 自动化测试:操作测试对象的方法
自动化测试:操作测试对象的方法








目录
感谢各位大佬对我的支持,如果我的文章对你有用,欢迎点击以下链接
🐒🐒🐒 个人主页
😎😎😎 C语言
🐿️🐿️🐿️ C语言例题
🐓🐓🐓 数据结构C语言
🐔🐔🐔 C++
🐱👓🐱👓🐱👓 Linux
🐣🐣🐣 python
😎😎😎 软件测试
🏀🏀🏀 笔试练习题
🐱👤🐱👤🐱👤 秋招准备算法题
🐱🚀🐱🚀🐱🚀 高并发内存池项目
🚀🚀🚀 C++面试题
👍👍👍 Linux基础面试题
🐥🐥🐥 软件测试面试题
🐿️🐿️🐿️ 文章链接目录
操作测试对象
常⻅的操作有点击、提交、输⼊、清除、获取⽂本
click() 点击/提交对象
click()在之前有用到过
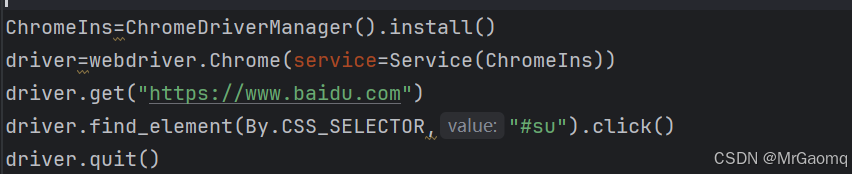
那我们能不能把他拆开呢,比如先找到指定的元素,然后再点击
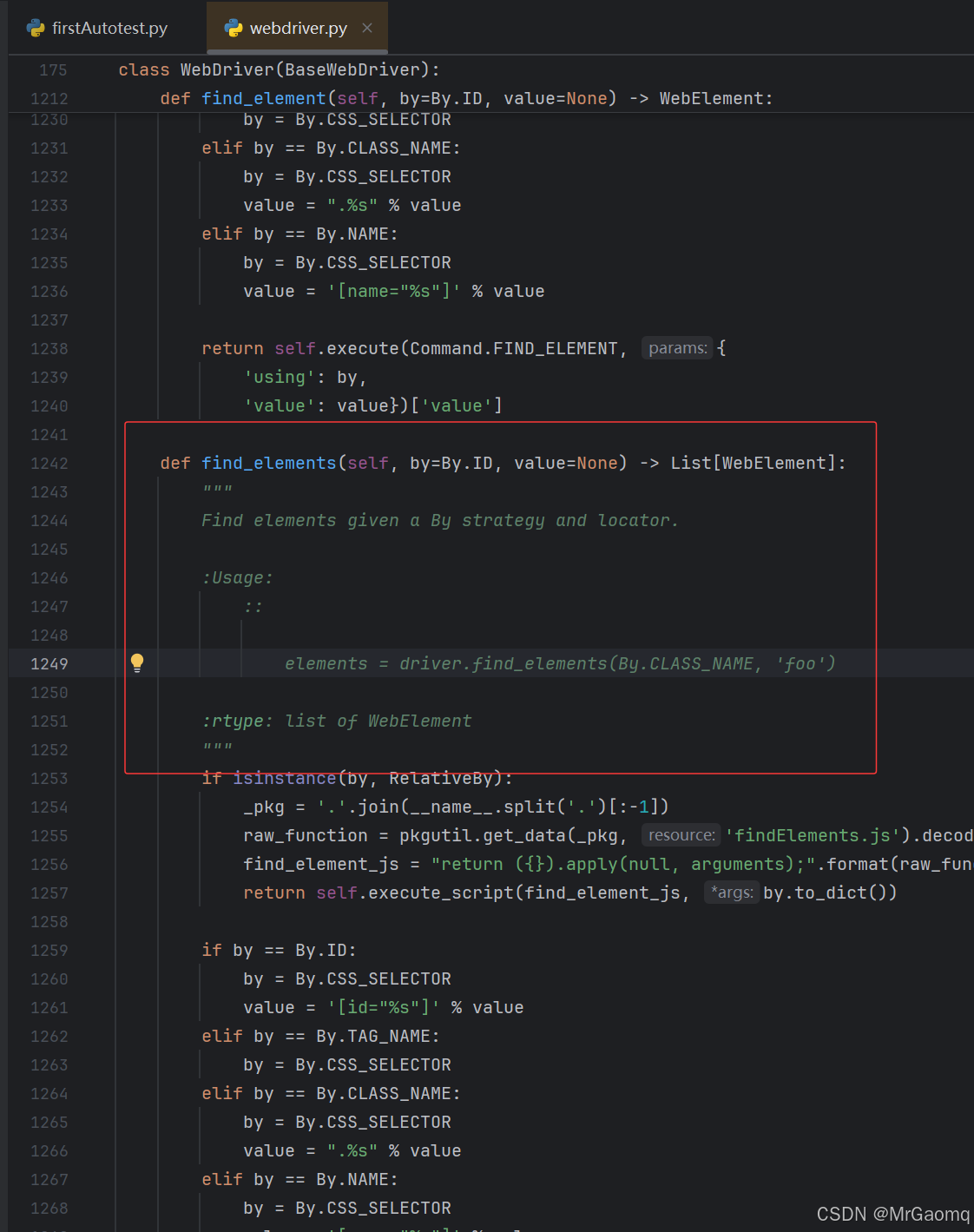
