







最后
笔者已经把面试题和答案整理成了面试专题文档






(1.2)在 pom.xml 里面加上

(1.3)创建 Test 类,好了工程就已经搭好了。
【2】Httpclient 实现网络请求
(2.1)什么是 httpclient ?
Httpclient 是 Apache 的一个子项目,它是一个为 Java 可以实现网络请求的客户端工具包。
简单的说,他是一个 Jar 包,有了他,我们通过 Java 程序就可以实现网络请求。
(2.2) 复制下面的 httpclient 依赖,加入到 pom.xml 文件中。
<!-- httpclient 核心包 -->
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.2</version>
</dependency>
 (2.3)创建一个 HttpTool 的类,这个类我们专门用来实现网络请求相关方法。
(2.3)创建一个 HttpTool 的类,这个类我们专门用来实现网络请求相关方法。
(2.4) 为了避免其他网站侵权问题,下面以我个人网站一个页面为例(http://www.zyqok.cn/material/index),我们来抓取这个页面上的所有图片。

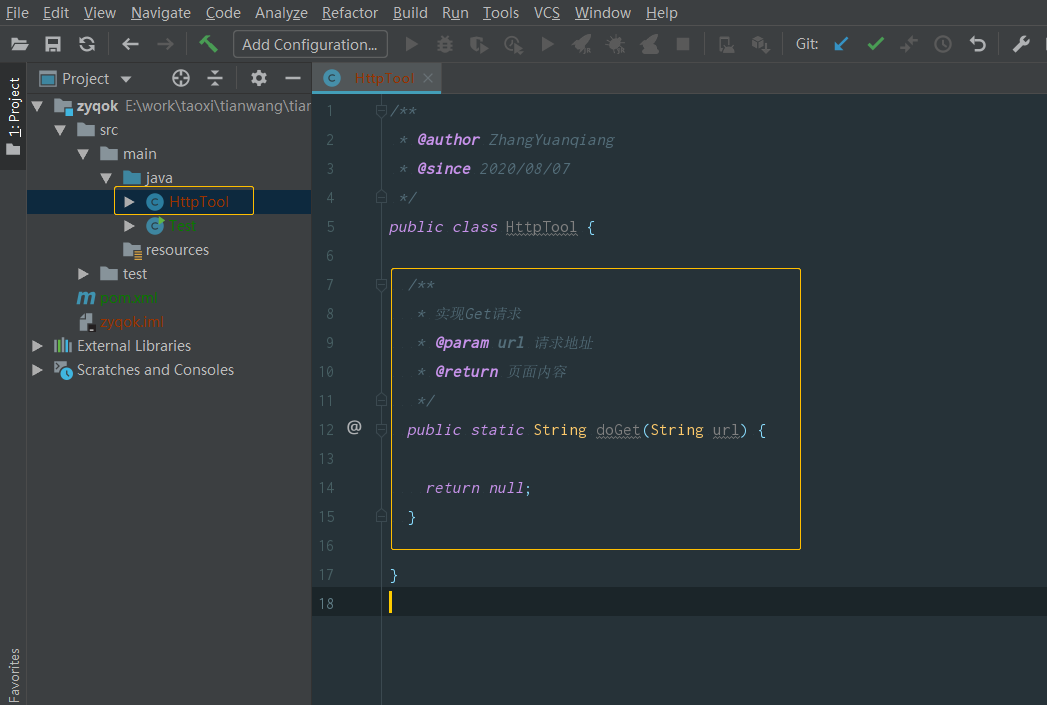
(2.5) 可以看得出,这是一个 get 请求,并且返回的是一个 Html 页面。所以我们在 HttpTool 类中加入一个如下方法体:
/**
* 实现Get请求
* @param url 请求地址
* @return 页面内容
*/
