






1.String是什么
String就是字符串,是Redis最基本的对象,最大的数据量限制是512M,最小数据量要根据Redis的版本而定。
最大数据量限制可以通过redis.conf中的proto-max-bulk-len修改:
# proto-max-bulk-len 512mb2.使用场景
一切字符串数据都可以使用String存储:字节数据,文本数据,序列化后的对象数据。、
确切的应用场景:
1.缓存场景:使用Value存储JSON字符串(序列化后的Object对象等)
2.计数场景:String也是可以存储整形数字/浮点型数字的,由于Redis执行命令是串行的(即可以保证执行命令是原子性),使用String对访问量,点赞量,转发量,库存数量计算是非常合适的(天然具有原子性,保证了线程安全)
3.常用操作
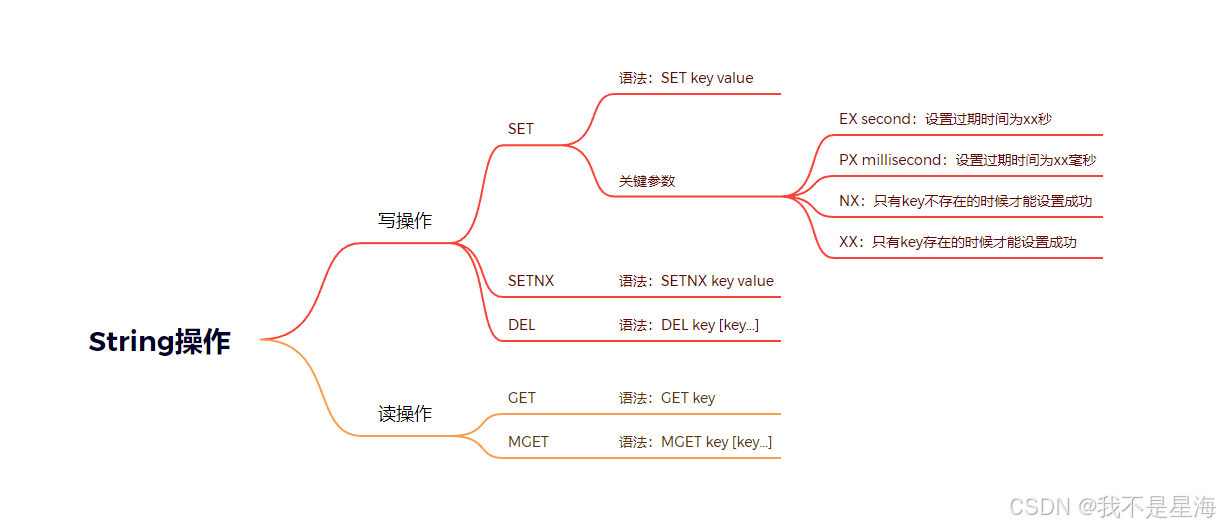
3.1常用操作分析
经常使用的操作其实就是对String的增删改查(需要注意的是这里说的是value对应的String对象,key本身就是String对象,也只能是String对象,对于key的操作就不过多解释了)
创建:SET SETNX
查询:GET MGET
更新:SET
删除:DEL
3.2写操作
3.2.1SET
语法:SET key value
功能:设置一个key的值为特定的value,设置成功则返回OK。
String的创建/更新都可以基于此命令:
127.0.0.1:6379> set niuma cc
OKSET命令有几个十分重要的扩展参数:
1.EX second:在设置key-value的时候,设置过期时间是多少秒
2.PX millisecond:在设置key-value的时候,设置过期时间是多少毫秒
3.NX:只有key不存在的时候,才对key进行操作,效果等同于SETNX key value,基本是替代了SETNX操作。
4.XX:只有key已经存在的时候,才对key进行操作。
要点:SET如果不指定EX和PX参数,则过期时间是-1,即永久有效。
3.2.2SETNX
语法:SETNX key value
功能:只有key不存在的的时候,才能设置key-value键值对成功,如果key-value存在就会设置失败,设置成功返回1,设置失败返回0。
对于不存在的key调用SETNX:
127.0.0.1:6379> setnx niuma2 cc
(integer) 1对于存在的key调用SETNX:
127.0.0.1:6379> setnx niuma2 c1
(integer) 03.2.3DEL
语法:DEL key [key...]
功能:删除key-value键值对,可以一次性删除多个key-value键值对,返回值为成功删除了几行。
127.0.0.1:6379> del niuma niuma2
(integer) 23.3读操作
3.3.1GET
语法:GET key
功能:查询某个key,存在就返回对应的value数据,不存在就返回nil(类似于null)
127.0.0.1:6379> set niuma cc nx
OK
127.0.0.1:6379> get niuma
"cc"
127.0.0.1:6379> get niuma2
(nil)
127.0.0.1:6379> 3.3.2MGET
语法:MGET key [key...]
