







文章目录
- 1. 整数在内存中的存储
- 2. ⼤⼩端字节序和字节序判断
- 3. 浮点数在内存中的存储
- 总结
1. 整数在内存中的存储
整数的2进制表⽰⽅法有三种,即原码、反码和补码
三种表⽰⽅法均有符号位和数值位两部分,符号位都是⽤0表⽰“正”,⽤1表⽰“负”,⽽数值位最
⾼位的⼀位是被当做符号位,剩余的都是数值位。
正整数的原、反、补码都相同。
负整数的三种表示方法各不相同。
- 原码:直接将数值按照正负数的形式翻译成⼆进制得到的就是原码。
- 反码:将原码的符号位不变,其他位依次按位取反就可以得到反码。
- 补码:反码+1就得到补码。
以10和-10为例,假设都在X86环境下即32bit位:
10的三种2进制表示:
原码:00000000 00000000 00000000 00001010
反码:00000000 00000000 00000000 00001010
补码:00000000 00000000 00000000 00001010-10的三种2进制表示:
原码:10000000 00000000 00000000 00001010
反码:11111111 11111111 11111111 11110101
补码:11111111 11111111 11111111 11110110对于整形来说:数据存放内存中其实存放的是补码。为什么呢?
在计算机系统中,数值⼀律⽤补码来表⽰和存储。
原因在于,使⽤补码,可以将符号位和数值域统⼀处理;同时,加法和减法也可以统⼀处理(CPU只有加法器)此外,补码与原码相互转换,其运算过程是相同的,不需要额外的硬件电路。
2.大小端字节序和字节序判断
当我们了解整数在内存中的存储后,可以调试以下代码
#include <stdio.h>
int main()
{
int a = 0x11223344;
return 0;
} 调试之后,我们可以看到在a中的 0x11223344 这个数字是按照字节为单位,倒着存储的。这是为
什么呢?

2.1 什么是大小端?
其实超过⼀个字节的数据在内存中存储的时候,就有存储顺序的问题,按照不同的存储顺序,我们分为⼤端字节序存储和⼩端字节序存储,下⾯是具体的概念:
-
⼤端(存储)模式:是指数据的低位字节内容保存在内存的⾼地址处,⽽数据的⾼位字节内容,保存在内存的低地址处。
-
⼩端(存储)模式:是指数据的低位字节内容保存在内存的低地址处,⽽数据的⾼位字节内容,保存在内存的⾼地址处。上述概念需要记住,⽅便分辨⼤⼩端。
2.2 为什么有大小端?
这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着⼀个字节,⼀个字节为8bit位,但是在C语⾔中除了8bit的 char 之外,还有16bit的 short 型,32bit的 long 型(要看具体的编译器),另外,对于位数⼤于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度⼤于⼀个字节,那么必然存在着⼀个如何将多个字节安排的问题。因此就导致了⼤端存储模式和⼩端存储模式。
例如:⼀个 16bit 的 short 型 x ,在内存中的地址为, x 的值为 0x1122 ,那么0x11 为⾼字节, 0x22 为低字节。对于⼤端模式,就将 0x11 放在低地址中,即 0x0010 中,0x22 放在⾼地址中,即 0x0011 中。⼩端模式,刚好相反。我们常⽤的 X86 结构是⼩端模式,⽽KEIL C51 则为⼤端模式。很多的ARM,DSP都为⼩端模式。有些ARM处理器还可以由硬件来选择是⼤端模式还是⼩端模式。
大端下的0x1122排列情况:
地址:0x0010 0x0011 (低->高)
数值: 0x11 0x22
小端下的0x1122排列情况:
地址:0x0010 0x0011 (低->高)
数值: 0x22 0x11 2.3 练习
以下是对之前知识点的练习,可以自己先做,后运行一下代码,尝试理解
2.3.1 练习1
请简述⼤端字节序和⼩端字节序的概念,设计⼀个⼩程序来判断当前机器的字节序。(10分)-百度笔试题