public static String doGet(String url) {
return null;
}
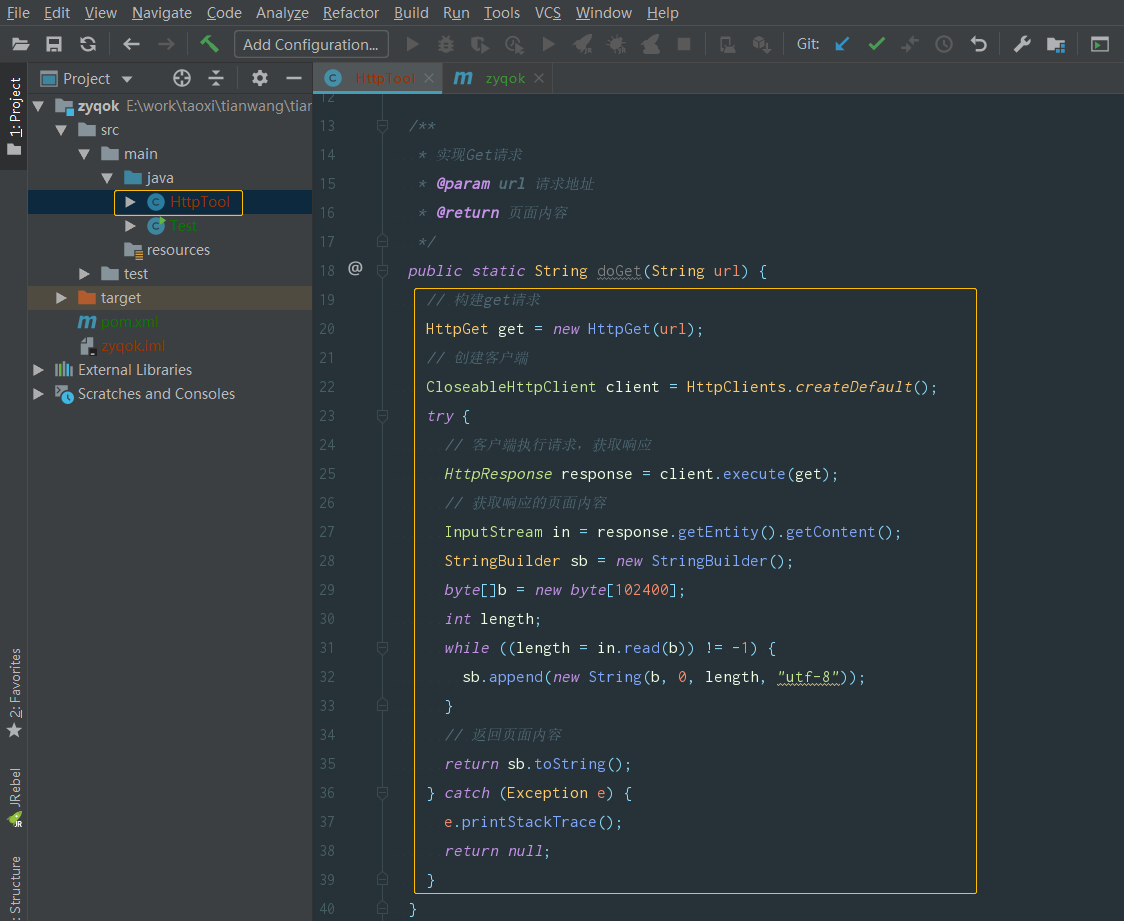
(2.6)复制代码,添加 get 实现方法:
// 构建get请求
HttpGet get = new HttpGet(url);
// 创建客户端
CloseableHttpClient client = HttpClients.createDefault();
try {
// 客户端执行请求,获取响应
HttpResponse response = client.execute(get);
// 获取响应的页面内容
InputStream in = response.getEntity().getContent();
StringBuilder sb = new StringBuilder();
byte[]b = new byte[102400];
int length;
while ((length = in.read(b)) != -1) {
sb.append(new String(b, 0, length, "utf-8"));
}
// 返回页面内容
return sb.toString();
} catch (Exception e) {
e.printStackTrace();
return null;
}
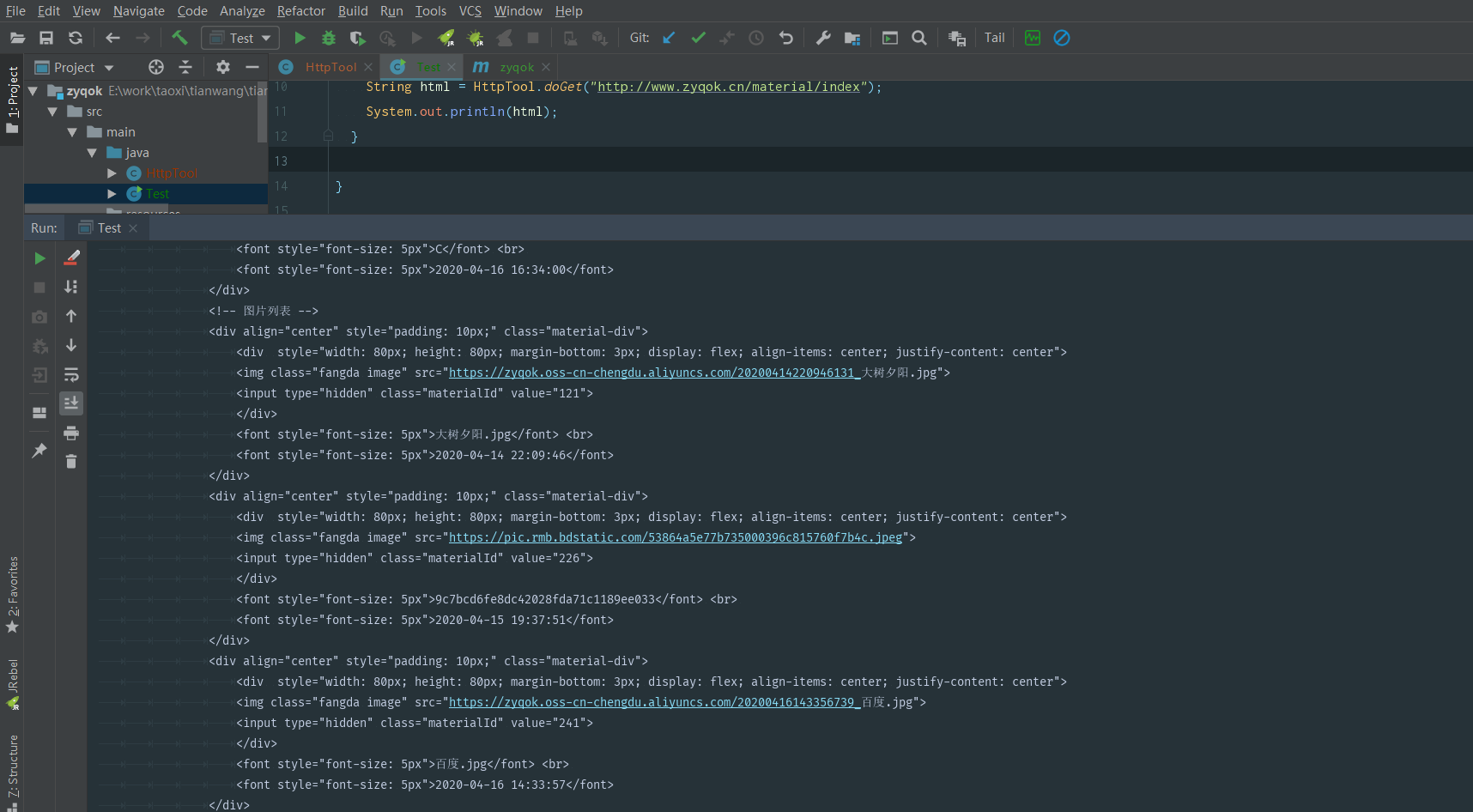
(2.7)OK,网络请求相关实现类我们已经写好了,我们接下来测试下,我们在 Test 类的 main 方法里加入如下代码:
String html = HttpTool.doGet("http://www.zyqok.cn/material/index");
System.out.println(html);
(2.8)执行程序,查看结果。可以看到我们确实已经通过请求,获取到网页的返回内容了。
【3】Jsoup 解析网页
在整个【2】的实现过程中,我们已经拿到网页返回的数据,但我们要的是整个网页中的图片,并不是这种杂乱无章的网页页面数据,那么我们该怎么办呢?简单,接下来我们需要用到另外一种技术了 ---- Jsoup。
(3.1)什么是 Jsoup 技术?
下面是度娘给出的一个官方解释:Jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据(摘自百度)。
下面再用我个人语言简单的总结下:Jsoup 技术就是用来处理各种 html 页面 和 xml 数据。我们这里可以通过 Jsoup 来处理【2】中返回的 html 页面。
(3.2)加入 Jsoup 依赖
我们在 pom.xml 加入如下依赖:
<!-- Jsoup 核心包 -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.3</version>
</dependency>
(3.3)当然,使用 Jsoup 之前,我们需要对响应的 HTML 页面进行分析,分析主要作用是:如何定位筛选出我们需要的数据?
我们把【2】中获取到的页面响应拷贝到 txt 文本中,然后可以发现:每个图片它都包含在一个 div 中,且该div 有一个名为 material-div 的 class。

