







# 导包
import pandas as pd
import numpy as np
from pandas import Series, DataFrame内容:
·处理?
·duplicated
【处理】
原始数据最基本的操作,一定包括如下三步:
(1)空值的处理
(2)重复值的处理
(3)异常值的处理
# (1)空值的处理
# (2)重复值的处理
# (3)异常值的处理
df = DataFrame(
data={
"name": ["lom", "kom", "jom", "hom", "gom", "fom", "dom"],
"python": np.random.randint(0, 100, size=7),
"java": np.random.randint(0, 100, size=7),
"php": np.random.randint(0, 100, size=7)
}
)
print()设置重复元素:
# 设置重复值数据,第0行=第4行=第7行
df.loc[7] = df.loc[0].copy()
df.loc[4] = df.loc[0].copy()
print(df)
print()运行结果:

【duplicated】
(原理)
函数中并不存在axis参数,意味着重复值只会在行内查找
(参数)
(无参数)
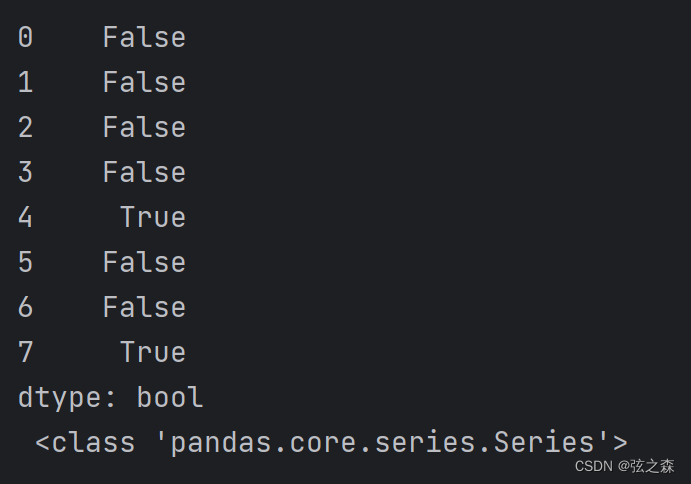
bool_things = df.duplicated()
print(bool_things, "\n", type(bool_things))
print()运行结果:
(keep参数)
drop_duplicates:删除多余行
keep="first"/"last"
keep="保留第一次的出现的重复行"/"保留最后一次出现的重复行"
# 删除重复行
# keep="last"保留重复行的最后一行,删除其他行
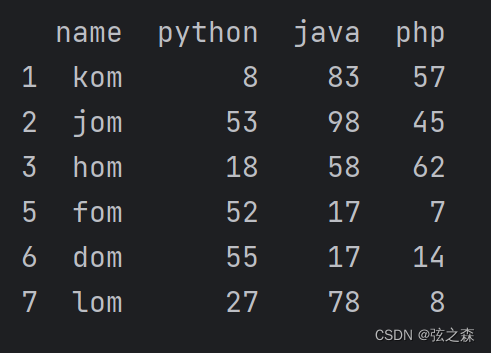
return_things = df.drop_duplicates(keep="last")
print(return_things)
print()运行结果:
(subset参数)
根据传入的参数,筛选出相同的行
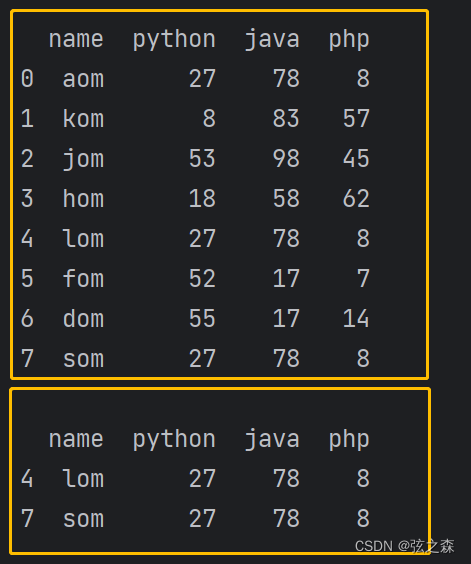
df.loc[7, "name"] = "som"
df.loc[0, "name"] = "aom"
print(df)
print()
print(df.loc[df.duplicated(subset=["python", "java", "php"])])运行结果:















 1313
1313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











