






我用的CentOS7做演示。
一.什么是init?
init进程,它是一个由内核启动的用户级进程(不需要内核支持而在用户程序中实现的线程)。
init命令是Linux系统中的进程初始化工具,是一切服务程序的父进程,它的进程号永远为1。管理员可以使用init命令对系统运行级别进行自由切换,亦可进行重启、关机等操作。
二.init一共有7个运行级别
可以从 /etc/rc.d文件夹下面看出来。
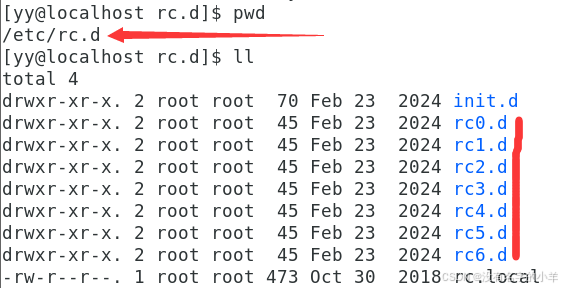
init.d:这个文件夹,这里面就是存放的shell脚本。
rc.local:存放的是脚本的路径。
正式介绍7种运行级别和切换方法
(0)运行级别0:官方是系统停机状态,系统默认运行级别不能设为0,否则不能正常启动。我认为就是关机。
命令:init 0
(1)运行级别1:官方是单用户工作状态,root权限,用于系统维护,禁止远程登陆
单用户工作状态:系统维护模式,该模式允许系统管理员登录到系统,只有一个用户可以登录。在单用户模式中,网络服务会被禁用,所以用户无法连接任何其它计算机。这个模式也被称作救援模式,因为它允许您修复损坏的系统,解决不可恢复的问题或者恢复丢失的数据。这个模式还允许用户更改或者重置Linux用户密码。在单用户模式下,您需要知道root用户的密码,因为这是唯一允许访问系统的用户。(面试题有考这个的)
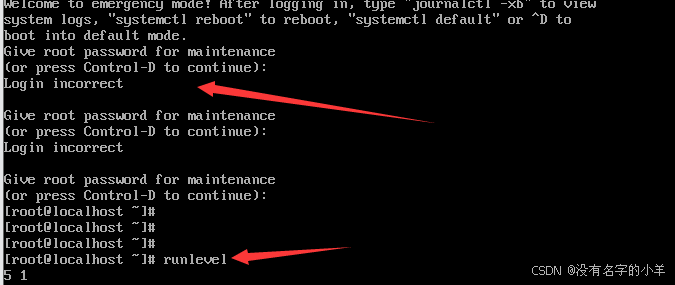
命令:init 1
叫你输入root用户的密码,并且你会发现它的运行级别变成了5 1,之前只有5。
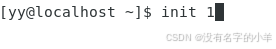
(2)运行级别2:官方是多用户状态(没有网络),不完全的多用户模式。
命令:init 2
不同于运行模式1的直接锁定了root用户,这里叫你输入账户名。
很奇怪的是我运行的init 2,显示的是运行级别3。查了好久也没发现是为什么。如果知道可以评论一下,谢谢。
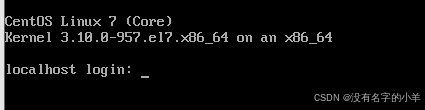
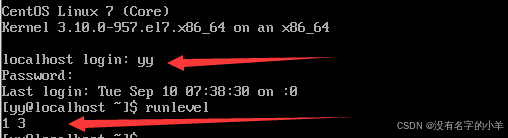
(3)运行级别3:官方是多用户状态(有网络),标准模式,其实更喜欢叫它命令框模式。
命令:init 3
同init2,
(4)运行级别4:官方是保留状态,其实没有实际含义,没有功能。
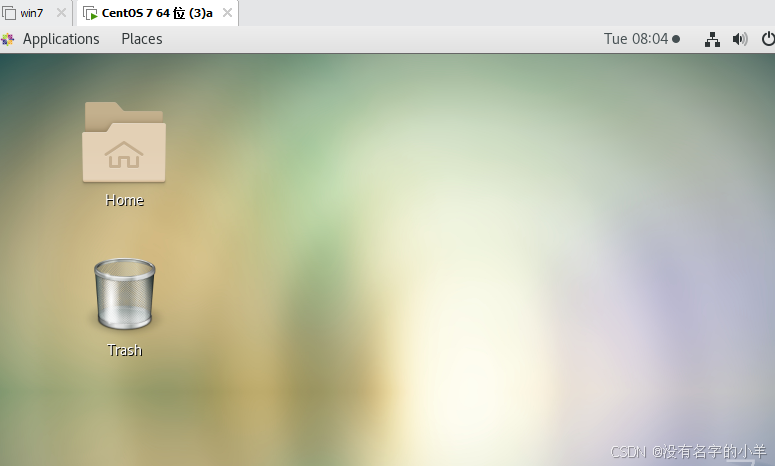
(5)运行级别5:官方是X11控制台,登陆后进入图形GUI模式,说白了就是可视化界面,就像windows一样。
命令:init 5
(6)运行级别6:官方是系统正常关闭并重启,默认运行级别不能设为6,否则不能正常启动,就是重启。
命令:init 6
重启了

三.启动默认的运行权限
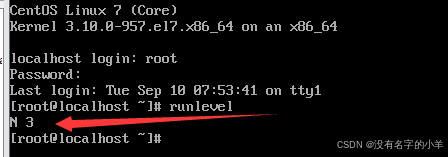
(1)runlevel 查看运行级别的变换,前一个数是之前的运行级别,后一个属是当前的运行级别

(2)systemctl get-default 查看默认运行级别
表示默认的运行级别是5,重启之后就是可视化界面。
(3)设置默认运行级别:
修改运行等级为3,下面这两条命令都可以修改。
systemctl set-default multi-user.target
systemctl set-default runlevel3
可以看到重启之后,直接是运行级别3,命令框模式。

修改运行等级为5,下面这两条命令都可以。
systemctl set-default graphical.target
systemctl set-default runlevel5




















 942
942

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