上图中rtype: list of WebElement的WebElement是find_elements的返回类型,这个类型是selenium自己定义的一个类型
我们只需要用ele来保存这个返回值即可
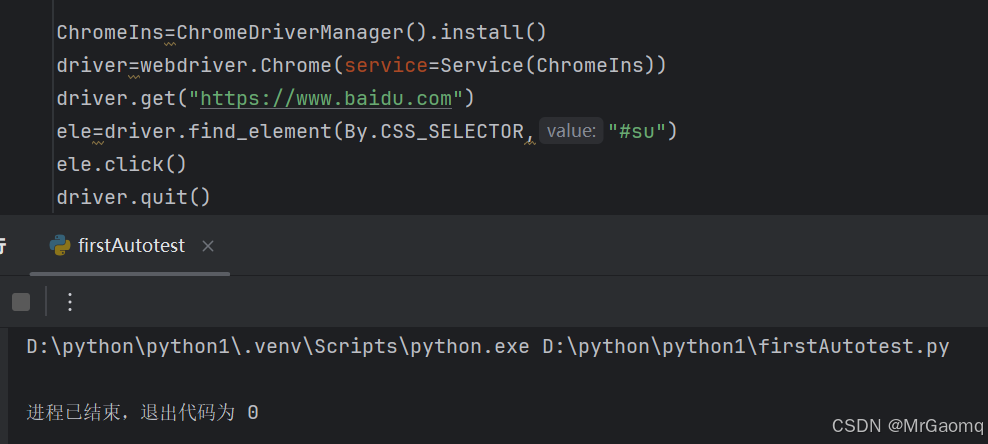
除了点击百度一下的按钮,我们还可以点击空白页 热搜等其他页面上的所有元素
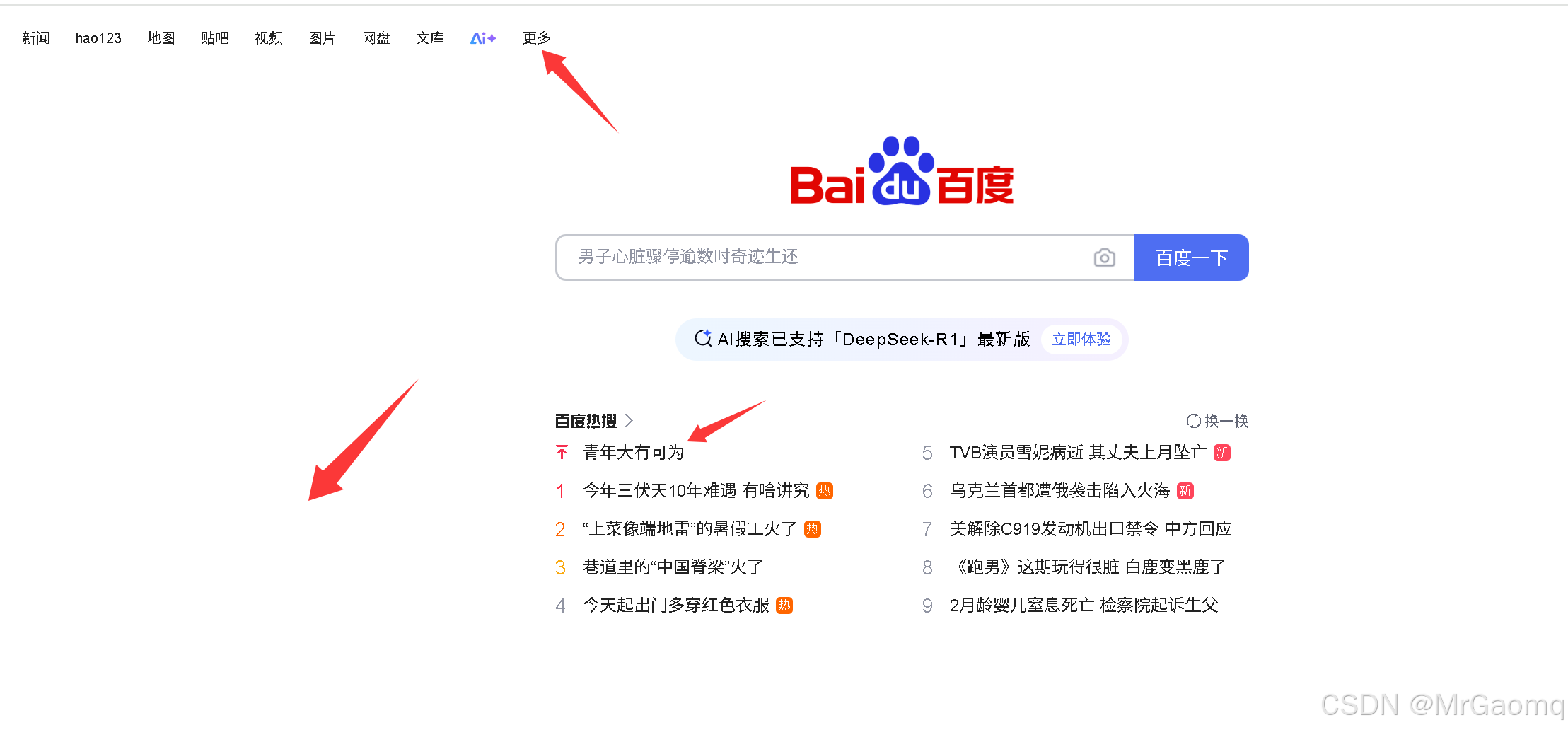
现在我们试一下点击热搜
先将热搜找到,然后选择Copy selector
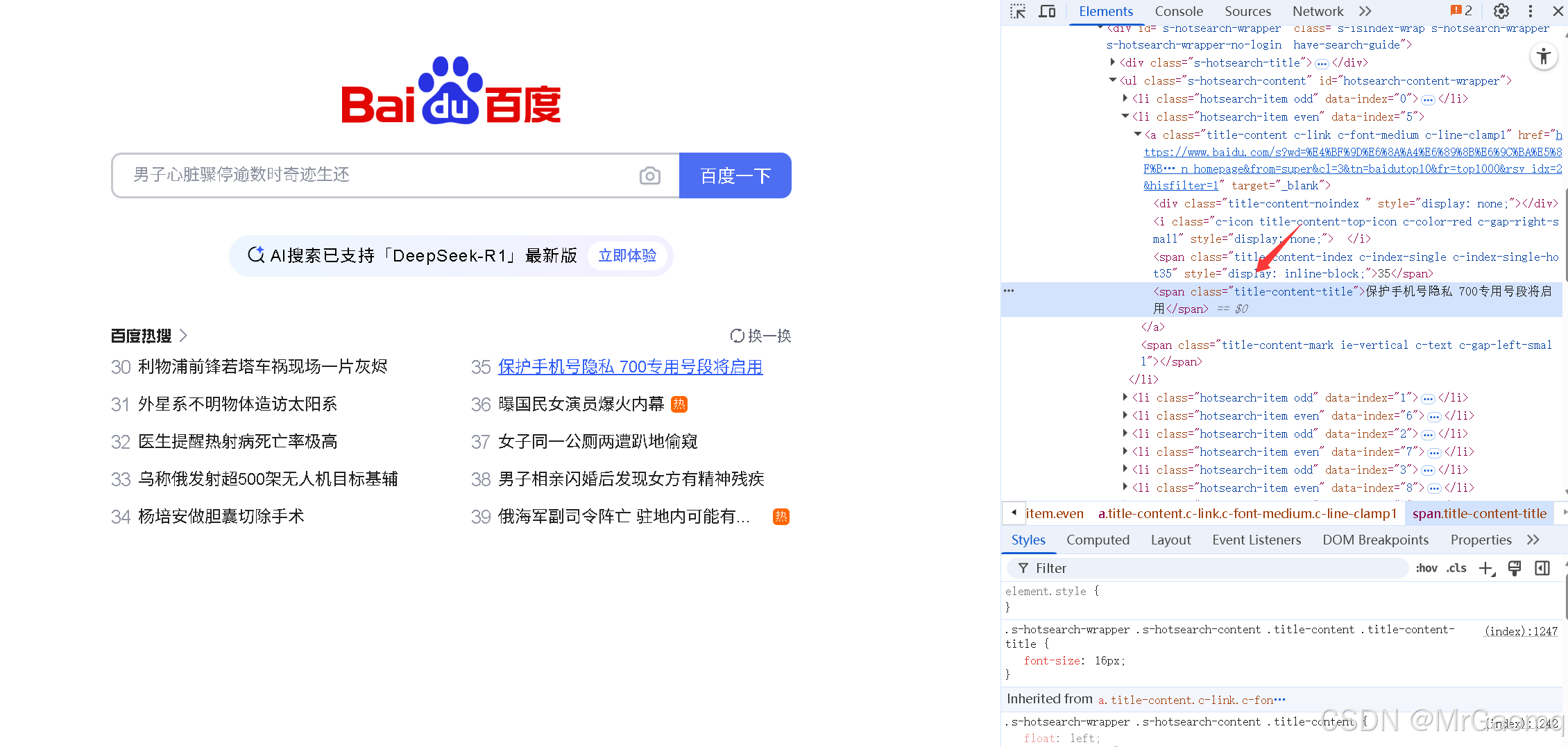
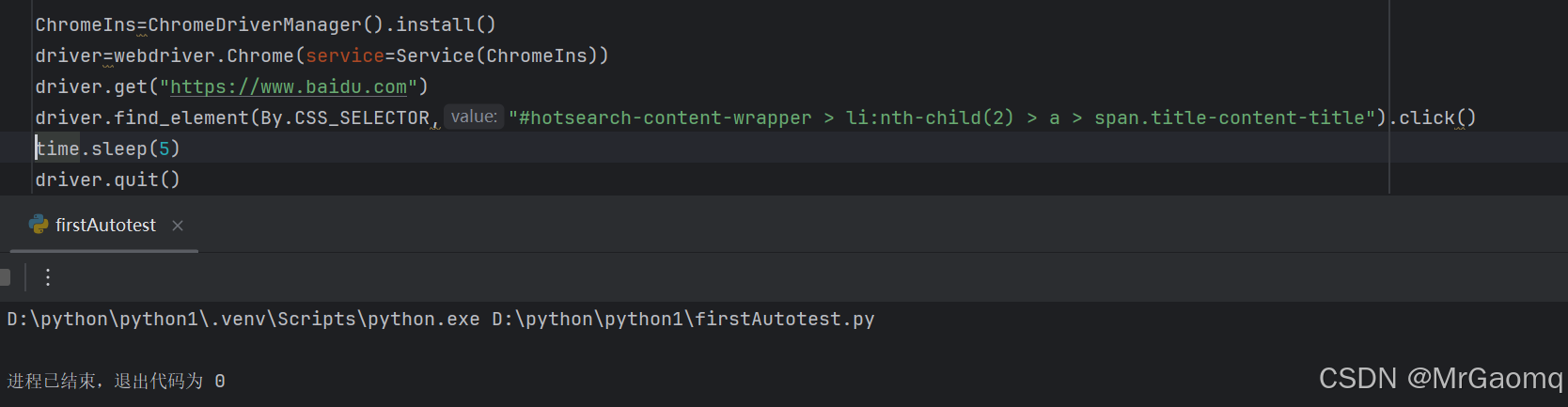
将复制的内容粘贴到find_element里,为了方便看到点击后的内容,我们休眠5s

send_keys(" ")模拟按键输入
