






一、知识点
集合、泛型、Map。
二、目标
-
了解集合关系图。
-
掌握List和Set的区别。
-
掌握ArrayList和LinkedList的区别。
-
熟练使用集合相关API。
三、内容分析
-
重点
-
集合、泛型、Map。
-
-
难点
-
集合相关API的使用。
-
各个集合底层原理的区别。
-
四、内容
1、泛型
泛型的本质就是"参数化类型",将原来具体的类型参数化。
// 这个T可以换成随便一个字母,我们一般会使用大写字母。如果有多个,使用<T,R,...>
public class Student<T> {
private String name;
private T sex;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public T getSex() {
return sex;
}
public void setSex(T sex) {
this.sex = sex;
}
public static void main(String[] args) {
// 定义的时候设置<String>,意味着Student<T>的T就是String,所以在setSex中只能传递String类型的数据进去
Student<String> student1 = new Student<>();
student1.setSex("1");
// 定义的时候设置<Integer>,意味着Student<T>的T就是Integer,所以在setSex中只能传递Integer类型的数据进去
Student<Integer> student2 = new Student<>();
student2.setSex(1);
}
}2、集合
用来存放多个对象的容器。
-
集合主要是两组(单列集合、双列集合)。
-
Collection接口有两个重要的子接口 List Set,它们的实现子类都是单列集合。
-
Map接口的实现子类是双列集合,存放的Key-Value(键值对)。
java.util.Collection下的接口和继承类关系简易结构图:
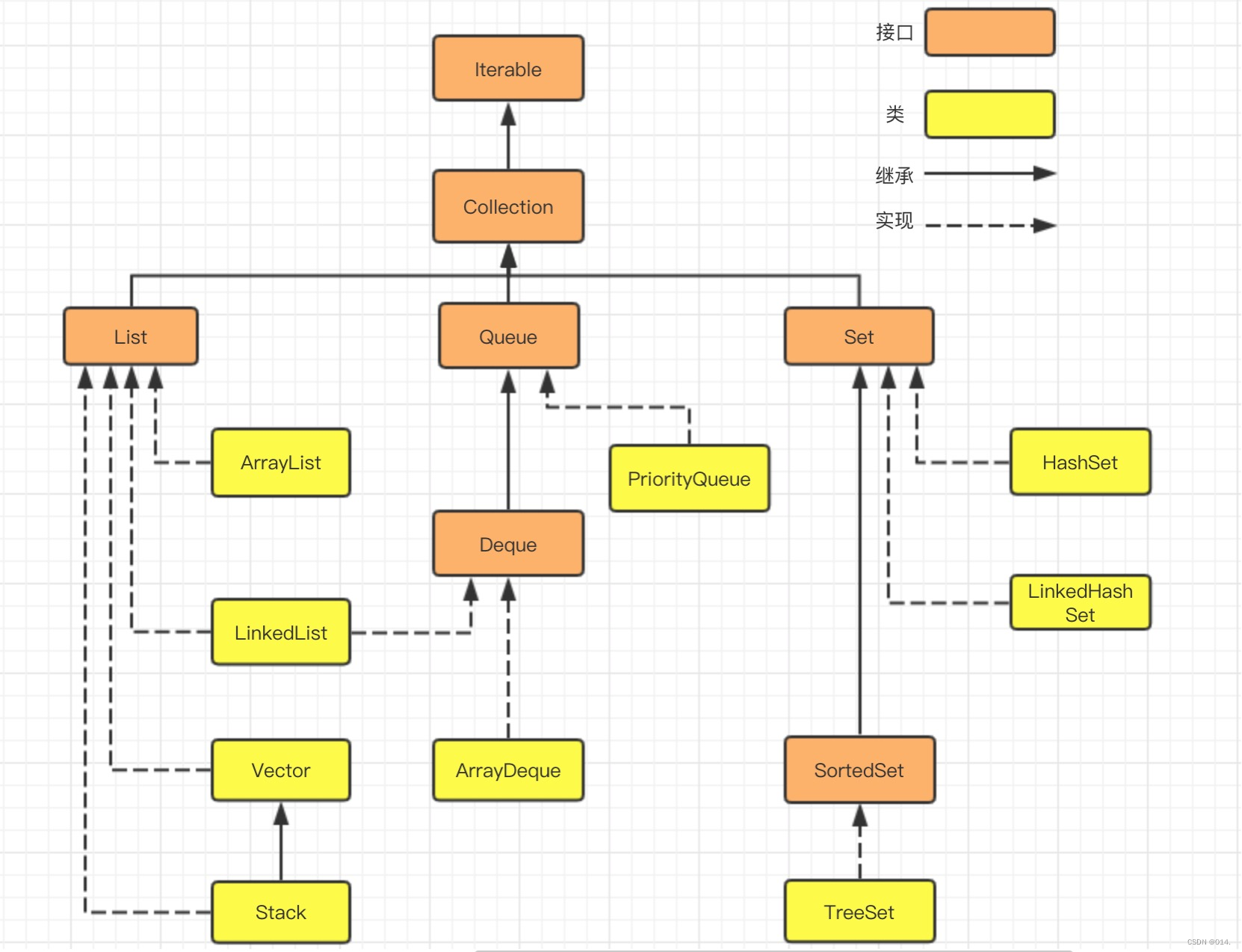
2.1 List
存取有序的集合,并且有索引值,元素可以重复。
2.1.1 ArrayList
底层使用数组实现。不是线程安全的,查询速度快
//利用数组实现
// 一个学生数组
String[] strArr1 = new String[3];
strArr1[0] = "张三";
strArr1[1] = "李四";
strArr1[2] = "王五";
// 添加一个新同学
String[] strArr2 = new String[4];
for(int i = 0; i < strArr1.length; i++) {
strArr2[i] = strArr1[i];
}
strArr2[3] = "赵六";public static void main(String[] args) {
// 创建ArrayList对象
List<String> list = new ArrayList<>();
// 添加元素,使用add方法,add(类型由泛型决定)
list.add("张三");
list.add("李四");
list.add("王五");
// 获取元素, 使用get方法,get(下标从0开始)
String name = list.get(1);
System.out.println(name); // 李四
// 遍历List
for(int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
// 增强for循环遍历
for(String str:list) {
System.out.println(str);
}
// 使用迭代器遍历
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()) {
System.out.println(iterator.next());
}
}常用方法:查看jdk文档。
| 返回值类型 | 方法和描述 |
|---|---|
boolean | add(E e) 将指定的元素追加到此列表的末尾。 |
void | add(int index, E element) 在此列表中的指定位置插入指定的元素。 |
boolean | addAll(Collection<? extends E> c) 按指定集合的Iterator返回的顺序将指定集合中的所有元素追加到此列表的末尾。 |