功能:一次性查询多个key,如果key存在就返回value,不存在就返回nil。
127.0.0.1:6379> MGET niuma niuma2
1) "cc"
2) (nil)3.4操作大总结
4.底层实现
4.1三种编码方式
4.1.1了解三种编码方式
String看起来简单,但实际上有三种编码方式:
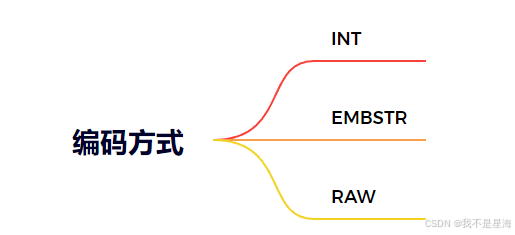
INT编码:可以用long表示的整数都会使用这个编码,存储整数。
EMBSTR:如果字符串小于等于阈值字节大小,就会使用EMBSTR编码。
RAW:如果字符串大于阈值字节大小,就会使用RAW编码。
EMBSTR和RAW的阈值大小限定和Redis的版本有关系,Redis3.2之前是39个字节,Redis3.2开始是44个字节(在Redis3.2的时候Redis中的字符串结构发生了一些变化)
注意点:EMBSTR和RAW的阈值字节统计只是包含字符串的长度统计,不包含组成String对象的结构体的大小。
4.1.2编码中的阈值
Redis中使用OBJ_ENCODING_EMBSTR_LIMIT这个变量控制由EMBSTR转换为RAW的阈值,可以看到当前7.2版本中,这个变量被定义为了44,当占用字节小于等于44个字节的时候,创建EMBSTR编码的字符串,大于44个字节,创建RAW编码的字符串。
#define OBJ_ENCODING_EMBSTR_SIZE_LIMIT 44
robj *createStringObject(const char *ptr, size_t len) {
if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT)
return createEmbeddedStringObject(ptr,len);
else
return createRawStringObject(ptr,len);
}
在Redis3.0的源码中,OBJ_ENCODING_EMBSTR_SIZE_LIMIT被限定为了39个字节:
#define REDIS_ENCODING_EMBSTR_SIZE_LIMIT 39
robj *createStringObject(char *ptr, size_t len) {
if (len <= REDIS_ENCODING_EMBSTR_SIZE_LIMIT)
return createEmbeddedStringObject(ptr,len);
else
return createRawStringObject(ptr,len);
}4.1.3结构分析
EMBSTR和RAW编码都是由RedisObject和SDS实现的。
区别在于EMBSTR编码的字符串,组成其的RedisObject和SDS是一次性分配空间的,RAW并非如此,RAW分配的空间是可变的。
EMBSTR的缺点在于如果重新分配空间,那么字符串对象就要重新分配空间,这是非常麻烦的一件事情,所以EMBSTR被设计为仅可读取,如果EMBSTR编码的String对象发生了变化,会被认为字符串是易变的,直接转变为RAW编码。
可以从以下角度理解EMBSTR和RAW的结构:
4.1.3.1EMBSTR内存存储结构分析
EMBSTR内存存储结构:

即EMBSTR是由两个结构体组成的,即RedisObject结构体和SDS结构体。SDSHDR结构体中有两个十分重要的字段:1.len字段,表示存储字符的长度,alloc表示String Object能够存储的最大长度,alloc - len代表的就是预留的空间,由于EMBSTR编码的String Object是一次性开辟空间,不会再次扩容,所以alloc和len的大小一致,预留空间alloc - len为0。
4.1.3.2RAW内存存储结构分析
RAW编码内存存储结构:
