SparkMllib案例
7)决策树及Mahout、SparkMllib案例
8)随机森林及Mahout、SparkMllib案例
9)GBDT及Mahout、SparkMllib案例
10)KMeans及Mahout、SparkMllib案例
11)贝叶斯及Mahout、SparkMllib案例
12)集成学习
13)特征处理及模型优化
十六、推荐系统
开发推荐系统的方法,尤其是许多经典算法,重点探讨如何衡量推荐系统的有效性。课程内容分为基本概念和进展两部分:前者涉及协同推荐、基于内容的推荐、基于知识的推荐、混合推荐方法,推荐系统的解释、评估推荐系统和实例分析;后者包括针对推荐系统的攻击、在线消费决策、推荐系统和下一代互联网以及普适环境中的推荐
1)协同过滤推荐
2)基于内容的推荐
3)基于知识的推荐
4)混合推荐方法
5)推荐系统的解释
6)评估推荐系统
7)案例研究
十七、分布式搜索引擎Elasticsearch开发
联网+、大数据、网络爬虫、搜索引擎等等这些概念,如今可谓炙手可热
1)Elasticsearch概念
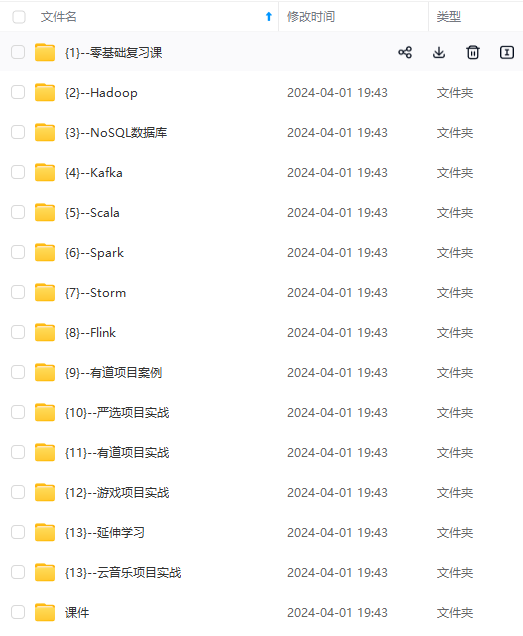
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
炙手可热
1)Elasticsearch概念
[外链图片转存中…(img-6BFJgnLu-1715273198234)]
[外链图片转存中…(img-LHJx4r4O-1715273198235)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1024
1024

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