boolean | addAll(int index, Collection<? extends E> c) 将指定集合中的所有元素插入到此列表中,从指定的位置开始。 |
void | clear() 从列表中删除所有元素。 |
boolean | contains(Object o) 如果此列表包含指定的元素,则返回 true 。 |
E | get(int index) 返回此列表中指定位置的元素。 |
int | indexOf(Object o) 返回此列表中指定元素的第一次出现的索引,如果此列表不包含元素,则返回-1。 |
boolean | isEmpty() 如果此列表不包含元素,则返回 true 。 |
Iterator<E> | iterator() 以正确的顺序返回该列表中的元素的迭代器。 |
int | lastIndexOf(Object o) 返回此列表中指定元素的最后一次出现的索引,如果此列表不包含元素,则返回-1。 |
E | remove(int index) 删除该列表中指定位置的元素。 |
boolean | remove(Object o) 从列表中删除指定元素的第一个出现(如果存在)。 |
boolean | removeAll(Collection<?> c) 从此列表中删除指定集合中包含的所有元素。 |
E | set(int index, E element) 用指定的元素替换此列表中指定位置的元素。 |
int | size() 返回此列表中的元素数。 |
Object[] | toArray() 以正确的顺序(从第一个到最后一个元素)返回一个包含此列表中所有元素的数组。 |
2.1.2 LinkedList
底层使用链表实现。
public static void main(String[] args) {
// 创建LinkedList对象
List<String> list = new LinkedList<>();
// 添加元素,使用add方法,add(类型由泛型决定)
list.add("张三");
list.add("李四");
list.add("王五");
// 遍历
for(int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
}常用方法:与ArrayList基本相似。
特点:添加、修改、删除的性能高,查询的性能不高
2.1.3 Vector
底层和ArrayList一样使用数组实现,线程安全的。缺点是效率比较低。
public static void main(String[] args) {
// 创建Vector对象
List<String> list = new Vector<>();
// 添加元素,使用add方法,add(类型由泛型决定)
list.add("张三");
list.add("李四");
list.add("王五");
// 遍历
for(int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
}常用方法:与ArrayList基本相似。
2.1.4 区别
-
ArrayList底层是用数组实现的,查询修改的效率比较快,增删的效率比较慢。
-
LinkedList底层是通过双向链表实现的,增删的速度较快,查询修改的速度比较慢。
-
Vector和ArrayList一样,都是通过数组实现的,但是Vector是线程安全的。
2.2 Set
存取无序的集合,元素不能重复。
保证元素唯一性需要让元素重写两个方法:一个是 hashCode(),另一个是 equals()。HashSet在存储元素的过程中首先会去调用元素的hashCode()值,看其哈希值与已经存入HashSet的元素的哈希值是否相同,如果不同 :就直接添加到集合;如果相同 :则继续调用元素的equals() 和哈希值相同的这些元素依次去比较。如果说有返回true的,那就重复不添加;如果说比较结果是false,那就是不重复就添加。
2.2.1 HashSet
无序,元素不能重复,允许存在一个null值。
public static void main(String[] args) {
Set<String> set = new HashSet<>();
set.add("a");
set.add("a");
set.add("b");
set.add("c");
set.add("a1");
System.out.println(set); // [a1, a, b, c]与添加的顺序是不一致的,是无序的。并且添加两个"a",最后只打印一个出来。
}常用方法:查看jdk文档。
2.2.2 LinkedHashSet
有序的set,元素不能重复,允许一个null存在。