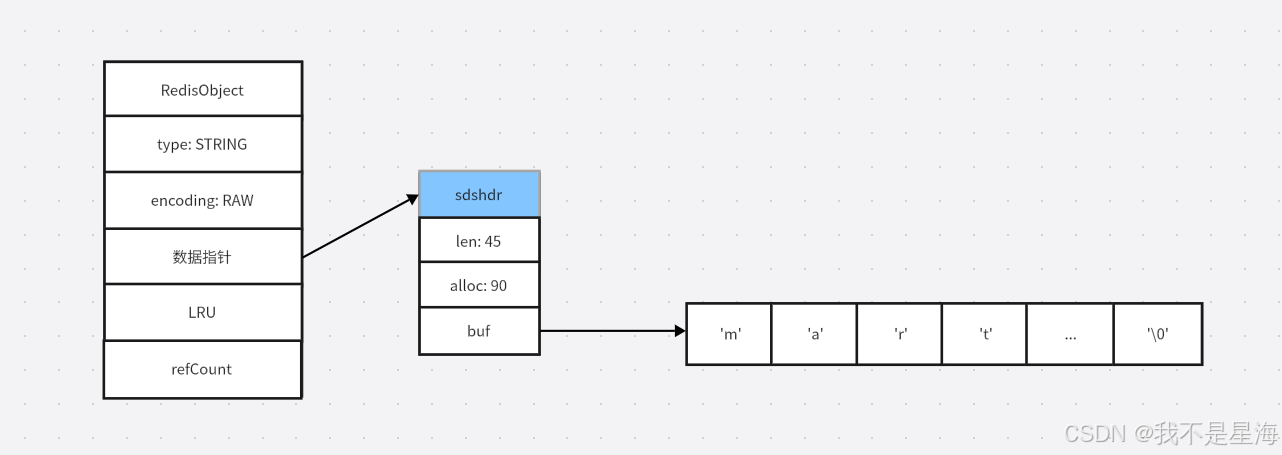
RAW编码的字符串对象也是由两个结构体RedisObject和SDS组成的,但是RAW编码的String对象的SDS的buf指针指向的数组是可以变化的,当存储空间不够的时候,Redis底层会实现自动扩容,扩大SDS的存储空间。并且RAW编码的字符串对象开辟的SDS在初始化时会有空间冗余(即alloc - len > 0)
4.1.4编码转换
String对象的编码不是永恒不变的,随着我们对String对象的操作,其编码也会被行为驱动发生改变。
前提铁律:在Redis中编码的转换时在对象写入时随之进行的,且过程不可逆,即小编码只能向大编码转换,反之则不可以。
INT => RAW,当存入的内容不再是整数,或者超出long能够表示的范围时,就会由INT编码转换为RAW编码。
EMBSTR => RAW,执行任何写操作的时候,都会由EMBSTR转换为RAW。
原因可以从两个角度去分析:
1.上层角度:EMBSTR被认为是不可变对象,一旦发生变化,就认为字符串是易变的,转换为RAW编码。
2.底层角度:EMBSTR开辟的空间是一次性分配的,如果变化,需要重新花费较高的成本,这个过程是很昂贵的,所以一旦发生转变,易变字符串对象的底层编码就会转换为RAW编码。
4.2SDS
4.2.1初识SDS
4.2.1.1什么是SDS
SDS即为Simple Dynamic String的缩写,简单动态字符串。
从定义上就不难理解,SDS是动态的字符串,相对于C语言的普通字符串做了一些改进。
4.2.1.2C语言中SDS的定义
在C语言中定义了多个SDS简单动态字符串的结构体:
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};SDS结构体中定义了len,alloc,flags字段。
4.2.1.3C语言中有String为什么还要定义SDS结构体?
C语言作为一个底层的语言,String定义的非常简单,底层使用char数组实现,并以'\0'字符作为字符串的结尾。
这就导致了三个问题:
1.计算字符串的长度len是O(N)的。
2.没有预留空间,字符串多长就开辟多长的数组,每次增加字符串内容都需要数组扩容。
3.以’\0‘为结尾,存储二进制数据是不安全的。
总结来说:C语言原生的String性能不行,二进制不安全。
SDS结构体就是为了解决以上的问题而生的数据结构,使用len字段将计算字符串长度的时间复杂度降低至O(1),使用alloc和buf数组开辟预留空间,避免每次追加字符串的操作都要使得字符数组扩容,不以’\0‘为结尾,保证了二进制安全。
4.2.2多种多样的SDS
为什么Redis要定义这么多种SDS呢?
其实这么多种SDS结构体字段属性都是一样的,主要的区别在于它们分别对应不同大小的字符串。
以SDS8结构体为例:
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};len和alloc是长度和预留长度,buf是存储字符的数组,SDS就是使用这些解决了原生字符串的三个问题的。
flags表示的是SDS的类型。
比如SDS8的类型定义如下:
#define SDS_TYPE_8 14.2.3字符串预留空间
前面说过,Redis使用SDS结构体替代String的主要原因之一是原生字符串每次追增数据时都需要将底层数据扩容,为了降低这个昂贵的开销,SDS在开辟空间时会预留出一部分空间。
字符串的大小小于1M时,预留的空间和字符串的大小一致,即len长度的预留空间。
字符串的大小大于1M时,预留的空间固定为1M。
即可以简单理解为:预留空间为Math.min(len, 1M)
5.常见面试题
5.1Set一个已有的数据会发生什么
会将原有的数据抹除,并将原有的数据的过期时间抹除,替换为新的数据和新的过期时间。
5.2浮点型在使用String时用什么表示?