因为要模拟按键输入,所有要先找到百度网页上的输入框
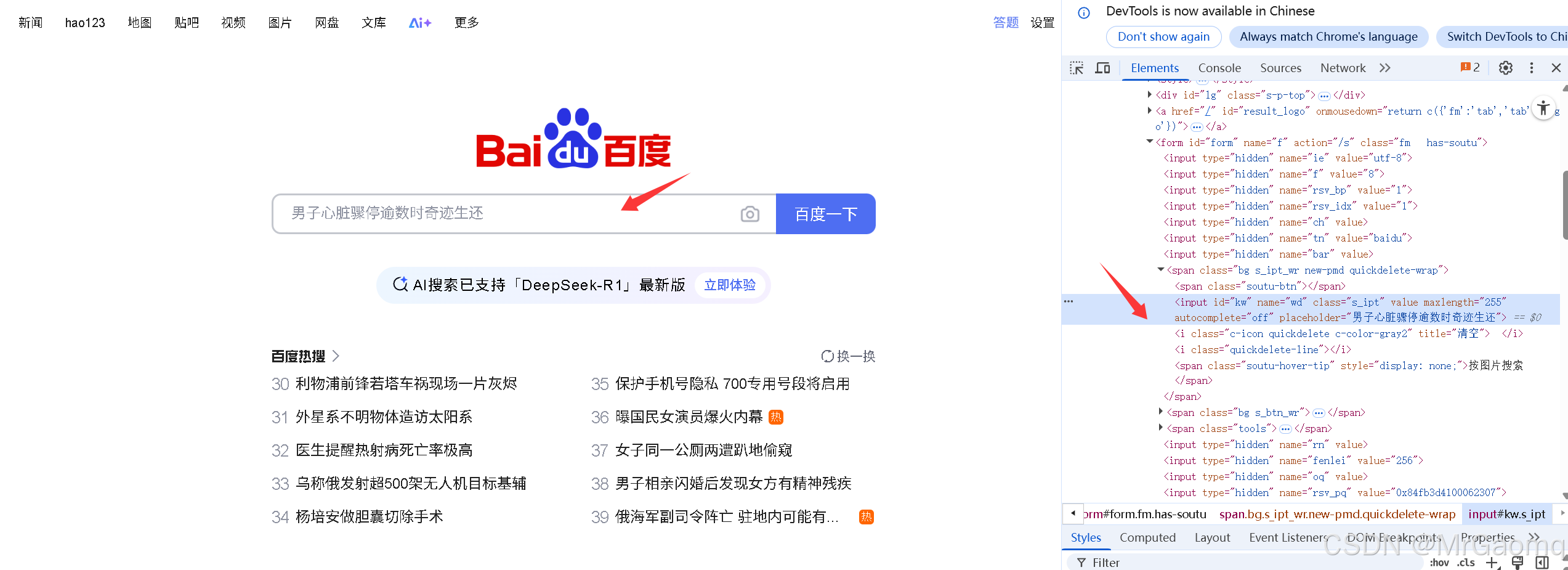
和之前一样选择Copy selector,将复制的内容粘贴套find_element里,不同的是我们这次用的是模拟按键输入,所有之前的click变成了sned_keys
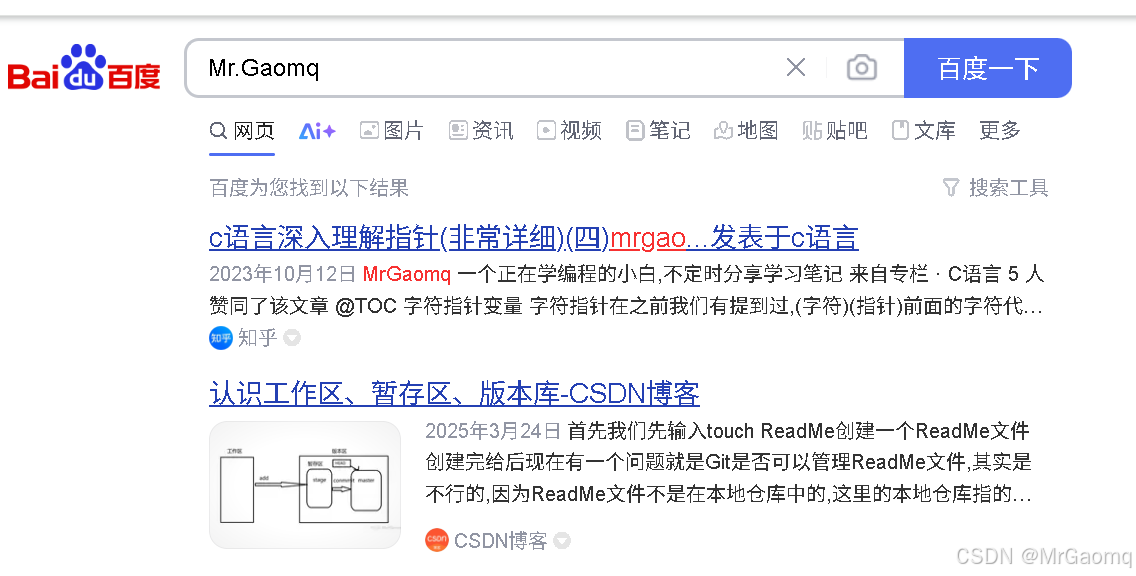
这里我搜一下我的博客名
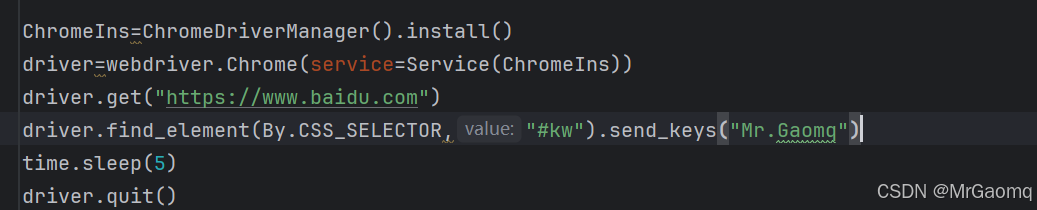
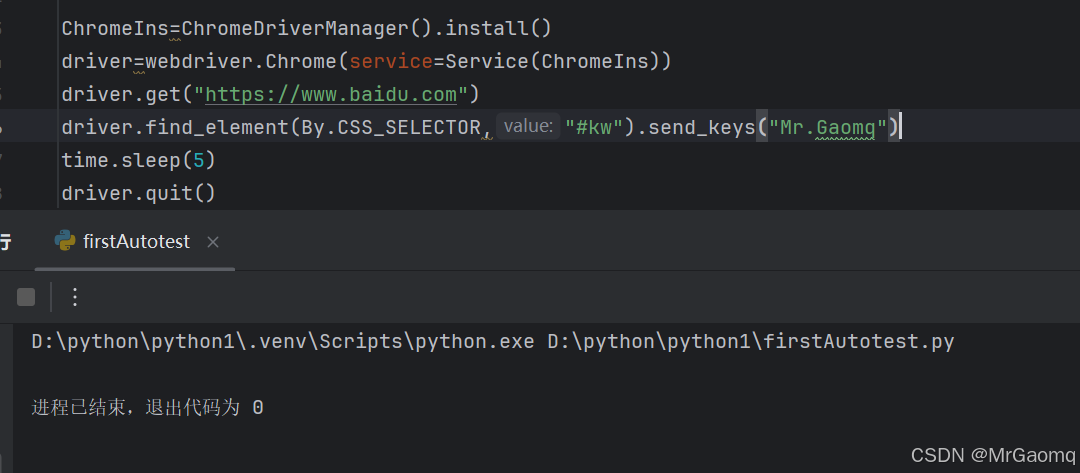
虽然是输入了,但是没有点击百度一下,于是我后面又加了click
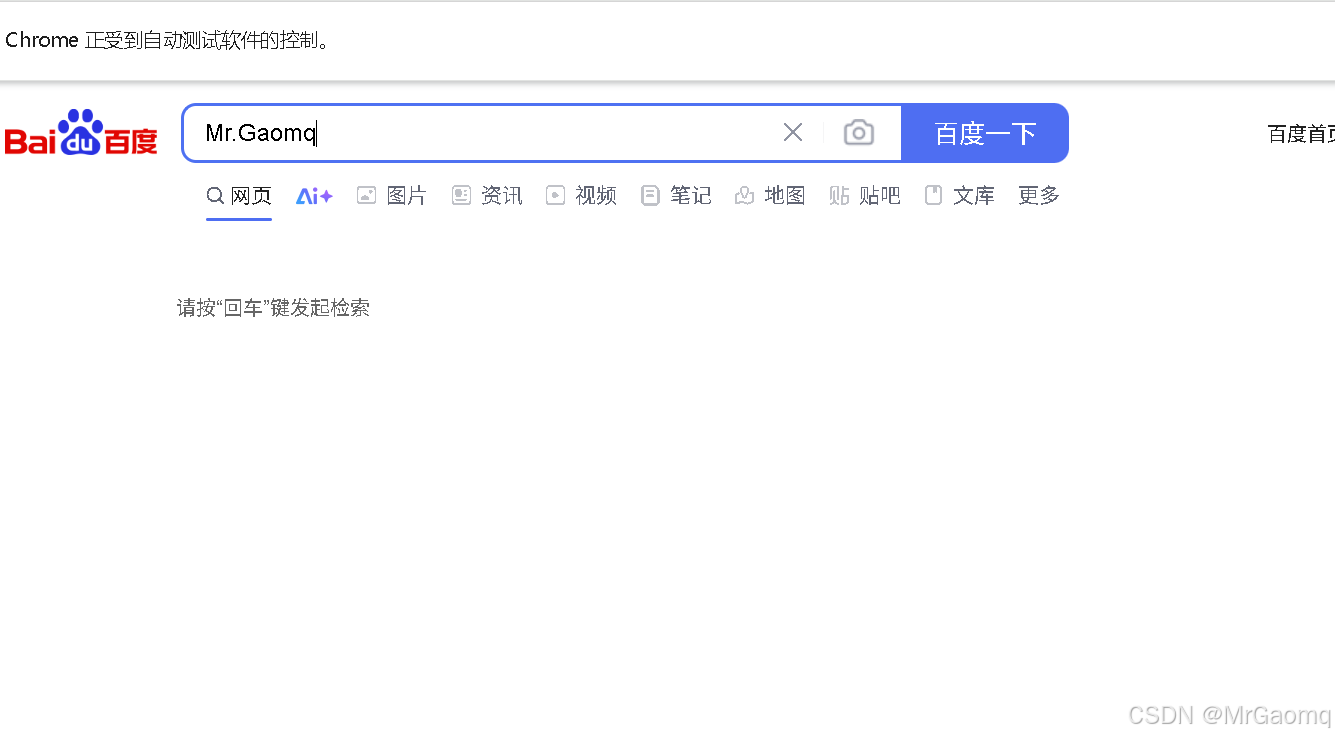
我试了下.click在send_keys后面接不了
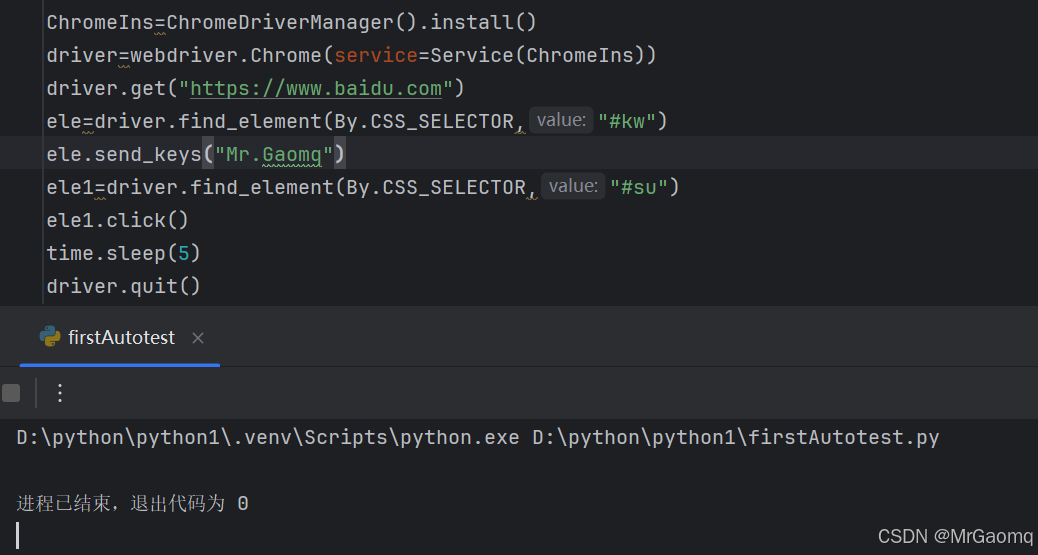