public static void main(String[] args) {
Set<String> set = new LinkedHashSet<>();
set.add("a");
set.add("b");
set.add("c");
set.add("a1");
System.out.println(set); // [a, b, c, a1],顺序与添加的顺序一致。
}常用方法:查看jdk文档。
2.2.3 TreeSet
自定义排序,元素不能重复,不允许null存在。
Set<Integer> set = new TreeSet();
set.add(5);
set.add(10);
set.add(13);
set.add(3);
set.add(2);
set.add(4);
set.add(18);
set.add(11);
set.add(9);
// 会发现,打印出来的元素从小到大排序了。
System.out.println(set); // [2, 3, 4, 5, 9, 10, 13, 14, 18]TreeSet使用二叉树进行排序,存储规则:
-
第一个元素作为根节点。
-
从第二个元素开始,每个元素从根节点开始比较。
-
比根节点大,就作为右子树;
-
比根节点小,就作为左子树;
-
与根节点相等,表示重复,不存储。
接下来介绍TreeSet具体如何实现:
让元素所在的类实现Comparable接口,并重写CompareTo() 方法,并根据CompareTo()的返回值来进行添加元素。
根据compareTo返回值决定:
-
返回1,认为新插入的元素比上一个元素大,于是二叉树存储时,会存在根的右侧。
-
返回-1,认为新插入的元素比上一个元素小,于是二叉树存储时,会存在根的左侧。
-
返回0,表示重复,不存储。
// Integer源码
// 为什么TreeSet里面存储Integer数据的时候会默认升序,因为Integer重写了Comparable接口的compareTo方法
public final class Integer extends Number implements Comparable<Integer> {
public int compareTo(Integer anotherInteger) {
return compare(this.value, anotherInteger.value);
}
public static int compare(int x, int y) {
return (x < y) ? -1 : ((x == y) ? 0 : 1);
}
}接下来通过案例分析TreeSet实现自定义排序的过程:
假设有学生类(姓名name,年龄age),现在有若干个学生对象,现在要按照年龄排序,放到容器中,我们就可以选择使用TreeSet解决。
// 学生类
public class Student implements Comparable{
private String name;
private Integer age;
public Student(String name, Integer age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public int compareTo(Object o) {
Student student = (Student) o;
return (this.age < student.age) ? -1 : ((this.age == student.age) ? 0 : 1);
}
}// 测试
public static void main(String[] args) {
// 有三个学生对象
Student student1 = new Student("张三", 18);
Student student2 = new Student("李四", 20);
Student student3 = new Student("王五", 19);
// 把学生存入set
Set<Student> students = new TreeSet<>();
students.add(student1);
students.add(student2);
students.add(student3);
// 遍历set
for(Student student:students) {
/*
打印结果:按照年龄升序。
Student{name='张三', age=18}
Student{name='王五', age=19}
Student{name='李四', age=20}
*/
System.out.println(student);
}