2.3.2 练习2

2.3.3 练习3

2.3.4 练习4

2.3.5 练习5

2.3.6 练习解析
- 练习1是利用大小端中在低地址处,存放的高低字节数的不同。1的16进制序列就是0x00 00 00 01,其中第一个0x00是高字节数,0x01是低字节数,在小端中,低地址存放的是0x01,而在大端中存放的是0x00。check_sys函数中返回首相将&i强制转换成char类型指针,之后再进行解引用(*),就得到了i第一个字节的数。此时再来判断是0还是1。
- 分析这道练习题前,我们需要知道字符类型其实也是整型家族里的一员。因为字符实际上存储的是ASCII码值,是个整型,只不过通过ASCII码表转换成了相应的字符。所以,字符可分为char、signed char和unsigned char这三种形式。字符在内存中仅占一个字节(8个bit位)。-1写成二级制序列:10000001。
- char类型字符,以整型形式打印的话,要先把该数值从原码转换成补码,然后再发生整型提升,此时这个二进制序列是要打印的补码,还需进一步转换成原码。
- 那什么是整型提升呢?整型提升就是把字节数较小的数据转换成字节数较大的数据。若是有符号数,以第一位符号位的数来填充前面数据bit位的空缺,例如:某个数的反码是10000001,整型提升后二进制序列为11111111 11111111 11111111 10000001,若第一位是0,则前面的bit位全部填0。若是无符号数,直接前面缺失的bit位全部填0。
将后面的练习题放在一起来看
-1字符二进制序列,先要以32位bit位(整型形式在X86环境下)写出它的原码、反码和补码
原码:10000000 00000000 00000000 00000001
反码:11111111 11111111 11111111 11111110
补码:11111111 11111111 11111111 11111111
此时要进行截断,将前三个字节内容舍去
则-1char类型下二进制序列位1111 1111
(补充:三种码转换时,符号位不变)
内存中处理的是补码(前面有提到),所以用-1的补码发生整型提升
char和signed char都是有符号数,以第一位符号位来填充前面的bit位
补码:11111111 11111111 11111111 11111111
反码:11111111 11111111 11111111 11111110
原码:10000000 00000000 00000000 00000001
最后打印的数值是原码,该原码就是-1。
unsigned char是无符号数,前面bit位全面填0
补码:00000000 00000000 00000000 11111111
反码:01111111 11111111 11111111 00000000
原码:01111111 11111111 11111111 11111111
打印原码,即2553.分析练习3前,我们要了解signed char和unsigned char这两种数值类型大小范围:
signed char为有符号数,第一个bit位是符号位,来判断正负,计算数值大小时,
可以忽略。放在内存的数值都是补码,所以我们以补码来分析。
这是正数,所以原码,反码和补码相同,直接计算数值大小即可
0000 0000 —— 0
0000 0001 —— 1
0000 0002 —— 2
…… ……
0111 1110 —— 126
0111 1111 —— 127
接下来时符号位为1的数,是负数,因此要把补码转换成原码。
1000 0000 —— -128
1000 0001 —— -127
1000 0002 —— -126
…… ……
1111 1101 —— -3
1111 1110 —— -2
1111 1111 —— -1
此时你应该从下往上看,1111 1111这个补码先取反再加1,得到1000 0001,
是-1,以此类推-2,-3 …… -126,-127. 但是1000 0000这个数按位取反为
1111 1111,再加1,就又变成1000 000,所以这个值就被规定为-128的补码。
如果换成unsigned char类型的话,就比较简单了,因为此时没有符号位,原反补码都相同,
直接将二进制转换成十进制计算
0000 0000 —— 0
0000 0001 —— 1
0000 0002 —— 2
…… ……
0111 1110 —— 126
0111 1111 —— 127
1000 0000 —— 128
1000 0001 —— 129
1000 0002 —— 130
…… ……
1111 1101 —— 253
1111 1110 —— 254
1111 1111 —— 255
所以signed char类型范围大小是-128~127,unsigned char类型范围大小是0~255.
- 练习3:当你了解了两种char类型大小的范围,就知道了这两个数值在内存中对应的补码。再来看这道题,打印的是%u,就是打印无符号数,所以第一个bit位是1时,不用进行原反补码的转换,因为此时被当作正数,原反补码相同,所以打印出很大的数。
- 练习4:通过char类型大小范围可知,-1的补码是1111 1111,而数组从第一个元素开始存放-1,之后每次减去1,以此类推,当i = 255时,补码为0000 0000。而0000 0000代表的是空字符,也是‘\0'。strlen函数计算字符个数,是以’\0'作为结尾并且只算‘\0'前面字符的个数,所以i从0~254,共有255个字符。
- 练习5第一段代码中定义了个unsigned char字符,无符号数,范围在0~255之间,当i = 255时,在内存中的补码是1111 1111,再加一变成1 0000 0000,但是字符只有一个字节,8个bit位,所以在内存看来i = 256时,i为0,以此类推,无限循环下去。
- 练习5第二段代码同理,当i = 0时,再减去1,变成-1。-1先以二进制整形形式写出,在进行截断和整型提升,这里的步骤跟练习2类似。因为是打印%u无符号数就会变成一个很大的数。并且会进入死循环,因为unsigned int最小值为0。
总结一下,char类型数值,先转换成整型类型的补码,不过正数原反补码相同,负数则要按规则转换,之后进行整型截断,之后进行根据有符号或无符号char整型提升,再根据打印的是%d还是%u类型,决定是否在进行原反补码的转换。这几个练习十分经典,内容较多,比较繁琐,所以需沉下心来好好消化。(写的时候我都给绕晕了)
3.浮点数在内存中的存储
3.1 练习