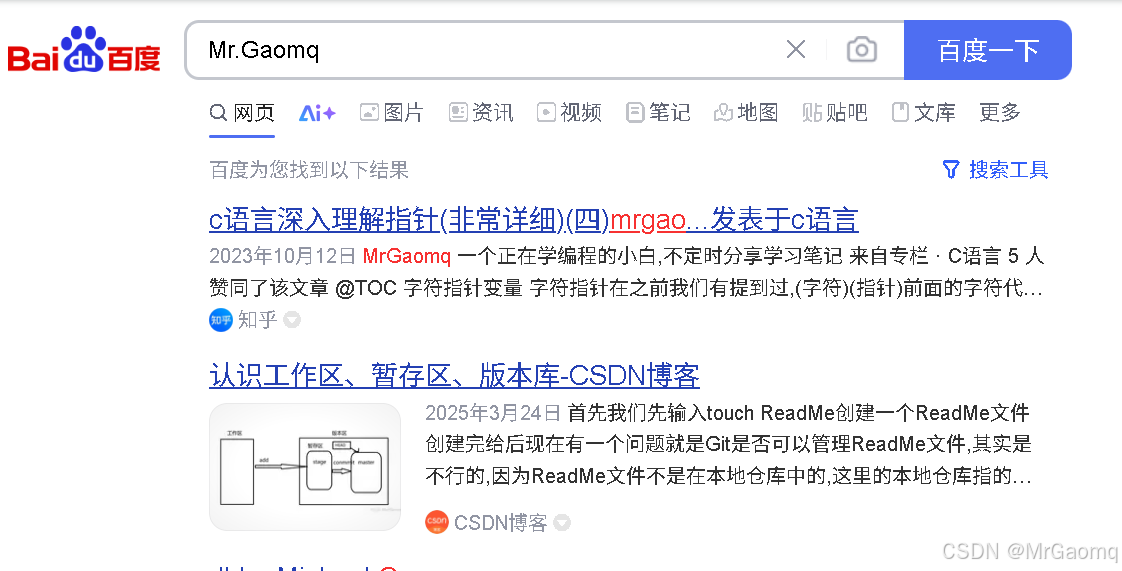
clear()清除文本内容
send_keys可以分段输入
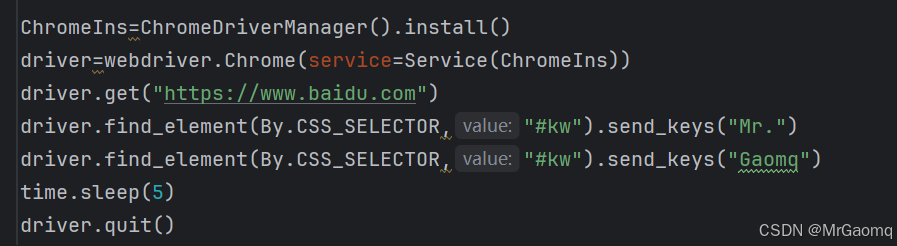
运行后先输入Mr.
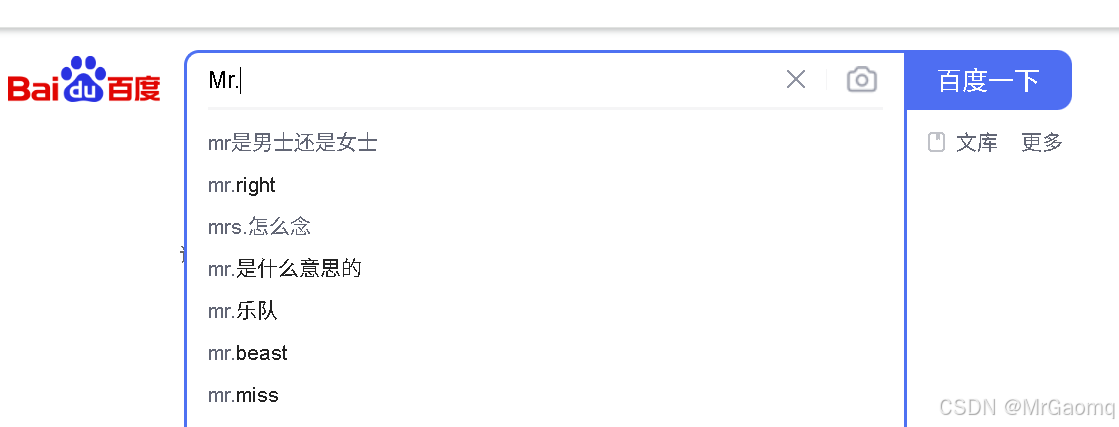
然后再输入Gaomq,可以看出分段输入不会将前面覆盖,而是在后面继续输入
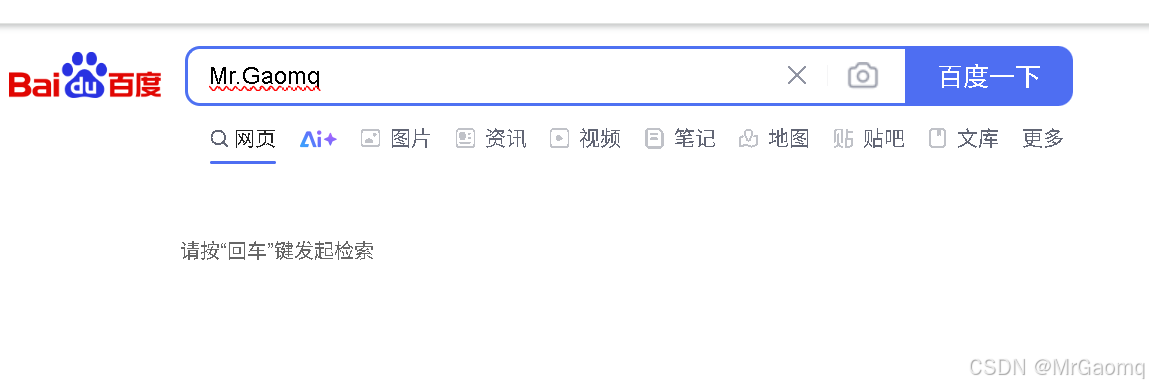
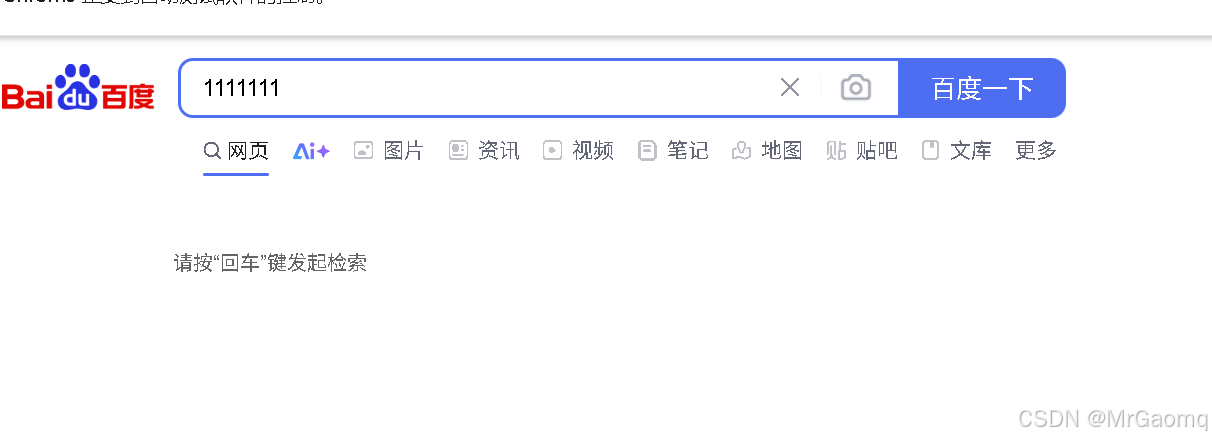
那此时我们用clear()将输入的部分信息清楚,然后再输入呢
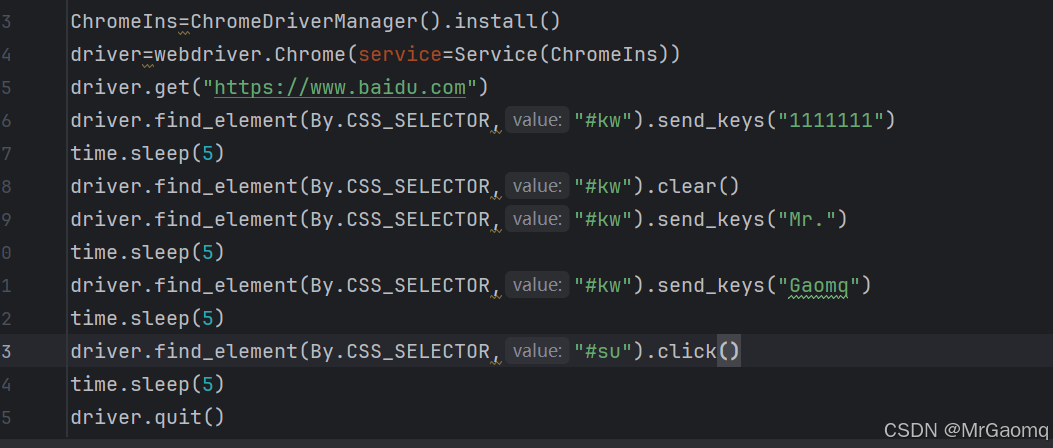
后面正如我们所想的一样,先输入1111111,然后清除,再分段输入Mr. 和Gaomq
text 获取文本信息