}2.3 Map(字典)
Map用于保存具有映射关系的数据,因此Map集合里保存着两组值,一组值用于保存Map里的key,另外一组值用于保存Map里的value。key和value都可以是任何引用类型的数据。
Map的存储结构:
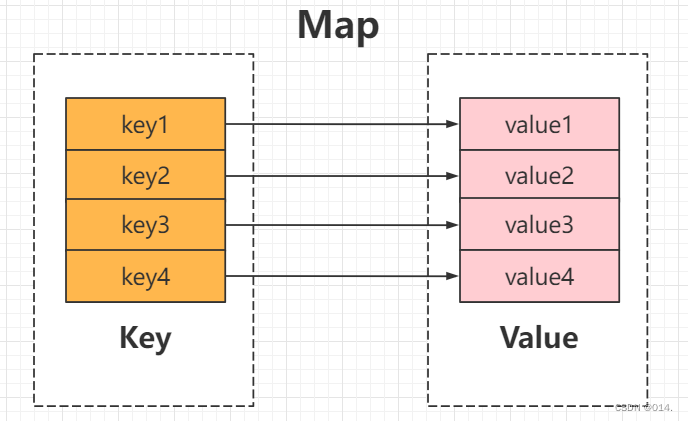
2.3.1 HashMap
-
无序,存储元素和取出元素的顺序有可能不一致;
-
key不能重复,key允许是null;允许多个 null值和一个null键(key重复值会被覆盖)
-
不是线程安全的。
Map<String, Integer> map = new HashMap<>();
// Map存值使用put(key, value)方法
map.put("a1", 100);
map.put("b", 150);
map.put("a2", 200);
map.put("a2", 300); // key重复,会把前面的值覆盖
// Map取值使用get(key) 方法
System.out.println(map.get("a1")); // 100
System.out.println(map.get("a2")); // 300
// keySet()获取map里面的key集合
Set<String> keys = map.keySet();
for(String key:keys) {
System.out.println("key: " + key + " value:" + map.get(key)); // 打印的顺序和存数据的顺序可能是不一致的
}2.3.2 TreeMap
-
可以按照key来做排序,默认按照 key 进行升序排序,
-
key不能重复,key不允许为null;
-
不是线程安全的。
Map<String, Integer> map = new TreeMap<>();
map.put("a1", 100);
map.put("b", 150);
map.put("a2", 200);
Set<String> keys = map.keySet();
for(String key:keys) {
System.out.println(key); // 打印顺序:a1,a2,b。
}Map<String, Integer> map = new TreeMap<>(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o2.compareTo(o1);
}
});
map.put("a1", 100);
map.put("b", 150);
map.put("a2", 200);
// map.put(null, 1); // 有异常,不允许键为null
Set<String> keys = map.keySet();
for(String key:keys) {
System.out.println(key); // 打印顺序:b,a1,a2。打印顺序和上面相反了
}2.3.3 Hashtable
-
无序;
-
不允许有任何的null键和null值;
-
是线程安全的。
Map<String, Integer> map = new Hashtable<>();
// 运行会出现异常:NullPointerException
map.put(null, 1);
map.put("a", null);2.3.4 LinkedHashMap
-
有序的;
-
key不能重复,key允许是null;允许一个null键和多个null值
-
不是线程安全的。
Map<String, Integer> map = new LinkedHashMap<>();
map.put("a1", 100);
map.put("b", 150);
map.put("a2", 200);
Set<String> keys = map.keySet();
for(String key:keys) {
System.out.println(key); // 打印的顺序与存储的顺序一致
}五、小结
主要介绍了Java容器Collection、Map接口以及接口下的实现类。容器相关的实现种类比较多,需要注意区别,记住每一个实现类的特点与使用场景
六、练习
-
什么是集合,请列举集合中常用的类和接口?
-
请简述使用泛型的优点。
-
集合中的List、set、map有什么区别?
-
从键盘随机输入10个整数保存到List中,并按照倒序、从大到小的顺序显示出来。















 2019
2019

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