可以尝试编写上面的代码,并分析,再运行。那答案是什么?

3.2 浮点数存储
上⾯的代码中,num 和 *pFloat 在内存中明明是同⼀个数,为什么浮点数和整数的解读结果会差别这么⼤要理解这个结果,⼀定要搞懂浮点数在计算机内部的表⽰⽅法。
根据国际标准IEEE(电⽓和电⼦⼯程协会)754,任意⼀个⼆进制浮点数V可以表⽰成下⾯的形式:
V = (−1)^S ∗ M ∗ 2^E (^表示次方)
• S 表⽰符号位,当S=0,V为正数;当S=1,V为负数 (−1) S
• M 表⽰有效数字,M是⼤于等于1,⼩于2的
• E 表⽰指数位
举例来说:
-
十进制5.0,改写成二进制为101.0,即是1.01 * 2^2
-
类比十进制10000可以改写成1 * 10^4
-
V = (-1)^0 * 1.01 * 2^2
-
S = 0, M = 1.01, E = 2
相反的十进制的-5.0,就是S = 1,其他不变。
IEEE754规定
对于32位的浮点数,最⾼的1位存储符号位S,接着的8位存储指数E,剩下的23位存储有效数字M?
对于64位的浮点数,最⾼的1位存储符号位S,接着的11位存储指数E,剩下的52位存储有效数字M