在浏览器页面中有非常多的文字信息
有时候在做web自动化测试时想要看页面展示的文本信息是不是我们想要的
比如输入框搜索按钮是百度一下,我想要看名字会不会有问题,比如百度两下 百度三下等等
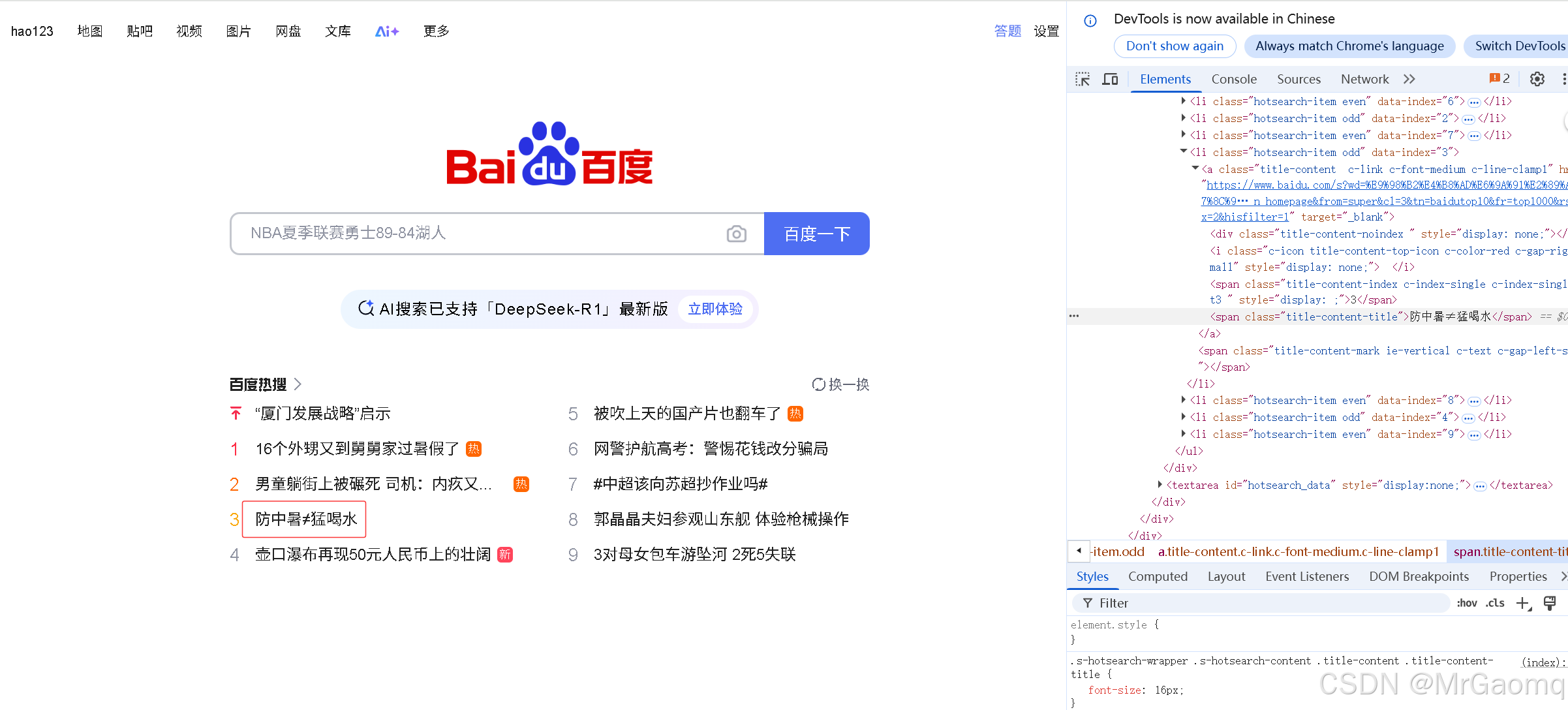
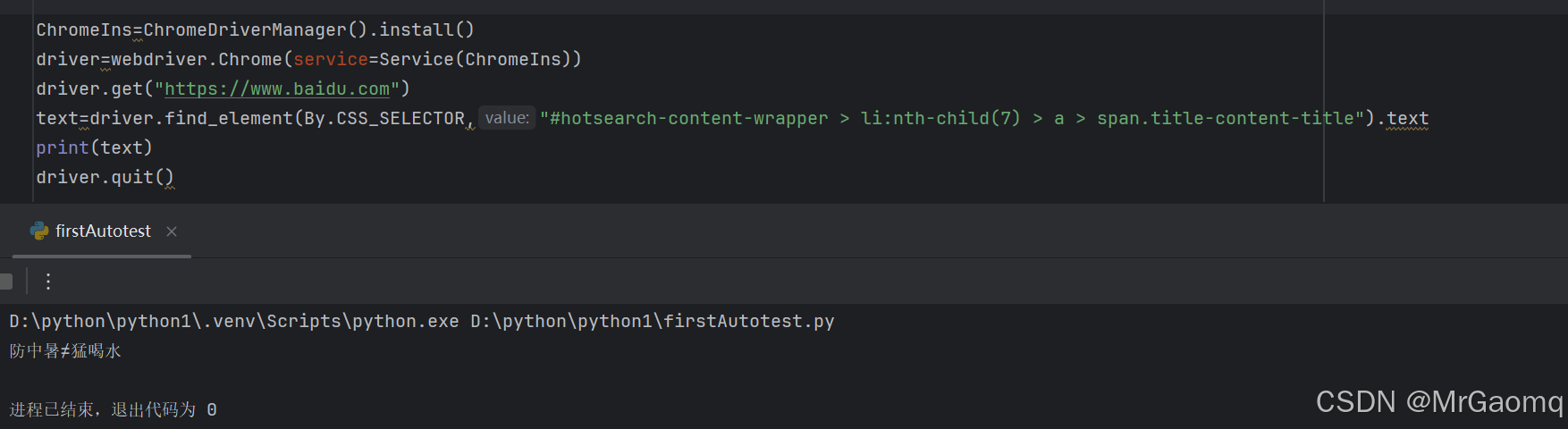
现在我将其中一条热搜的文本信息打印出来,我们先要用Copy selector复制这条热搜的信息
将复制的信息粘贴到find_element里面

需要注意的是text是由返回值的,所以我们用text来接受这个返回值

后面用print来打印这个返回值

最后输出的结果确实是正确的,只不过我有个疑问为什么有时候我运行代码会运行好几分钟
另外我们可以通过使用断言来判断我们查找的文本内容是否是我们想要的
这里我将!=改为=,所以最后出错了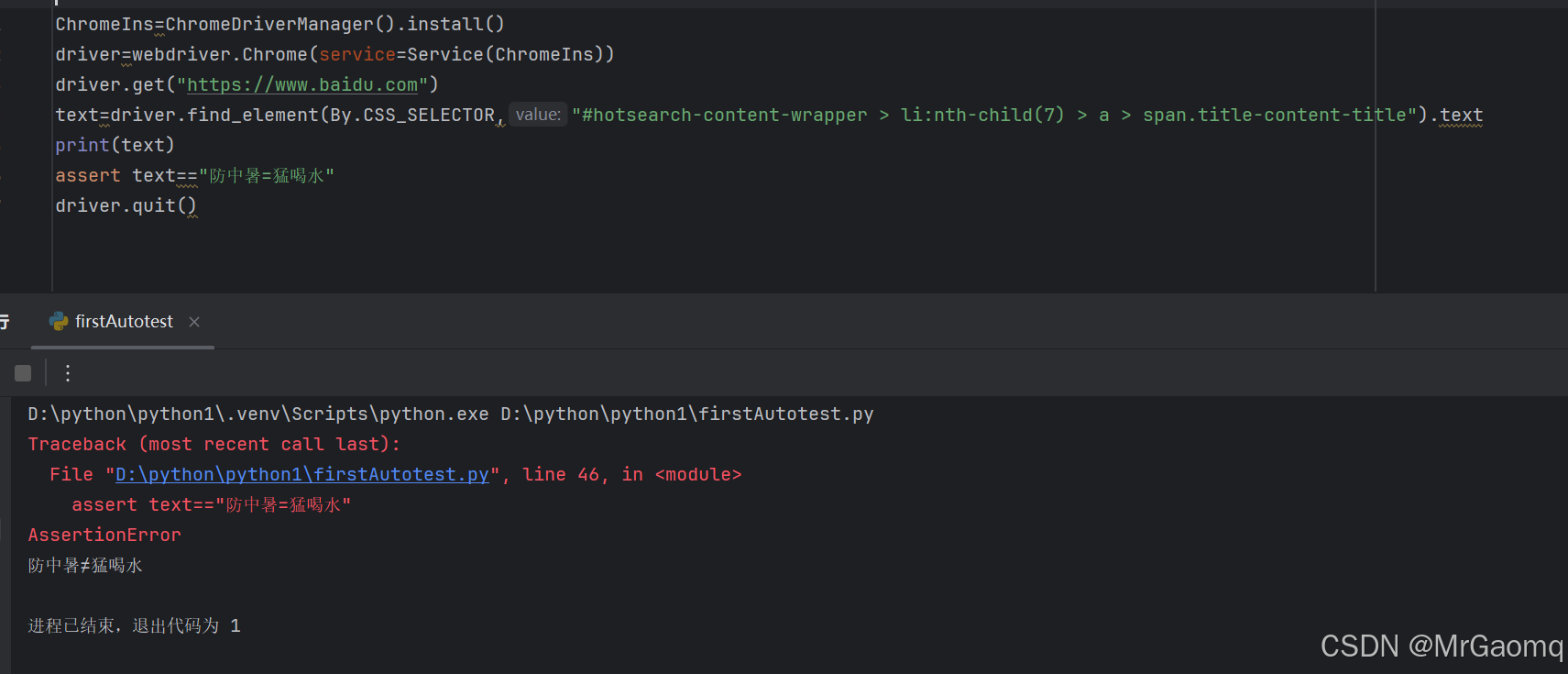