(3.4)按照上面分析:首先我们要获取到包含图片的所有 div,于是我们修改main方法中代码为如下:
String html = HttpTool.doGet("http://www.zyqok.cn/material/index");
// 将 html 页面解析为 Document 对象
Document doc = Jsoup.parse(html);
// 获取所有包含 class = material-div 的 div 元素
Elements elements = doc.select("div.material-div");
for(Element div: elements){
System.out.println(div.toString());
}
注意:doc.select() 括号中的参数为过滤条件,基本等同于 Jquery 的过滤条件,所以会Jquery的同学,如何筛选条件基本就得心应手的,当然不会写筛选条件的也不要怕,这里有一份 Jsoup 使用指南,阁下不妨收下(传送门:Jsoup 官方使用指南)。

(3.5)我们执行代码,将输出结果继续拷贝到文本中。
可以看到,本次确实只有图片相关的div元素了,但这并不是我们想要的最终结果,我们最终的结果是获取到所有图片。
所以我们还需要继续分析:如何获取所有图片的链接和名字。

(3.6)由于每个图片所在的div元素结构都一样,所以我们可以取随机取一个div元素进行分析,于是我们可以取第一个div来进行分析,结构如下:
<div align="center" style="padding: 10px;" class="material-div">
<div style="width: 80px; height: 80px; margin-bottom: 3px; display: flex; align-items: center; justify-content: center">
<img class="fangda image" src="https://zyqok.oss-cn-chengdu.aliyuncs.com/20200414220946131_大树夕阳.jpg">
<input type="hidden" class="materialId" value="121">
</div>
<font style="font-size: 5px">大树夕阳.jpg</font><br>
<font style="font-size: 5px">2020-04-14 22:09:46</font>
</div>
(3.7)我们可以看到,整个结构内,就一个 img 元素标签,于是我们可以取第1个img标签的 src 属性为图片链接;同理,我们取第1个 font 元素的文本内容为图片名称。

(3.8)于是我们可以修改循环中的代码内容如下:
// 获取第1个 img 元素
Element img = div.selectFirst("img");
// 获取第1个 font 元素
Element font = div.selectFirst("font");
// 获取img元素src属性,即为图片链接
String url = img.attr("src");
// 获取name元素文本,即为图片名称
String name = font.text();
System.out.println(name + ": " + url);

总结
大型分布式系统犹如一个生命,系统中各个服务犹如骨骼,其中的数据犹如血液,而Kafka犹如经络,串联整个系统。这份Kafka源码笔记通过大量的设计图展示、代码分析、示例分享,把Kafka的实现脉络展示在读者面前,帮助读者更好地研读Kafka代码。
麻烦帮忙转发一下这篇文章+关注我

中各个服务犹如骨骼,其中的数据犹如血液,而Kafka犹如经络,串联整个系统。这份Kafka源码笔记通过大量的设计图展示、代码分析、示例分享,把Kafka的实现脉络展示在读者面前,帮助读者更好地研读Kafka代码。
麻烦帮忙转发一下这篇文章+关注我
[外链图片转存中…(img-1J8B7odh-1715297622735)]















 8540
8540











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