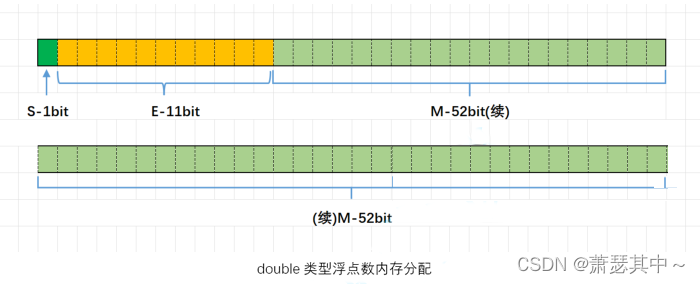
3.2.1 浮点数存储的过程
IEEE754对有效数字M和指数E,还有⼀些特别规定。
前⾯说过, 1≤M<2 ,也就是说,M可以写成 1.xxxxxx 的形式,其中 xxxxxx 表⽰⼩数部分。
IEEE754规定,在计算机内部保存M时,默认这个数的第⼀位总是1,因此可以被舍去,只保存后⾯的xxxxxx部分。⽐如保存1.01的时候,只保存01,等到读取的时候,再把第⼀位的1加上去。这样做的⽬的,是节省1位有效数字。以32位浮点数为例,留给M只有23位,将第⼀位的1舍去后,等于可以保存24位有效数字。
⾄于指数E,情况就⽐较复杂
⾸先,E为⼀个⽆符号整数(unsigned int)
这意味着,如果E为8位,它的取值范围为0~255;如果E为11位,它的取值范围为0~2047。但是,我们知道,科学计数法中的E是可以出现负数的,所以IEEE754规定,存⼊内存时E的真实值必须再加上⼀个中间数,对于8位的E,这个中间数是127;对于11位的E,这个中间数是1023。⽐如,2^10的E是10,所以保存成32位浮点数时,必须保存成10+127=137,即10001001。
3.2.2浮点数取出的过程
指数E从内存中取出还可以再分成三种情况:
- E不全为0或不全为1
这时,浮点数就采⽤下⾯的规则表⽰,即指数E的计算值减去127(或1023),得到真实值,再将有效数字M前加上第⼀位的1。
⽐如:0.5的⼆进制形式为0.1,由于规定正数部分必须为1,即将⼩数点右移1位,则1.0*2^(-1),其阶码为-1+127(中间值)=126,表⽰为01111110,⽽尾数1.0去掉整数部分为0,补⻬0到23位00000000000000000000000,则其⼆进制表⽰形式为:
0 01111110 00000000000000000000000- E全为0
这时,浮点数的指数E等于1-127(或者1-1023)即为真实值,有效数字M不再加上第⼀位的1,⽽是还原为0.xxxxxx的⼩数。这样做是为了表⽰±0,以及接近于0的很⼩的数字。
0 00000000 00100000000000000000000
- E全为1
这时,如果有效数字M全为0,表⽰±⽆穷⼤(正负取决于符号位s);
0 11111111 00010000000000000000000
3.3 题目解析
我们回顾刚开始的练习
int n = 9;
float *pFloat = (float *)&n;
printf("n的值为:%d\n",n);
printf("*pFloat的值为:%f\n",*pFloat);
这里将指向n的指针变量强制转换成float类型的指针变量,之后打印的结果是 0.000000,想要搞清楚为什么,要把9以整型的形式存储在内存的二进制序列写出来:
0000 0000 0000 0000 0000 0000 0000 1001
⾸先,将 9 的⼆进制序列按照浮点数的形式拆分,得到第⼀位符号位s=0,后⾯8位的指数
E=00000000 ,最后23位的有效数字M=000 0000 0000 0000 0000 1001。
由于指数E全为0,所以符合E为全0的情况。因此,浮点数V就写成:
V=(-1)^0 × 0.00000000000000000001001×2^(-126)=1.001×2^(-146)
显然,V是⼀个很⼩的接近于0的正数,所以⽤⼗进制⼩数表⽰就是0.000000。
int n = 9;
float *pFloat = (float *)&n;
*pFloat = 9.0;
printf("num的值为:%d\n",n);
printf("*pFloat的值为:%f\n",*pFloat);
再看下面的代码,*pFloat赋值为9.0。则此时n的值也修改为9.0,但是下面是以整型的方式打印n。我们把n写成浮点型规则下的表达式:
⾸先,浮点数9.0等于⼆进制的1001.0,即换算成科学计数法是:1.001×2^3
所以:9.0 = (−1) ^0 * (1.001) ∗ 2^3
那么,第⼀位的符号位S=0,有效数字M等于001后⾯再加20个0,凑满23位,指数E等于3+127=130,即10000010.所以,写成⼆进制形式,应该是S+E+M,即
0 10000010 001 0000 0000 0000 0000 0000这个32位的⼆进制数,被当做整数来解析的时候,就是整数在内存中的补码,原码正是1091567616 。
总结
数据的内存存储是C语言的重中之重,学好数据在内存中的存储,才可以在未来的C语言的学习中如鱼得水。内容较多,十分繁琐,需要耐心分析,理解消化。
创作不易,如果喜欢的话,请一定不要吝啬你手中的三连,你们的支持是我最大的动力!!!
















 3804
3804











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