现在想要获取百度一下这个按钮的文本
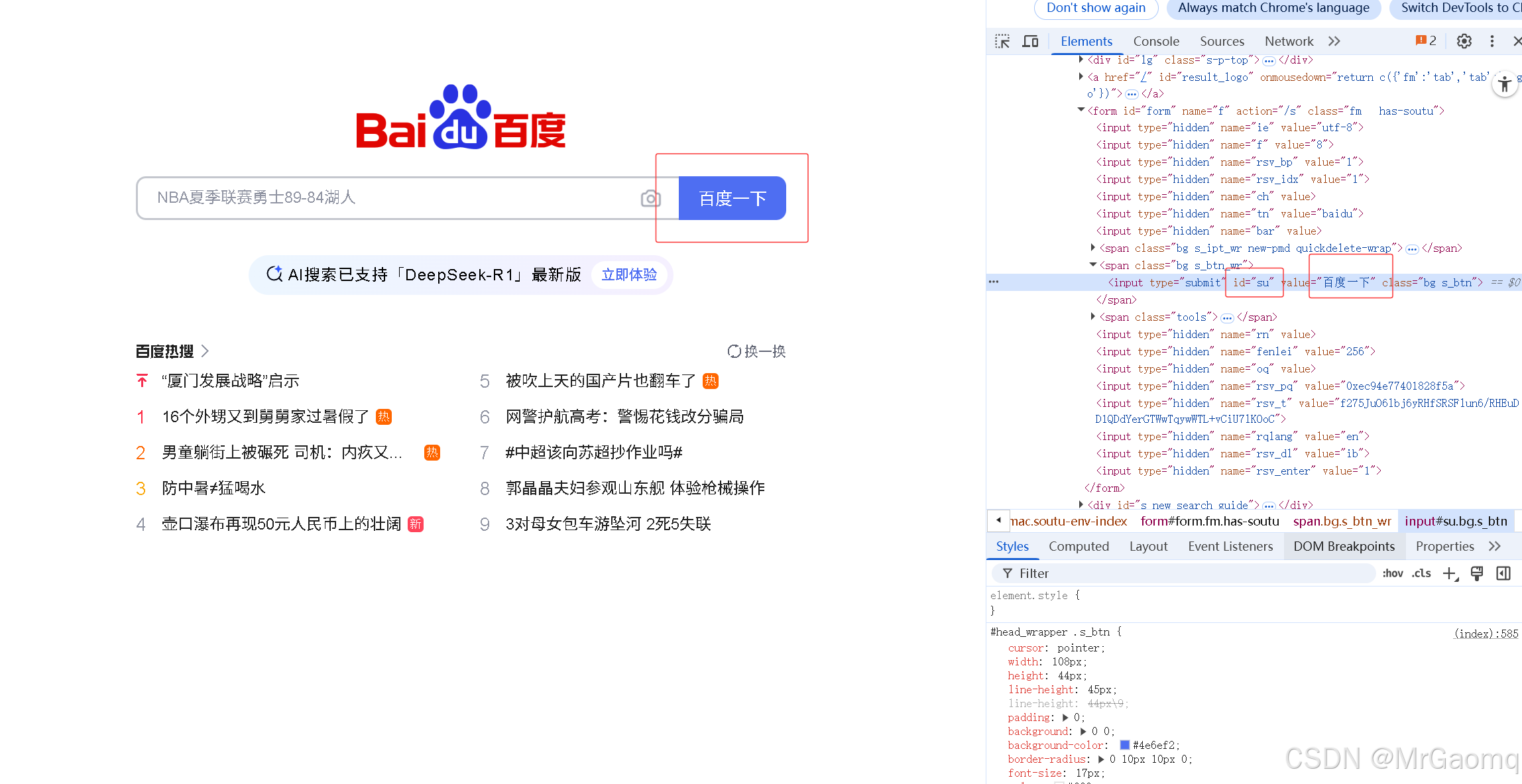
还是按之前的操作
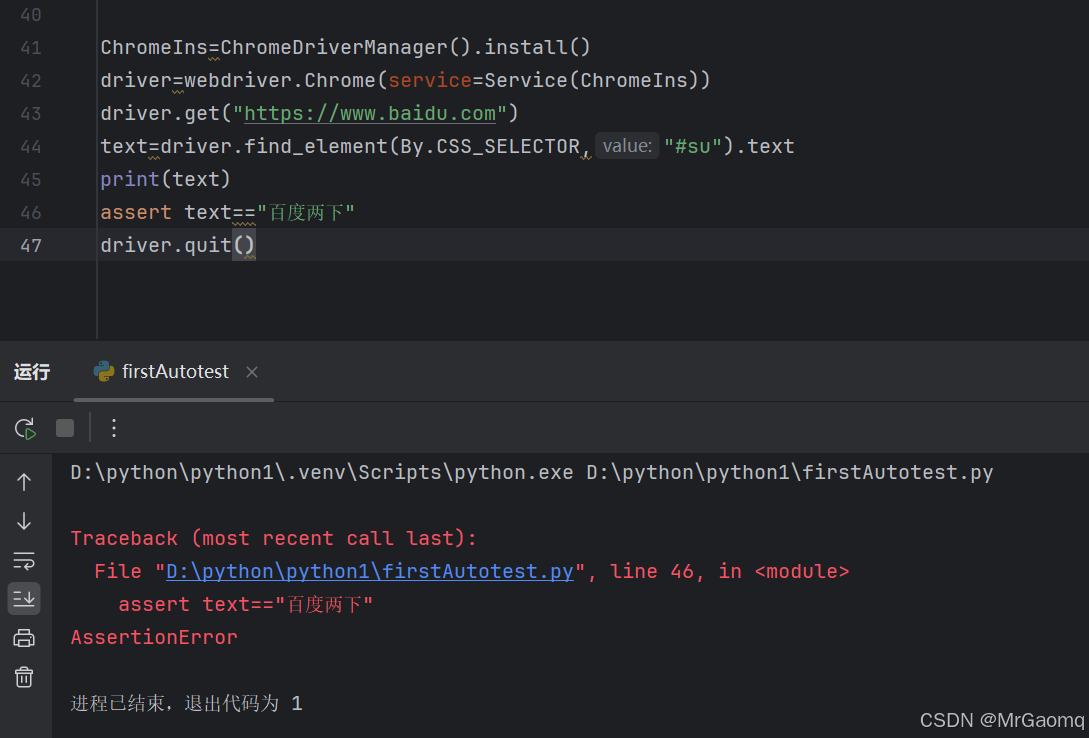
断言百度两下时确实会报错,但是改为百度一下居然还是报错
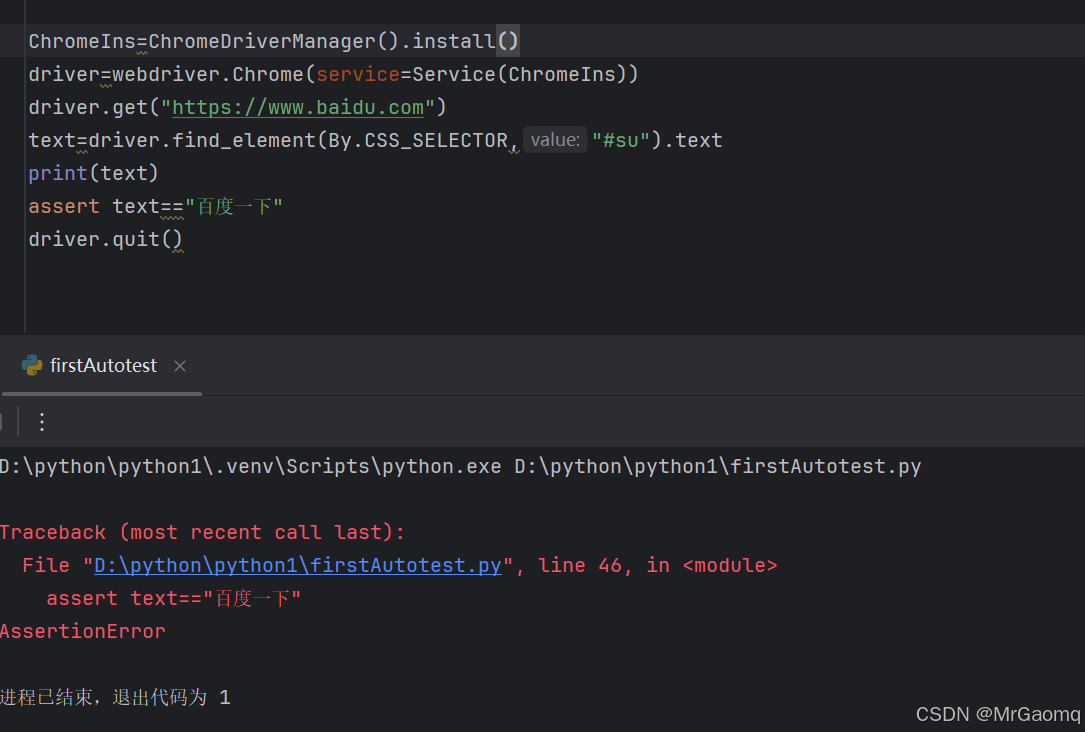
这个按钮的信息确实是百度一下
如果不是百度一下那又会是什么,我们把断言屏蔽下,最后发现什么都没有打印
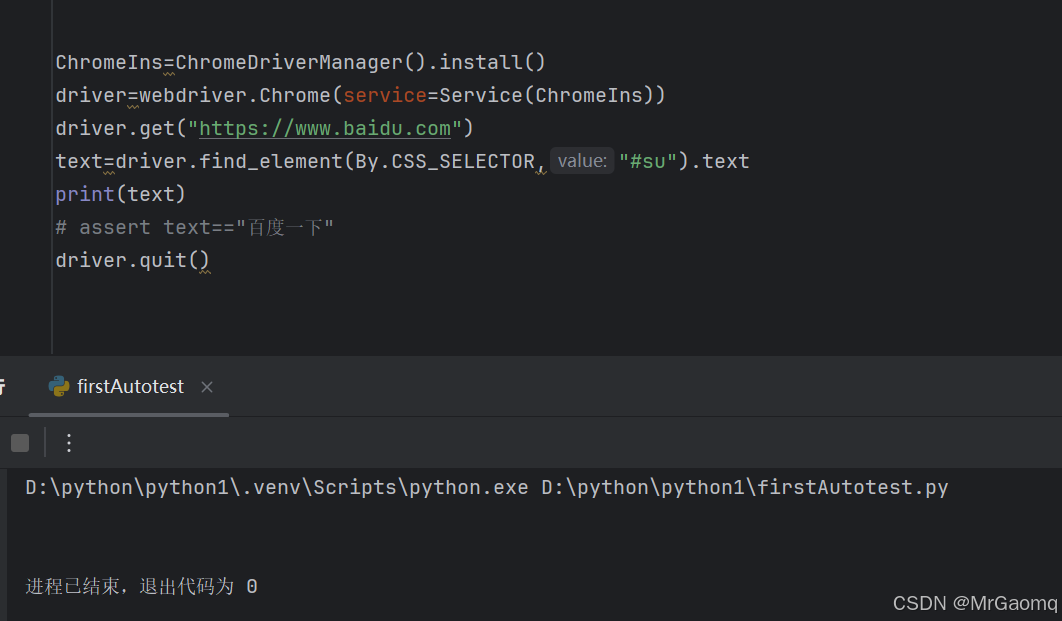
这说明text为空没有打印任何文本信息,这是因为在特殊情况时,元素的属性值不等于文本信息
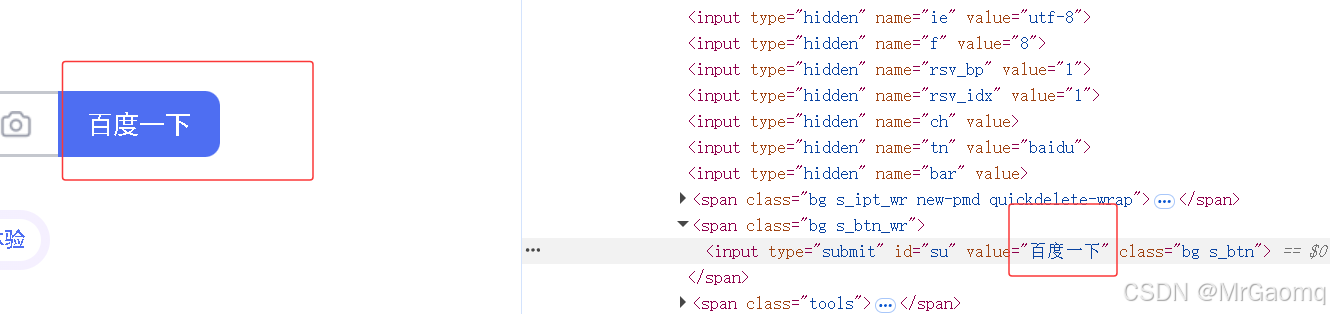
那为什么之前热搜可以打印出来,注意我们在复制热搜的元素的时候,文字是在span标签中间的