这像是一个大坑,很多人可能会类比说String有三种编码方式,只有整型才用INT编码,走数字存储,那就掉坑里了。
整型对应的是INT编码的String,底层还是依赖的SDS结构的char数组存储的数据,浮点型对应的编码是EMBSTR/RAW,其使用的依然是String存储,所以无论如何存储任何数字数据,都是使用的String字符串存储。
5.3String可以有多大
String的最大值可以存储512MB的数据,在3.2版本的源码中是直接写死的512MB,但是在后来4.0版本中与又增加了proto-max-bulk-len配置项,可以调整String的最大存储空间。
5.4Redis字符串是怎么实现的
Redis字符串底层采用的是Redis自封装的SDS结构体和RedisObject结构体实现的字符串结构,字符串底层有三种编码:INT/EMBSTR/RAW,如果存储的数据是可以被long表示的整型,采用的编码是INT,其他数据按字符串是否小于等于某个阈值分别采用EMBSTR编码/RAW编码,在Redis3.2版本之前,阈值被设定为39,自Redis3.2版本开始,阈值被更改为44。
5.5为什么EMBSTR的阈值是44
阈值是44的原因需要从Redis底层默认的内存管理器Jemalloc角度上分析。
Jemelloc内存管理器是以64个字节为一个存储单元,即占用的内存小于等于64个字节的时候,只需要一个存储单元,如果超过了64个字节,就需要采用多个存储单元存储数据,会增加内存寻址的消耗。
分析StringObject的组成:
1.其组成是RedisObject和SDS,RedisObject的结构如下:
struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
};type和encoding共占用8bit,即一个字节。
lru的字节占用被设定为24个字节。
#define LRU_BITS 24refCount引用计数占用32个字节。
ptr指针为了在多平台间有良好的兼容性,被认为是指针的最大值,占用64个字节。
即redisObject的占用为:(8 + 24 + 32 + 64) / 8 = 16个字节。
2.SDS结构如下:
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};len占用1字节,alloc占用1字节,flag占用1字节,buf数组中会存在一个‘\0’占位符,占用1字节。
即SDS的占用为1 + 1 + 1 + 1 = 4字节。
最终我们可知,StringObject的非内容占用为20字节。
由于Jemalloc内存管理器的特性,当StringObject占用在64字节内时,使用的是一个内存管理单元,没有内存寻址的消耗,符合局部跳转原理,就可以将占用一个内存单元的StringObject认为是一个小字符串,故设置为EMBSTR编码。
即EMBSTR编码,需要字符串的内容占据64 - 20 = 44个字节。
回答面试官可以从Redis3.2版本开始,RedisObject占用字节数量,SDS结构占用字节数量,Jemalloc内存管理器,内存单元大小,内存寻址消耗方面去回答。
5.6为什么EMBSTR曾经的阈值是39吗?
与上面的问题相似,都是要从StringObject的组成结构RedisObject,SDS占用的非内容字节数量,Jemalloc内存管理器,内存单元大小,内存寻址消耗方面去回答。
这里相对于44字节的改动,是因为Redis3.2版本中SDS结构发生了变化导致的。
Redis3.2版本之前采用的SDS结构体是通用的,没有那么多的区分:
struct sdshdr {
unsigned int len;
unsigned int free;
char buf[];
};后来为了节约内存,便将通用SDS结构拆分为SDS8,SDS16,SDS32,SDS64等,例如SDS8相对于通用SDS结构节约了6个字节,但是由于增加了占用一个字节的flag,故SDS8结构比通用SDS结构,节约了5个字节,所以曾经的阈值是44 - 5 = 39个字节。
要点:把握住Redis3.2版本开始SDS结构内存占用减少了5字节,即曾经的内容字节要比现在少存储5字节。
5.7SDS有什么作用
SDS结构的出现就是为了取代C语言原始的String结构的。
SDS结构解决了C语言String结构的三大问题:1.求字符串长度时间复杂度为O(N)。2.字符串追增数据时需要数组扩容。3.字符串以‘\0’结尾,二进制不安全。
1.SDS结构使用len字段,将长度求解降低至O(1)
2.SDS使用冗余设计,开辟了冗余空间,不必每次都扩容数组。
3.SDS的char数组不以'\0'结尾,可以保证二进制安全。

















 2211
2211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









