






快速排序
一.引入
我们如何划分老人与青年?身高高矮与否又如何划分?在人类社会,任何事物都有自己的一个分类标准:我们把大于60岁的人叫做老人,身高大于180cm的人我们都会说他很高。“60岁”、"180cm"就是这个标准。在一个群体中,我们对某一个体通过某种标准进行定性分类时,本质上就是一种比较与排序。

那我们利用这一特性,将这个群体数量进行“缩小”并在群体中挑出“标兵”(标准)进行分类,是否是一种排序思路呢?没错,听到这,你已经初步认识了快速排序。
二.排序思想
如下图所示;其实,快速排序的过程是从整体到局部的过程,整体先确定一个标准(keyi)进行分类(大于keyi的放一边,小于keyi的放一边),分出两类数据后两类数据确定标准继续分类,当一个数据单独成类时,我们的排序也就完成了。我们发现快速排序也是大事件化小事件的一个过程,第一想法肯定是递归。同时我们与归并排序比较发现,快速排序是一个前序遍历过程(先整体后局部),归并排序是一个后序遍历的过程(先局部后整体)。

三.递归方法——代码实现与注意要点
通过上述排序思想的分析,递归已经很简单,我们的重点就是如何分类,我们要写出实用的代码就有三点问题需要解决:
a.如何实现标兵左右的分类操作呢?
说到这,我们介绍一种新的排序算法,它是一种十分简单的排序算法,但对我们解决快速排序的分类问题会有所启发!
0.选择排序算法及其对快速排序的启发
选择排序实质上是对数组进行遍历选出最值的算法,具体操作如下图演示所示
为了方便,我们用两个指针对数组进行遍历分别选出最大与最小的数据与数组头尾(begin,end)两个数据交换,如下图:

代码如下:
int SelectSort(int*a,int n)
{
int begin=0;int end=n-1;
while(begin<end)
{
int max=begin;int min=begin;
for(int i=begin;i<end;i++)
{
if(a[i]<a[begin])
min=i;
if(a[i]>a[end])
max=i;
}
Swap(&a[begin],&a[min]);
if(begin==max)
{
a[max]=a[min];//特殊情况容易遗漏
}
Swap(&a[end],&a[max]);
begin++;
end--;
}
}
经过上面选择排序,我相信你已经想到快速排序的分类操作是否也能也能利用双指针进行遍历得到。
b.我们的标兵(keyi)要如何挑选?
理论上而言,我们的keyi可以是数组内任意一个数,由于需要递归,为了方便,我们取每个数组的首元素为标兵(keyi)。
c.标兵(keyi)如何移动到指定位置?
那为了解决keyi的问题,前辈们总结出了三种方案(三种方案都以升序为例):
1.霍尔排法
霍尔排法最初由霍尔大佬提出,他的思路是首先选取数组首个元素为keyi(思考:此处的key(i)用于接收数组元素本身?还是接收数组的下标?),采用两个指针,一个从前往后遍历找大(大于key);一个从后往前遍历找小(小于key),找小的指针先走,找到之后两个指针指向元素进行交换,当两个指针相遇时交换数组标兵(key)这时完成一次分类过程。随后进行递归,继续分类直至分到一个元素无可再分时返回,完成排序。思考:此处为什么能够确定相遇位置的元素一定要比key值更小从而进行交换?
动图演示:

(1)注意要点
&1.思考:此处为什么能够确定相遇位置的元素一定要比key值更小从而进行交换?
由于最后交换的是数组内部元素不是key的值,因此霍尔法中我们最好用keyi记录标准的下标。
&2.思考:(相遇问题)此处为什么能够确定相遇位置的元素一定要比key值更小?
这是由于遍历时我们让找小的指针先走,在实际排序中,无非两种情况:找小指针遇找大指针,或者找大指针遇找小指针,我们不妨两种情况分开讨论:
a.找小指针遇找大指针:此步骤前一步是找大指针找大,虽是找大但别忘了找到大之后一定进行过一次交换,因此大指针指向的位置一定是较小数。
b.找大指针(L)遇找小指针(R):此步骤前一步是小指针找小,所以同理小指针此时一定已经找到了小数,但因为小指针先走代表大指针走完次才能完成一次交换,故此时一定还未交换,小指针一定指向较小数
综上所述:小指针先走,相遇时的数据一定比key值小。
(2)代码实现
经过上诉分析,我想大家已经想好如何编写代码了,具体代码如下:
void QuickSort(int* a, int begin, int end)
{
if (begin >= end)
{
return;
}
int left = begin; int right = end;
int keyi = begin;
while (left < right)
{
while (left < right && a[right] >= a[keyi] )//内部限定指针防止特殊情况越界访问或者陷入死循环
{
right--;//此处一定要让找小指针先走
}
while (left<right && a[left] <= a[keyi])
{
left++;
}
Swap(&a[left], &a[right]);
}
Swap(&a[keyi], &a[left]);
QuickSort(a, begin, left - 1);
QuickSort(a, left + 1, end);
}
我们可以将找keyi的过程分装成一个函数。代码如下:
int _QuickSort1(int*a, int begin, int end)
{
int keyi = begin;
while (begin < end)
{
while ( begin < end && a[end] >= a[keyi])
{
end--;
}
while ( begin < end && a[begin] <= a[keyi])
{
begin++;
}
Swap(&a[begin], &a[end]);
}
Swap(&a[begin], &a[keyi]);
return begin;//返回直接用keyi值接收
}
void QuickSort(int* a, int begin ,int end )
{
if (begin >= end)
{
return;
}
int keyi = _QuickSort1(a, begin, end);
QuickSort(a, begin, keyi - 1);//分装函数之后keyi即可作为标兵也可做递归分割界限值
QuickSort(a, keyi + 1,end );
}
2.挖坑法
挖坑法是对霍尔法的理解层面的优化:其主要区别是标兵直接存数组元素而不存储下标元素,首元素直接覆盖形成一个坑位,此时就不存在相遇问题的干扰,具体细节如下动图所示:
代码如下(仅写封装函数之后的代码):
//挖坑法
int _QuickSort2( int*a, int begin, int end )
{
int key = a[begin];
while( begin < end)
{
while( begin < end && a[end] >= key )
{
end--;
}
a[begin]=key;
while( begin < end && a[begin] <= key )
{
begin++;
}
a[end] = key;
}
a [begin]= key;
return begin;
}
3.前后指针法
这种方法十分的巧妙,思路是:定义两个指针(pre 与 cur),cur 向前走有两种情况
a.遇等于(等于key的值在左在右无所谓)或者比key大的值——此时只做一件事:++cur;
b.遇比key小的值——++pre 后交换 pre 与 cur 所指向的值最后 ++cur。
当cur越界时,交换key与pre即完成一次分类。
具体操作如下动图:

具体实现代码如下:
//前后指针法
int _QuickSort(int* a,int begin,int end)
{
int pre = begin;int cur =begin;
int keyi = begin;
while(cur<=end)
{
if(a[cur] < a[keyi])
{
pre++;
Swap(&a[pre], &a[cur]);
}
cur++;
}
Swap(&a[pre], &a[keyi]);
return pre;
}
四.非递归方法——代码实现与注意要点
引入
一般递归改非递归最主要的方式有两种:
第一种:循环算法(比如上节所讲的归并排序)
第二种:利用数据结构——栈来实现。
由于快速排序是一种前序遍历算法,相当于每次出栈都能进行一次分类处理,所以快速排序;用方法二思路更加直观。
算法思想
快排算法中递归中我们每递归一层便分类一次递归一次,相当于在栈中入栈一次出栈一次,我们每次在栈中入两个收尾指针(直到两个指针相遇为止不入栈),出栈时进行一次分类算法处理(霍尔、挖坑、前后指针),直到栈空间内为空(既不用出栈也不用入栈时)完成排序。
如下列动图所示:

代码实现
快排的非递归代码实现其起来较为简单,C语言代码(记得自己造“轮子”)如下:
void QiuckSortNonR(int* a,int begin,int end)
{
ST s;//申请一个栈空间
STInit(&s);
STPush(&s, end);//先进右后进左
STPush(&s, begin);
while(!STEmpty(&s))
{
int left = STTop(&s);
STPop(&s);
int right = STTop(&s);
STPop(&s);
int keyi=int _QuickSort(int* a,left,right);//出栈后要进行分类处理
if (left < keyi - 1)
{
STPush(&s, keyi - 1);
STPush(&s, left);
}
if (keyi + 1 < right)
{
STPush(&s, right);
STPush(&s, keyi+1);
}
STDestroy(&s);
}
}
五.算法优化
以上写的快速排序当数据趋于有序时效率是不高的,为此可对某些环节进行系列优化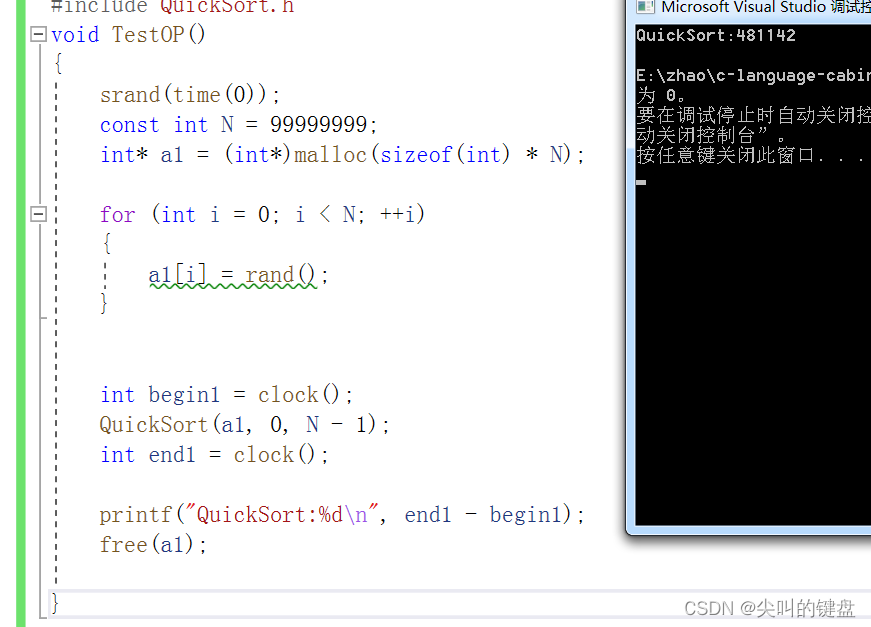
1.小区间优化
之前我们学习递归时知道,越往后递归的次数越多,最后一层是所有递归次数的一半,而且递归的越深,数据的数量越少,那此时能否使用其他简单的排序进行替换呢?我们一般采用插入排序进行替换。此方式有一定的优化效果但并不突出。当数据足够大时甚至会起到反作用:
void QuickSort(int* a, int begin ,int end )
{
if (begin >= end)
{
return;
}
if (end - begin + 1 <= 7)
{
InsertionSort(a + begin, end - begin + 1);
}
else {
int keyi = _QuickSort3(a, begin, end);
QuickSort(a, begin, keyi - 1);
QuickSort(a, keyi + 1, end);
}
}
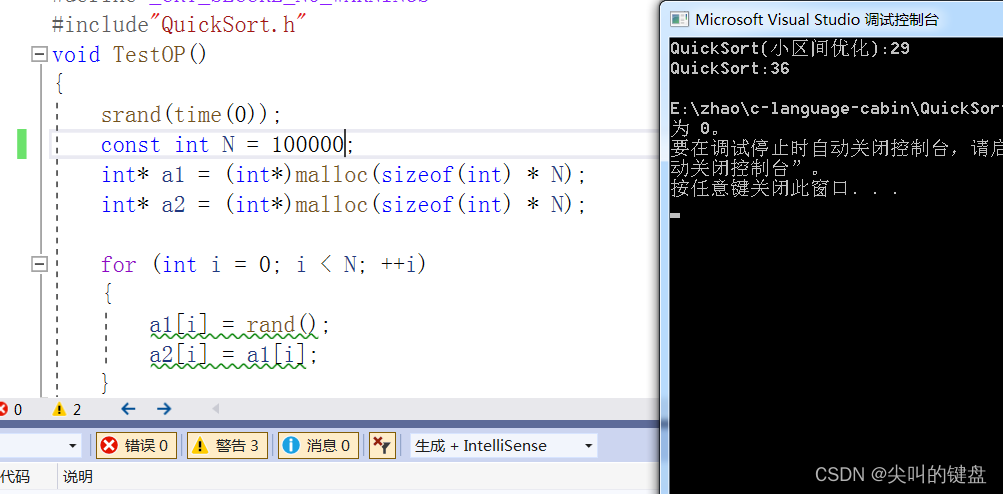
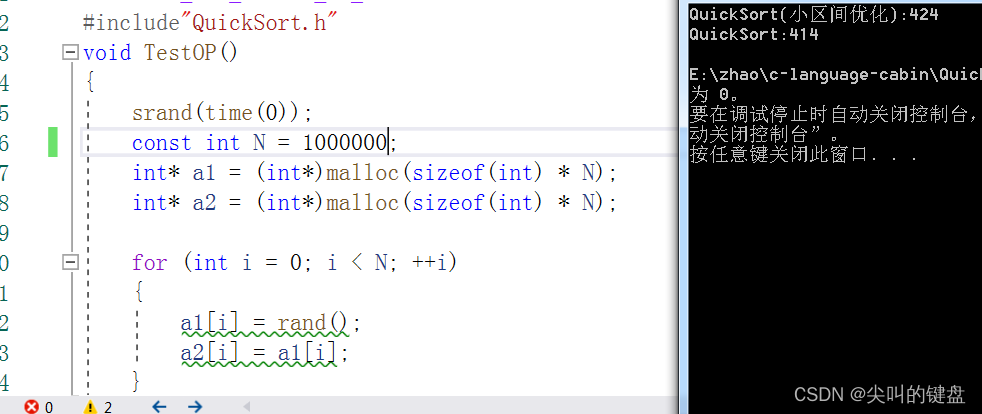
2.三数取中优化
三数取中优化的优化程度最高,它的原理很简单,每次我们分类之前能得到三个值(begin、end、(begin+end)/2),我们尽可能选择三个数的中位数当标准与keyi交换,这样能较大程度的减小递归的次数,从而达到提高效率的要求。下面。我们简单地写一个三数取中的函数:
int Getmid(int* a, int begin, int end)
{
int mid = (begin + end) / 2;
if (a[begin] >= a[end])
{
if (a[mid] >= a[begin])
return begin;
else if (a[mid] > a[end])
return mid;
else
return end;
}
else {
if (a[mid] >=a[end])
return end;
else if (a[begin] >= a[mid])
return begin;
else
return mid;
}
}
三数取中主要对快速排序排有序数组进行了优化。















 1301
1301











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