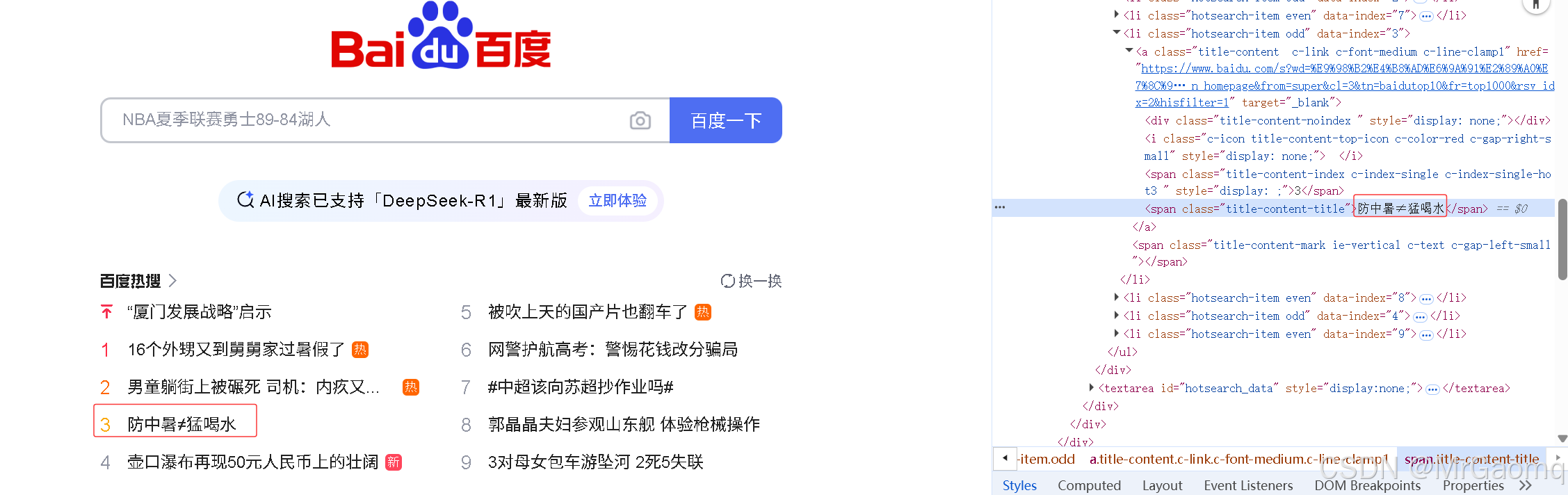
而百度一下这四个字是在input的value里的,而不是在这个标签中间的(这里面的 type id value class都是属性),所以这里的百度一下并不是标签里的文本信息,而是属性值

如果我就是想要打印出百度一下这四个字呢
get_attribute(属性) 获取属性值
上面说过了百度一下是属性值,所以这里我们不能用text来获取文本,需要用get_attribute( 属性 )来获取
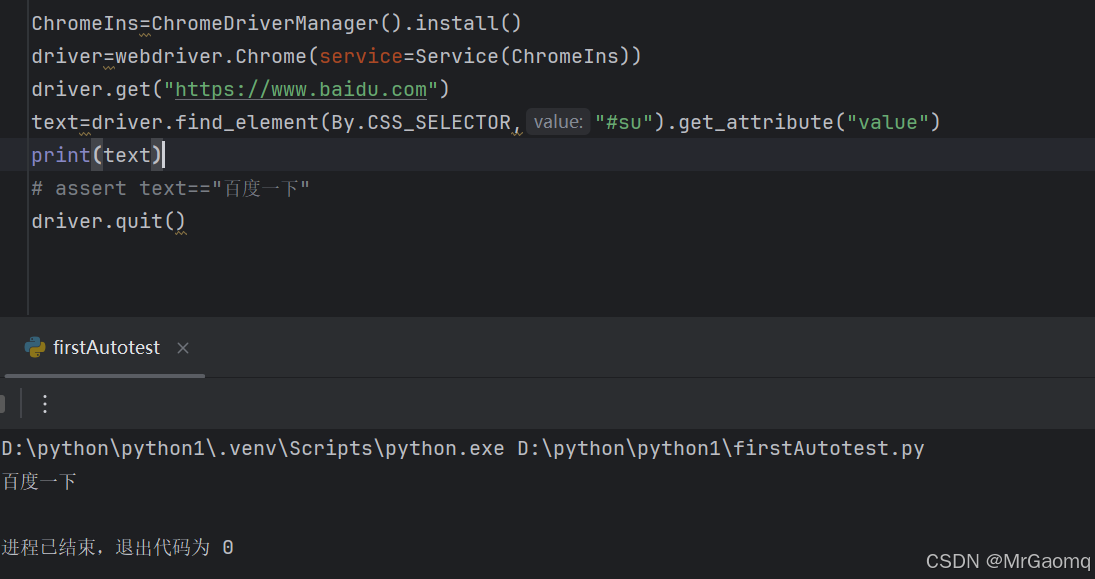
最后总结一下就是在标签中间的文字才是文本信息,而像class=xxx value=xxx…是标签里的属性值
title 获取当前页面标题 current_url 获取当前页面URL链接
有时候在访问页面的时候会想要看一下页面的标题和URL(这里的URL就是链接baidu.com)
获取的方式是用title(标题)和current_url(URL)
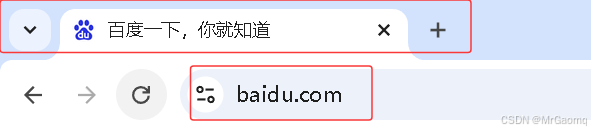
当我们用箭头点击上面的标题和链接的时候发现他不会变成蓝色的方框

而我们点击搜索框等地方就会变成蓝色方框
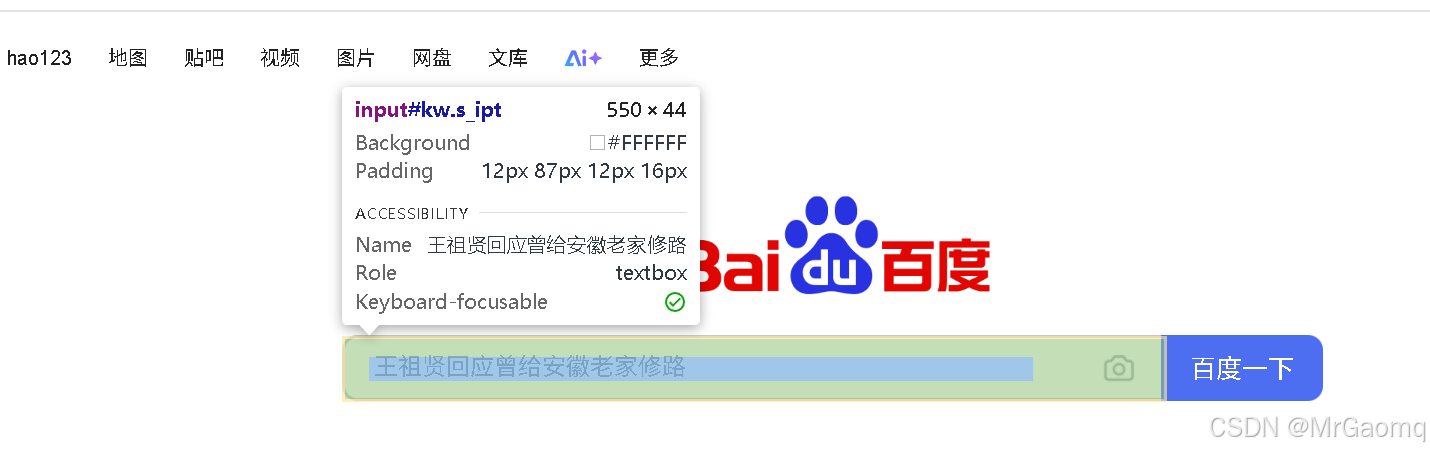
这是因为上面的内容不是页面内容,所以在这个页面是没有定位到标题和链接的前端代码
通过下面的代码就可以获取内容
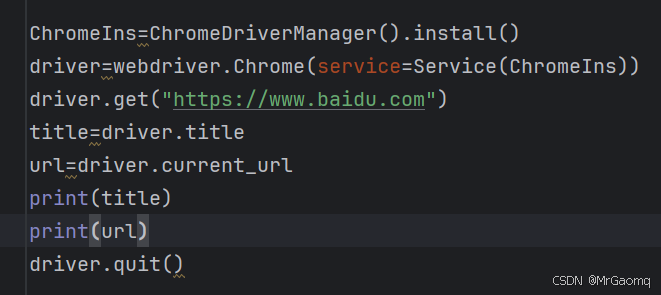
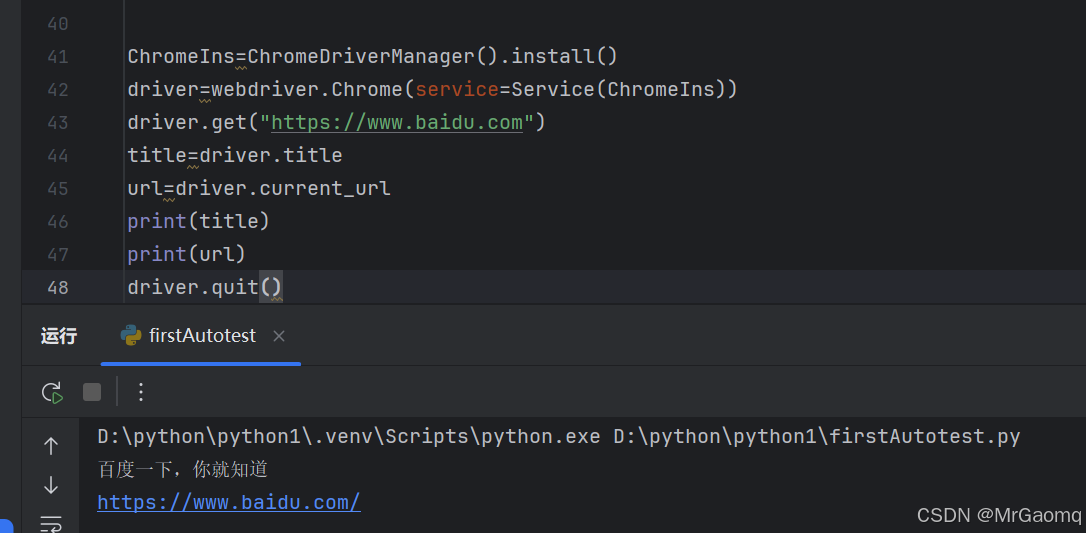
获取标题和url链接是因为有时候在跳转页面时我们不知道是否跳转成功了,所以需要获取


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









